

Magnetosomas para el tratamiento del cáncer
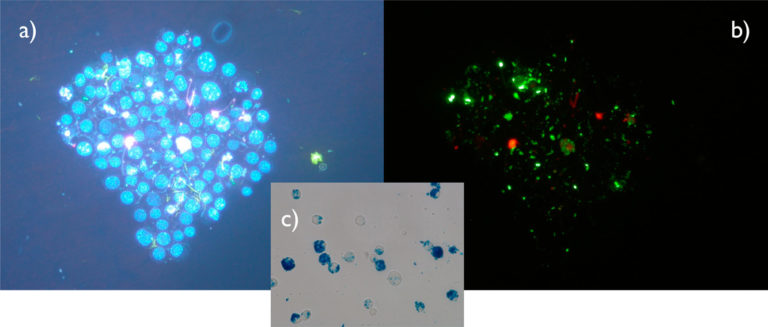 Magnetosomas internalizados por macrófagos, bajo diferentes filtros. Fuente: A. Muela et al (2016)
Magnetosomas internalizados por macrófagos, bajo diferentes filtros. Fuente: A. Muela et al (2016)Las nanopartículas magnéticas han permitido en los últimos años explorar modos de actuación alternativos a las terapias actualmente en uso en la lucha contra el cáncer. Una ventaja notable de las nanopartículas magnéticas es que pueden emplearse como agentes teranósticos (elementos que participan tanto en la terapia como en el diagnóstico) y entre los diferentes tipos destacan los magnetosomas, nanopartículas magnéticas sintetizadas por un tipo concreto de bacterias denominadas bacterias magnetotácticas.
Estos nanosistemas no solo se pueden usar en el transporte de fármacos sino que también presentan notables propiedades físicas y magnéticas para poder emplearlos en hipertermia —aumento de la temperatura corporal—, así como en el transporte guiado de fármacos. “El presente trabajo se centra en el estudio del potencial terapéutico de los magnetosomas en tratamientos de hipertermia magnética, una técnica que aprovecha la energía térmica producida por nanopartículas magnéticas bajo la acción de un campo magnético alterno para eliminar las células cancerígenas”, señala David Muñoz Rodríguez, investigador del Departamento de Inmunología, Microbiología y Parasitología de la UPV/EHU.
“Los magnetosomas, al contrario que las nanopartículas magnéticas de síntesis química, poseen de manera natural una membrana lipoproteica que los protege, evitando a la vez su aglomeración. Además, pueden funcionalizarse, es decir, ciertos fármacos o agentes antitumorales pueden adherirse a la membrana para poder guiarlos de forma eficiente hasta la masa tumoral. Las nanopartículas magnéticas emiten en forma de calor la energía que absorben del campo magnético alterno que se les aplica desde el exterior, provocando así un aumento de temperatura en los tumores y combatiéndolos”, indica Muñoz.
“Los magnetosomas presentan gran capacidad de producir calor (mayor que las nanopartículas magnéticas de síntesis química) y su eficiencia en la hipertermia queda demostrada al ver que el 80 % de las células morían en los experimentos realizados”, comenta David Muñoz. Además, “la hipertermia magnética tiene la ventaja de ser una terapia local, sin provocar efectos secundarios severos en el organismo. El campo magnético no debe aplicarse en cualquier zona del cuerpo, ni de cualquier manera: hay que aplicarlo solo a la zona afectada por el tumor, alcanzando una temperatura que oscile entre los 43 y 46 ºC ,ya que en este intervalo de temperatura las células entran en lo que se llama apoptosis —muerte celular programada—. Hemos demostrado que la hipertermia magnética usando magnetosomas proporciona un aumento de temperatura suficiente para reducir la viabilidad celular de forma estadísticamente significativa, induciendo a las células a que entren en apoptosis y mueran”, subraya el autor del trabajo.
El investigador ha destacado que «el uso de magnetosomas en este tipo de terapias podría tener un futuro prometedor y ser una alternativa válida a los tratamientos antitumorales convencionales”. Sin embargo, Muñoz afirma que “sería fundamental conocer la distribución de dichas partículas magnéticas en el organismo. Es decir, una vez han actuado, ¿dónde van a parar? Algunos estudios señalan que el propio organismo podría metabolizar los magnetosomas; otros dicen que suelen acumularse en órganos como el hígado, riñón, el bazo… Ahí está el hándicap”.
Referencias:
Muela, A.; Muñoz, D.; Martín-Rodríguez, R.; Orue, I.; Garaio, E.; Abad Díaz de Cerio, A.; Alonso, J.; García, J. Á.; Fdez-Gubieda, M. L. Optimal Parameters for Hyperthermia Treatment Using Biomineralized Magnetite Nanoparticles: Theoretical and Experimental Approach. (2016) J. Phys. Chem. C, 120, 24437– 24448, doi: 10.1021/acs.jpcc.6b07321
Huizar-Felix, A. M.; Munoz, D.; Orue, I.; Magen, C.; Ibarra, A.; Barandiaran, J. M.; Muela, A.; Fdez-Gubieda, M. L. Assemblies of magnetite nanoparticles extracted from magnetotactic bacteria: A magnetic study. (2016) Appl. Phys. Lett. , 108, 063109, doi: 10.1063/1.4941835
Lourdes Marcano, David Muñoz, Rosa Martín-Rodríguez, Iñaki Orue, Javier Alonso, Ana García-Prieto, Aida Serrano, Sergio Valencia, Radu Abrudan, Luis Fernández Barquín, Alfredo García-Arribas, Alicia Muela, and M. Luisa Fdez-Gubieda (2018) Magnetic Study of Co-Doped Magnetosome Chains The Journal of Physical Chemistry C 122 (13), 7541-7550 doi: 10.1021/acs.jpcc.8b01187
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Magnetosomas para el tratamiento del cáncer se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Lo mejor de dos mundos para avanzar en el tratamiento del cáncer
- Implante de factores de crecimiento en nanoesferas para el tratamiento de alzhéimer y párkinson
- Nanopartículas para reducir la metástasis hepática del cáncer de colon
El genio cegado por su propia teoría
Nos situamos en 1873. James Clerk Maxwell era uno de los miembros más distinguidos de la Royal Society de Londres, ya que, unos años antes había demostrado que electricidad y magnetismo son dos caras del mismo fenómeno, y que viajan de la mano en forma de onda a la velocidad de la luz. Ese mismo año publicó su magnum opus: el Tratado de Electricidad y Magnetismo, un compendio de todo su trabajo que predecía que la luz es, de hecho, una onda electromagnética.
Pero aquel tratado predecía otro fenómeno quizás más sorprendente: al igual que una masa empuja a otra masa al chocar con ella, las ondas electromagnéticas, por el mero hecho de ser ondas que transportan energía, serían capaces de transmitir movimiento al incidir en un objeto, de empujarlo. No en vano, hoy en día sabemos que este es el principio por el que funcionan las velas solares.
Por aquel entonces, William Crookes, que era químico y un gran experimentador, tenía fama por su gran habilidad creando tubos de vacío: tubos de vidrio de los que se extraía casi todo el aire con diferentes propósitos. De hecho, ha pasado a la historia por ser el creador del tubo de rayos catódicos: un tubo de vacío con dos electrodos que, años más tarde, se utilizó para descubrir los electrones y los rayos-X, e incluso sirvió para inventar el televisor.
Pero a pesar de su habilidad técnica, también tenía fama de no ser muy buen científico. O, al menos, en la Royal Society no estaba muy bien considerado, puesto que, como buen caballero victoriano, era espiritista. De hecho, durante aquel año, el buen hombre se hallaba buscando “fuerzas psíquicas”… Para ello, estaba realizando unas medidas de masa muy delicadas con talio dentro de uno de sus tubos de vacío cuando se dio cuenta de que, cuando el sol incidía en el dispositivo, las medidas salían distintas.
¿Cómo podía ser posible? Crookes lo vio claro: estaba ante una prueba empírica de la teoría de Maxwell. Esto le llevó a concebir el artilugio que conocemos como “molinillo de luz” o “radiómetro de Crookes”. Consta, cómo no, de un tubo de vacío, normalmente en forma de bombilla. En su interior hay unas aspas, con una cara negra y otra reflectante, unidas a un capuchón de vidrio que pende sobre una aguja, para evitar al máximo el rozamiento. Según Crookes, la teoría de Maxwell establece que la luz interactúa de forma diferente con la parte negra y la reflectante, lo que resulta en una fuerza neta que impulsa las aspas. Y lo cierto es que, cuando pones el molinillo a la luz… ¡las aspas giran!
 Fuente: Wikimedia Commons
Fuente: Wikimedia Commons{kind=link}
Maxwell recibió el artículo de Crookes que describía el experimento y se quedó maravillado con la elegancia de la prueba de su propia teoría. Alabó su trabajo, perdonando su pasado espiritista, y recomendó su inmediata publicación. Se realizó una presentación del artilugio en la Royal Society por todo lo alto, y las crónicas contaron que “la ciencia había hecho un agujero en el infinito”.
Pero finalmente resultó que uno de los mayores genios científicos de la historia, cegado por su propia teoría, seducido por la supuesta elegancia de la demostración, cayó presa de su propio sesgo. Y es que la teoría electromagnética, efectivamente, establece que la luz interacciona de forma distinta con las caras de las aspas, pero más concretamente dice que la parte reflectante recibe el doble de presión que la parte negra. Y, por tanto, ¡gira al revés!, ¡debería girar para el otro lado!
Ni que decir tiene que, a partir de ese momento, empezó una carrera para investigar el verdadero funcionamiento del molinillo. Entre otras cosas, se vio que, cuando había mucho aire dentro, no giraba; cuando había demasiado poco, tampoco; cuando se enfriaba, giraba en el otro sentido… todo parecía indicar que algo tenía que ver el poco aire que quedaba dentro del tubo de vacío.
Se especuló mucho hasta que Osborne Reynolds, en 1879, dio finalmente con la solución: se trata de un fenómeno denominado transpiración térmica. Resulta que, en las condiciones del tubo de vacío, las poquitas moléculas de aire que quedan en su interior ya no interaccionan entre ellas, lo que se denomina gas enrarecido. La cara negra de las aspas se calienta más que la cara reflectante, porque absorbe la radiación, y así se calienta el aire circundante. Lo que sucede entonces es que el aire frío tiende a trepar por el borde del aspa y pasa al lado caliente, y así se produce un empuje neto hacia el otro lado.
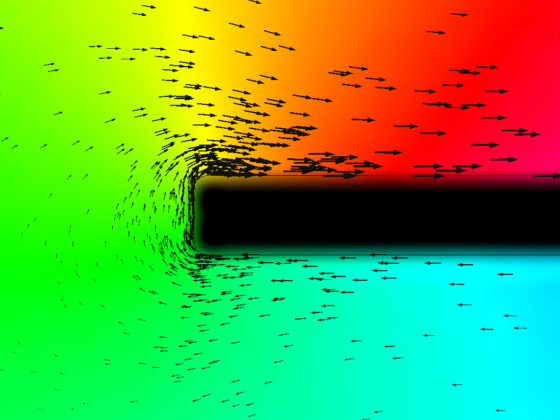 Simulación de la transpiración térmica en un molinillo de luz, por Moritz Nadler
Simulación de la transpiración térmica en un molinillo de luz, por Moritz NadlerComo epílogo, Reynolds escribió un artículo con esta explicación que revisó… Maxwell de nuevo. Pero Maxwell, quizás herido en su orgullo, decidió paralizar la publicación y escribir su propio artículo para criticar a Reynolds. Entonces Reynolds quiso publicar una crítica de la crítica de Maxwell al primer artículo suyo rechazado. Pero, entretanto, lamentablemente Maxwell murió, y de nuevo Reynolds se quedó sin publicación, esta vez por respeto al recién fallecido. Hoy en día, el molinillo es una baratija que se suele vender en tiendas de museos científicos como curiosidad.
Sobre el autor: Iñaki Úcar es doctor en telemática por la Universidad Carlos III de Madrid e investigador postdoctoral del UC3M-Santander Big Data Institute.
El artículo El genio cegado por su propia teoría se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La teoría de la invariancia
- ¿La teoría de la invariancia es física o metafísica?
- La teoría cinética y la segunda ley de la termodinámica
La ecuación de las ciudades oscuras
Las ciudades oscuras es una serie de novelas gráficas, publicadas originalmente en francés, del dibujante belga François Schuiten y el guionista francés Benoît Peeters, cuyo primer álbum Las murallas de Samaris fue publicado en 1983 y que sigue publicándose en la actualidad. En el momento en el que escribo estas líneas cuenta con doce álbumes: Las murallas de Samaris, La fiebre de Urbicande, La Torre, La ruta de Armilia, Brüsel, La chica inclinada, La sombra de un hombre, La Frontera Invisible (doble), La teoría del grano de arena (doble), Recuerdos del eterno presente.
En la colección de novelas gráficas Las ciudades oscuras nos encontramos ante una serie de historias entre fantásticas y surrealistas que transcurren en diferentes ciudades de un continente imaginario que se encuentra situado en el planeta Antichton, o Anti-Tierra. Este hipotético planeta fue inventado por el filósofo y matemático pitagórico Filolao (aprox. 470 – 380 a.n.e.) cuando describió un sistema cosmológico, no geocéntrico, en el que había un fuego central distinto del Sol y un planeta situado en la posición diametralmente opuesta a la Tierra, respecto a dicho fuego central, la anti-Tierra.
La arquitectura y el diseño urbanístico de las ciudades oscuras son protagonistas principales de esta serie de novelas gráficas, pero también la política, la sociedad, la ciencia, las creencias o las relaciones humanas., entre muchos otros
 Nueve portadas de la serie de novelas gráficas Las ciudades oscuras de François Schuiten (dibujo) y (Benoît Peters), publicadas por Norma Editorial. Imágenes de la página web de Norma Editorial
Nueve portadas de la serie de novelas gráficas Las ciudades oscuras de François Schuiten (dibujo) y (Benoît Peters), publicadas por Norma Editorial. Imágenes de la página web de Norma EditorialEn esta entrada del Cuaderno de Cultura Científica vamos a centrarnos en uno de los álbumes de la serie titulado La fiebre de Urbicande (1985). El protagonista de esta historia es Eugen Robick, el “urbatecto” (unión de urbanista y arquitecto) oficial de la ciudad de Urbicande, que está preocupado por el diseño urbanístico de la ciudad y su falta de simetría. La ciudad de Urbicande está dividida por su río en dos zonas. La zona sur, en la que vive la alta sociedad, sería una ciudad geométrica, con avenidas rectas, que se intersecan perpendicularmente, sobre la que se han diseñado, de forma racional, edificios rectos y simétricos, mientras que la zona norte, en la que vive la parte de la sociedad que la clase alta quiere mantener alejada, posee un desarrollo urbanístico irregular.
Sin embargo, un inesperado acontecimiento cambiará las preocupaciones de Eugen Robick y de los habitantes de la ciudad de Urbicande, la aparición de un misterioso cubo encontrado en unas obras y que se convertirá en el desencadenante de los acontecimientos futuros de la ciudad.
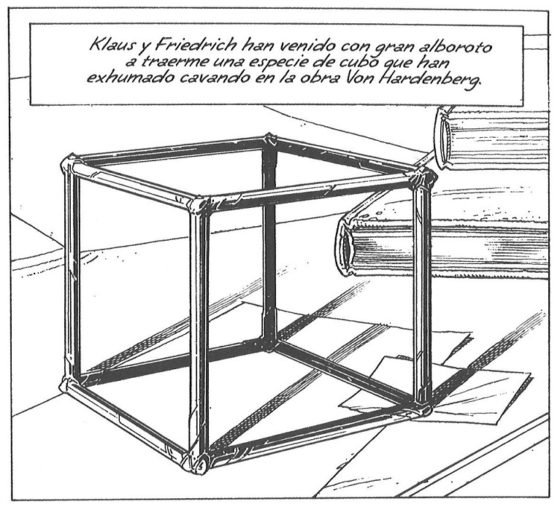 Viñeta de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en el cual vemos el cubo que se convertirá en protagonista de esta historia
Viñeta de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en el cual vemos el cubo que se convertirá en protagonista de esta historia
Aparentemente el cubo no posee un gran interés, salvo que está construido con un material extremadamente duro. El urbatecto Eugen Robick lo describe así en las primeras páginas.
“Klaus y Friedrich han venido con gran alboroto a traerme una especie de cubo que han exhumado cavando en la obra Von Hardenberg.
El objeto habría quebrado la pala de una grúa, debido a su gran solidez.
Al observarla fríamente, no tiene sin embargo nada de demasiado extraño. Es una simple estructura cúbica totalmente vacía cuyas aristas no deben de superar los quince centímetros.”
Lo curioso es que, poco tiempo después, del cubo han surgido unas prolongaciones que extendían los lados del mismo, con un crecimiento constante, hasta generar un nuevo cubo en cada una de las caras del hexaedro regular original. De forma que en esta primera etapa se ha creado una pequeña red con 7 cubos. Además, al tiempo que iba ocurriendo esto, el tamaño del cubo original ha ido creciendo también, así en un día el tamaño de las aristas del cubo, de los cubos, ha pasado de 15 a 20 centímetros. El grosor de las aristas también ha ido creciendo paulatinamente.
 Viñeta de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en el cual vemos el momento en que se está terminando la primera etapa de desarrollo del cubo original, convirtiéndose en una pequeña red de 7 cubos, el central y uno en cada cara del mismo
Viñeta de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en el cual vemos el momento en que se está terminando la primera etapa de desarrollo del cubo original, convirtiéndose en una pequeña red de 7 cubos, el central y uno en cada cara del mismo
Como el proceso no para, la red de cubos va creciendo poco a poco, en tamaño y en número de ortoedros que lo conforman. En la siguiente etapa de crecimiento, en cada cara de los cubos que forman la red surgen nuevos cubos, luego de 7 cubos pasa a 25. Y en la siguiente etapa, la red de cubos, que tendrá la forma de un octaedro (es decir, una doble pirámide, hacia arriba y hacia abajo), estará formada por 63 cubos. Después, 129, 231, etcétera.
 Viñetas de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en las cuales vemos al urbatecto Robick estudiar la estructura y calcular el número de cubos que tendrá en cada etapa de crecimiento
Viñetas de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en las cuales vemos al urbatecto Robick estudiar la estructura y calcular el número de cubos que tendrá en cada etapa de crecimiento
Eugen Robick, que era matemático de formación según se comenta en la parte de La leyenda de la red, empieza a estudiar la estructura reticular que se genera. En particular, obtiene una fórmula, que veremos más adelante, que le da el número de cubos que tendrá la estructura en cada paso. Pero estudiemos nosotros esa sucesión de números que nos da la cantidad de cubos que posee la red octaédrica que aparece en la novela gráfica.
Empecemos pensando el problema en dimensión 2. Supongamos que nuestra estructura original es un cuadrado, que va creciendo y formando una red de cuadrados de forma similar a como la red de cubos de Urbicande (véase la siguiente imagen). En cada lado del cuadrado original se forma un nuevo cuadrado y sobre los lados de los nuevos cuadrados irán creciendo nuevos cuadrados.
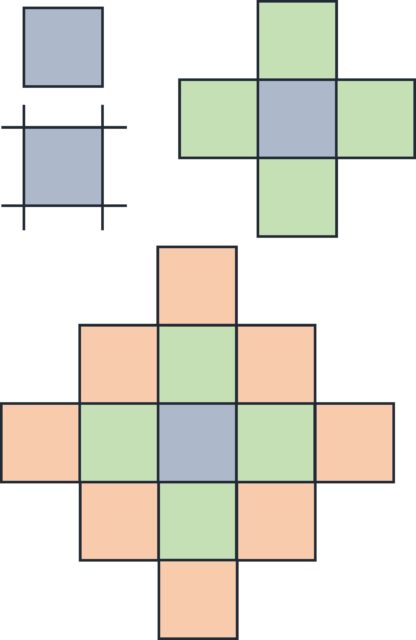
Primero, en el momento cero tenemos 1 cuadrado (c0), del que surgen 4 más, luego 5 (c1) en total. En la segunda etapa se incorporan 8, luego 13 (c2) en total… y así continúa. Pero, veamos cuantos cuadrados se incorporan en cada momento. Si nos fijamos en la anterior imagen, en la segunda etapa (c2), los cuadrados que se incorporan forman un cuadrado grande (rojo) con 3 cuadrados en cada lado, luego tiene (4 x 3 – 4 = 4 x (3 – 1) = 4 x 2 = 8 cuadrados, es decir, cuatro veces los cuadrados que hay en cada lado menos 4, de los vértices, que contábamos dos veces). En general, en el paso n-ésimo se incorporarán, a los anteriores cubos, 4 x n cubos más. Por lo tanto, se obtiene la siguiente fórmula:
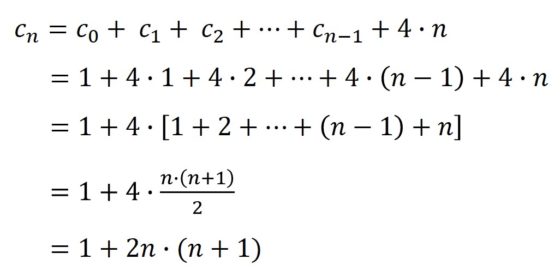
Donde hemos utilizado, en el ante-último paso, la fórmula de la suma de los n primeros números (véase la entrada Matemáticas para ver y tocar ).
 Página de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en la cual vemos al urbatecto Robick dentro de la estructura reticular que cada vez va creciendo más
Página de la novela gráfica La fiebre de Urbicande, de Scuiten-Peeters, en la cual vemos al urbatecto Robick dentro de la estructura reticular que cada vez va creciendo más
 Estructura reticular con cubos, que adopta la forma de un octoedro, después de tres etapas, luego con 25 cubos, que he realizado con el material de construcción Zometool
Estructura reticular con cubos, que adopta la forma de un octoedro, después de tres etapas, luego con 25 cubos, que he realizado con el material de construcción Zometool
El razonamiento que hemos desarrollado en el plano, para cuadrados, no solo nos ayuda a entender el problema en dimensión tres, para cubos, sino que nos permite obtener fácilmente una fórmula para la cantidad de cubos de cada etapa de la red. Esto se debe a que en la etapa n-ésima la cantidad de cubos de la zona/capa central de la red octaédrica es igual a la cantidad de cuadrados de la etapa n-ésima de los cuadrados planos (cn), ya que solo nos fijamos en los cubos que están a la misma altura, en la misma capa horizontal. En la capa de arriba de la central, y también en la de abajo, hay tantos cubos como cuadrados había en la etapa anterior, luego (n – 1)-ésima de los cuadrados planos (c(n – 1)), y así con el resto. Veamos los primeros pasos. En la primera etapa hay 5 cubos en la zona central y 1 arriba y otro abajo, en total, 7 cubos. En la segunda etapa hay 13 cubos en la zona central, 5 en la zona que está justo encima y 5 en la que está justo debajo, y 1 cubo arriba del todo y 1 abajo del todo, en total 13 + 2 x 5 + 2 x 1 = 25 cubos.
Es decir, tenemos la fórmula general para la cantidad de cubos de la red de Urbicande dada en función de los anteriores números:
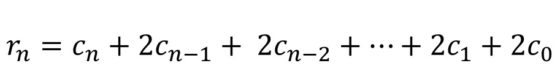
Pero sustituyendo el valor de los números de cuadrados (cn) calculados anteriormente, se obtiene:
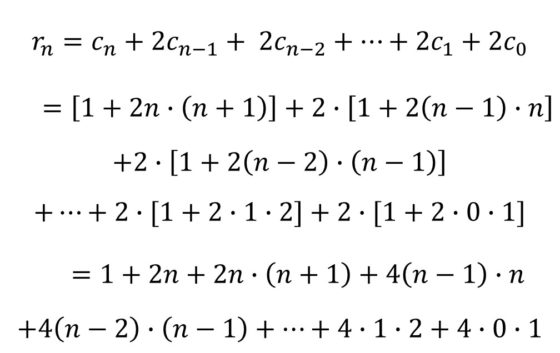
Observemos que en la segunda igualdad hemos sumado primero los 1s de los corchetes, obteniendo el número 1 + 2n del inicio.
Hemos obtenido así una primera fórmula para el cálculo del número de cubos de la red. Si vais dando valores a n = 0, 1, 2, 3, 4, 5, … obtendréis la cantidad de hexaedros regulares de cada etapa 1, 7, 25, 63, 129, 231, …
Vamos a intentar obtener una fórmula más sencilla de manejar. Si denotamos como Tn a los números triangulares, es decir, la suma de los n primeros números, Tn = 1 + 2 + … + n, que sabemos que es igual a n (n + 1) / 2, podemos demostrar que la anterior fórmula es igual a:
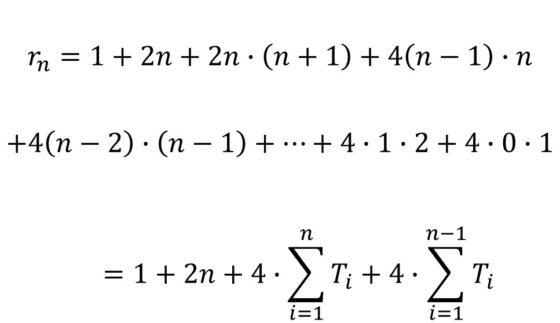
Para seguir avanzando necesitamos la fórmula de la suma de los números triangulares. En la siguiente imagen podéis ver dicha fórmula, con la demostración sin palabras que publicó Monte J. Zerger en Mathematics Magazine (diciembre, 1990) y que aparece también en el libro Demostraciones sin Palabras, de Roger B. Nelsen.
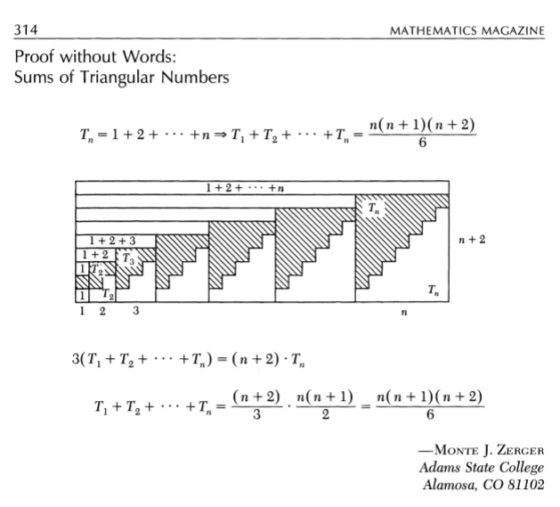 Demostración sin palabras que publicó Monte J. Zerger en Mathematics Magazine (diciembre, 1990) de la suma de los números triangulares
Demostración sin palabras que publicó Monte J. Zerger en Mathematics Magazine (diciembre, 1990) de la suma de los números triangulares
Ahora, haciendo uso de la anterior fórmula se obtiene la siguiente fórmula para la sucesión de cubos que conforman la red octaédrica de La fiebre de Urbicande:
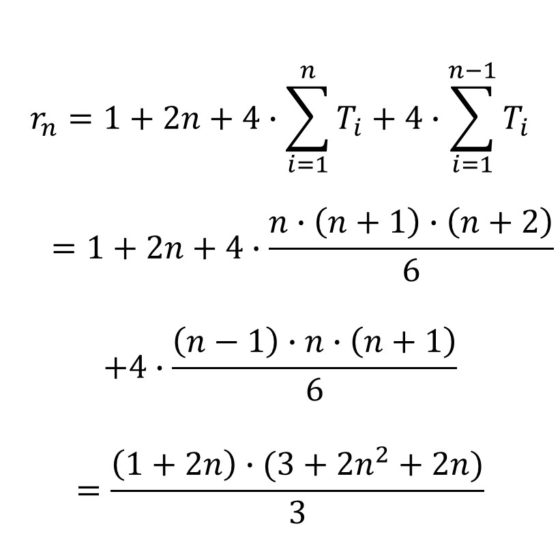
 Robick y Sofía, una mujer a la que conoce nuestro protagonista y de la que se enamora, disfrutando del paisaje de la estructura reticular, de la que se ve la pirámide superior, mientras que la inferior está ya bajo tierra
Robick y Sofía, una mujer a la que conoce nuestro protagonista y de la que se enamora, disfrutando del paisaje de la estructura reticular, de la que se ve la pirámide superior, mientras que la inferior está ya bajo tierra
Si volvemos a la novela gráfica de Schuiten-Peeters, podemos observar que la fórmula que he obtenido coincide con una de las dos que aparecen en la misma. Una de ellas es la fórmula de Robick y la otra la que aparece en el opúsculo El misterio de Urbicande “de un tal R. de Brok”, dentro de la parte denominada La leyenda de la red, que es un documento perteneciente a los Archivos de “las ciudades oscuras”.
 Página extraída del opúsculo El misterio de Urbicande, anotada por Eugen Robick, en la que podemos ver las dos fórmulas matemáticas para el número de cubos de la estructura reticular, la fórmula de Robick y la fórmula de R. de Brok (que aparece descrita como “Mi fórmula”)
Página extraída del opúsculo El misterio de Urbicande, anotada por Eugen Robick, en la que podemos ver las dos fórmulas matemáticas para el número de cubos de la estructura reticular, la fórmula de Robick y la fórmula de R. de Brok (que aparece descrita como “Mi fórmula”)
El razonamiento que utiliza Eugen Robick es diferente al mío y por eso la fórmula que obtiene es diferente. Podemos decir que yo cuento los cubos de cada capa horizontal de la estructura reticular, mientras que Robick cuenta los cubos en columnas verticales.
Expliquemos brevemente la idea de Robick. En la etapa n-ésima del desarrollo de la red la “columna central” de la estructura con forma de octaedro (pirámide doble) tiene 2n + 1 cubos, que es el número que aparece en primer lugar en su fórmula. Después divide la pirámide doble, menos la columna central, en cuatro partes iguales (en la siguiente imagen observamos la partición en lo que sería la vista desde arriba de la red) y calcula la cantidad de cada parte, que es la expresión que aparece multiplicando al 4.
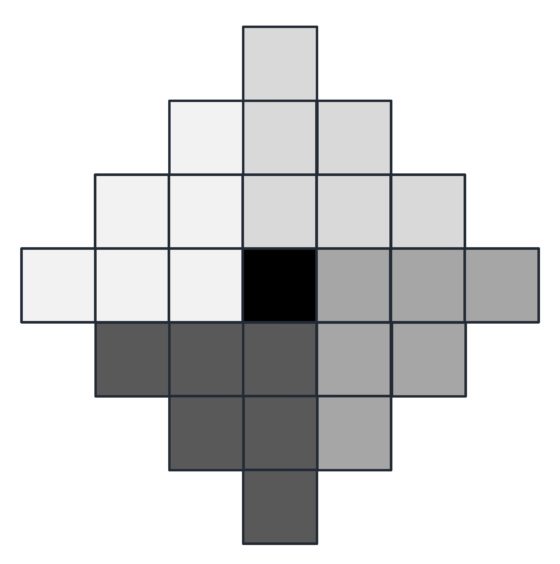 Vista desde arriba de la estructura reticular, con la columna central que se corresponde con el cuadrado negro y las cuatro zonas de la retícula octaédrica en las que Robick divide la estructura
Vista desde arriba de la estructura reticular, con la columna central que se corresponde con el cuadrado negro y las cuatro zonas de la retícula octaédrica en las que Robick divide la estructura
Ahora razonemos visualmente (en la siguiente imagen) cómo obtiene Robick la fórmula del cálculo de los cubos de cada una de esas cuatro partes.
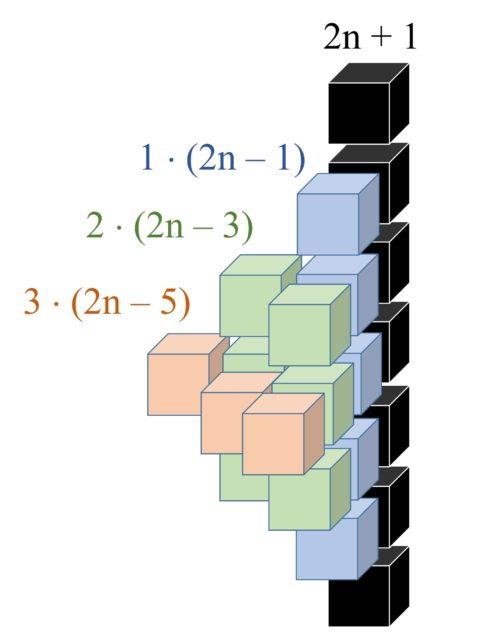 Ilustración, para la etapa n = 3 del crecimiento de la red, de la columna central de cubos, en la que hay 2n +1 elementos, más una de las cuatro partes en las que Robick divide la retícula. Se indican con diferentes colores los cubos que cuenta juntos, que van por alturas
Ilustración, para la etapa n = 3 del crecimiento de la red, de la columna central de cubos, en la que hay 2n +1 elementos, más una de las cuatro partes en las que Robick divide la retícula. Se indican con diferentes colores los cubos que cuenta juntos, que van por alturas
Juntando todo lo anterior se obtiene la fórmula de Robick:
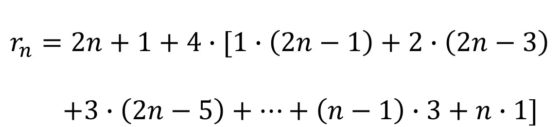
No hemos entrado en el trasfondo social y político de la historia que se cuenta en La fiebre de Urbicande, pero eso dejo que lo descubráis en vuestra propia lectura de la novela gráfica.
 Viñeta de La fiebre de Urbicande, de Schuiten-Peeters, en la que vemos el momento en el que la red ya solo tiene un cubo alrededor de la ciudad, por lo que ya no interfiere en la vida de la misma. La red de hexaedros regulares seguirá creciendo, primero superando la ciudad, luego el continente, después el planeta y seguirá creciendo en la galaxia
Viñeta de La fiebre de Urbicande, de Schuiten-Peeters, en la que vemos el momento en el que la red ya solo tiene un cubo alrededor de la ciudad, por lo que ya no interfiere en la vida de la misma. La red de hexaedros regulares seguirá creciendo, primero superando la ciudad, luego el continente, después el planeta y seguirá creciendo en la galaxia
Finalizamos la entrada animando a la lectura de la serie de novelas gráficas de François Schuiten y Benoît Peeters, Las ciudades oscuras, y con la imagen de la contraportada de La fiebre de Urbicande de la edición en castellano de Norma editorial en 2015, con tres de los protagonistas de la historia, Eugen, Sofía y el misterioso cubo.
 Contraportada de La fiebre de Urbicande, Schuiten-Peeters, Norma editorial, 2015
Contraportada de La fiebre de Urbicande, Schuiten-Peeters, Norma editorial, 2015
Bibliografía
1.- Francois Schiten, Benoit Peeters, La fiebre de Urbicande (Las ciudades oscuras), Norma Editorial, 2015.
2.- Roger B. Nelsen, Demostraciones sin palabras (ejercicios de pensamiento visual), Proyecto Sur, 2001.
3.- Jean-Paul Van Bendegem, A short explanation of «Le Mystère d’Urbicande», Alta plana, the impossible & infinite encyclopedia of the world created by Schuiten & Peeters
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo La ecuación de las ciudades oscuras se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Triangulando: Pascal versus Sierpinski
- Buscando las soluciones del cubo de Anda
- Locura instantánea, un rompecabezas con cubos de colores
La interpretación de Copenhague de la mecánica cuántica
 Sede del Instituto de Física Teórica de la Universidad de Copenhague construida y constituido, respectivamente, en 1921 con Niels Bohr como director. Popularmente conocido como Instituto Bohr, adoptó oficialmente ese nombre en 1965. Fuente: Niels Bohr Institutet
Sede del Instituto de Física Teórica de la Universidad de Copenhague construida y constituido, respectivamente, en 1921 con Niels Bohr como director. Popularmente conocido como Instituto Bohr, adoptó oficialmente ese nombre en 1965. Fuente: Niels Bohr InstitutetEl principio de complementariedad de Bohr es una afirmación de una enorme importancia, porque significaba que lo que observamos en nuestros experimentos no es lo que la naturaleza realmente es cuando no la estamos observando. Pero ahondemos sobre esto, porque la afirmación choca con el sentido común [1], lo que puede hacer más difícil asimilar lo que aquí se está diciendo [2].
De hecho, la naturaleza no favorece ningún modelo específico cuando no estamos observando; si algo podemos afirmar es que la naturaleza es una mezcla de las muchas posibilidades que podría ser hasta que observamos [3]. Al establecer un experimento, seleccionamos el modelo que exhibirá la naturaleza y decidimos si los fotones, electrones, protones e incluso las pelotas de tenis (si se mueven lo suficientemente rápido) se comportarán como corpúsculos o como ondas.
En otras palabras, según Bohr, ¡el experimentador se convierte en parte del experimento! Al hacerlo, el experimentador interactúa con la naturaleza, de tal modo que nunca podemos observar todos los aspectos de la naturaleza como realmente es “en sí” [4]. De hecho, esta expresión, si bien es atractiva, no tiene un significado operativo. En cambio, deberíamos decir que solo podemos conocer la parte de la naturaleza que nuestros experimentos ponen de manifiesto. [5] La consecuencia de este hecho, a nivel cuántico, decía Bohr, es el principio de incertidumbre, que coloca una limitación cuantitativa sobre lo que podemos aprender sobre la naturaleza en cualquier interacción dada; y la consecuencia de esta limitación es que debemos aceptar la interpretación de probabilidad de los procesos cuánticos individuales. De aquí que al principio de incertidumbre a menudo también se le llame principio de indeterminación.
No hay forma de evitar estas limitaciones, según Bohr, mientras la mecánica cuántica siga siendo una teoría válida. Estas ideas, por supuesto, están totalmente en desacuerdo con el sentido común, como apuntábamos antes. Asumimos que la naturaleza existe de manera completamente independiente de nosotros y que posee una realidad y un comportamiento definidos, incluso cuando no la estamos observando. Así, supones que el mundo fuera del lugar donde estás todavía existe más o menos como fue la última vez que lo observaste. No cabe duda de que la naturaleza se comporta así en nuestra experiencia cotidiana, y esta visión es una suposición fundamental de la física clásica. Incluso tiene un nombre filosófico; se llama «realismo», y para los fenómenos y objetos en el rango de la experiencia ordinaria es perfectamente apropiado. Pero, como Bohr a menudo enfatizó, tenemos que estar preparados para esperar que el mundo cuántico no sea como el mundo cotidiano en el que vivimos.
Parte de la dificultad viene del lenguaje que empleamos. Nuestra lengua común no puede expresar adecuadamente lo que las matemáticas consiguen hacer de manera muy eficiente. Max Born, uno de los fundadores de la mecánica cuántica, lo expresó así (nuestro énfasis):
El origen último de la dificultad radica en el hecho (o principio filosófico) de que estamos obligados a usar las palabras del lenguaje común cuando deseamos describir un fenómeno, no mediante un análisis lógico o matemático, sino mediante una imagen atractiva para la imaginación. El lenguaje común ha crecido con la experiencia cotidiana y nunca puede superar estos límites. La física clásica se ha limitado al uso de conceptos de este tipo; al analizar los movimientos visibles, ha desarrollado dos formas de representarlos mediante procesos elementales: partículas en movimiento y ondas. No hay otra forma de dar una descripción pictórica de los movimientos: tenemos que aplicarlo incluso en la región de los procesos atómicos, donde la física clásica se descompone. [6]
Juntos, el principio de complementariedad de Bohr, el principio de incertidumbre de Heisenberg y la interpretación de probabilidad de Born forman una interpretación lógicamente coherente del significado de la mecánica cuántica. Dado que esta interpretación se desarrolló en gran medida en el instituto de Bohr en la Universidad de Copenhague, se la conoce como la Interpretación de Copenhague de la mecánica cuántica. Los resultados de esta interpretación tienen profundas consecuencias científicas y filosóficas que se siguen estudiando y debatiendo. [7]
Notas:
[1] La ciencia se empeña en demostrar que el sentido común no deja de ser una colección de sesgos antropocéntricos y, por lo tanto, si bien útiles para el día a día en muchos casos, no necesariamente ciertos.
[2] Por eso es interesante fijarse en las palabras en cursiva, que están cuidadosamente seleccionadas.
[3] Este es el principio de superposición cuántico, sobre el que reflexionamos en La teoría superpositiva.
[4] Esto del “en sí” está entrecomillado porque es más un concepto filosófico que físico. Está relacionado con la caracterización de la sustancia de la época racionalista de la filosofía. Recordemos, por ejemplo, que Spinoza en la definición tercera del libro primero de la Ética decía “Por substancia entiendo aquello que es en sí y se concibe por sí, esto es, aquello cuyo concepto, para formarse, no precisa del concepto de otra cosa.”
[5] Y aquí hay que reflexionar mínimamente. Esto no es una invitación al misticismo, como algunos se apresuran a adoptar. Fijémonos en que, al fin y al cabo, conocemos incluso a nuestro mejor amigo solo a través de un mosaico de encuentros, conversaciones y actividades repetidas, en muchas circunstancias diferentes.
[6] A este respecto puede resultar interesante nuestro La verdadera composición última del universo (y IV): Platónicos, digitales y pansiquistas
[7] Una introducción a los elementos del debate puede encontrarse en nuestra serie Incompletitud y medida en mecánica cuántica
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo La interpretación de Copenhague de la mecánica cuántica se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Construyendo la mecánica cuántica
- La probabilidad en mecánica cuántica
- El principio de complementariedad
La crisis de reproducibilidad en ciencia
 Fuente: Science
Fuente: ScienceUno de los elementos más valiosos con que debiera contar la comunidad científica es con la replicación sistemática de los estudios o, al menos, con aquellos que introducen alguna novedad significativa. Sin embargo, la mayoría de los científicos se muestran poco inclinados a tratar de replicar los experimentos o análisis realizados por otros investigadores. Al fin y al cabo, resulta mucho más gratificante hacer nuevos estudios que puedan aportar novedades de interés en un campo que limitarse a comprobar si se obtienen los mismos resultados que obtuvieron antes otros. Además, las revistas científicas no están interesadas en publicar repeticiones, máxime si las conclusiones no refutan las del primer trabajo; en ese caso no hay novedades que contar.
En varios estudios se ha llegado a la conclusión de que muchos resultados publicados no son reproducibles o solo lo son parcialmente. Aunque lleva años generando preocupación, este problema se manifestó con toda su crudeza a raíz de la publicación en 2015 de un estudio en la revista Science, según el cual tan solo para una treintena de 100 experimentos de psicología publicados en las mejores revistas científicas del campo se habían podido reproducir sus resultados. Pero el problema no se limita a la psicología, sino que afecta a un buen número de disciplinas.
De acuerdo con una encuesta realizada en 2016 por la revista Nature a 1500 investigadores de diferentes campos, el 70% habían sido incapaces de reproducir los resultados de otros colegas y el 50% no lo habían sido de reproducir sus propios resultados. Por disciplinas, estos fueron los datos de la encuesta: en química el 90% y el 60% (ajenos y propios, respectivamente), en biología el 80% y el 60%, en medicina el 70% y el 60%, en física e ingeniería el 70% y el 50%,en medicina, y en ciencias de la Tierra y el ambiente el 60% y el 40% (Baker, 2016).
Parece evidente que la imposibilidad o dificultad para reproducir resultados constituye una severa limitación al ejercicio del escepticismo, sin el cual no es posible someter a contraste los resultados y conclusiones publicadas.
Aunque a veces la imposibilidad de reproducir los resultados se refiere a casos de fraude, lo normal es que no haya trampa ni malas prácticas realizadas de forma voluntaria. Las razones por las que los resultados experimentales no se reproducen al repetirse los experimentos son diversas. Muchas veces no se especifican de forma correcta las condiciones experimentales. En otras los investigadores se ven afectados por sesgos como los expuestos en una anotación anterior y que tienen que ver con el grado de aproximación de los resultados obtenidos a las expectativas iniciales. Cuando en un conjunto de datos alguno destaca como “anómalo” es relativamente común descartarlo basándose en el supuesto de que la anomalía bien puede deberse a un error experimental sin trascendencia. En todo esto influyen de forma decisiva dos factores. Uno es que el personal de universidades y centros de investigación, como ya hemos visto, está sometido a una fuerte presión por publicar. Y el otro es que las revistas científicas rara vez aceptan publicar resultados negativos. Por esa razón, no es de extrañar que funcionen sesgos que, inconscientemente, facilitan la obtención de resultados positivos y, por lo tanto, publicables.
El tratamiento estadístico es también una fuente de resultados de difícil reproducción. Es relativamente común la práctica de ensayar diferentes procedimientos y seleccionar, entre un catálogo más o menos amplio de posibilidades, aquél cuyos resultados mejor se acomodan a las expectativas. Este es un problema serio en los campos en que se realizan ensayos que han de conducir al desarrollo posterior de tratamientos médicos. Pero, el daño que causa es general, ya que esa forma de proceder tiende a neutralizar la emergencia de nuevas ideas que debería caracterizar, de forma intrínseca, a la práctica científica. Si se opta por mostrar los resultados que mejor se acomodan a las expectativas, se deja de lado el examen crítico de posibilidades que podrían haber conducido a nuevas ideas.
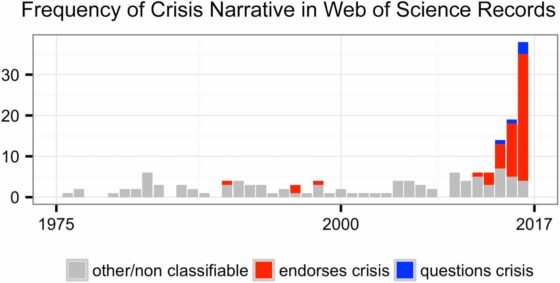 La figura muestra la frecuencia de aparición de expresiones relativas a, reales o supuestas, crisis científicas. Fuente: D Fanelli (2018) PNAS 115 (11): 2628-2631
La figura muestra la frecuencia de aparición de expresiones relativas a, reales o supuestas, crisis científicas. Fuente: D Fanelli (2018) PNAS 115 (11): 2628-2631La revista Proceedings of the National Academy of Sciences, más conocida por sus siglas PNAS y una de las más prestigiosas del mundo, publicó una serie de artículos analizando la llamada “crisis de reproducibilidad” y, en general, la validez de un discurso muy en boga mediante el que se difunde la idea de que la ciencia se encuentra hoy en crisis. De ese conjunto de estudios parece concluirse que esa idea no tiene suficiente base y que se trata, más bien, de una leyenda urbana. Sin embargo, en nuestra opinión, lo que esos estudios documentan es que el fraude no ha crecido durante las últimas décadas, de la misma forma que no ha crecido el número de artículos retractados (retirados de la publicación por los editores) en términos relativos. Pero no es tan clara la conclusión de que no hay problemas de reproducibilidad, porque el procedimiento seguido para llegar a esa conclusión es demasiado indirecto, mientras que los estudios que documentan las dificultades para reproducir resultados anteriores son bastante más directos.
En nuestra opinión, la falta de reproducibilidad procede de una progresiva relajación de los estándares que se consideran aceptables en cuanto calidad de la evidencia científica; nos referimos a asuntos tales como tamaños de muestra, claridad de la significación estadística más allá del valor de p, calidad de los blancos, etc. Los científicos como colectivo somos a la vez autores de los experimentos, autores de los artículos y revisores de estos. Que poco a poco se vayan aceptando niveles cada vez más bajos nos conviene si nuestro objetivo es el de publicar más rápidamente y engrosar un currículo investigador en un tiempo breve. Pero eso conduce, lógicamente, a un declive del rigor y exigencia generales. Ahora bien, al tratarse de un declive gradual, no se aprecia con nitidez la pérdida de calidad. Sin embargo, cuando el deterioro se acentúa se acaban dando por buenos (publicándolos) resultados que realmente no responden a hechos reales y por tanto no se pueden reproducir.
Este artículo se publicó originalmente en el blog de Jakiunde. Artículo original.
Sobre los autores: Juan Ignacio Perez Iglesias es Director de la Cátedra de Cultura Científica de la UPV/EHU y Joaquín Sevilla Moroder es Director de Cultura y Divulgación de la UPNA.
El artículo La crisis de reproducibilidad en ciencia se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El legado de Fisher y la crisis de la ciencia
- Ciencia Patológica
- Sesgos cognitivos que aquejan a la ciencia
Roberto Frucht, matemático en tránsito
Alberto Mercado Saucedo
Fueron varias las fronteras que cruzó Roberto Frucht tanto en las matemáticas como en su trayectoria personal. Obtuvo resultados de gran importancia y profunda belleza en teoría de grafos, cuando esta área recién comenzaba a definirse como tal en el medio académico internacional, y fue autor de algunos de los primeros artículos de investigación matemática realizada en Chile, publicados en revistas internacionales en los años cuarenta del siglo veinte. Además, dejó cantidad de gratos recuerdos entre colegas y estudiantes de la Universidad Técnica Federico Santa María –UTFSM- en Valparaíso, donde fue profesor durante más de medio siglo.
Hace un tiempo tuve la oportunidad de presenciar un bello e inesperado testimonio del poeta Raúl Zurita, que estudió ingeniería a fines de los años sesenta y tuvo a Frucht como profesor. El 2015 Zurita recibió el doctorado honoris causa de la universidad, y en su discurso de aceptación dedicó varios minutos a recordar una clase dictada por un “profesor ya mayor, de baja estatura” en la que el entonces futuro poeta se encontró con la “elegancia, simpleza y belleza” de cierta fórmula matemática. Como si la clase ocurriera en esos momentos, la voz del poeta recordó el áspero andar de la tiza en el pizarrón de cuarenta años atrás: el profesor Roberto Frucht explicando a sus estudiantes la fórmula de Euler, quizá una de las expresiones más hermosas de la matemática, como bien lo percibió Zurita.
¿Dónde reside la belleza de esta fórmula? Quizá simplemente en que aparecen distintos números bien conocidos: los irracionales e, junto con el imaginario i, la raíz cuadrada de -1, relacionados por operaciones matemáticas. Pero también podemos pensar que la fórmula relaciona los mundos del álgebra y la geometría: expresa que el número -1 hace ángulo con el eje x en el plano complejo; lo mismo ocurre con el valor de para cualquier ángulo Quizá fueron estos cruces lo que impactó a Zurita y provocó tan duradero recuerdo.
De hecho, la obra literaria de Zurita hace recurrentes alusiones al mundo de las matemáticas, tema del que no hablaremos ahora pero que podemos conjeturar se originó en momentos iluminadores como el anterior, que en el discurso del poeta tuvo un trágico contrapunto en la alusión al golpe de estado y el inicio de la dictadura, lo cual afectó directamente a Zurita y dejó al pueblo chileno un triste legado, aún vigente en nuestros días. Precisamente, el profesor Frucht había llegado a Sudamérica treinta años antes huyendo de horrores similares.
 Ilustración de Constanza Rojas-Molina. Todos los derechos reservados; cesión en exclusiva para su publicación en el Cuaderno de Cultura Científica.
Ilustración de Constanza Rojas-Molina. Todos los derechos reservados; cesión en exclusiva para su publicación en el Cuaderno de Cultura Científica.Roberto Frucht nació el 9 de agosto de 1906 en Brno, ciudad que hoy pertenece a la República Checa, y luego vivió en Berlin desde los dos años de edad, cuando su familia se instaló en la ciudad alemana. Allí finalizó estudios universitarios y decidió continuar especializándose en matemáticas, para lo que obtuvo su doctorado en 1930 en teoría de grupos, área del álgebra abstracta. Obtener una de las escasas plazas en la universidad era sumamente difícil, e impartir clase en un Gimnasium (colegio) estaba reservado para los alemanes, nacionalidad que no poseía Frucht. Estas circunstancias, por no hablar del contexto internacional, de lo más complicado para un descendiente de familia judía, hicieron que en 1930 se trasladara a Trieste, Italia, donde trabajaría en una compañía de seguros por casi ocho años. Allí, inició una relación con María Mercedes Bertogna, compañera de trabajo de origen argentino, con quien se casó en 1932.
Podemos imaginar que durante esos años en Trieste el trabajo de Roberto era rutinario, pero se las ingenió para publicar artículos -escritos en alemán- sobre la investigación realizada en su doctorado, además de otros trabajos de contabilidad escritos en italiano. Pero lo mejor estaba por venir, pues un día cualquiera de 1936 un hecho fortuito determinó la trayectoria de Roberto Frucht: recibió en su oficina de seguros un catálogo con información de un libro del matemático húngaro Dénes Kőnig sobre teoría de grafos, prácticamente el primero sobre la materia, y se interesó por el título de un capítulo que era algo así como “aplicaciones de la teoría de grupos a los grafos”. Ordenó el libro y desde que lo recibió se convirtió, según sus propias palabras, en un entusiasta de la teoría de grafos. Tan fue así, que se dedicó a estudiar el tema en detalle y en especial a trabajar en los problemas abiertos planteados en el libro.
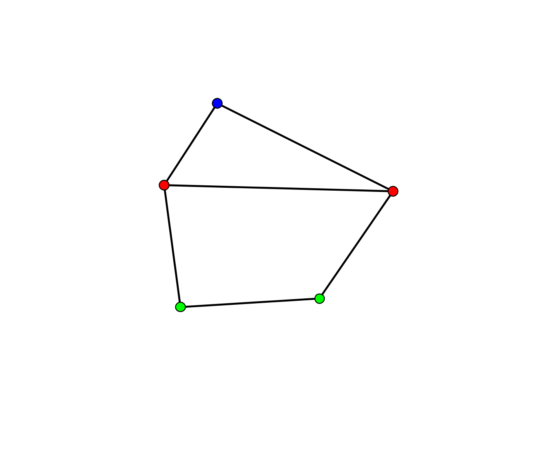
Para comprender la idea de esta área de las matemáticas, pensemos que un grafo es una colección de vértices junto con segmentos que los unen en una combinación dada, y es esta combinación lo que determina el grafo en particular. Por ejemplo un polígono: los triángulos, cuadrados y demás son grafos.
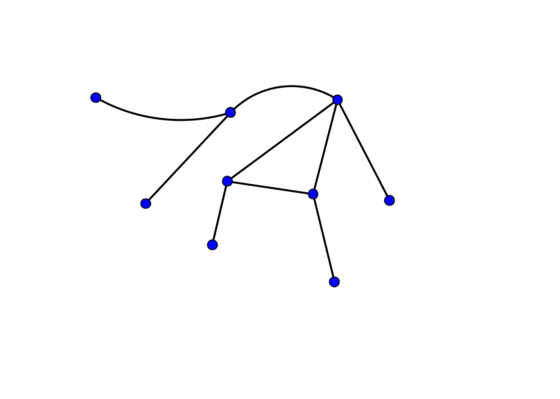 Ejemplo de grafo.
Ejemplo de grafo.
También es un grafo el diagrama del mapa del metro en una ciudad, si pensamos que cada estación es un vértice, que está unido con otro si es que hay una línea de metro entre las estaciones. Lo importante en un grafo es su estructura: el cómo se dan las conexiones, la combinación precisa, y no importan la longitud o la forma con que dibujemos sus segmentos. Es lo mismo que para el usuario del metro cuando lee el mapa, pues lo que le importa es saber si un par de vértices/estaciones dados están o no conectados.
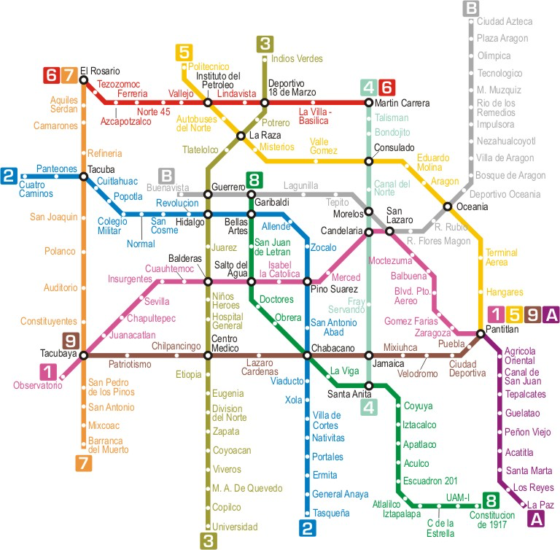 Mapa del metro de Ciudad de México, México D.F.
Mapa del metro de Ciudad de México, México D.F.
En teoría de grafos se estudian problemas planteados sobre estas estructuras, problemas que pueden ser geométricos, combinatorios, algebraicos o de otra índole. El tema en el que se interesó Frucht está relacionado con determinar el conjunto de automorfismos de un grafo, que son permutaciones entre los vértices que no cambian su estructura. Los automorfismos son una especie de simetrías del grafo respecto a sus conexiones, y son transformaciones que forman un grupo, pues se puede definir una operación entre dos de ellas: la composición, que consiste en aplicar una transformación y luego la otra. En el caso de un triángulo, es fácil ver que todas sus permutaciones son simetrías: ya sea realizar una especie de rotación entre los tres vértices o bien intercambiar dos de ellos como en una reflexión especular (el lector podrá determinar cuántos automorfismos hay).

Hacemos hincapié en que no es importante el largo o forma de los segmentos. Por ejemplo, el grafo con forma de pentágono mostrado abajo posee un solo automorfismo (además de la identidad), que consiste en intercambiar los vértices verdes uno con el otro, lo mismo que los vértices rojos también entre sí, dejando fijo el vértice de color azul.
Tras estudiar el libro de teoría de grafos, uno de los primeros resultados de Roberto fue determinar el grupo de automorfismos de algunos sólidos platónicos (equivalente tridimensional de los polígonos regulares). Un año más tarde, resolvió un problema mucho más importante: König había planteado en su libro la pregunta abierta si dado un grupo finito cualquiera, éste corresponderá necesariamente a los automorfismos de un grafo, el que habría que determinar. Esto significa pasar del álgebra a la geometría, algo así como dibujar el grupo dado por medio de su grafo. Frucht respondió afirmativamente a esta pregunta, y definió un procedimiento constructivo para determinar el grafo a partir del grupo dado, lo que se conoce como Teorema de Frucht. Además, encontró un grafo especial: uno que no posee ninguna simetría más que la identidad. A este grafo se le conoce como Grafo de Frucht y se ha convertido en un ejemplo clásico en el área. Es mostrado en la siguiente figura, donde se puede notar que cada vértice posee exactamente tres conexiones; de hecho este es el grafo más pequeño con tal estructura y que no tiene automorfismos.
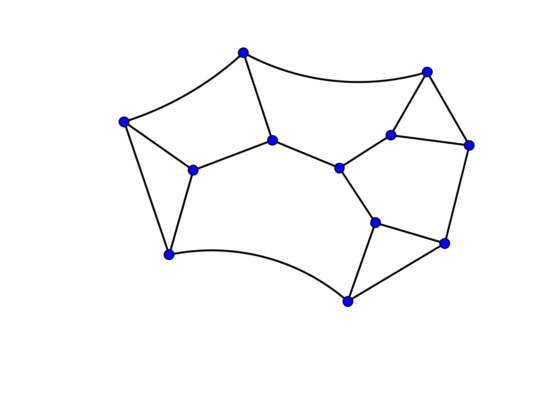 Grafo de Frucht
Grafo de Frucht
Frucht realizó estos trabajos entre 1936 y 1938, tristes años en Europa, en pleno auge del nazismo alemán y del fascismo italiano. Por esos años se aprobaron en Italia discriminadoras leyes raciales que complicaron la continuidad laboral de Roberto en Trieste. La familia, que ya incluía a su hija Érica, nacida en Trieste poco antes, decide mudarse a Argentina, donde vivían parientes de Mercedes. A principios de 1939 viajaron en el buque de vapor Augustus hasta el puerto de Buenos Aires, donde Frucht trabajó de nuevo en una compañía de seguros, pero también encontró la forma de seguir pensando en matemáticas, pues publicó varias notas sobre geometría diferencial en la revista de la Unión Matemática Argentina UMA, en ediciones bilingües en alemán y español.
De manera un tanto azarosa, la estadía en Buenos Aires llegó pronto a su fin, pues Roberto se encontró con la oportunidad de optar por una plaza como profesor en la UTFSM, institución que había sido recientemente creada y se abocaba a contratar un número de profesores extranjeros, sobre todo alemanes, para poder lograr rápidamente una masa crítica de académicos. Del Atlántico al Pacífico, seguramente la vida en el puerto de Valparaíso era más tranquila que en Trieste o Buenos Aires; en todo caso la familia se acostumbró sin dificultad a Valparaíso, excepto por los no poco frecuentes temblores, según Roberto contaba, un poco en tono de broma, a sus cercanos.
Roberto continuó publicando algunas notas sobre geometría diferencial y álgebra en revistas de la UMA, escritas en español y ahora con afiliación UTFSM. Retomó su trabajo en teoría de grafos gracias a una invitación del matemático Harold S.M. Coxeter para contribuir al recién creado Canadian Journal of Mathematics, para lo que se dispuso a trabajar contra el tiempo, y logró obtener interesantes refinamientos de sus resultados anteriores y publicar un artículo en 1949.
Durante las décadas que siguieron, Roberto Frucht continuó con su investigación en teoría de grafos y se convirtió en uno de los pioneros de la matemática en Chile. Fue decano de la Facultad de Ciencias de la universidad entre 1948 y 1968, director y miembro fundador de la Sociedad de Matemáticas de Chile SOMACHI, colaborador frecuente de la revista local Scientia, entre otras labores académicas, y en 1970 fue nombrado profesor emérito. Desde entonces y hasta poco antes de su fallecimiento en 1997 continuó impartiendo clases en la universidad, como aquella donde enseñó la formula de Euler y transmitió a sus alumnos, en las palabras del poeta que entonces ocupaba un pupitre de estudiante anónimo, la irremediable melancolía de lo que nos parece extremadamente bello.
Referencias:
Gary Chartrand, Ping Zhang. A First Course in Graph Theory. Dover Publications 2012.
R. Frucht. Herstellung von Graphen mit vorgegebener abstrakter Gruppe
Compositio Mathematica, tome 6 (1939), p. 239-250.
Robert Frucht. Graphs of degree three with a given abstract group. Canad. J. Math. 1 (1949), 365–378.
Roberto W. Frucht. (1982). How I became interested in graphs and groups. Journal of Graph Theory. 6(2), 101-104 https://doi.org/10.1002/jgt.3190060203
Harary, F. (1982). Homage to roberto frucht. Journal of Graph Theory, 6(2), 97–99. https://doi:10.1002/jgt.3190060202
Héctor Hevia. Grafos con grupo dado de automorfismos. Proyecciones Vol 14 No 2 (1995).
Iván Szántó, Betsabe González. Breve reseña histórica de la Revista Scientia y las publicaciones de Matemática en Chile. Boletín de la Asociación Matemática Venezolana, Vol. XXI, No. 1 (2014).
Reinhard Siegmund-Schultze. Mathematicians Fleeing from Nazi Germany Individual Fates and Global Impact. Princeton university press. 2009.
Raúl Zurita Canessa. No nos hemos perdido (Discurso). Cuadernos de Educación. Publicación Trimestral Gratuita – ISSN 0719-0271. N 35, 2016.
Sobre el autor: Alberto Mercado Saucedo es profesor de matemáticas en la Universidad Técnica Federico Santa María (Valparaíso, Chile)
Sobre la ilustradora: Constanza Rojas Molina es profesora del departamento de matemáticas de la CY Cergy Paris Université (Cergy-Pontoise, Francia)
El artículo Roberto Frucht, matemático en tránsito se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Ilustraciones artísticas de un matemático
- Pierre Fatou, un matemático poco (re)conocido
- Solomon Lefschetz, matemático ‘por accidente’
Los ecos del fondo submarino: imágenes de las estructuras geológicas.
Los fósiles, los minerales o las rocas son, entre otras cosas, en lo primero que pensamos al hablar de geología, pero lo cierto es que la física es un ámbito científico que difícilmente se puede desvincular de la geología. Y es que el fundamento físico resulta clave a la hora de explicar algunos procesos geológicos que suceden tanto en el océano como en la superficie terrestre.
Con el fin de poner sobre la mesa la estrecha relación entre la geología y la física, los días 27 y 28 de noviembre de 2019 se celebró la jornada divulgativa “Geología para poetas, miopes y despistados: La Geología también tiene su Física”. El evento tuvo lugar en la Sala Baroja del Bizkaia Aretoa de la UPV/EHU en Bilbao.
La segunda edición de esta iniciativa estuvo organizada por miembros del grupo de investigación de Procesos Hidro-Ambientales (HGI) de la Facultad de Ciencia y Tecnología de la Universidad del País Vasco, en colaboración con el Vicerrectorado del Campus de Bizkaia, el Geoparque de la Costa Vasca y la Cátedra de Cultura Científica de la UPV/EHU.

Gemma Ercilla, investigadora del CSIC en el Instituto de Ciencias del Mar (Barcelona), nos explica cómo estudiar el fondo marino usando el sonido y que podemos aprender de este estudio.
Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Los ecos del fondo submarino: imágenes de las estructuras geológicas. se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Otra mirada al planeta: arte y geología
- Geología: la clave para saber de dónde venimos y hacia dónde vamos
- Geología, ver más allá de lo que pisamos
La topología frágil es una extraño monstruo
Los electrones circulan sobre la superficie de ciertos materiales cristalinos inusuales, los aislantes topológicos, excepto las veces que no lo hacen. Dos nuevos estudios publicados en la revista Science explican la fuente de ese insólito comportamiento y describen un mecanismo para restaurar la conductividad en estos cristales, apreciados por su potencial uso en futuras tecnologías, incluyendo los ordenadores cuánticos.
 Los aislantes topológicos tienen un lado frágil. Imagen cortesía de Zhi-Da Song, Universidad de Princeton.
Los aislantes topológicos tienen un lado frágil. Imagen cortesía de Zhi-Da Song, Universidad de Princeton.Durante los últimos 15 años, una clase de materiales conocidos como aislantes topológicos ha dominado la búsqueda de los materiales del futuro. Estos cristales tienen una propiedad poco común: su interior es aislante —los electrones no pueden fluir—, pero sus superficies son conductoras perfectas, donde los electrones fluyen sin resistencia.
Esa era la realidad hasta que hace dos años se descubrió que algunos materiales topológicos son incapaces de conducir la corriente en su superficie, un fenómeno que se acuñó con el nombre de «topología frágil».
«La topología frágil es una extraño monstruo: ahora se predice su existencia en cientos de materiales», comenta B. Andrei Bernevig, profesor de física en Princeton y coautor de ambos trabajos. «Es como si el principio habitual en el que nos hemos basado para determinar experimentalmente un estado topológico se desmoronara”.
Para conocer cómo se forman los estados frágiles, los investigadores recurrieron a dos recursos: las ecuaciones matemáticas y la impresión 3D. Con la colaboración de Luis Elcoro, profesor del Departamento de Física de la Materia Condensada de la Facultad de Ciencia y Tecnología de la UPV/EHU, Bernevig y el investigador postdoctoral de Princeton Zhi-Da Song, construyeron una teoría matemática para explicar lo que ocurre en el interior de los materiales. A continuación, Sebastian Huber y su equipo en el ETH Zurich, en colaboración con investigadores de Princeton, el Instituto Científico Weizmann en Israel, la Universidad Tecnológica del Sur de China y la Universidad de Wuhan, probaron esa teoría construyendo un material topológico de tamaño real con piezas de plástico impresas en 3D.
Los materiales topológicos toman su nombre del campo de las matemáticas que explica cómo objetos diferentes, por ejemplo las rosquillas o las tazas de café, están relacionadas (ambas tienen un agujero). Esos mismos principios pueden explicar cómo saltan los electrones de un átomo a otro en la superficie de los aproximadamente 20.000 materiales topológicos identificados hasta la fecha. Los fundamentos teóricos de los materiales topológicos les valieron el Premio Nobel de Física de 2016 a F. Duncan Haldane, David J. Thouless y Michael Kosterlitz.
Lo que hace que estos cristales sean tan interesantes para la comunidad científica son sus paradójicas propiedades electrónicas. El interior del cristal no tiene la capacidad de conducir la corriente, es un aislante. Pero si se corta el cristal por la mitad, los electrones se deslizarán sin ninguna resistencia por las superficies que acaban de surgir, protegidos por su naturaleza topológica.
La explicación radica en la conexión entre los electrones de la superficie y los del interior. Los electrones pueden ser considerados no como partículas individuales, sino como ondas que se extienden como las ondas de agua que se generan al arrojar un guijarro a un estanque. En esta visión de la mecánica cuántica, la ubicación de cada electrón se describe por una onda que se extiende y que se denomina función de onda cuántica. En un material topológico, la función de onda cuántica de un electrón del interior se extiende hasta el borde del cristal, o límite de la superficie. Esta conexión entre el interior y el borde da lugar a un estado en la superficie perfectamente conductor.
Esta “correspondencia de interior-borde (bulk-boundary correspondence en inglés)” fue ampliamente aceptada para explicar la conducción topológica de la superficie hasta hace dos años, cuando varios trabajos científicos revelaron la existencia de la topología frágil. A diferencia de los estados topológicos habituales, los estados topológicos frágiles no contienen estados de conducción en la superficie. «El habitual principio de interior-borde se desmoronó», explica Bernevig. Pero no se pudo esclarecer cómo sucede exactamente.
En el primero de los dos trabajos publicados en Science, Bernevig, Song y Elcoro proporcionan una explicación teórica para una nueva correspondencia interior-borde que explica la topología frágil. Los autores muestran que la función de onda de los electrones en topología frágil solo se extiende hasta la superficie en condiciones específicas, que los investigadores han acuñado como correspondencia interior-borde retorcida.
El equipo descubrió, además, que se puede ajustar esa correspondencia interior-borde retorcida, y así hacer reaparecer los estados conductores de la superficie. «Basándonos en las formas de la función de onda, diseñamos un conjunto de mecanismos para introducir interferencias en el borde de tal manera que el estado del borde se convierta inevitablemente en conductor perfecto», comenta Luis Elcoro, profesor de la UPV/EHU.
Encontrar nuevos principios generales es algo que siempre fascina a los físicos, pero este nuevo tipo de correspondencia interior-borde podría además tener un valor práctico, según los investigadores. «La correspondencia interior-borde retorcida de la topología frágil proporciona un procedimiento potencial para controlar el estado de la superficie, que podría ser útil en aplicaciones de mecánica, electrónica y óptica», declara Song.
Pero probar que la teoría funciona era prácticamente imposible, dado que se tendría que interferir en los bordes a escalas atómicas infinitesimalmente pequeñas. Así que el equipo recurrió a otros colaboradores para construir un modelo de tamaño real con el que poner a prueba sus ideas.
En el segundo artículo de Science, Sebastian Huber y su equipo en el ETH Zurich construyeron la imitación en plástico de un cristal topológico a gran escala imprimiendo sus partes en impresoras 3D. Utilizaron ondas de sonido para representar las funciones de onda de los electrones. Insertaron barreras para bloquear el tránsito de las ondas sonoras, lo que es análogo a cortar el cristal para dejar al descubierto las superficies conductoras. De esta manera, los investigadores imitaron la condición de borde retorcido, y luego mostraron que manipulándolo, podían demostrar que una onda sonora que circula libremente se propaga a través de la superficie.
«Esta fue una idea y una ejecución muy de vanguardia», añade Huber. «Ahora podemos mostrar que prácticamente todos los estados topológicos que se han materializado en nuestros sistemas artificiales son frágiles, y no estables como se pensaba en el pasado. Este trabajo proporciona esa confirmación, pero aún más, introduce un nuevo principio general».
Referencias:
Valerio Peri, Zhi-Da Song, Marc Serra-Garcia, Pascal Engeler, Raquel Queiroz, Xueqin Huang, Weiyin Deng, Zhengyou Liu, B. Andrei Bernevig, and Sebastian D. Huber (2020) Experimental characterization of fragile topology in an acoustic metamaterial Science doi: 10.1126/science.aaz7654
Zhi-Da Song, Luis Elcoro, B. Andrei Bernevig (2020) Twisted Bulk-Boundary Correspondence of Fragile Topology Science doi: 10.1126/science.aaz7650
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo La topología frágil es una extraño monstruo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Aislantes topológicos en sólidos amorfos
- La teoría de bandas de los sólidos se hace topológica
- Un aislante topológico intrínsecamente magnético
Así funcionan las baterías de litio
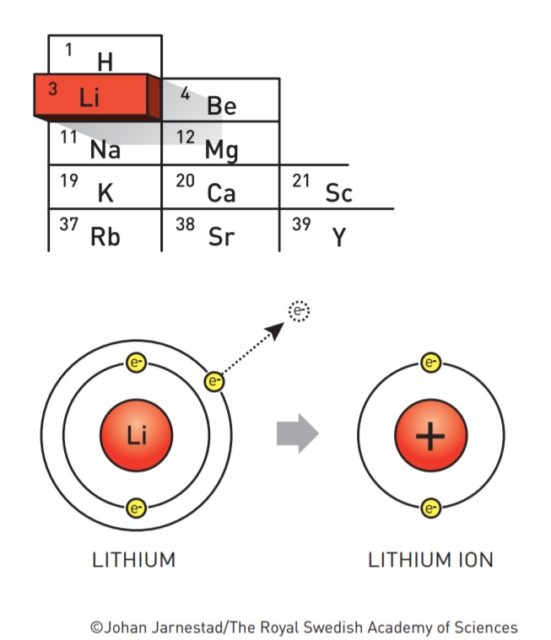
Antes de que se empezasen a fabricar baterías de litio ya se fantaseaba con la idea de poder hacer baterías de litio. La razón es que el litio es un metal que tiene tendencia a desprenderse de su electrón más externo. Al fin y al cabo, la electricidad es el tránsito de electrones, así que para producir electricidad necesitamos sustancias que tiendan a desprenderse de ellos.
 Fuente: nobelprize.org
Fuente: nobelprize.org
El litio es el metal con el menor potencial de reducción (-3,05V). Esto significa que es el elemento químico que más tendencia tiene a regalar electrones. Cuando regala su electrón más externo, el litio se queda cargado positivamente. Lo representamos como Li+ y lo llamamos ion litio. De ahí que las baterías de litio también se llamen baterías de ion-litio.
Que el litio ceda electrones con tanta alegría obviamente es una ventaja, pero al mismo tiempo es una maldición. Cede electrones a cualquiera. Al aire, al agua, a todo. Esto significa que es un metal muy inestable, que se oxida rápidamente en contacto con el aire, y que en contacto con el agua reacciona de forma violenta. Esa es la razón por la que la historia de las baterías de litio no ha sido un camino de rosas.
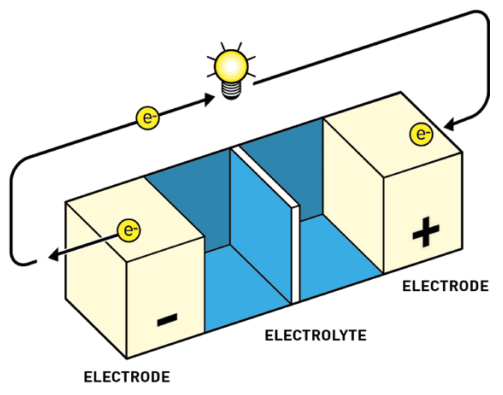
Las baterías tienen todas un mismo esquema fundamental:
-
Ánodo o electrodo negativo. Aquí es donde alguna sustancia se desprende de electrones. A estas reacciones de pérdida de electrones las denominamos reacciones de oxidación. Por convenio, al representar baterías o pilas el ánodo se dibuja a la izquierda.
-
Cátodo o electrodo positivo. Aquí es donde alguna sustancia acepta los electrones. A estas reacciones de captura de electrones las denominamos reacciones de reducción. Es la reacción inversa a la oxidación. Por convenio, al representar baterías o pilas el cátodo se dibuja a la derecha.
-
Electrolito. El electrolito actúa como separador entre el cátodo y el ánodo. Sirve para mantener el equilibrio entre las cargas del ánodo y el cátodo, ya que, si los electrones fluyen de ánodo a cátodo, se produce una diferencia de potencial, algo así como una descompensación de cargas, que frena el flujo de más electrones. El electrolito permite el flujo de iones (no de electrones) que reequilibran la carga entre ambos lados.
El ánodo y el cátodo están unidos en la batería por medio del electrolito. También se unen por fuera por medio de un conductor externo a través del cual solo circulan electrones. El conductor tiene dos extremos, polo positivo y polo negativo, como cualquier pila. Así que por el electrolito fluyen los iones de litio de un extremo a otro, y por el conductor externo fluyen los electrones.
En las baterías recargables las reacciones de oxidación (ceder electrones) y reducción (captar electrones) son reversibles, pueden fluir en ambas direcciones.
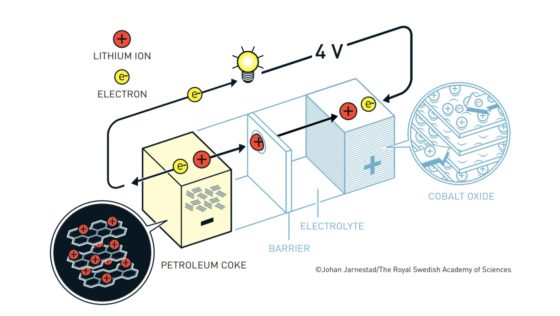 Batería Yoshino. Fuente: nobelprize.org
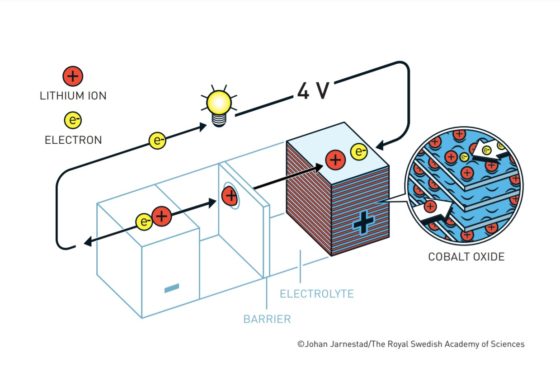
Batería Yoshino. Fuente: nobelprize.orgLas baterías de ion litio actuales más habituales tienen un cátodo de óxido de cobalto y un ánodo de un material similar al grafito denominado coque. Tanto el cátodo como en el ánodo tienen una disposición laminar en la que pueden albergar al litio. El litio viajará de cátodo a ánodo o de ánodo a cátodo a través del electrolito según el ciclo de carga o descarga. Los electrones, en cambio, circularán a través de un circuito externo.
-
Esto es lo que ocurre cuando se usa la batería
Cuando la batería está cargada, todo el litio está en el ánodo de coque. Durante la descarga los iones fluyen a través del electrolito desde el ánodo de coque hacia al cátodo de óxido de cobalto-litio. Los electrones también fluyen desde el ánodo al cátodo, pero lo hacen a través del circuito exterior, alimentando el móvil, el ordenador o el coche.
Como los iones de litio en el coque están a un potencial electroquímico más alto que en el óxido de cobalto-litio, caen desde el potencial del ánodo al potencial del cátodo. Esa es la razón por la que la batería aporta energía al aparato al que esté conectada.
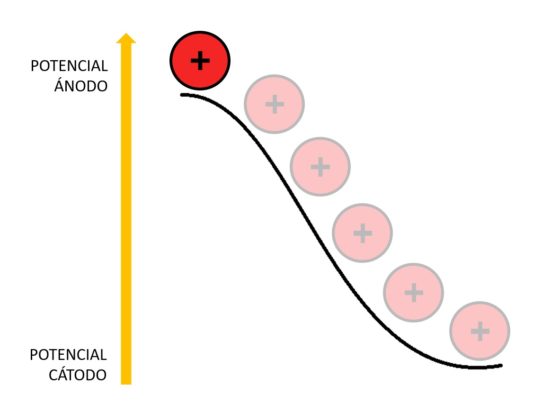 Imagen: Deborah García Bello
Imagen: Deborah García Bello
El voltaje ofrecido por la batería depende de la diferencia de potencial entre el cátodo y el ánodo. Cuanto mayor sea esta diferencia, mayor voltaje obtendremos.
Cuando todos los iones de litio llegan al cátodo, la batería estará completamente descargada.
-
Esto es lo que ocurre cuando cargamos la batería
La carga de la batería se realiza conectando la batería a una fuente de energía externa como la red eléctrica. Los electrones de la red eléctrica entran en el ánodo a través del circuito externo. Esto provoca que los iones de litio abandonen el cátodo y regresen al ánodo a través del electrolito. Tanto los electrones como los iones litio se quedan acomodados en el ánodo entre las diferentes capas de coque. Cuando no fluyen más indica que la batería está completamente cargada.
La batería almacena energía en este proceso porque el potencial electroquímico del coque es más elevado que el del óxido de cobalto-litio. Esto quiere decir que los iones de litio han tenido que subir desde el potencial del cátodo hasta el potencial del ánodo.
-
Las evolución de las baterías de litio
A lo largo de la historia se han creado diferentes baterías. La de Volta, de 1800, usaba como electrodos zinc y cadmio, llegando a obtener hasta 1,1 V. Las baterías de plomo-ácido que hoy en día se utilizan en muchos coches producen 2 V cada una. Se suelen colocar 6 para producir los habituales 12V. También hay baterías de níquel-hierro (NiFe), de niquel-cadmio (NiCd), de níquel-hidruro metálico (NiMH)…
El problema que presentan estas baterías es que contienen metales tóxicos como el plomo o el cadmio. Además, ofrecen densidades energéticas relativamente bajas. Cuanto mayor sea la densidad de energía, más energía habrá disponible para acumular o transportar (por volumen o por masa). Así, las baterías de plomo-ácido ofrecen 30 Wh/kg de densidad energética, las de NiFe 40 Wh/kg, las de NiCd 50 Wh/kg y las de NiMH 80 Wh/kg. En cambio, las de ion litio ofrecen al menos 120 Wh/kg y un voltaje mayor, de 4,2 V. Hay que tener en cuenta que las pilas alcalinas clásicas, las AA, solo ofrecen 1,5 V. Por eso las baterías de litio son tan compactas y los teléfonos móviles se han aligerado tanto.
El boom en la carrera investigadora de las baterías de litio se desató en los 70 a causa de la crisis del petróleo. Estaba claro que el ánodo perfecto tendría que ser de litio. Ahora faltaba descubrir el cátodo perfecto.
La primera batería de ion litio tenía un cátodo de sulfuro de litio y titanio (LixTiS2) que era capaz de acomodar en su interior los iones de litio que llegaban desde el ánodo. El ánodo era de litio metálico, y el electrolito era de LiPF6 disuelto en carbonato de propileno. En este electrolito el litio estaba protegido tanto del agua como del aire, ganando estabilidad. Así se lograban 2,5 V. La primera batería de litio comercial fue una evolución de esta, desarrollada por la empresa Exxon. En ella se usaba litio como ánodo, TiS2 como cátodo y perclorato de litio (LiClO4) disuelto en dioxolano como electrolito.
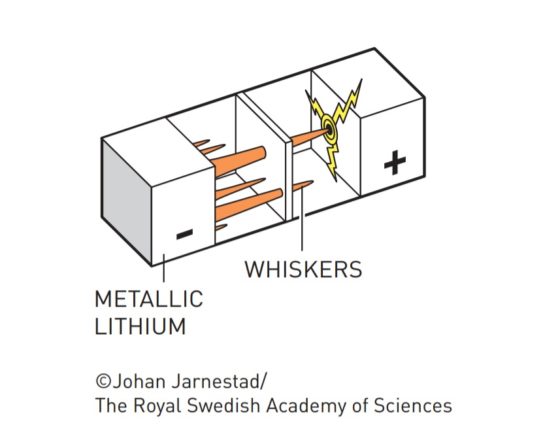 Dendritas («whiskers»). Fuente: nobelprize.org
Dendritas («whiskers»). Fuente: nobelprize.org
Pero se encontraron con un problema: cuando estas baterías se sobrecalentaban, llegaban a explotar. Descubrieron que lo que ocurría es que tras cada ciclo de carga y descarga se iban formando dendritas de litio que traspasaban la barrera de electrolito hasta llegar al cátodo, produciendo así un cortocircuito.
El problema parecía resolverse usando un ánodo diferente. En lugar de un sulfuro metálico, se probó con un óxido metálico, en concreto el dióxido de cobalto (CoO2) que, combinado con el litio se denomina óxido de cobalto-litio (LiCoO2). El LiCoO2 tiene un potencial de reducción tan alto, que ni siquiera hacía indispensable el uso de litio metálico puro como ánodo, sino que podría usarse otra sustancia que acomodase al litio de forma más estable y segura.
 Batería Goodenough. Fuente: nobelprize.org
Batería Goodenough. Fuente: nobelprize.org
La respuesta llegaría en 1985 de la mano de la corporación japonesa Asahi Kasei. Descubrieron que el coque de petróleo —un sólido carbonoso derivado del refinado del petróleo— era capaz de acomodar al litio de forma muy eficiente. En muchos textos se le llama grafito. Es cierto que se le parece, pero no es exactamente grafito, sino un material de carbono que presenta dominios cristalinos grafíticos —en capas— y dominios no cristalinos. Entre unos y otros se acomodan los iones de litio.
 Imagen: Litio en coque de petróleo. Fuente: nobelprize.org
Imagen: Litio en coque de petróleo. Fuente: nobelprize.org
En 1991, la empresa Sony, en colaboración con Asahi Kasei, sacaron a la venta la primera batería ion litio comercial con ánodo de óxido de cobalto-litio y cátodo de coque. El hecho de que los iones de litio entren y salgan ordenadamente en el ánodo y en el cátodo, forzados por las estructuras bidimensionales del coque y del óxido del cobalto, garantiza que las baterías apenas tengan efecto memoria. Es decir, las podemos cargar sin esperar a que se hayan descargado completamente sin miedo a que la batería se vicie.
En la actualidad se producen baterías de litio con cátodos todavía más eficientes. Como el cobalto es un elemento químico caro y relativamente escaso, el óxido de cobalto-litio se ha sustituido por el de fosfato de hierro-litio (LiFePO4) haciéndolas más baratas de producir. Se conocen como LFP, y adoptan estructuras cristalográficas diferentes. La de LFP con estructura tipo olivino es la que en la actualidad comercializa Sony. Puede durar 10 años si se carga a diario, cuando normalmente no sobrepasaban los 3-4 años. También tienen carga rápida, ya que en 2 h cargan el 95% de su capacidad.
En 2019 el desarrollo de las baterías de ion litio logró el Premio Nobel de Química repartido a partes iguales entre el alemán John B. Goodenough, el británico M. Stanley Whittingham, y el japonés Akira Yoshino. Whittingham fue quien lideró la investigación en la electrointercalación de iones de litio en disulfuros metálicos en los años 70. John Goodenough, que trabajó para Exxon, en los años 80 fue quien propuso la solución a que las baterías explotasen cuando se calentaban. Lo resolvió con el cátodo de óxido de cobalto-litio. Akira Yoshino, que trabajaba para la Corporación Asahi Kasei, en 1985 propuso el ánodo de coque.
La investigación actual en baterías de ion-litio se fundamenta en mejorar su eficiencia y el número ce ciclos de carga y descarga que pueden soportar. Se está experimentando con baterías de dióxido de carbono y litio, aunque hay expertos que aseguran que el futuro estará en el litio-grafeno.
Referencias:
They developed the world’s most powerful battery. Nobelprice.org.
Scientific Background on the Nobel Prize in Chemistry 2019 LITHIUM-ION BATTERIES. Nobelprize.org.
Baterías de iones litio, ¿cómo son?. Por Ignacio Mártil en CdeComunicación
Premio Nobel de Química 2019: Goodenough, Whittingham y Yoshino por las baterías de ión-litio. Por Francis Villatoro en La ciencia de la mula Francis.
Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo Así funcionan las baterías de litio se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Baterías de litio y oxígeno sólido
- Las baterías ion sodio, la alternativa estacionaria
- ADN para la nueva generación de baterías
Teselando el plano con pentágonos
 Imagen: Osckar Espinosa / Pixabay
Imagen: Osckar Espinosa / Pixabay
Una teselación o mosaico del plano consiste en una serie de polígonos –las teselas o losetas– que lo cubren sin dejar zonas vacías, de manera que si dos teselas se tocan, lo hacen necesariamente lado con lado o vértice con vértice.
En su obra Harmonice mundi el astrónomo Johannes Kepler estudió qué polígonos regulares podían cubrir el plano. Es decir, se preguntaba si existen mosaicos que utilicen un polígono regular como única tesela base. La respuesta es sencilla: los únicos que existen son los mosaicos por triángulos, cuadrados y hexágonos regulares.
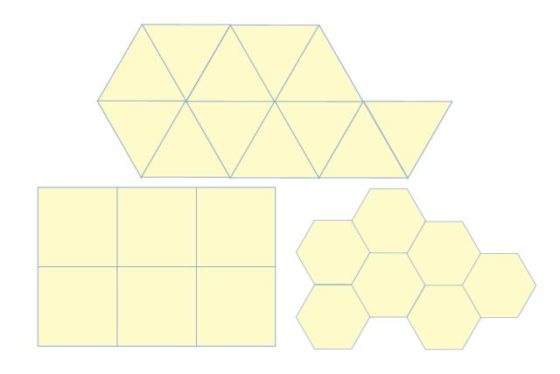 Teselando el plano con triángulos, cuadrados y hexágonos regulares. Imagen: Wikimedia Commons.
Teselando el plano con triángulos, cuadrados y hexágonos regulares. Imagen: Wikimedia Commons.
¿Por qué no hay más? Por ejemplo, en el caso del pentágono regular, su ángulo interno es de 108 grados. Si deseáramos teselar el plano con pentágonos regulares, los vértices de dos losetas colindantes deberían tocarse sin dejar ningún hueco. Pero esto imposible, ya que 360 no es divisible por 108. De otra manera, si colocamos pentágonos regulares alrededor de un vértice, se observa en seguida que solo pueden colocarse tres, pero queda un espacio que no puede cubrirse con pentágonos.
Recordemos que un polígono regular de n lados posee ángulos internos de 180(n-2)/n grados. Así, para polígonos con siete o más lados, el ángulo interior es mayor que 120 grados pero menor que 180, con lo que llegamos a la misma conclusión que con el pentágono. Es decir, el triángulo, el cuadrado y el hexágono (regulares) son los únicos polígonos regulares cuyos ángulos internos (60 grados, 90 grados y 120 grados, respectivamente) son divisores de 360 grados.
En el estudio de mosaicos podríamos proseguir preguntarnos qué sucede al mezclar varios polígonos regulares para cubrir el plano –teselaciones semirregulares, de estos solo hay ocho–, o al usar una única pieza no regular, o al utilizar varias no regulares. Estos problemas no son sencillos de resolver. Cuando su estudio comenzó a sistematizarse llevó al desarrollo de técnicas matemáticas complejas aplicadas al estudio de teselaciones del plano (y del espacio) que después han encontrado utilidad en otros campos.
Vamos a elegir uno de estos problemas tomando el pentágono como pieza clave. La pregunta que nos planteamos es: ¿se puede teselar el plano con un único pentágono (convexo) no regular? La respuesta es que se puede, y además existen solo quince maneras de hacerlo –parece casi seguro que esta es la cantidad, aunque está en fase de revisión–.
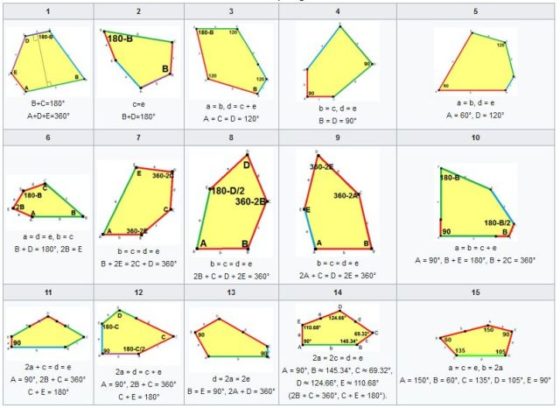 Los quince tipos de pentágonos convexos que teselan el plano. Se denotan con letras minúsculas los lados de cada pentágono a, b, c, d, e y con letras mayúsculas los ángulos internos. Imagen: Wikimedia Commons.
Los quince tipos de pentágonos convexos que teselan el plano. Se denotan con letras minúsculas los lados de cada pentágono a, b, c, d, e y con letras mayúsculas los ángulos internos. Imagen: Wikimedia Commons.
Citamos a continuación a las personas que han descubierto estas quince clases de pentágonos: Karl Reinhardt(1895-1941)encontró cinco en 1918 (ver [1]);Richard B. Kershner (1913-1982) halló tres más en 1968 (ver [2]); Richard James descubrió el noveno tipo en 1975 tras leer un artículo de Martin Gardner sobre teselaciones pentagonales en la revista Scientific American; ese artículo también inspiró a Marjorie Rice (1923-2017) quien halló otros cuatro tipos en 1976 y 1977 (ver [3] y [4]); Rolf Stein (ver [5]) encontró el decimocuarto tipo de pentágono en 1985; y en 2015 Casey Mann, Jennifer McLoud y David Von Derau descubrieron una nueva clase (ver [6]) con ayuda de un programa informático.
El 1 de mayo de 2017 Michaël Rao anunció (ver [7]) que había realizado una prueba asistida por ordenador en la que demostraba que estos quince pentágonos convexos eran los únicos que teselaban el plano con un único tipo de loseta. La parte computacional de su demostración ha sido revisada y no contiene errores, aunque aún no se ha publicado la prueba definitiva revisada por pares.
De este grupo de personas, algunas no son matemáticas. Richard James es informático y Marjorie Rice matemática aficionada. Ambos se enamoraron de este problema leyendo el artículo de Martin Gardner indicado anteriormente. Y emprendieron su búsqueda en solitario.
El caso de Marjorie es muy especial: aunque no tenía formación en matemáticas, desarrolló su propio sistema de notación para representar las restricciones y las relaciones entre los lados y ángulos de los pentágonos que estaba intentando encontrar. Fue la matemática Doris Schattschneider quien descifró la notación de Marjorie Rice y quien se ocupó de difundir sus descubrimientos entre la comunidad matemática. En la página Intriguing Tesselations, Marjorie Rice mostraba con orgullo sus descubrimientos y algunos mosaicos decorativos que diseñó a partir de ellos. ¡Admirable!
Referencias:
[1] Karl Reinhardt.Über die Zerlegung der Ebene in Polygone, Dissertation Frankfurt am Main (1918), páginas 77-81
[2] Richard Kershner. On paving the plane, American Mathematical Monthly 75 (8) (1968) 839-844
[3] Doris Schattschneider.Tiling the plane with congruent pentagons, Mathematics Magazine 51 (1) (1978) 29-44
[4] Marjorie Rice. Tesselations, Intriguing Tesselations
[5]Doris Schattschneider. A new pentagon tiler, Mathematics Magazine 58 (5) (1985) 308
[6] Casey Mann, Jennifer McLoud-Mann, David Von Derau, Convex pentagons that admit i-block transitive tilings. arXiv:1510.01186(publicado posteriormente en Geometriae Dedicata 194 (2018)141-167)
[7] Michael Rao.Exhaustive search of convex pentagons which tile the plane. arXiv:1708.00274
[8] Natalie Wolchover. Pentagon Tiling Proof Solves Century-Old Math Problem. Quanta Magazine, 11 julio 2017
[9] Pedro Alegría. El caso de los 14 pentágonos que embaldosan un espacio infinito. ABC Ciencia, 10 abril 2017
[10] Teselados pentagonales, Wikipedia [consultado 15 febrero 2020]
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Teselando el plano con pentágonos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El teorema de los cuatro colores (2): el error de Kempe y la clave de la prueba
- Shizuo Kakutani y sus teoremas
- La característica de Euler de una superficie: un invariante topológico
El principio de complementareidad
 Foto: Leonardo Yip / Unsplash
Foto: Leonardo Yip / UnsplashLa mecánica cuántica se fundó sobre la existencia de la dualidad onda-corpúsculo de la luz y la materia, y el enorme éxito de la mecánica cuántica, incluida la interpretación de probabilidad, parece reforzar la importancia de esta dualidad. Pero, ¿cómo puede considerarse un corpúsculo como que «realmente» tenga propiedades de onda? ¿Y cómo puede pensarse que una onda tenga «realmente» propiedades de corpúsculo?
Se podría construir una mecánica cuántica consistente sobre la idea de que un haz de luz o un electrón pueden describirse simultáneamente por los conceptos incompatibles de onda y corpúsculo. En 1927, sin mebargo, Niels Bohr se percató de que precisamente la palabra «simultáneamente» era la clave para mantener la coherencia. Se dio cuenta de que nuestros modelos, o imágenes, de la materia y la luz se basan en su comportamiento en distintos experimentos en nuestros laboratorios. En algunos experimentos, como el efecto fotoeléctrico o el efecto Compton, la luz se comporta como si constara de partículas; en otros experimentos, como el experimento de doble rendija, la luz se comporta como si estuviera formada por ondas. Del mismo modo, en experimentos como el de J.J. Thomson con los rayos catódicos, los electrones se comportan como si fueran partículas; en otros experimentos, como los estudios de difracción de su hijo G.P. Thomson, los electrones se comportan como si fueran ondas. Pero la luz y los electrones nunca se comportan simultáneamente como si estuviesen constituidos por partículas y ondas. En cada experimento específico se comportan como corpúsculos o como ondas, pero nunca como ambos.
Esto le sugirió a Bohr que las descripciones corpusculares y ondulatorias de la luz y de la materia son ambas necesarias aunque sean lógicamente incompatibles entre sí. Deben considerarse como «complementarias» entre sí, es decir, como dos caras diferentes de la misma moneda. Esto llevó a Bohr a formular lo que se llama el principio de complementariedad:
Los dos modelos, corpuscular y ondulatorio, son necesarios para una descripción completa de la materia y de la radiación electromagnética. Dado que estos dos modelos son mutuamente excluyentes, no se pueden usar simultáneamente. Cada experimento, o el experimentador que diseña el experimento, selecciona una u otra descripción como la descripción adecuada para ese experimento.
Bohr demostró que este principio es una consecuencia fundamental de la mecánica cuántica. Afrontó la cuestión de la dualidad onda-corpúsculo, no resolviéndola a favor de ondas o partículas, sino incorporándola en los cimientos mismos de la física cuántica. Al igual que hizo con su modelo de átomo, Bohr transformó una dificultad en la base del sistema, a pesar de que esto supusiese contradecir la física clásica.
Es importante comprender qué significa realmente el principio de complementariedad. Al aceptar la dualidad onda-corpúsculo como un hecho de la naturaleza, Bohr lo que afirmaba es que la luz y los electrones (u otros objetos) tienen potencialmente las propiedades de las partículas y las ondas, hasta que se observan, momento en el que se comportan como si fueran una cosa u otra, dependiendo del experimento y la elección del experimentador. Esta era una afirmación de una enorme importancia, porque significaba que lo que observamos en nuestros experimentos no es lo que la naturaleza realmente es cuando no la estamos observando.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo El principio de complementareidad se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El principio de incertidumbre, cualitativamente
- El comportamiento corpuscular de la luz: el efecto Compton
- El principio de incertidumbre, cuantitativamente
Sesgos ideológicos que aquejan a la ciencia
 Mapa de la previsión de la trayectoria del huracán Dorian alterado para que se ajustase a las declaraciones de Donald Trump en el sentido de que podía afectar a Alabama.
Mapa de la previsión de la trayectoria del huracán Dorian alterado para que se ajustase a las declaraciones de Donald Trump en el sentido de que podía afectar a Alabama.Los cognitivos no son los únicos sesgos que afectan al desarrollo de la ciencia. También hay sesgos ideológicos. Quienes se dedican a la investigación científica no son ajenos a la influencia de la cosmovisión, la ideología, las creencias, etc., y esos factores inciden en el desarrollo de la ciencia o en aspectos colaterales a la misma aunque de importantes repercusiones sociales. Los científicos llevados por sus creencias se ven afectados por sesgos (inconscientes, no serían casos de mala ciencia voluntaria) que les llevan realizar una actividad científica poco rigurosa (eligiendo datos -cherry picking- , interpretándolos, etc.) en la dirección de sostener con sus conclusiones científicas lo que ya creían antes de comenzar. El “razonamiento motivado” a que se ha hecho mención en la anotación anterior estaría en la base cognitiva de este comportamiento y la motivación sería un fuerte convencimiento ideológico.
En lo que a este aspecto se refiere y antes de poner algunos ejemplos ilustrativos, conviene advertir de que la incidencia de los sesgos es mayor cuanto más complejos son los sistemas que se estudian, más son las variables en juego y más difícil resulta aislar los efectos de los factores cuyo efecto se desea establecer empíricamente. La ciencia funciona a partir de la identificación de regularidades en los sistemas que estudia, pero esa identificación arroja mayores garantías cuando el sistema permite fijar o excluir factores que pueden incidir en ellas de forma incontrolada y limitar el análisis al efecto de aquellos que pueden ser modificados a voluntad o, al menos, medidos con precisión. La física es, en ese sentido, la disciplina cuyas observaciones ofrecen mayores garantías pues los sistemas que estudia son fácilmente acotables. Y a las ciencias sociales les ocurre lo contrario: es muy difícil eliminar factores de confusión y fijar con garantías los factores que se desea analizar. Y cuando es especialmente difícil descartar factores de confusión y fijar o controlar efectos de unas pocas variables, queda un amplio margen para la influencia de las motivaciones de carácter ideológico, tanto en el diseño de las investigaciones como en el posterior análisis de los resultados.
Quizás los antecedentes más antiguos del efecto de los sesgos ideológicos se remontan a los mismos orígenes de la ciencia moderna. En la controversia acerca del heliocentrismo o la naturaleza geométrica de las órbitas de los planetas (del movimiento de los cuerpos celestes, al fin y al cabo) ejercieron un efecto claro las creencias de sus protagonistas.
Algunos de los sesgos tuvieron carácter general en ciertas épocas. Las ideas de superioridad de la (supuesta) “raza blanca” o de las personas de origen caucásico con respecto a otras (supuestas) “razas” o procedencias condicionaron la investigación que se hizo en las épocas en que eran predominantes. Los prejuicios en relación con la capacidad de las mujeres para desempeñar roles considerados masculinos han ejercido una influencia muy fuerte en fechas relativamente recientes e, incluso, hoy lo siguen ejerciendo. Marlenne Zuk (2013) ha revisado críticamente algunas ideas muy extendidas acerca del (supuesto) “origen evolutivo” de las diferencias entre hombres y mujeres y ha refutado las bases de algunas de ellas.
Las creencias religiosas han alimentado actitudes claramente anticientíficas. En la actualidad el ejemplo más claro, quizás, de esta actitud es el del bioquímico Michael J. Behe, profesor de la Universidad de Lehigh, en Pensilvania (EEUU). Behe se opone a la teoría de la evolución por selección natural y defiende el llamado “diseño inteligente” que es, en realidad, una forma sofisticada de creacionismo. Según Behe, ciertas estructuras bioquímicas son demasiado complejas como para poder ser explicadas en virtud de los mecanismos de la evolución. Desarrolló el concepto de “complejidad irreducible” como un “sistema individual compuesto de varias partes bien coordinadas que interaccionan para desempeñar la función básica de este, de modo que si se eliminara cualquiera de esas partes dejaría de funcionar por completo”.
La ideología política puede tener también una influencia notable. No solo entre el púbico general, también en la comunidad científica la negación del cambio climático, en sus diferentes modalidades, está vinculada al campo conservador. La base ideológica está aquí relacionada con lo que podría considerarse una visión “optimista” del mundo, según la cual la naturaleza no tiene límites, ni desde el punto de vista de la disponibilidad o existencia de los recursos naturales, ni de la capacidad para asimilar la influencia de las actividades humanas. Esa visión optimista, junto con el hecho de que los efectos que se le atribuyen al cambio climático nos remiten a un futuro que se percibe como indefinido, neutraliza el peso de los argumentos y datos en que se basa el consenso científico al respecto.
Las actitudes anticientíficas más características de la izquierda suelen estar relacionadas con cuestiones de carácter ambiental y de salud. Sostienen que ciertas tecnologías ejercen efectos negativos sobre la salud de las personas y del medio ambiente. Se incluye en esa categoría, por ejemplo, la oposición a los organismos modificados genéticamente. Quienes defienden esas posturas suelen invocar el hecho de que son fuente de enriquecimiento para las empresas que las fabrican y comercializan, y que sus intereses se anteponen a otras consideraciones, incluidas las relativas a la salud de las personas o del medio ambiente.
Es probablemente una motivación de esa naturaleza la que anima a investigadores como Gilles-Eric Seralini. Seralini es conocido por sus opiniones contrarias a los transgénicos. En 2012 publicó un artículo en Food and Chemical Toxicology cuya conclusión era que el consumo de maíz transgénico provocaba el crecimiento de tumores en ratas de laboratorio que acababa provocándoles la muerte. El artículo, tras ser duramente criticado por numerosos científicos, fue finalmente retractado al año siguiente al entender el editor que no cumplía los estándares propios de una publicación científica debido a sus graves deficiencias metodológicas. La impresión que causa un caso como ese es que el investigador ha sacrificado el rigor exigible a un trabajo científico al objeto de obtener los resultados que mejor se acomodan a sus expectativas. J M Mulet (2013) ha expuesto aquí con claridad los pormenores de este caso.
Fuente:
Zuk, M (2013): Paleofantasy: What Evolution Really Tells Us about Sex, Diet, and How We Live. Norton & Co, New York.
Este artículo se publicó originalmente en el blog de Jakiunde. Artículo original.
Sobre los autores: Juan Ignacio Perez Iglesias es Director de la Cátedra de Cultura Científica de la UPV/EHU y Joaquín Sevilla Moroder es Director de Cultura y Divulgación de la UPNA.
El artículo Sesgos ideológicos que aquejan a la ciencia se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Sesgos cognitivos que aquejan a la ciencia
- Ciencia Patológica
- #Naukas14 Algunos trucos para reducir sesgos
Los números del sistema circulatorio humano
 Imagen: PIXOLOGICSTUDIO/Science Photo Library
Imagen: PIXOLOGICSTUDIO/Science Photo LibraryEl corazón es el único músculo humano que se contrae una y otra vez desde que se forma hasta que se detiene, tras lo cual y si no media intervención, sobreviene la muerte.
Dieciocho días después de la fecundación se empieza a desarrollar en el embrión, un proceso que concluye prácticamente en la octava semana. Es el primer órgano que empieza a funcionar; lo hace con tres semanas, cuando aún es un tubo cardiaco primitivo. En la quinta, configurado ya como un corazón, late a 80 pulsaciones por minuto (bpm en adelante). El ritmo se eleva hasta alcanzar en la novena -cuando ya se han formado los tabiques, las válvulas y las cuatro cámaras- valores máximos, que varían entre 155 y 195 bpm. El ritmo desciende a partir de ese momento hasta los 120-160 bpm.
El corazón adulto late a una frecuencia algo superior a un latido por segundo, aunque varía entre unos individuos y otros, dependiendo del peso, la edad, la condición física y el sexo. En promedio, late cien mil veces cada día, alrededor de treinta millones al cabo de una vida.
Su trabajo consiste en bombear sangre a través de dos sistemas de vasos. El de menores dimensiones la conduce a los pulmones -donde capta O2 y se desprende de CO2– y la trae de vuelta al corazón. El mayor la impulsa para limpiarla en los filtros renales, suministrar O2 a las células, recoger el CO2 que producen, llevar las moléculas de alimento del sistema digestivo a los tejidos, transportar hormonas y otras sustancias, conducir las plaquetas a donde sean necesarias, trasladar las células del sistema inmunitario para combatir el ataque de patógenos, distribuir calor por el organismo y desempeñar otras funciones de comunicación y transporte de sustancias entre órganos.
En reposo, un corazón de adulto bombea a los tejidos alrededor de cinco litros de sangre por minuto, lo que supone unos siete mil doscientos litros diarios. En otras palabras, bombea toda la sangre del cuerpo en un minuto, aunque en condiciones de actividad intensa, ese tiempo se reduce a quince segundos. Los tres órganos que más sangre reciben son el sistema digestivo (27%), los riñones (20%) y el encéfalo (un 15%). Ahora bien, la musculatura puede llegar a recibir dos terceras partes del flujo sanguíneo total cuando el organismo hace un ejercicio intenso.
Los vasos sanguíneos del cuerpo humano recorrerían, dispuestos uno detrás del otro, del orden de cuarenta mil kilómetros, aunque esa distancia resulta de sumar la correspondiente a miles de vasos que circulan en paralelo, puesto que el sistema circulatorio se ramifica en arterias, arteriolas y capilares para alcanzar así hasta el último rincón de nuestro cuerpo, y luego reagruparse en vénulas y venas antes de retornar al corazón. Por esa razón, cada gota de sangre, célula sanguínea o partícula en suspensión no recorre esa distancia cada vez que completa una vuelta al sistema. Dado que una célula sanguínea, por ejemplo, tarda en promedio un minuto en completar el circuito, viaja a una velocidad aproximada de dos kilómetros por hora y recorre unos treinta y tres metros.
Un 45% del volumen sanguíneo está ocupado por glóbulos rojos (también llamados eritrocitos), células carentes de núcleo encargadas de transportar O2 y CO2 y cuya vida se limita a unos cuatro meses. Cada día se renuevan del orden de cien mil millones de estas células. A lo largo de su breve vida, un eritrocito pasa por el corazón unas ciento cincuenta mil veces y recorre del orden de ciento sesenta mil kilómetros.
Y todo esto sin que, prácticamente, nos demos cuenta.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Los números del sistema circulatorio humano se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Un viaje a través del sistema circulatorio humano
- La emergencia de un doble sistema circulatorio
- ¿Cuántas células hay en el cuerpo humano?
Día de Darwin 2020: Evolución del Sistema Solar + Teoría evolutiva y medicina

El Día de Darwin se celebra en la capital vizcaína desde el año 2007, formando parte actualmente del calendario de citas ineludibles para los amantes de la ciencia. La Cátedra de Cultura Científica y el Círculo Escéptico este año han vuelto a conmemorar el 12 de febrero el aniversario del nacimiento del científico Charles Darwin, autor de la teoría de la evolución por selección natural. Hace ya 211 años que nació el reconocido científico y, en esta decimocuarta edición del Día de Darwin, las ponencias se centraron en la evolución del Sistema Solar y la relación entre la teoría evolutiva y la medicina.
La ponencia titulada “Pasado, presente y futuro del Sistema Solar” corre a cargo de Itziar Garate Lopez. La charla describe el Sistema Solar, una complicada familia de astros que cuenta con distintos tipos de planetas, lunas, asteroides y cometas orbitando una estrella nada extraordinaria, además de cómo pudo formarse en nuestra vecindad estelar, cómo ha cambiado desde entonces y cual es el futuro que le espera.
Itziar Garate Lopez es licenciada en Física por la Universidad de La Laguna y doctora en Ciencia, Tecnología y Observación Espacial por la UPV/EHU. Actualmente es profesora en el Departamento de Física Aplicada I de la Escuela de Ingeniería de Bilbao (UPV/EHU) e investigadora del Grupo de Ciencias Planetarias de la misma universidad. Anteriormente fue investigadora postoctoral del Centre National d’Études Spatiales en la Sorbonne Université. Su línea de investigación se centra en el estudio de la dinámica atmosférica de los planetas terrestres Venus y Marte y, más en concreto, en la formación y evolución de los vórtices polares venusianos.
En la segunda ponencia, “Teoría evolutiva y medicina: caminos convergentes”, Luis Carlos Álvaro González aborda la medicina desde una perspectiva diferente. La medicina ha vivido de espaldas a la teoría evolutiva por razones históricas y las propuestas de convergencia han ido surgiendo en los últimos años. Estas propuestas permiten un acercamiento, fundamentado en mecanismos operativos simples, que explican trastornos degenerativos, el envejecimiento con múltiples patologías asociadas, las enfermedades vasculares, los trastornos autoinmunes, diversas infecciones o las migrañas.
Luis Carlos Álvaro González es médico neurólogo del Hospital de Basurto de Bilbao y profesor del Departamento de Neurociencias de la UPV/EHU. Es autor de más de 100 publicaciones en su ámbito clínico, además de revisor de revistas especializadas nacionales e internacionales y miembro de comités editoriales. Ha sido premiado por su labor y dedicación en el área de la neurología. Autor de varios libros de divulgación de su especialidad, participa activamente en la investigación y difusión de la teoría evolutiva en el escenario clínico y para el público no experto.
La sesión está enmarcada en el ciclo Bidebarrieta Científica, una iniciativa que organiza todos los meses la Cátedra de Cultura Científica de la UPV/EHU y la Biblioteca Bidebarrieta para divulgar asuntos científicos de actualidad.
Edición realizada por César Tomé López
El artículo Día de Darwin 2020: Evolución del Sistema Solar + Teoría evolutiva y medicina se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Los primeros pasos de la evolución darwiniana y sesgos cognitivos y evolución (Día de Darwin 2018)
- Una simulación más eficiente de la evolución del Sistema Solar
- Planeta X, en busca del inquilino invisible del sistema solar
La superconductividad a 250 K se estabiliza mediante fluctuaciones cuánticas
 Estructura cristalina de la fase Fm-3m de LaH10, donde una jaula de hidrógeno altamente simétrica encierra los átomos de lantano. En la parte superior se muestra un bosquejo del complejo paisaje energético clásico, donde están presentes muchos mínimos. Por otro lado, en la parte inferior vemos un bosquejo del paisaje de energía cuántica completamente reformado y mucho más simple, donde sólo sobrevive un mínimo.
Estructura cristalina de la fase Fm-3m de LaH10, donde una jaula de hidrógeno altamente simétrica encierra los átomos de lantano. En la parte superior se muestra un bosquejo del complejo paisaje energético clásico, donde están presentes muchos mínimos. Por otro lado, en la parte inferior vemos un bosquejo del paisaje de energía cuántica completamente reformado y mucho más simple, donde sólo sobrevive un mínimo.Cálculos recientes han demostrado que el material con el récord de superconductividad se estabiliza mediante fluctuaciones cuánticas. El trabajo, publicado en Nature, ha sido dirigido por Ion Errea, profesor de la Escuela de Ingeniería de Gipuzkoa de la Universidad del País Vasco (UPV/EHU) e investigador del Centro de Física de Materiales (CFM) de Donostia / San Sebastián y del Donostia International Physics Center (DIPC), junto con José A. Flores-Livas de la Universidad de Roma La Sapienza (Italia). El trabajo es fruto de una amplia colaboración internacional de investigadores de España, Italia, Alemania, Francia y Japón. Este nuevo resultado sugiere que compuestos ricos en hidrógeno pueden ser superconductores a prácticamente temperatura ambiente a presiones mucho más bajas que las predichas anteriormente, acercando la posibilidad de obtener materiales superconductores en condiciones normales.
Llegar a conseguir superconductividad a temperatura ambiente es uno de los mayores sueños de la física. Este descubrimiento podría dar lugar a una revolución tecnológica al proporcionar transporte eléctrico sin pérdidas de energía, motores o generadores eléctricos ultraeficientes, así como la posibilidad de crear enormes campos magnéticos sin necesidad de enfriamiento. Los recientes descubrimientos de superconductividad, primero, a –73ºC en sulfuro de hidrógeno y, después, a -23ºC en LaH10 han demostrado que los compuestos de hidrógeno pueden ser superconductores de alta temperatura. El problema es que ambos descubrimientos han sido realizados a altas presiones: la superconductividad solo se ha conseguido por encima de los 100 gigapascales, un millón de veces la presión atmosférica.
La temperatura de–23 °C obtenida en el LaH10 —la temperatura habitual a la que trabajan los congeladores domésticos—, es la temperatura más alta en la cual se ha observado la superconductividad. La posibilidad de observar la superconductividad de alta temperatura enLaH10, un superhidruro formado por lantano e hidrógeno, fue predicha teóricamente en 2017. Estos cálculos sugirieron que por encima de 230 gigapascales podría formarse un compuesto LaH10 altamente simétrico (grupo espacial Fm-3m), en el que una jaula de hidrógeno envuelve los átomos de lantano. Se calculó que esta estructura podría distorsionarse a presiones más bajas, y romper la estructura altamente simétrica. Sin embargo, en experimentos llevados a cabo en 2019, se pudo sintetizar el compuesto altamente simétrico a presiones mucho menores, entre 130 y 220 gigapascales, y se pudo medir la superconductividad en torno a -23ºC en todo este rango de presión. Dada la contradicción entre las presiones predichas teóricamente y los resultados experimentales, la estructura cristalina del superconductor récord y, por consiguiente, su superconductividad estaban sin esclarecer.
Ahora, gracias a los resultados de este trabajo, sabemos que las fluctuaciones cuánticas atómicas “pegan” la estructura simétrica de LaH10 en todo el rango de presión en el que se ha observado la superconductividad. En mayor detalle, los cálculos efectuados muestran que si los átomos son tratados como partículas clásicas, es decir, como simples puntos en el espacio, muchas distorsiones de la estructura tienden a bajar la energía del sistema. Esto significa que el paisaje de energía clásico es muy complejo, con muchos mínimos (ver figura), similar a un colchón muy deformado debido a la cantidad de gente que soporta. Sin embargo, cuando los átomos son tratados como objetos cuánticos, que se describen con una función de onda deslocalizada, el paisaje de energía se remodela completamente: resulta evidente un único mínimo, que corresponde a la estructura altamente simétrica Fm-3m. De alguna manera, los efectos cuánticos eliminan a toda la gente del colchón excepto a una persona, que lo deforma en un único punto.
Además, las estimaciones de la temperatura crítica utilizando el paisaje de energía cuántica concuerdan satisfactoriamente con la evidencia experimental. Esto apoya aún más la estructura de alta simetría Fm-3m como responsable de la superconductividad récord.
Referencia:
Ion Errea, Francesco Belli, Lorenzo Monacelli, Antonio Sanna, Takashi Koretsune, Terumasa Tadano, Raffaello Bianco, Matteo Calandra, Ryotaro Arita, Francesco Mauri & José A. Flores-Livas (2020) Quantum crystal structure in the 250-kelvin superconducting lanthanum hydride Nature doi: 10.1038/s41586-020-1955-z
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo La superconductividad a 250 K se estabiliza mediante fluctuaciones cuánticas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El origen de la superconductividad récord
- La cuántica del protón y la superconductividad apestosa
- Fluctuaciones cuánticas y aspirinas
Receta de un Adagio 2
Hay muchas formas de componer la tristeza. No existe una única pieza clave, una nota dolorosa, ni una fórmula mágica que haga brotar las lágrimas. Pero como el vinagre y el aceite, existen ingredientes que se repiten en casi todas las ensaladas (tristes ensaladas). Para componer la tristeza no se usan aliños sino sonidos que se parecen a los que emite un humano triste y sonidos que se parecen a los de un humano que gotea.
Puedes leer la primera parte de esta receta aquí.
 Foto: seoungsuk ham / Pixabay
Foto: seoungsuk ham / Pixabay
Dice una (alegre) canción que “no se puede tocar música triste con un banjo”. En cambio, otros instrumentos como el violín o la viola da gamba, parecen siempre afinados para la depresión.
El timbre de los instrumentos parece ser un ingrediente importante a la hora de caracterizar emocionalmente una pieza musical 12. A menudo hablamos de timbres oscuros o rugosos, o timbres dulces o brillantes, sin que ningún elemento de nuestra vista, nuestro gusto o nuestro tacto pueda darnos tal información. No obstante, el timbre parece evocar sensaciones y emociones que no siempre resultan fáciles de explicar.
Existen, por supuesto, asociaciones culturalmente bien establecidas: en parte, el banjo suena alegre porque —se diría— en su eco está escrita toda la alegre música para banjo que hemos oído anteriormente. Pero no se trata solo de eso: cuando uno escarba más allá de las convenciones culturales, encuentra propiedades sonoras, tímbricas, que sistemáticamente se asocian a la alegría, a la tristeza o a la ira3.
La idea clave, vuelve a ser la misma: para componer la tristeza, debemos usar sonidos que se parecen a los que emite un humano triste. Para elegir una instrumentación, debemos buscar timbres que recuerden a los de una voz.
Los instrumentos de cuerda frotada resultan muy apropiados en este sentido: violines, violas, cellos etc. pueden alargar y vibrar cada nota de la melodía. Pueden jugar con la dinámica sin cambiar de sonido (es decir: pueden subir y bajar de volumen sobre una misma nota). Pueden variar ligeramente la afinación o incluso hacer glissandos (una rampa de frecuencias continua entre dos notas) que recuerdan a los de la prosodia humana: una de las diferencias entre el habla y la música es que el habla se mueve entre frecuencias de manera continua, mientras que la música va saltando entre notas discretas. La ausencia de trastes en la familia del violín, permite diluir las fronteras entre las notas, como habitualmente hacemos con la voz.
Todos estos recursos resultan fundamentales en el Adagion de Barber. El sonido de las cuerdas da sentido y expresividad a las notas tenidas, los retardos, las apoyaturas. La dinámica fluctúa sobre cada sonido y forma una línea continua. Basta con escuchar una versión para piano de la misma obra para comprobar cuándo se pierde al cambiar de instrumentación. O, todo lo contrario, oír cuánto se parece una versión para voz.
La lentitud del Adagio se vuelve todavía más complicada porque Barber indica que casi toda la obra debe ser tocada piano o pianissimo.La obra está escrita en si bemol menor: en esta tonalidad, apenas hay notas que se toquen con las cuerdas al aire (sin que el dedo las atrape sobre el mástil), así se evitan sonidos demasiado brillantes.
Los humanos tristes, de hecho, suelen hablar en voz baja porque no les da la energía para mucho más. Emiten sonidos opacos y comparativamente graves: este es el motivo por el que en occidente asociamos a la tristeza el modo menor (pero eso merece su propia anotación).
Esta quietud se vuelve complicada cuando se lleva al mundo de la interpretación musical: los sonidos leves hacen más evidentes los fallos. Cualquier ruido, cualquier desequilibrio llega hasta los oídos del público, que ahora tiene toda su atención enfocada para oír la música mejor.
Esta la paradoja que acompaña a cualquier virtuoso: el público aplaude y se maravilla ante los pasajes fuertes, rápidos, brillantes, aparatosos. Pero la mayor dificultad de la partitura a menudo se esconde en las notas más tímidas.
En el Adagio de Barber, sin embargo, no todo es quietud. Las primeras repeticiones del tema ascienden tímidamente y vuelven a hundirse. Pero en la tercera repetición, la música aumenta de intensidad durante minuto y medio y culmina poco antes del final. Durante el ascenso, encontramos sonidos que ya no tienen nada que ver con un humano triste: sonidos agudos, estridentes, tensos, ruidosos. Los sonidos de un humano que llora.
Existen piezas donde esta especie de transición de la tristeza al llanto se da, incluso, sobre un mismo tema, las mismas notas, la misma armonía. El nocturno en do menor (Op.48, No.1) de Chopin comienza con una sección lenta, fúnebre, callada. Se ilumina hacia la mitad (2’05’’), crece en intensidad y vuelve al tema inicial. Pero cuando lo retoma (4’10’’), el tema ha cambiado: ahora suena al doble de velocidad, su textura es mucho más densa, ruidosa, hay acordes que agitan la melodía en ambas manos. El nocturno ya no es triste, ahora suena… desesperado. Y el efecto es aún mayor porque el cambio de carácter se da sobre un mismo argumento: la misma melodía, antes abatida, ahora reclama ayuda casi a gritos. Si hubiese gritado desde el principio, quizás no la hubiésemos ni escuchado.
Referencias:
1David Huron, Neesha Anderson, Daniel Shanahan. «You Can’t Play a Sad Song on the Banjo: Acoustic Factors in the Judgment of Instrument Capacity to Convey Sadness”. Empirical Musicology Review, 2014.
2Michael Schutz, David Huron, Kristopher Keeton, Gred Loewer. “The Happy Xylophone: Acoustics Affordances Restrict An Emotional Palate”. Empirical Musicology Review, 2008.
3Xiaoluan Liu, Yi Xu, Kai Alter and Jyrki Tuomainen. “Emotional Connotations of Musical Instrument Timbre in Comparison With Emotional Speech Prosody: Evidence From Acoustics and Event-Related Potentials”. Frontiers in Psychology, 2018.
Sobre la autora: Almudena M. Castro es pianista, licenciada en bellas artes, graduada en física y divulgadora científica
El artículo Receta de un Adagio 2 se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Fractus, arte y matemáticas
Como viene siendo habitual en los últimos años, alrededor del 14 de marzo, día conocido internacionalmente como Día de Pi (la fecha del 14 de marzo se escribe, tanto en el sistema anglosajón, como en euskera, 03/14, que nos remite a la aproximación de pi: 3,14), desde la Cátedra de Cultura Científica, junto con BCAM y NAUKAS, celebramos la Jornada BCAM-NAUKAS en el día de Pi. Esta consiste en una serie de talleres para escolares, por la mañana, y monólogos científicos para todos los públicos, por la tarde. El programa de este año, que tendrá lugar el 13 de marzo, viernes, en el Bizkaia Aretoa (Bilbao), lo podéis consultar en el Cuaderno de Cultura Científica.
Sin embargo, el Día de Pi ha adquirido una importancia mucho mayor, después de que la UNESCO –a propuesta de la Unión Matemática Internacional– lo declarara el Día Internacional de las Matemáticas. Además, el lema de este año es Mathematics everywhere (Las matemáticas están en todas partes). Por este motivo, la Cátedra de Cultura Científica de la UPV/EHU ha decidido organizar este año una doble exposición, también en el Bizkaia Aretoa (Bilbao), sobre matemáticas y arte, entre los días 12 y 25 de marzo (de 2020). Las exposiciones son Fractus, de la artista murciana Verónica Navarro, de la que vamos a hablar en esta entrada del Cuaderno de Cultura Científica, y Azares, del artista mexicano, afincado en Bilbao, Esaú de León, a la que dedicaremos una entrada en el futuro.
 Logo del Día Internacional de las Matemáticas. Toda la información sobre el mismo se recoge en idm314
Logo del Día Internacional de las Matemáticas. Toda la información sobre el mismo se recoge en idm314
Antes de hablar de la exposición Fractus, presentemos a su autora, la artista Verónica Navarro (Puerto Lumbreras, Murcia, 1983). Es licenciada en Bellas Artes y doctora por la investigación El laboratorio artístico-literario. Una investigación de interacción hipertextual en segundo y tercer ciclo de Educación Primaria, en la Facultad de Educación de la Universidad de Murcia.
Ha realizado diferentes instalaciones y exposiciones individuales y colectivas. Entre las exposiciones individuales, podemos mencionar la exposición Horma/forma/norma, en el Palacio Guevara de Lorca (2008), el Museo del Calzado de Elda (2009) y Sala Caja Murcia de Jumilla (2010), la instalación Menudo Punto, en el Centro Párraga de Murcia (2013) o la exposición Fractus en Águilas, Murcia (2019).Y entre las exposiciones colectivas, Sentido sin sentido, en la Galería Fernando Guerao, Murcia (2006), La periferia como nudo, estructuras de red en la creación contemporánea, en el Parlamento Europeo (Bruselas, Bélgica), en la Sede del Comité de las Regiones (2010), La imagen como enigma, que ha recorrido diferentes salas de Madrid, Murcia y Salamanca (2010), Historias mínimas, junto al artista Francisco Cuellar, en el Palacio Guevara, Lorca (2010) y en Espacio para la Creación Joven de Zafra y Llerena, Badajoz (2011), Las formas toman forma, en la Fundación Caja Murcia de Lorca (2012) y la Biblioteca Regional de Murcia (2013) o Infinitas, junto a la artista Teresa Navarro, en el Centro Párraga de Murcia (2019).
 Dos imágenes de la exposición Menudo Punto, de la artista Verónica Navarro, en la cual se juntaban literatura (álbum ilustrado) y el arte (laboratorio/instalación). Fotografías de Francisco Cuellar, de la web de la editorial y laboratorio puntodepapel
Dos imágenes de la exposición Menudo Punto, de la artista Verónica Navarro, en la cual se juntaban literatura (álbum ilustrado) y el arte (laboratorio/instalación). Fotografías de Francisco Cuellar, de la web de la editorial y laboratorio puntodepapel
También ha realizado varios libros de artista, que pueden verse en su página web, entre los que podemos mencionar Punto/Línea/Fractal, Fina e infinita, Fractales, Postalnova o Granada de papel.
 Fotografías de los libros de artista Granada de papel (arriba) y Postalnova (abajo), de la artista Verónica Navarro. Imágenes de la página web de la artista
Fotografías de los libros de artista Granada de papel (arriba) y Postalnova (abajo), de la artista Verónica Navarro. Imágenes de la página web de la artista
Como autora ha publicado varios libros: Libro de bolsillo, El muy punto (2014), XYZ (2012) y Menudo punto (2012). Pero, además, es directora ejecutiva y coordinadora de la editorial y laboratorio puntodepapel.
Verónica Navarro compagina su labor plástica con la educación, aunando arte, literatura y matemáticas, creando sorprendentes e interesantes talleres didácticos, creativos y para altas capacidades, así como materiales adecuados para los mismos, tanto marionetas, como álbumes ilustrados o maletas de juegos educativos.
 Imagen de la exposición Fractalmente emocionados, celebrada en el Centro Párraga, Murcia, en 2017, recogiendo los trabajos desarrollados durante las seis sesiones del taller “Fractalmente emocionados” por alumnado de altas capacidades de Educación Primaria en Murcia. Imagen de la editorial y laboratorio puntodepapel
Imagen de la exposición Fractalmente emocionados, celebrada en el Centro Párraga, Murcia, en 2017, recogiendo los trabajos desarrollados durante las seis sesiones del taller “Fractalmente emocionados” por alumnado de altas capacidades de Educación Primaria en Murcia. Imagen de la editorial y laboratorio puntodepapel
Con la exposición Fractus, de Verónica Navarro, nos encontramos ante una exposición en la que se aúnan arte y matemáticas. Con el objetivo de crear la serie de obras de arte que conforman Fractus, esta artista ha utilizado las matemáticas tanto como fuente de inspiración, como herramienta de creación artística. Los fractales y, en particular, la conocida curva de Koch (que explicaremos más adelante), son elementos fundamentales para la creación de estas obras. En esta serie de obras se confronta además la geometría fractal, a través de la curva fractal de Koch, con la geometría euclídea, mediante objetos geométricos clásicos como el triángulo, el cuadrado o la circunferencia.
Como nos dice la propia artista:
Fractus es una exposición que parte de la literatura, del libro Menudo punto (Verónica Navarro, puntodepapel, 2012), para acercarnos a la geometría fractal y en concreto a la Curva de Koch, a través de obras artísticas de pequeño y mediano formato trabajadas en papel a modo de escenografías. Obras que invitan al espectador a investigar el aparente caos descrito en ellas e imaginar mundos inexplorados y mágicos.
Este libro, en el que se “reflexiona sobre los cambios que se producen en la vida y su relación con las emociones”, tiene como protagonista a un pequeño punto, que va transformando en una línea de puntos, una línea continua, que se enreda, zigzaguea, sonríe o se quiebra, hasta convertirse en el conjunto de Cantor, un fractal.
 Dos imágenes del libro Menudo punto (puntodepapel, 2012), de Verónica Navarro. En la segunda imagen podemos ver el fractal conocido como conjunto de Cantor. Imágenes de la página web de la artista
Dos imágenes del libro Menudo punto (puntodepapel, 2012), de Verónica Navarro. En la segunda imagen podemos ver el fractal conocido como conjunto de Cantor. Imágenes de la página web de la artista
Puesto que estos objetos matemáticos, los fractales, son muy importantes para el trabajo de la artista Verónica Navarro y, en particular, para su exposición Fractus, es necesario que no detengamos un momento para explicar qué son los fractales y cuál es su importancia.
Para empezar, ¿qué son los fractales? Estos son objetos matemáticos de una gran complejidad, pero no es sencillo dar una definición de los mismos, ya que todas las definiciones propuestas dejan algunos de los fractales fuera. Por este motivo vamos a intentar acercarnos al concepto de objeto fractal mediante algunas de sus propiedades más características:
Autosemejanza. Su estructura se repite a diferentes escalas. Si nos fijamos en una parte cualquiera de un objeto fractal y la ampliamos convenientemente (pensemos en la lupa de un ordenador o un microscopio) obtendremos una réplica del objeto fractal inicial. También podemos pensar en algunos objetos fractales como formados por copias de sí mismos a escalas más pequeñas.
Ejemplos de la naturaleza de formas en cierto modo autosemejantes son el romanescu y el brócoli, los helechos, los árboles, las montañas, etc…
 El romanescu es uno de los ejemplos más bonitos de forma de tipo fractal, en el sentido de ser autosemejante, de la naturaleza. Aquí podemos ver varias imágenes del cocinero y escritor Xabier Gutierrez de la preparación de su plato Romanescu (o como zamparse un fractal) y antxoas
El romanescu es uno de los ejemplos más bonitos de forma de tipo fractal, en el sentido de ser autosemejante, de la naturaleza. Aquí podemos ver varias imágenes del cocinero y escritor Xabier Gutierrez de la preparación de su plato Romanescu (o como zamparse un fractal) y antxoas
La autosemejanza la podemos observar claramente en objetos fractales como el conjunto de Cantor, la curva de Koch, la esponja de Menger, que aparecen ex`plicados más adelante, o el conjunto de Mandelbrot, como ya mostramos en la entrada Guía matemática para el cómic ‘Promethea’.
Rugosidad. Los fractales son objetos geométricos de una gran rugosidad, de una gran irregularidad, y la medida matemática de esa rugosidad es la “dimensión fractal” (la dimensión de Hausdorff-Besicovich), que no explicaremos aquí por su complejidad. Los objetos de la geometría clásica (recta, circunferencia, esfera,…) son objetos lisos, sin rugosidad, y por lo tanto su dimensión es un número natural (la recta y las curvas tienen dimensión 1, las superficies 2,…), mientras que los fractales son objetos geométricos rugosos y su dimensión puede ser un número real no natural (las curvas fractales tienen dimensión entre 1 y 2, las superficies fractales entre 2 y 3,…).
 Mandelbulb, fractal tridimensional, construido por Daniel White and Paul Nylander en 2009. Imagen de Ondřej Karlík a través de Wikimedia Commons
Mandelbulb, fractal tridimensional, construido por Daniel White and Paul Nylander en 2009. Imagen de Ondřej Karlík a través de Wikimedia Commons
De hecho, el conjunto de Cantor tiene dimensión fractal 0,6309…, la curva de Koch 1,2618…, el conjunto de Mandelbrot tiene dimensión fractal igual a 2 (este importante fractal no entraría dentro de la familia de fractales si la definición fuese que su dimensión es un número real no natural), la esponja de Menger 2,7268…, por citar algunos.
 En la parte superior, cuatro iteraciones de la definición de la esponja de Menger, mientras que en la parte inferior vemos la esponja de Menger –sugerida tras cuatro iteraciones- y como una parte, que es uno de los 27 cuadrados que conforman el cuadrado inicial, pintado de rojo, es de nuevo la esponja de Menger –aunque sugerida en tres iteraciones-. Imagen de Niabot a través de Wikimedia Commons
En la parte superior, cuatro iteraciones de la definición de la esponja de Menger, mientras que en la parte inferior vemos la esponja de Menger –sugerida tras cuatro iteraciones- y como una parte, que es uno de los 27 cuadrados que conforman el cuadrado inicial, pintado de rojo, es de nuevo la esponja de Menger –aunque sugerida en tres iteraciones-. Imagen de Niabot a través de Wikimedia Commons
Esta propiedad está asociada a la paradoja de la costa, que planteó Mandelbrot en su artículo ¿Qué longitud tiene la costa de Gran Bretaña? (Revista Science, 1967). Supongamos que nos preguntamos cuanto mide la costa de Gran Bretaña… si medimos la imagen de una fotografía aérea tendremos una longitud, si medimos la costa con “nuestros pasos”, la escala humana, nos dará una longitud mayor, si la medimos con “pasos de gato” la longitud será mayor aún, y mucho mayor con “pasos de hormiga”… tendiendo esa longitud al infinito.
 Dibujo explicativo de la paradoja de la costa, en el que se puede observar que midiendo con diferentes escalas –rectas de 100, 50 y 1 kilómetros de longitud-, se obtienen aproximaciones cada vez mayores de la longitud de la costa de Gran Bretaña –de unos 2.800, 3.500 y más de 8.000 kilómetros. Imagen de la web Sketchplanations
Dibujo explicativo de la paradoja de la costa, en el que se puede observar que midiendo con diferentes escalas –rectas de 100, 50 y 1 kilómetros de longitud-, se obtienen aproximaciones cada vez mayores de la longitud de la costa de Gran Bretaña –de unos 2.800, 3.500 y más de 8.000 kilómetros. Imagen de la web Sketchplanations
Procesos iterativos infinitos. Muchos de los objetos fractales son descritos mediante procesos iterativos, tanto geométricos, como analíticos, infinitos. Pongamos un ejemplo para ilustrarlo, el mencionado conjunto de Cantor. Este fue definido y estudiado, en 1883, por el matemático alemán, nacido en Rusia, Georg Cantor (1845-1918), de quien deriva su nombre (aunque los historiadores de las matemáticas han descubierto que realmente aparece en un artículo de 1875 del matemático británico Henry John Stephen Smith).
Para definir el conjunto de Cantor, empezamos con el intervalo [0,1] de longitud 1, sobre el que se realiza el siguiente proceso iterativo (los primeros pasos del proceso se ilustran en la imagen siguiente). Se parte el intervalo en tres partes –luego de longitud 1/3– y se quita el intervalo central, quedando los dos intervalos laterales –de longitud 1/3–. En el siguiente paso se considera cada uno de los dos intervalos y se dividen, de nuevo, en tres partes –cada una de longitud 1/9– y se eliminan los dos intervalos centrales, quedando los cuatro intervalos laterales –de longitud 1/9–. En el siguiente paso se realiza el mismo proceso para los cuatro intervalos, y así hasta el infinito.
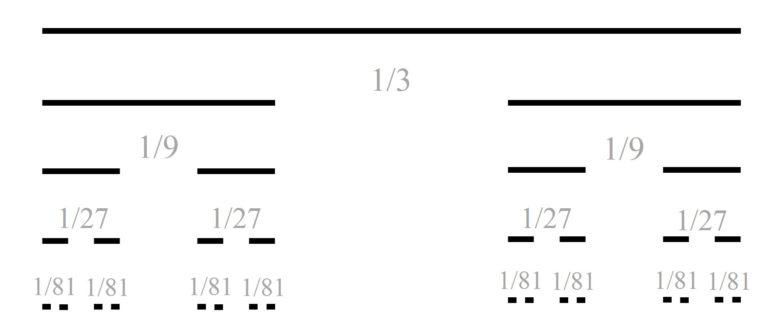 Primeros pasos del proceso iterativo que define el fractal llamado conjunto de Cantor
Primeros pasos del proceso iterativo que define el fractal llamado conjunto de Cantor
Después de este proceso iterativo infinito queda un conjunto de puntos del segmento [0,1] inicial, que es el llamado conjunto de Cantor. Este es un conjunto muy extraño. Si se suman las longitudes de los intervalos que se han ido eliminando, la suma es 1, que es la longitud del intervalo original [0,1], por lo tanto, ese conjunto de puntos, el fractal de Cantor, “no mide nada” o “tiene medida de longitud 0”. Aunque se puede demostrar que, en el conjunto de Cantor, hay tantos puntos como en todo el intervalo [0,1].
 Fotografía de Benoit Mandelbrot, su mujer Aliette Kagan, Raúl Ibáñez y Antonio Pérez, durante la celebración del International Congress of Mathematicians 2006, en Madrid
Fotografía de Benoit Mandelbrot, su mujer Aliette Kagan, Raúl Ibáñez y Antonio Pérez, durante la celebración del International Congress of Mathematicians 2006, en Madrid
El matemático polaco, nacionalizado francés y estadounidense, Benoît Mandelbrot (1924-2010) es considerado el padre, o creador, de la geometría fractal –de hecho, él bautizó a estos objetos con el nombre de “fractal”, que viene del latín “fractus”, roto, quebrado–. Además de investigar estos extraños objetos, generar la primera imagen con ordenador del que después se bautizará como conjunto de Mandelbrot y observar la gran cantidad de aplicaciones que existen de los mismos, realizó una exitosa divulgación de la geometría fractal, por ejemplo, publicando los libros Los objetos fractales: forma, azar y dimensión (1975) o La geometría fractal de la naturaleza (1982), entre muchos otros.
La geometría fractal significó un cambio de paradigma dentro de las matemáticas, que podemos ilustrar con las dos siguientes citas. La primera pertenece al libro Il Saggiatore/El ensayador (1623), del matemático italiano Galileo Galilei (1564-1642), y nos dice que la geometría euclídea y sus formas –rectas, círculos, polígonos, esferas, cubos, poliedros, etcétera– son las herramientas que deben utilizarse para modelizar la naturaleza.
“La filosofía está escrita en ese grandísimo libro que tenemos abierto ante los ojos, quiero decir, el universo, pero no se puede entender si antes no se aprende a entender la lengua, a conocer los caracteres en los que está escrito. Está escrito en lengua matemática y sus caracteres son triángulos, círculos y otras figuras geométricas, sin las cuales es imposible entender ni una palabra; sin ellos es como girar vanamente en un oscuro laberinto.”
Mientras que la segunda cita pertenece al libro La geometría fractal de la naturaleza (1982), del propio Benoît Mandelbrot, anunciando el cambio de paradigma, que la geometría euclídea no era una herramienta suficiente para modelizar la naturaleza.
“…las nubes no son esferas, las montañas no son conos, las costas no son circulares y la corteza de los árboles no son lisas, ni tampoco el rayo viaja en línea recta.”
 Función de Weierstrass, que es continua en todo punto y no derivable en ninguno punto. Imagen de Wikimedia Commons
Función de Weierstrass, que es continua en todo punto y no derivable en ninguno punto. Imagen de Wikimedia Commons
Sin embargo, el origen de los objetos fractales se remonta a finales del siglo XIX y principios del XX. Fue entonces cuando grandes matemáticos como Riemann, Cantor, Peano, Hilbert, Sierpinski o Hausdorff, entre otros, introdujeron algunas construcciones matemáticas “patológicas”, los primeros objetos fractales, con propiedades geométricas o analíticas contrarias a la intuición matemática. Es decir, ponían de manifiesto la existencia de lagunas en el conocimiento matemático dentro de la geometría clásica (euclídea) y el análisis. La matemática de ese tiempo los consideró “monstruos” y no hizo caso a su existencia.
El primer objeto patológico que se introdujo fue el conjunto de Cantor (1875-1883), que hemos definido más arriba, un conjunto con una infinidad no numerable de puntos, pero que no tiene longitud.
Entre esos primeros monstruos matemáticos también se encontraban curvas continuas que no tienen tangente en ningún punto (es decir, completamente irregulares, son todo picos), como es el caso de las funciones de Weierstrass (véase la anterior imagen) o Riemann, la curva de Takagi, la curva de Koch o el copo de nieve de Koch (que serán introducidas más adelante). Estas curvas también cumplían la paradoja de la costa, es decir, tienen longitud infinita. Más aún, el copo de nieve de Koch es una curva de longitud infinita pero que encierra un área finita.
Otros objetos patológicos de esos inicios de los fractales a finales del siglo XIX y principios del siglo XX fueron ejemplos anómalos de curvas que llenan todo un cuadrado. Esta cualidad ponía en duda el concepto de dimensión, que se manejaba hasta el momento en las matemáticas. No era claro cual era la dimensión de estas “curvas”. Si era una curva la dimensión debía de ser 1, pero como llenaba todo el espacio plano (cuadrado), quizás podría ser 2. Entre otras estaban la curva de Hilbert y la curva de Peano.
El matemático alemán David Hilbert (1862-1943) introdujo, en el año 1891, la siguiente curva, definida de forma iterativa, que llena el espacio. Como podemos ver en la siguiente imagen se empieza con tres segmentos (rojos en la imagen) formando un cuadrado sin uno de sus lados (el superior en la imagen). En la primera iteración se reduce el 50% esta figura y se hacen cuatro copias, que se colocan de forma que los centros de las figuras “cuadradas” estén en los extremos de los segmentos de la figura original, de forma que los dos de arriba están en horizontal, con sentidos opuestos, y los dos de abajo en vertical, hacia abajo. Para que la figura construida (de azul en la imagen) sea continua se le añaden tres segmentos para conectar las cuatro figuras “cuadradas”. Para la siguiente iteración se realiza el mismo proceso anterior, pero para cada una de las cuatro figuras “cuadradas”, generando así la figura negra (el tercer diagrama de la siguiente imagen). Y así se continúa en un proceso iterativo infinito. En el límite infinito se obtiene una curva que llena todo el cuadrado.
 Imágenes de los tres primeros pasos de proceso iterativo para generar la curva de Hilbert e imagen de la curva tras la séptima iteración. Imágenes de Geoff Richards y Alfred Nussbaumer a través de Wikimedia Commons
Imágenes de los tres primeros pasos de proceso iterativo para generar la curva de Hilbert e imagen de la curva tras la séptima iteración. Imágenes de Geoff Richards y Alfred Nussbaumer a través de Wikimedia Commons
Los fractales significaron por tanto un cambio de paradigma dentro de las matemáticas, pero además, como ya puso de manifiesto Benoit Mandelbrot, poseían una enorme cantidad de aplicaciones. Citemos algunas de ellas:
Los fractales aparecieron dentro de la matemática pura, formando parte de los estudios teóricos de los propios matemáticos. Fueron muy importantes, puesto que significaron por tanto un cambio de paradigma dentro de las matemáticas, como puso de manifiesto Benoit Mandelbrot. Pero, sus orígenes están dentro de lo que la gente de la calle llama “locuras de los matemáticos que no sirven para nada”. Sin embargo, confirmando una vez más “la irrazonable eficacia de las matemáticas (puras)”, sus aplicaciones se han ido extendiendo a casi todos los aspectos de nuestra vida cotidiana. Hay aplicaciones en multitud de áreas. Algunas de ellas:
– Computación: compresión de imágenes digitales, …
– Infografía: utilización en la industria cinematográfica (Star Trek, Star Wars, La Tormenta Perfecta, Apolo 13, Titanic, Doctor extraño, Escuadrón suicida o Guardianes de la Galaxia) o en publicidad, para diseñar paisajes, objetos, texturas, …
 La primera imagen pertenece a la película Star Trek 2: La ira de Khan (Nicholas Meyer, 1982), que fue la primera película en la que se utilizaron los fractales para construir un paisaje realista, mientras que las otras dos imagenes pertenecen a la película Los guardianes de la galaxia, vol. 2 (James Gunn, 2017), en la que se utilizan los fractales para crear el planeta de Ego
La primera imagen pertenece a la película Star Trek 2: La ira de Khan (Nicholas Meyer, 1982), que fue la primera película en la que se utilizaron los fractales para construir un paisaje realista, mientras que las otras dos imagenes pertenecen a la película Los guardianes de la galaxia, vol. 2 (James Gunn, 2017), en la que se utilizan los fractales para crear el planeta de Ego
– Medicina: la osteoporosis, las arterias y venas, los pulmones o el cerebro tienen estructura fractal, así como los tumores sólidos, lo cual es utilizado para la detección temprana de algunas enfermedades, su estudio, …
– Biología: Crecimiento tejidos, organización celular, evolución de poblaciones depredador-presa, …
– Geología: análisis de patrones sísmicos, fenómenos de erosión, modelos de formaciones geológicas, …
– Economía: análisis bursátil y de mercado, …
– Telecomunicaciones: Antenas fractales, fibra óptica, estructura de la red de Internet, …
– Meteorología, Ingeniería, Acústica, nuevos materiales, Ciencias Sociales,…
y un largo etcétera.
 Una de las obras de la serie Fractus (2018) de la artista Verónica Navarro. Imagen de la página web de la artista
Una de las obras de la serie Fractus (2018) de la artista Verónica Navarro. Imagen de la página web de la artistaPero volvamos a la exposición Fractus, de Verónica Navarro. La curva de Koch, como la propia artista afirmaba en el párrafo que hemos incluido al principio de la entrada, es uno de los elementos principales en la creación de las obras de la serie Fractus.
La curva de Koch fue introducida en 1904 por el matemático sueco Helge von Koch (1870-1924) como ejemplo de una curva continua que no tiene recta tangente en ningún punto. Para construir la curva de Koch, se empieza con un intervalo, por ejemplo, de longitud 1. En la primera iteración se divide el intervalo en tres partes, de longitud 1/3, y se reemplaza el intervalo central por dos segmentos de la misma longitud formando un ángulo de 60 grados entre ellos (como se ve en la imagen). La longitud total de la construcción en este primer paso es 4/3.
En la segunda iteración se realiza la misma operación en cada uno de los cuatro intervalos que se han formado en la primera. Obteniendo así una figura curva formada por 16 pequeños intervalos de longitud 1/9, luego la longitud total es 16/9 (4/3 al cuadrado). Y así se continúa en cada iteración. En el límite de este proceso infinito se obtiene la curva de Koch.
 Las seis primeras iteraciones en la construcción de la curva de Koch. Imagen de Christophe Dang Ngoc Chan, a través de Wikimedia Commons
Las seis primeras iteraciones en la construcción de la curva de Koch. Imagen de Christophe Dang Ngoc Chan, a través de Wikimedia Commons
Como la longitud de la iteración n-ésima de la curva de Koch es 4/3 elevado a la potencia n, entonces, la longitud de la curva de Koch, que es el límite cuando n tiende a infinito de esa longitud es infinito. Es decir, la curva de Koch tiene longitud infinita. Claramente, la curva de Koch es autosemejante y está creada por un proceso iterativo infinito. Además, la dimensión fractal (que no hemos explicado realmente) es Ln 4/Ln 3 = 1,26186…
La construcción del copo de nieve de Koch es la misma que la que acabamos de ver para la curva de Koch, pero tomando como punto inicial un triángulo equilátero y realizando el proceso iterativo sobre cada uno de los lados.
 Imagen de la sexta iteración del copo de nieve de Koch. Imagen de Mcgill a través de Wikimedia Commons
Imagen de la sexta iteración del copo de nieve de Koch. Imagen de Mcgill a través de Wikimedia Commons
Las delicadas obras de la serie Fractus, de Verónica Navarro, tienen unas dimensiones de 40 x 40 centímetros, el material utilizado es papel 100% algodón y están realizadas mediante la técnica del papel troquelado a mano. Si se tiene en cuenta que las formas que aparecen, además de las formas geométricas clásicas triángulo, cuadrado y circunferencia, son partes de la curva y del copo de nueve de Koch, la realización de las piezas es de una enorme dificultad y fragilidad.
En las obras aparecen diferentes capas de papel, lo que produce un contraste importante entre las formas creadas en cada capa y aparecen sombras que acentúan las formas y los contrastes. En palabras de la autora de esta serie:
“Las sugerentes sombras, creadas por la superposición de papeles troquelados, permite crear composiciones que aviven en el espectador recuerdos en forma de imágenes próximas a paisajes archivados en nuestra mente, extraídos de nuestras vivencias con la naturaleza. Y es que la geometría fractal nace con la necesidad de representar la naturaleza con la máxima fidelidad, al resultar insuficiente hacerlo a través de la geometría Euclídea.”
 Fotografía de la exposición Fractus, de Verónica Navarro, en la Casa de Cultura de Águilas (Murcia), entre el 9 de noviembre y el 9 de diciembre de 2018
Fotografía de la exposición Fractus, de Verónica Navarro, en la Casa de Cultura de Águilas (Murcia), entre el 9 de noviembre y el 9 de diciembre de 2018
Las piezas de la exposición Fractus nos pueden recordar al teatro de sombras. Más aún, la exposición está complementada con un proyector de transparencias, con el que se propone al público jugar con las sobras de triángulos, la curva de Koch y el copo de nieve de Koch.
 Fotografía del proyector de transparencias con las sombras de triángulos, la curva de Koch y el copo de nieve de Koch, de la exposición Fractus, de Verónica Navarro, en la Casa de Cultura de Águilas (Murcia), entre el 9 de noviembre y el 9 de diciembre de 2018
Fotografía del proyector de transparencias con las sombras de triángulos, la curva de Koch y el copo de nieve de Koch, de la exposición Fractus, de Verónica Navarro, en la Casa de Cultura de Águilas (Murcia), entre el 9 de noviembre y el 9 de diciembre de 2018
En definitiva, lo que propone esta artista murciana es
“un espacio en el que el público pasee por la geometría fractal, una geometría transformada por la imaginación de la artista y que sufrirá una nueva transformación originada por la mente del espectador.”
 Una de las obras de la serie Fractus (2018) de la artista Verónica Navarro. Imagen de la página web de la artista
Una de las obras de la serie Fractus (2018) de la artista Verónica Navarro. Imagen de la página web de la artista
 Una de las obras de la serie Fractus (2018) de la artista Verónica Navarro. Imagen de la página web de la artista
Una de las obras de la serie Fractus (2018) de la artista Verónica Navarro. Imagen de la página web de la artista
Bibliografía
1.- Página web del 14 de marzo, Día Internacional de las Matemáticas
2.- Ediciones PUNTODEPAPEL, arte literatura y matemáticas.
3.- Página personal de la artista Verónica Navarro
4.- Benoît Mandelbrot, How Long Is the Coast of Britain? Statistical Self-Similarity and Fractional Dimension, Science, New Series, Vol. 156, No. 3775, 1967.
5.- Benoît Mandelbrot, Los objetos fractales: forma, azar y dimensión, colección Metatemas, Tusquets, 1984.
6.- Benoît Mandelbrot, La geometría fractal de la naturaleza, colección Metatemas, Tusquets, 1982.
7.- Ma. Asunción Sastre, Geometría Fractal, Un Paseo por la Geometría 2007/2008, UPV/EHU, 2008. Versión online aquí.
8.- Julián Aguirre, Curvas fractales, Un Paseo por la Geometría 1997/1998, UPV/EHU, 1998. Versión online aquí.
9.- María Isabel Binimelis, Una nueva manera de ver el mundo, la geometría fractal, El mundo es matemático, RBA, 2010.
10.- Nicholas A. Scoville, The Cantor Set Before Cantor: A Mini-Primary Source Project for Analysis and Topology Students, Convergence, MAA, 2019
11.- Mike Seymour, The fractal nature of guardians of the galaxy vol. 2 , fxguide, 2017.
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo Fractus, arte y matemáticas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Cuadrados latinos, matemáticas y arte abstracto
- El cubo soma: diseño, arte y matemáticas
- Artistas que miran a las matemáticas
La probabilidad en mecánica cuántica
 Foto: skeeze / Pixabay
Foto: skeeze / PixabayLa dualidad onda-corpúsculo es un aspecto fundamental de la mecánica cuántica. Una de las consecuencias de este hecho es que el concepto de probabilidad se establece en la base misma del modelo.
Debemos entender bien qué significa probabilidad. Hay situaciones en la que un acontecimiento concreto no se puede predecir con certeza. Pero sí podemos predecir para estas mismas situaciones las probabilidades estadísticas de muchos acontecimientos similares. Por ejemplo, en un fin de semana largo se pueden producir en España 15 millones de desplazamientos en automóvil. Yo voy a realizar dos de esos desplazamientos, uno de ida y otro de vuelta. ¿Moriré en la carretera? No lo sé, no lo puedo saber. Pero Tráfico sabe que se va a producir del orden de 1 muerte por cada millón y medio de desplazamientos, por lo que cabe esperar que ese fin de semana se produzcan del orden de 10 muertos en carretera. No se sabe quienes van a ser pero la predicción estadística es esa. Dicho en otras palabras, el comportamiento promedio es bastante predecible.
A grandes rasgos el razonamiento para el tráfico se puede aplicar también al comportamiento de los fotones y las partículas materiales. Las limitaciones básicas en la capacidad de describir el comportamiento de una partícula individual, ya habían demostrado no ser un problema a la hora de describir el comportamiento de grandes colecciones de partículas con buena precisión; el caso más significativo quizás fuese la distribución de las velocidades moleculares de Maxwell y la teoría cinética de los gases en general.
Aquí está el quid de la cuestión: la ecuación de Schrödinger para las ondas asociadas con las partículas cuánticas da las probabilidades de encontrar las partículas en un lugar determinado y en un momento dado; no da el comportamiento preciso de una partícula individual.
Consideremos una onda electrónica que está confinada a una región concreta del espacio. Un ejemplo sería la onda de Broglie asociada con el electrón de un átomo de hidrógeno, que se extiende por todo el átomo. Otro ejemplo sería la onda de Broglie de un electrón en un buen conductor de electricidad. Pues bien, la amplitud de la onda en un punto representa la probabilidad de que el electrón esté allí. [1]
De lo anterior se sigue que, según la mecánica cuántica, el átomo de hidrógeno no consiste en una partícula negativa localizada (un electrón) que se mueve alrededor de un núcleo como en el modelo de Bohr que hemos estado usando como referencia hasta ahora. De hecho, el modelo no proporciona ninguna imagen concreta y fácilmente visualizable del átomo de hidrógeno. Una descripción de la distribución de probabilidad es lo más parecido a una imagen que proporciona la mecánica cuántica. [2]
En la teoría cinética es fácil predecir el comportamiento promedio de un gran número de partículas, a pesar de que no se sabe nada sobre el comportamiento de ninguna de ellas. Sin embargo, a diferencia de la teoría cinética, el uso de probabilidades en la mecánica cuántica no es por conveniencia, sino que parece ser una necesidad intrínseca. No hay otra forma de abordar la mecánica cuántica.
El modelo no se ocupa realmente de la posición de ningún electrón individual en ningún átomo individual, sino que ofrece una representación matemática que puede usarse para predecir interacciones con partículas, campos y radiación. Por ejemplo, se puede usar para calcular la probabilidad de que el hidrógeno emita luz de una longitud de onda concreta. La intensidad y la longitud de onda de la luz emitida por una gran cantidad de átomos de hidrógeno se pueden comparar con estos cálculos. Comparaciones como estas han demostrado que la teoría concuerda con el experimento.
Max Born, el fundador principal de la interpretación de probabilidad, condensó magistralmente la idea básica en 1926:
El movimiento de las partículas se ajusta a las leyes de probabilidad, pero la probabilidad misma se propaga de acuerdo con la ley de causalidad.
O como saben los pastores desde tiempos inmemoriales: no sabemos que hará cada oveja, pero sí lo que hará el rebaño.
Notas:
[1] Si se pudiese realizar una medición de la ubicación del electrón, se entiende.
[2] El lector interesado en una lectura más filosófica de esta consecuencia puede ver El universo ametafórico y La verdadera composición última del universo (y IV): Platónicos, digitales y pansiquistas
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo La probabilidad en mecánica cuántica se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Construyendo la mecánica cuántica
- El comportamiento corpuscular de la luz: el efecto Compton
- El comportamiento ondulatorio de los electrones
Motivos para un día internacional
Hemos ido a un centro de enseñanza y hemos preguntado a un grupo de jóvenes a qué científicas conocen. Han nombrado a Marie Curie, a nadie más.
A partir de ahí se ha iniciado un diálogo entre el grupo acerca de la presencia de las mujeres en el mundo de la ciencia. Se han referido, entre otras cosas, a la falta de reconocimiento, al hecho de que antes las mujeres tenían vedado el acceso de determinados estudios, y a la orientación mayoritaria de las mujeres a profesiones relacionadas con la atención y cuidado de las personas. Exponen diferentes puntos de vista y mencionan la existencia de presiones sociales y familiares para orientar la formación y vidas profesionales de las chicas en una u otra dirección.

Tienen la impresión de que las cosas han mejorado y la idea de que ahora ellas pueden escoger lo que quieran ser.
Todas estas son cuestiones que atañen a los motivos por los que, cada 11 de febrero, se celebra el Día Internacional de la Mujer y la Niña en la Ciencia. Hay una presencia desigual de chicos y chicas en unos y otros estudios y, sobre todo, hay muy pocas chicas que se decantan por estudiar grados y posgrados de disciplinas a las que se atribuye una especial dificultad y para los que se supone es necesario ser especialmente brillante. Las diferencias en el acceso a unos y otros estudios tienen después consecuencias sociales y económicas, pues contribuyen a generar brechas sociales y económicas o ampliar las ya existentes.
La Universidad del País Vasco está comprometida con el objetivo de una sociedad en la que hombres y mujeres tengan los mismos derechos y gocen de las mismas oportunidades. La Cátedra de Cultura Científica de la UPV/EHU comparte ese compromiso y se ha propuesto, en la medida de sus modestas posibilidades, contribuir a cambiar ese estado de cosas. Por esa razón publica desde el 8 de mayo de 2014 Mujeres con ciencia.
Pero hoy, 11 de febrero, no hemos querido quedar al margen de la celebración internacional, promovida por Naciones Unidas del Día Internacional de la Mujer y la Niña en la Ciencia. Con ese propósito hemos producido el vídeo Somos capaces, que acompaña este texto. Hemos querido mostrar la visión que jóvenes que cursan estudios preuniversitarios tienen de la situación de las mujeres en el mundo de la ciencia.
Compartimos con los chicos y chicas que aparecen en el vídeo la disconformidad con un estado de cosas injusto, y queremos compartir también el optimismo y la confianza en sus capacidades que expresan. Pero para que ese optimismo se justifique con avances en la igualdad de derechos y oportunidades de hombres y mujeres es preciso actuar y seguir trabajando. Ese es el propósito de la Cátedra de Cultura Científica. Y por esa razón, para nosotros, mañana, como ayer, también será día de la mujer y la niña en la ciencia.
Somos capaces es una producción de K2000, ha sido dirigido por Jose A. Pérez Ledo, la música es de Borrtex (Christmas Tree) y ha sido grabado en Begoñazpi Ikastola (Bizkaia), a la que queremos agradecer su colaboración en el proyecto. Este vídeo ha contado con la colaboración de Iberdrola.
—————————————————————–
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
Más sobre el 11 de febrero
- Juan Ignacio Pérez, Hoy es el día de la mujer y la niña en la ciencia, todos lo son, 11 febrero 2016.
- Juan Ignacio Pérez, No es una percepción, 11 febrero 2017.
- Juan Ignacio Pérez, Mi hija quiere ser ingeniera, 11 febrero 2018.
El artículo Motivos para un día internacional se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Comienza Jakin-mina, el programa de conferencias para estudiantes de 4 de ESO
- Hoy es el día de la mujer y la niña en la ciencia, todos lo son
- Ciencia Clip: un concurso de vídeos de ciencia para jóvenes estudiantes
Sesgos cognitivos que aquejan a la ciencia
 Linus Pauling (1901-1994). Ganador de dos premios Nobel. Uno de los padres de la química cuántica y de la biología molecular. Pacifista y activista. Pero también prisionero de sus sesgos cognitivos. Padre de la medicina ortomolecular (sin base científica; una superchería inventada en un sillón, como el psicoanálisis de Freud o la homeopatía de Hahnemann) y perseguidor arrogante, hostil e incansable de Dan Shechtman, los cuasicristales y de cualquiera que trabajase en ellos desde su descubrimiento en 1984 hasta la muerte del propio Pauling en 1994 (Shechtman recibiría el Nobel en 2011 por el descubrimiento de los cuasicristales).
Linus Pauling (1901-1994). Ganador de dos premios Nobel. Uno de los padres de la química cuántica y de la biología molecular. Pacifista y activista. Pero también prisionero de sus sesgos cognitivos. Padre de la medicina ortomolecular (sin base científica; una superchería inventada en un sillón, como el psicoanálisis de Freud o la homeopatía de Hahnemann) y perseguidor arrogante, hostil e incansable de Dan Shechtman, los cuasicristales y de cualquiera que trabajase en ellos desde su descubrimiento en 1984 hasta la muerte del propio Pauling en 1994 (Shechtman recibiría el Nobel en 2011 por el descubrimiento de los cuasicristales).Algunas de las modalidades de fraude, así como los casos de ciencia patológica vistos en anotaciones anteriores no se producirían de no ser por la existencia de malas prácticas y sesgos que los facilitan o, incluso, los propician.
En lo relativo a los sesgos, estos pueden ser de dos tipos. Están, por un lado, los que afectan a las personas concretas que practican la investigación científica. Y por el otro, los que afectan al funcionamiento del sistema en su conjunto y a los que podríamos denominar sistémicos. Eso que se suele denominar “método científico” no deja de ser, en el fondo, un conjunto de estrategias que se han ido poniendo en práctica para evitar los sesgos que afectan a los científicos; se trata, por lo tanto, de que el conocimiento no dependa de la persona que lo produce y que, por esa razón, tenga la máxima validez posible. Los sesgos sistémicos precisan de otro tipo de medidas para su corrección pues no afectan a los individuoa, sino al conjunto del sistema.
El sesgo de confirmación lleva a favorecer, interpretar y recordar la información que confirma las creencias o hipótesis propias. Es un sesgo que nos afecta a todos, también opera en la actividad científica. Una variante de este sesgo es la que afecta a las publicaciones científicas, aunque en este caso se suele denominar sesgo de publicación. Es la tendencia a publicar solamente resultados positivos, confirmatorios. Incluye también la tendencia a publicar resultados novedosos, que anticipan interesantes desarrollos científicos. Por esa razón, puede consistir en la confirmación de los resultados que avalan la hipótesis de partida, los de investigaciones anteriores que han abierto una nueva vía o, incluso, resultados acerca de los cuales de piensa que abren nuevas posibilidades. Lo que no se suelen publicar son resultados que simplemente no confirman las hipótesis de partida.
Los evaluadores de las revistas (los pares) tienen la tendencia a rechazar la publicación de resultados negativos con el argumento de que no suponen una aportación relevante al campo de conocimiento. Además, como ha mostrado Fanelli (2010), ese fenómeno se acentúa en las disciplinas consideradas “ciencias blandas”. O sea, es de menor importancia en física o química, intermedia en ciencias biomédicas y máxima en ciencias cognitivas o sociales. Mientras que el sesgo de confirmación es personal, el de publicación, sin embargo, es sistémico.
El sesgo retrospectivo consiste en proponer post hoc una hipótesis como si se hubiese formulado a priori. En otras palabras, se adapta la hipótesis de un trabajo a los resultados obtenidos. Este sesgo actúa porque la hipótesis original que era el punto de partida de la investigación no se suele publicar con anterioridad. Kerr (1998) denomina a esta práctica HARking (de HARK: Hypothesizing After the Results are Known). El problema del HARKing radica en que eleva la probabilidad de rechazar erróneamente una hipótesis nula, o sea, de que se produzcan errores de tipo I (falsos positivos). También conduce, de manera indirecta, a un despilfarro de recursos, tanto de tiempo como de dinero, ya que se necesitan más estudios de los que deberían ser necesarios para mostrar que no se producen los efectos que se producen.
El psicólogo Brian Nosek, de la Universidad de Virginia, sostiene que el sesgo más común y de mayores consecuencias en ciencia es el razonamiento motivado, que consiste en interpretar los resultados de acuerdo con una idea preconcebida. La mayor parte de nuestro razonamiento es, en realidad, racionalización. En otras palabras, una vez tomada una decisión acerca de qué hacer o de qué pensar sobre algo, nuestro razonamiento es una justificación post hoc por pensar o hacer lo que queremos o lo que creemos (Ball, 2017).
Karl Popper sostenía que los científicos buscan refutar las conclusiones a que han llegado otros científicos o ellos mismos. Esa es la forma en que, a su entender, avanza la ciencia. La práctica real es, sin embargo, diferente. Lo normal es que los científicos busquemos la manera de verificar nuestros hallazgos o los de los científicos con los que nos alineamos. Por eso, cuando los datos contradicen las expectativas, no es extraño que se rechacen por irrelevantes o erróneos.
Estos sesgos ejercen un efecto muy importante debido a que para los investigadores es crucial publicar artículos con sus resultados en revistas importantes. Es clave pata obtener la estabilidad en el puesto de trabajo, para promocionarse, para obtener financiación para sus proyectos, en definitiva, para ser reconocidos en su comunidad. Y para poder publicarlos, han de acomodarse a lo que se ha señalado antes: descartar resultados negativos, seleccionar los positivos y, si es posible, dar cuenta de hallazgos que sean considerados relevantes para el avance del conocimiento. La presión por publicar es tan fuerte que provoca una relajación de los controles subjetivos frente a los sesgos personales e introduce sesgos sistémicos, dirigiendo el tipo de investigaciones que se hacen y los resultados que se reportan, dado que las revistas acepatan más fácilmente resultados positivos.
Curiosamente, sin embargo, tampoco resulta fácil conseguir que se acepten para su publicación resultados verdaderamente revolucionarios. En cierto modo eso es lógico, ya que el escepticismo obliga a tomar con cautela todas las alegaciones relativas a hallazgos novedosos y a exigir que superen el cedazo de la prueba o, al menos, que las evidencias a su favor sean muy sólidas. Pero eso no quiere decir que esas alegaciones se desestimen o se les opongan obstáculos difícilmente salvables sin darles la debida oportunidad. Eso es lo que ocurrió con las investigaciones de, entre otros, Barbara McClintock (Nobel en 1984), Stanley Prusiner (Nobel en 1997), Robin Warren y Barry Marshall (Nobel en 2005), o Dan Shechtman (Nobel en 2011) cuyos descubrimientos necesitaron más tiempo y esfuerzo del que debería haber sido necesario para su aceptación. Y no sabemos en cuántas ocasiones resultados de similar trascendencia y carácter revolucionario han sido silenciados. Por lo tanto, no se trata solo de que ideas erróneas pervivan durante demasiado tiempo, sino que además, estos sesgos suponen un obstáculo serio para que nuevos descubrimientos e ideas se abran paso y se afiancen en el bagaje universal del conocimiento.
Los científicos solemos decir que la ciencia se corrige a sí misma. Y es cierto, pero a veces pasa demasiado tiempo hasta que se produce la corrección. Y a veces la corrección se hace con alto coste para quienes se atreven a desafiar el status quo. Las dificultades para la corrección se deben, en parte, a lo que hemos expuesto aquí. Pero también a que no se suelen intentar replicar las investigaciones y cuando se replican, es relativamente probable que no se reproduzcan los resultados originales. Pero de eso nos ocuparemos en una próxima anotación.
Para acabar, merece la pena reseñar, eso sí, que ya se han hecho propuestas concretas para mejorar la fiabilidad de los resultados que se publican (Ioannidis, 2014). Propone, entre otras, la participación en proyectos colaborativos de gran alcance, generalizar una cultura de la replicación, registrar los proyectos con sus hipótesis de partida antes de empezarlos y mejorar los métodos estadísticos. Algunas de esas propuestas se están llevando a la práctica.
Este artículo se publicó originalmente en el blog de Jakiunde. Artículo original.
Sobre los autores: Juan Ignacio Perez Iglesias es Director de la Cátedra de Cultura Científica de la UPV/EHU y Joaquín Sevilla Moroder es Director de Cultura y Divulgación de la UPNA.
El artículo Sesgos cognitivos que aquejan a la ciencia se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Los primeros pasos de la evolución darwiniana y sesgos cognitivos y evolución (Día de Darwin 2018)
- Ciencia Patológica
- #Naukas14 Algunos trucos para reducir sesgos
Orriak
- « lehenengoa
- ‹ aurrekoa
- …
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- …
- hurrengoa ›
- azkena »