

Un modelo simple de gas

¿Cuáles son las diferencias entre un gas y un líquido o un sólido? Sabemos por experiencia que, si no se comprimen, los líquidos y los sólidos tienen volumen definido. Incluso si sus formas cambian, todavía ocupan la misma cantidad de espacio. Un gas, por otra parte, se expandirá espontáneamente para llenar cualquier recipiente (como una habitación). Si no está confinado, saldrá y se extenderá en todas direcciones [1].
Los gases tienen densidades bajas en comparación con los de líquidos y sólidos, típicamente alrededor de 1000 veces más pequeñas. Por lo tanto, las moléculas [2] de gas suelen estar relativamente alejadas unas de otras. En el modelo de un gas que vamos a construir, podemos suponer razonablemente que las fuerzas entre las moléculas actúan sólo a distancias muy cortas. En otras palabras, las moléculas de gas se consideran que se mueven libremente la mayor parte del tiempo. En los líquidos, las moléculas están más juntas, las fuerzas actúan continuamente entre ellas y les impiden que se separen demasiado. En los sólidos, las moléculas suelen estar aún más juntas, y las fuerzas entre ellas las mantienen en una disposición más (cristales) o menos (vidrios) definida.
Antes de continuar quizás convengan recordar que vamos a plantear un modelo teórico de un gas. Este modelo existirá, por tanto, solo en nuestra imaginación. Al igual que los puntos, las líneas, los triángulos y las esferas que se estudian en geometría, este modelo teórico podrá ser tratado matemáticamente. Los resultados de este tratamiento pretenden comprender el mundo real aunque, por supuesto, previamente el modelo tendrá que ser comprobado experimentalmente a fin de ver si se aproxima a la realidad.
![]()
Nuestro modelo inicial de un gas es por tanto muy simple, siguiendo el consejo de Newton de comenzar con las hipótesis más simples. Asumiremos que las moléculas son pequeñas esferas o grupos de esferas que no ejercen ninguna fuerza en las demás salvo cuando hacen contacto. Además, supondremos que todas las colisiones de estas esferas son perfectamente elásticas, esto es, la energía cinética total de dos esferas es la misma antes y después de chocar, no hay pérdidas.
Nuestro modelo teórico considera que el gas consiste en un gran número de partículas muy pequeñas en movimiento rápido y desordenado. “Un gran número” significa algo así como un trillón (1018) o más partículas en una muestra tan pequeña como una burbuja en un refresco. “Muy pequeño” significa un diámetro claramente inferior a un nanómetro (10-9 m) para cada una de esas partículas. “Movimiento rápido” significa una velocidad media a temperaturas normales de unos cuantos cientos de metros por segundo.
El concepto “desordenado” es algo más prolijo de explicar. Los teóricos cinéticos del siglo XIX supusieron que cada molécula individual se movía de manera definida, determinada por las leyes del movimiento de Newton. Por supuesto, en la práctica es imposible seguir billones y billones de partículas al mismo tiempo. Se mueven en todas direcciones y cada partícula cambia su dirección y velocidad durante las colisiones con otras partículas o con la pared del recipiente. Por lo tanto, no podemos hacer una predicción definida del movimiento de ninguna partícula individual. Por contra, debemos contentarnos con describir el comportamiento promedio de grandes colecciones de partículas. De un momento a otro, cada molécula individual se comporta de acuerdo con las leyes del movimiento. Pero es más fácil describir el comportamiento promedio, y asumir completa ignorancia sobre cualquier movimiento individual.
Para ver por qué esto es así, imagina los resultados de lanzar al aire un gran número de monedas a la vez. Si asumimos que las monedas se comportan al azar, puedes predecir con confianza que lanzar un millón de monedas dará aproximadamente 50% de caras y 50% de cruces. El mismo principio se aplica a las moléculas de gas rebotando en un contenedor. Puedes asumir con seguridad, por ejemplo, que se mueven en una dirección tantas como lo hacen en cualquier otra. Además, en un momento dado el mismo número de moléculas es igualmente probable que se encuentre en cualquier centímetro cúbico de espacio dentro del contenedor como en cualquier otro. “Desordenado”, entonces, significa que las velocidades y las posiciones se distribuyen al azar. Cada molécula es tan probable que esté moviéndose a la derecha como a la izquierda (o en cualquier otra dirección). Es tan probable que esté cerca del centro como cerca del borde (o en cualquier otra posición).
Ya tenemos construido nuestro modelo. Ahora a ver cómo se comporta y a ver que extraemos de ello. Eso será en las próximas entregas de esta serie.
Notas:
[1] El confinamiento no implica la existencia de un contenedor, aunque en este texto asumamos implícitamente que sí por simplicidad. Un gas puede estar confinado por la gravedad, como en una estrella o, sin ir más lejos, en la atmósfera, aunque no sea un confinamiento completamente estanco.
[2] Empleamos “moléculas” y no “átomos” por generalidad del concepto. Los gases constituidos por átomos que no forman parte de una molécula son una minoría frente a todos los gases moleculares posibles.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Un modelo simple de gas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Una cuestión de movimiento
- La ley del gas ideal y la tercera ley de la termodinámica
- La segunda ley de la termodinámica
El consumo de alcohol para el corazón y las dificultades de divulgar ciencia
Javier Sánchez Perona
Es frecuente encontrar divulgadores científicos de nutrición que rechazan de forma tajante el consumo de alcohol, negando las creencias previas, que tan extendidas están en nuestra sociedad y nuestra cultura. Esas creencias que dicen que el consumo de alcohol de forma moderada es saludable para el corazón.
El máximo exponente de esta corriente es probablemente Julio Basulto. A Julio, lo mismo que a los otros divulgadores científicos, lo respeto muchísimo porque la labor que hacen es compleja, ingente y muy necesaria. Sin embargo, en algunas ocasiones me da la impresión de que algunos divulgadores somos demasiado categóricos con algunas afirmaciones. Realmente, es complicado divulgar, porque el público normalmente exige respuestas contundentes y en ciencia no siempre es fácil ser riguroso y contundente al mismo tiempo. Además la ciencia es dinámica, lo que hoy se da por sentado puede ser rebatido mañana. Las demostraciones científicas se obtienen tras muchos tipos de estudios que van aportando pequeñas evidencias, algunas con más potencia que otras, pero esos matices son difíciles de explicar al gran público. Aquí os dejo una charla Ted de Julio Basulto sobre el consumo de alcohol, que se ha hecho bastante viral.
Otra de mis divulgadoras favoritas es Deborah García Bello, que ha publicado muy recientemente un artículo sobre el consumo de alcohol, siguiendo la misma tesis que Julio Basulto: el consumo se alcohol es perjudicial siempre y en toda cantidad.
En su artículo, Deborah sostiene que el fundamento de que “el consumo de alcohol es saludable” proviene de los experimentos realizados con resveratrol, un polifenol presente en el vino. A este compuesto se han atribuido multitud de efectos, la mayoría positivos, sobre la salud. Yo llegué a escuchar a alguien decir que “si quieres que te salga algo en un experimento in vitro, ponle resveratrol, que hace de todo”. Sin embargo, los efectos del resveratrol no han sido aún probados en humanos.
En el artículo, Déborah hace una recopilación del conocimiento científico hasta la fecha sobre el consumo de alcohol y la opinión de algunas organizaciones de referencia, como la Organización Mundial de la Salud (OMS). En el informe de la OMS, Alcohol in the European Union, que es de 2012, se dice “el uso del alcohol está relacionado de forma abrumadora y perjudicial con muchos eventos cardiovasculares, incluyendo la enfermedad hipertensiva, accidente cerebrovascular hemorrágico y fibrilación auricular”. Pero lo que no menciona Déborah es que en el mismo párrafo se dice que “Para la cardiopatía isquémica y el accidente cerebrovascular isquémico, la relación es más compleja.” O sea, que para estos otros eventos cardiovasculares, no está tan claro si es consumo de alcohol es perjudicial. Y ya estamos con el problema de siempre. En estas condiciones es muy complicado responder a la pregunta ¿el alcohol es bueno para el corazón? Para poder responder rigurosamente habría que explicar los matices de accidente cerebrovascular hemorrágico y accidente cerebrovascular isquémico y eso no es tan fácil.
Siguiendo con el informe de la OMS, en el mismo párrafo dice. “Pero, por término medio, el consumo ligero a moderado tiene un efecto protector sobre las enfermedades isquémicas (Roerecke & Rehm, en prensa). Este efecto se encuentra igual para las personas que sólo beben cerveza o que sólo beben vino”. Y cuando ya parecía que el consumo moderado de cerveza sí podría tener un beneficio, el mismo párrafo le da otra vuelta. “Sin embargo, cada vez más se entiende que gran parte de este efecto se debe a factores de confusión (Roerecke & Rehm, 2010)”. Los factores de confusión son variables que se deben tener en cuenta a la hora de establecer las relaciones entre alcohol y salud. Por ejemplo, el estatus económico, la edad, la educación, el consumo de tabaco, drogas, etc. Muchas veces si no se tienen en cuenta estos confundidores aparecen relaciones donde en realidad no las hay. Por ejemplo, las personas que consumen vino habitualmente podrían tener mejor calidad de vida, pero no debido a las virtudes del vino, sino a su mayor poder adquisitivo.
Como habéis visto, en el párrafo anterior he citado a Roerecke y Rehm, investigadores de la Universidad de Toronto (Canadá), lo que me sirve para ejemplificar que el debate sobre el consumo moderado de alcohol sigue vigente. Estos autores hablan de la influencia de los confundidores, pero ellos mismos en un meta-análisis de estudios observacionales publicado en la revista Addiction en 2012, concluían que “Este estudio demostró que la mayor parte del efecto cardioprotector se puede lograr ya con 1-2 bebidas/día para los hombres y 1 bebida/día para las mujeres.” [1].
Y ahora viene lo bueno. ¡Guerra de científicos! Tras esta conclusión, Tim Stockwell, de la Universidad de Victoria (Canada), respondió con un comentario en la misma revista [2]. “Los autores señalan que la mayoría de los estudios incluidos fueron muy pobres. Muy pocos controlaron factores de confusión potenciales del estilo de vida (por ejemplo, no fumar) que pudieran estar correlacionados tanto con el consumo moderado de alcohol como con la salud, muy pocos controlados directamente por la inclusión de ex bebedores en el grupo de referencia ‘abstemio’ y muchos evaluaron la bebida al inicio durante un período de tiempo relativamente corto.” O sea, que según Stockwell, Roerecke y Rehm no habían elegido bien los estudios incluidos en su meta-análisis.
¿Qué es lo ideal que tiene que hacer un científico cuando hace una crítica de ese tipo? Replicar el estudio. Si los demás lo han hecho mal, él lo hará bien. Y eso hizo Stockwell. En 2016, publicó otro meta-análisis en el que incluyó más estudios que Roerecke y Rehm y se publicó en la revista Journal of Studies on Alcohol and Drugs [3]. Stockwell concluyó que “Las estimaciones del riesgo de mortalidad por el alcohol están significativamente alteradas por el diseño y las características del estudio. Los metaanálisis que ajustan para estos factores encuentran que el consumo de alcohol en volumen pequeño no tiene un beneficio neto de mortalidad en comparación con la abstención de por vida o el consumo ocasional de alcohol.” Dicho de otro modo, el consumo moderado de alcohol no es protector, y si otros estudios lo han encontrado es porque estaban mal diseñados. Este estudio se menciona en el artículo de Deborah también.
¿Pero pensabais que Roerecke y Rehm no tendrían una respuesta? Si es así os equivocabais. La publicaron en la misma revista [4]. Resulta que el estudio de Stockwell también tenía deficiencias: “Los estudios disponibles para el análisis de Stockwell son de cohortes seleccionadas de un rango limitado de sociedades, con importantes deficiencias metodológicas. La mayoría de los estudios dependen de una sola medida auto-reportada del volumen de bebida al momento de la inscripción en el estudio.” Y llegan a decir que no es posible comparar sociedades donde el consumo de alcohol es cultural y habitual con sociedades donde ser abstemio es lo normal: “Parece imposible determinar comparaciones verdaderas con la abstención en los países occidentales de altos ingresos. Los estudios prospectivos en países donde la abstención no es una anomalía cultural podrían ayudar a cuantificar los efectos.”
A Stockwell también le respondieron otros investigadores y de forma mucho más contundente [5]. En primer lugar porque se trata de investigadores que forman parte del Foro Científico Internacional de Investigación sobre Alcohol. Es importante señalar que este foro declara no recibir apoyo de ninguna organización o empresa de la industria de bebidas alcohólicas y que no tienen conflictos de interés. Y en segundo lugar por este comentario final: “En opinión de nuestro Foro, el artículo de Stockwell et al. distorsiona la evidencia científica acumulada sobre el alcohol y la mortalidad. La preocupación es que la selección sesgada de los estudios socava el valor del artículo, pero, lo que es más importante, promulga la desinformación en nombre del método científico.” ¡Toma ya! Pocas veces se puede leer algo tan duro en una revista científica.
En definitiva, parece que no está ni mucho menos claro que el consumo moderado de alcohol sea perjudicial para el corazón y que el debate está en su apogeo. Hace un par de meses, el grupo de Roerecke y Rehm publicó el último meta-análisis [6]: “Cuanto más alcohol se consume, mayor es el riesgo de enfermedad o muerte. Las excepciones fueron las enfermedades isquémicas y la diabetes, con relaciones curvilíneas, y con efectos beneficiosos en personas que beben de forma ligera o moderada, sin ocasiones irregulares en que beben grandes cantidades.” Con relaciones curvilíenas se refieren a la famosa curva J, que indica que el consumo moderado es más beneficioso que no consumir alcohol pero que los grandes consumidores tienen un riesgo mucho mayor (Figura 1).

Figura 1. Imagen tomada de Basulto J. La verdadera “curva en J” del alcohol, accedido el 28/08/2017
En este estudio, Roerecke y Rehm también admitían que se necesita tener en cuenta muchos más factores además de la cantidad de alcohol. El equipo de Miguel Angel Martínez-González, de la Universidad de Navarra, publicó en 2014 un estudio observacional en el que se tuvieron en cuenta, además de la cantidad de alcohol consumida diaria, la frecuencia de consumo semanal, el tipo de bebida alcohólica, si se come preferentemente con las comidas y si se abusa en algunas ocasiones [7]. Teniendo en cuenta todos estos factores, concluyeron que un patrón de consumo mediterráneo (consumo moderado diario, sobre todo de vino, durante las comidas y sin abuso irregular) conduce a un menor riesgo de mortalidad en comparación con los abstemios.
Como veis, el problema se suscita porque el grado de evidencia existente no es lo suficientemente alto. No existen por el momento suficientes datos de ensayos clínicos, que aportan un mayor nivel de evidencia científica. Por el momento los estudios está realizados en pequeños grupos de 20-40 personas [8-9], y están enfocados a marcadores asociados a la enfermedad cardiovascular, pero no a mortalidad o eventos primarios como el infarto o el ictus. Tendremos que esperar.
En conclusión, hay un fuerte debate científico todavía sobre los perjuicios y beneficios del consumo de alcohol. Por supuesto, no hay discusión sobre el consumo de alcohol en grandes cantidades, pero sí cuando el consumo es moderado y consiste en vino o cerveza. Aún no tenemos suficientes estudios clínicos para hacer afirmaciones demasiado rotundas sobre si el consumo de una copa de vino o cerveza al día puede ser beneficioso. Por tanto, me parece un poco arriesgado ser categórico, aunque sea lo que el público demande de un divulgador.
Referencias
1. Roerecke M, Rehm J. The cardioprotective association of average alcohol consumption and ischaemic heart disease: a systematic review and meta-analysis. Addiction. 2012;107(7):1246-60.
2. Stockwell T. Commentary on Roerecke & Rehm (2012): The state of the science on moderate drinking and health–a case of heterogeneity in and heterogeneity out? Addiction. 2012;107:1261-2.
3. Stockwell T, Zhao J, Panwar S, Roemer A, Naimi T, Chikritzhs T. Do “Moderate” Drinkers Have Reduced Mortality Risk? A Systematic Review and Meta-Analysis of Alcohol Consumption and All-Cause Mortality. J Stud Alcohol Drugs. 2016;77(2):185-98.
4. Rehm J, Roerecke M, Room R. All-Cause Mortality Risks for “Moderate Drinkers”: What Are the Implications for Burden-of-Disease Studies and Low Risk-Drinking Guidelines? J Stud Alcohol Drugs. 2016;77(2):203-4; discussion 205-7.
5. Barrett-Connor E, de Gaetano G, Djoussé L, Ellison RC, Estruch R, Finkel H, Goldfinger T, Keil U, Lanzmann-Petithory D, Mattivi F, Skovenborg E, Stockley C, Svilaas A, Teissedre PL, Thelle DS, Ursini F, Waterhouse AL. Comments on Moderate Alcohol Consumption and Mortality. J Stud Alcohol Drugs. 2016;77(5):834-6.
6. Rehm J, Gmel GE Sr, Gmel G, Hasan OSM, Imtiaz S, Popova S, Probst C, Roerecke M, Room R, Samokhvalov AV, Shield KD, Shuper PA. The relationship between different dimensions of alcohol use and the burden of disease-an update. Addiction. 2017;112(6):968-1001.
7. Gea A, Bes-Rastrollo M, Toledo E, Garcia-Lopez M, Beunza JJ, Estruch R, Martinez-Gonzalez MA. Mediterranean alcohol-drinking pattern and mortality in the SUN (Seguimiento Universidad de Navarra) Project: a prospective cohort study. Br J Nutr. 2014;111(10):1871-80.
8. Estruch R, Sacanella E, Mota F, Chiva-Blanch G, Antúnez E, Casals E, Deulofeu R, Rotilio D, Andres-Lacueva C, Lamuela-Raventos RM, de Gaetano G, Urbano-Marquez A. Moderate consumption of red wine, but not gin, decreases erythrocyte superoxide dismutase activity: a randomised cross-over trial. Nutr Metab Cardiovasc Dis. 2011;21(1):46-53.
9. Mori TA, Burke V, Zilkens RR, Hodgson JM, Beilin LJ, Puddey IB. The effects of alcohol on ambulatory blood pressure and other cardiovascular risk factors in type 2 diabetes: a randomized intervention. J Hypertens. 2016;34(3):421-8.
Sobre el autor: Javier Sánchez Perona (@MrChylo) es Científico Titular del Instituto de la Grasa-CSIC y Profesor Asociado de la Universidad Pablo de Olavide. Trabaja en el conocimiento de los mecanismos implicados en el transporte y metabolismo de los lípidos en humanos, así como en las repercusiones que tienen las grasas de la dieta y sus compuestos bioactivos sobre las enfermedades metabólicas. Es miembro de Ciencia Con Futuro y divulga en el blog Malnutridos
El artículo El consumo de alcohol para el corazón y las dificultades de divulgar ciencia se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- «Una copita de vino es buena para el corazón». Claro que sí, guapi.
- Daños estructurales por consumo de alcohol en el cerebro humano
- Beber alcohol produce cáncer
Resveratrol y pteroestilbeno en el control epigenético de la acumulación de grasa corporal
Ana Gracia Jadraque ha demostrado, en su tesis doctoral defendida en la Universidad del País Vasco/Euskal Herriko Unibertsitatea, que los cambios producidos por los compuestos fenólicos resveratrol y el pterostilbeno en la adición de grupos metilo al ADN y a los microRNAs están involucrados en la prevención de la acumulación de grasa corporal.

ADN metilado (las esferas blancas representan grupos metilo)
En los últimos años, está cobrando mucho interés la regulación de genes a través de la metilación del ADN, proceso epigenético (mecanismo que regula la expresión de genes) que produce cambios en la actividad del ADN sin alterar su secuencia, y su control mediante pequeños fragmentos de RNA llamados microRNAs. Este tipo de regulación tiene gran importancia tanto en la fisiopatología de diversas enfermedades comunes en nuestra sociedad como en el tratamiento de las mismas. Asimismo, la dieta es un factor ambiental que ha demostrado ejercer una influencia importante sobre estos procesos de regulación. En concreto, se ha demostrado que diversos compuestos bioactivos, presentes en los alimentos, son capaces de modificar la metilación del ADN y la expresión de microRNAs.
Los resultados de la tesis defendida por Ana Gracia Jadraque, ‘Implicación de la metilación del ADN y los microRNAs en el efecto delipidante de los estilbenos en el tejido adiposo y el hígado’, basados en estudios realizados en modelos animales con obesidad, demuestran que el pterostilbeno provoca modificaciones en el grado de metilación de una de las enzimas (proteínas que llevan a cabo reacciones químicas dentro del organismo) involucradas en la lipogénesis de novo, ruta por la que se forman ácidos grasos nuevos para ser almacenados en el tejido adiposo, además de interactuar directamente con las enzimas responsables de realizar estas marcas epigenéticas (DNMTs).
Aunque esa alteración de la lipogénsis de novo no se produce con el tratamiento con resveratrol, presente entre otros en frutos rojos como uva y derivados, sí produjo cambios en la regulación de varios microRNAs en el tejido adiposo blanco. Varios de los microRNAs modificados tienen relación con genes del metabolismo de los triglicéridos, ejerciendo algunos de ellos una regulación indirecta sobre la formación de ácidos grasos.
Un segundo estudio realizado en hígado, ha proporcionado nuevas pruebas que muestran que el resveratrol disminuye la expresión de microRNAs altamente expresados en ese órgano. Como resultado, se ha observado que un aumento de la expresión y de la actividad de una enzima involucrada en la b-oxidación de ácidos grasos, ruta metabólica que degrada ácidos grasos para formar energía, puede ser debido a una modulación de la expresión de microRNAs mediada por el resveratrol.
Estos cambios producidos por ambos compuestos fenólicos en la metilación del ADN y en los microRNAs están involucrados en la prevención de la acumulación de grasa corporal.
Estudios previos, realizados por el grupo de investigación Nutrición y Obesidad del Departamento de Farmacia y Ciencias de los Alimentos de la UPV/EHU, ya pusieron de manifiesto que algunos compuestos fenólicos, como el resveratrol y el pterostilbeno, eran capaces de prevenir la obesidad inducida por dietas ricas en grasa saturada y azúcares simples en modelos animales. Debido al escaso conocimiento de los efectos de estos compuestos por mecanismos epigenéticos y microRNAs, esta tesis doctoral se ha centrado en el estudio de esos dos aspectos moleculares sobre el metabolismo de los triglicéridos. Para ello, se llevaron a cabo dos enfoques. El primero fue analizar la posible influencia del resveratrol y pterostilbeno sobre la metilación del ADN en la acumulación de triglicéridos en el tejido adiposo y, el segundo, establecer la participación del resveratrol en la regulación post-transcripcional por microRNAs en el tejido adiposo y la acumulación de grasa hepática.
Referencias:
Gracia A, Fernández-Quintela A, Miranda J, Eseberri I, González M, Portillo MP (2017) Are miRNA-103, miRNA-107 and miRNA-122 Involved in the Prevention of Liver Steatosis Induced by Resveratrol? Nutrients doi: 10.3390/nu9040360
Gracia A, Miranda J, Fernández-Quintela A, Eseberri I, Garcia-Lacarte M, Milagro FI, Martínez JA, Aguirre L, Portillo MP (2016) Involvement of miR-539-5p in the inhibition of de novo lipogenesis induced by resveratrol in white adipose tissue Food Funct. doi: 10.1039/c5fo01090j
Gracia A, Elcoroaristizabal X, Fernández-Quintela A, Miranda J, Bediaga NG, M de Pancorbo M, Rimando AM, Portillo MP (2014) Fatty acid synthase methylation levels in adipose tissue: effects of an obesogenic diet and phenol compounds Genes Nutr. doi: 10.1007/s12263-014-0411-9
El artículo Resveratrol y pteroestilbeno en el control epigenético de la acumulación de grasa corporal se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La combinación de dos moléculas marroniza la grasa
- El pteroestilbeno como posible tratamiento de la obesidad
- La grasa abdominal no depende del ejercicio que hagas sino de la grasa que consumas
El arte de innovar, de Javier Echeverría
Juan Ignacio Pérez Iglesias, lector

La noción de innovación se adueñó hace ya bastantes años del lenguaje de gestores y políticos relacionados con la industria y con lo que antes se había venido denominando I+D (investigación y desarrollo) a secas. Esa innovación en el lenguaje obedecía, a mi juicio, a que gestores y políticos, en su gran mayoría, consideran el conocimiento (a secas) un lujo cultural que está bien pero que resulta, a todas luces, limitado y, si es el caso, prescindible. No les parecía suficiente la D de desarrollo (tecnológico), y encontraron en la i minúscula una posible vía para reorientar las políticas de apoyo a la generación de conocimiento y ámbitos relacionados con estas. La opción por la i minúscula se vio favorecida por los intereses de ciertos agentes que habían encontrado limitaciones para acceder al sistema de I+D (o sea, a sus fondos) tal y como se hallaba configurado y vieron en la i minúscula una posible vía para superar la limitación.
Es así como un servidor ha interpretado la irrupción de esa i en el mundo de las instituciones e industrias muy dependientes del conocimiento avanzado y de las políticas públicas dirigidas a su promoción. Pero lo más probable es que esté perfectamente equivocado, por supuesto.
Se acaba de publicar un libro raro. Se titula El arte de innovar. Naturalezas, lenguajes, sociedades y aunque el título no lo expresa con claridad, la obra tiene por objeto elaborar las que podrían ser bases para un desarrollo de una nueva disciplina, que podría denominarse innología, en la que se englobarían estudios sobre innovación y muy en particular, una filosofía de la innovación.
Lo cierto es que hasta que no lo leí en el texto no había sido consciente de que tal cosa, filosofía de la innovación, no existe o, al menos, no existe con carácter formal. Existen la epistemología, la axiología y la filosofía de la ciencia, pero no existe nada que pueda ser denominado filosofía de la innovación. Se han publicado algunos libros sobre innovación (Drucker, 1995; Lundvall, 1992; o más recientemente y de tono muy divulgativo, Johnson, 2010, son buenos ejemplos). Y existen los textos de la OCDE (Manual de Oslo de 2005 y otros textos más recientes) y de la Comisión Europea, de 2006 y 20101. Pero ninguno de ellos había abordado de forma explícita la cuestión de la filosofía de la innovación.
Y eso es, precisamente, lo que ha hecho Javier Echeverría, quizás una de las personas, por su trayectoria, más adecuadas para abordar la tarea. Javier recibió en 1995 el Premio Anagrama de Ensayo por Cosmopolitas domésticos y el Premio Nacional de Ensayo en 2000 por Los Señores del Aire, Telépolis y el Tercer Entorno. En la actualidad es profesor de investigación Ikerbasque, trabaja en la UPV/EHU y es miembro de Jakiunde.
En su libro Echeverría se propone sacar la noción de innovación del marco limitado del mundo de la empresa y las instituciones para llevarlo a uno mucho más amplio. Pretende naturalizar el concepto de innovación, de manera que se convierta en una noción aplicable a esferas tan diferentes como la naturaleza, las sociedades, las empresas, las ideas, el lenguaje y otras. El enfoque de Echeverría es, pues, pluralista y sistémico.
Y es ambicioso. La ambición de su planteamiento es necesaria; de otra forma no saldría de los cauces trillados en los manuales al uso. Pero esa ambición es quizás la causa de las principales objeciones que le encuentro. Así, por ejemplo, si bien me parece razonable incluir muchos procesos biológicos, con sus resultados, en el catálogo de innovaciones, no veo tan claro que merezcan similar consideración fenómenos de carácter cósmico. Desde el punto de vista de lo que podemos aprender de los citados ejemplos, además, me parece claro que los biológicos –con algunas reservas respecto al estatus de nociones tales como evolución lamarkiana o el concepto de evolución darwinista- pueden ser fuente de inspiración para elaborar modelos de procesos innovadores, en una línea que ya apunta el autor. Pero no veo esa misma funcionalidad en fenómenos tales como la formación de agujeros negros, por ejmplo. Y, en el otro extremo, por muy innovadora que haya sido una táctica bélica, dudo que cumpla los requisitos que el propio autor impone a las innovaciones en términos, por ejemplo, de difusión social y grado de adopción. Pero realmente estas son cuestiones que no impugnan el núcleo del atrabajo y que merecerían una discusión pormenorizada.
Dejo para el final dos consideraciones relativas a aspectos de la obra que me han resultado de especial interés. Uno es su componente axiológica. Aunque la noción de valor me sigue resultando esquiva a ciertos efectos, esa componente me parece relevante. Y entronca, además, con parte de la producción de Echeverría de los últimos años, en concreto en el terreno de los valores de la ciencia. Y la segunda consideración se refiere a la reseña que hace de tres pensadores –Aristóteles, Bacon y Leibniz- que introdujeron innovaciones de gran alcance en el pensamiento humano. Quizás por mi desconocimiento del personaje, lo relativo al último, a Leibniz, me resultado de especial interés.
En suma, tenemos una obra sobre un tema muy de moda, pero, hasta donde alcanza mi conocimiento, con un tratamiento nuevo. Si la propuesta de Javier Echeverría tiene éxito, la innovación debería salir de los estrechos y confusos cauces por los que discurre ahora y para ser contemplada en nuevo contexto, más amplio y más fecundo. Para quienes levantamos la ceja cada vez que oímos o leemos la palabra innovación, eso serían buenas noticias. Aunque solo fuera por esa razón ya me parece suficiente para dar la bienvenida al libro. Y a quien, además, esté interesado en la innovación por razones académicas (en su estudio) o prácticas (en su ejercicio), “El arte de innovar” puede resultarle una lectura enriquecedora.
Ficha:
Autor: Javier Echeverría
Año: 2017
Título: El arte de innovar. Naturalezas, lenguajes, sociedades.
Editorial: Plaza y Valdés editores, Madrid.
1 Se omiten las referencias porque no se han utilizado para la redacción de esta reseña, pero pueden hallarse, junto con muchas más, en el propio texto de Echeverría.
En Editoralia personas lectoras, autoras o editoras presentan libros que por su atractivo, novedad o impacto (personal o general) pueden ser de interés o utilidad para los lectores del Cuaderno de Cultura Científica.
El artículo El arte de innovar, de Javier Echeverría se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Arte & Ciencia: Cómo descubrir secretos que esconden las obras de arte
- Arte & Ciencia: Química y Arte, reacciones creativas
- Arte & Ciencia: Sobre la dimensión cognitiva del arte en relación a la ciencia
Ciencia a presión: Periodistas que avalan patrañas

La expresión publish or perish (publica o perece) es de sobra conocida en el ámbito científico. Quiere expresar la importancia que tienen las publicaciones en los currículos del personal investigador. En ciencia no basta con hacer observaciones, obtener unos resultados y derivar conclusiones. Hay, además, que hacerlo público y, a poder ser, en medios de la máxima difusión internacional. La ciencia que no se da a conocer, que no se publica, no existe. El problema es que de eso, precisamente, depende el éxito profesional de los investigadores, sus posibilidades de estabilización y de promoción. De ahí la conocida expresión del principio.
El mundo de la comunicación tiene también sus normas. En comunicación se trata de que lo que se publica sea consumido. De la misma forma que la ciencia que no se publica no existe, en comunicación tampoco existen los contenidos que no se consumen: o sea, no existen los artículos que no se leen, los programas de radio que no se oyen, los de televisión que no se ven o los sitios web que no se visitan. En comunicación valdría decir “sé visto, oído o leído, o perece”.
Ambas esferas tienen ahí un interesante punto en común. Y por supuesto, en comunicación o difusión científica el ámbito de confluencia se aprecia en mayor medida aún. Confluyen aquí ambas necesidades, la de hacer públicos los resultados de investigación y, además, conseguir que lleguen a cuantas más personas mejor.
El problema es que la presión por publicar y por tener impacto comunicativo puede conducir tanto a unos como a otros profesionales, a adoptar comportamientos deshonestos, contrarios a la ética profesional e, incluso, a desvirtuar completamente el fin de la ciencia y de su traslación al conjunto del cuerpo social. Y también puede conducir, y de hecho ha conducido, a que se haya configurado un sistema de publicaciones científicas con patologías.
De todo esto se trató el pasado 31 de marzo en “Producir o perecer: ciencia a presión”, el seminario que organizaron conjuntamente la Asociación Española de Comunicación Científica y la Cátedra de Cultura Científica de la UPV/EHU.
2ª Conferencia
José Antonio Pérez Ledo, autor del blog Mi Mesa cojea y colaborador en distintos medios de comunicación: Periodistas que avalan patrañas
Periodistas que avalan patrañasEdición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Ciencia a presión: Periodistas que avalan patrañas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Ciencia a presión: Científicos que avalan patrañas
- Curso de verano “La ciencia de nuestras vidas”: Cuando la música era ciencia, por Almudena M. Castro
- Curso de verano “La ciencia de nuestras vidas”: Arte, literatura y ciencia, por Gustavo A. Schwartz
Redescubriendo las integrales en 1994
Los científicos a menudo nos quejamos, especialmente desde foros como este en el que escribo, del desinterés por la cultura científica que existe en gran parte de la sociedad. Frecuentemente esta falta de interés está relacionada con la sensación de que la ciencia es demasiado difícil para ser comprendida, la creencia de que “la ciencia no es para mí”[1].
Por su reputación de asignatura hueso y su terrible capacidad para traumatizar estudiantes, las matemáticas se llevan la palma en el ránking de “cosas demasiado difíciles”. La idea de la inaccesibilidad de las matemáticas llega a calar incluso entre científicos de otras ramas. Para mayor drama, en todas las ramas de la ciencia surgen problemas matemáticos de forma natural. Abordar este tipo de problemas dando la espalda a las matemáticas suele ser una mala idea. Lo ilustraremos con un ejemplo, un ejemplo bastante extremo:
Sucedió en febrero de 1994, cuando se publicó este artículo en la revista Diabetes Care: “A mathematical model for the determination of total area under glucose tolerance and other metabolic curves”, firmado por Mary M. Tai, que pasaría inmediatamente a la historia de la ciencia, aunque por motivos poco halagadores.
El artículo trata del análisis de curvas metabólicas. Simplificando mucho, la diferencia entre un paciente sano y un paciente con diabetes es que este último es mucho más lento eliminando de su sangre la glucosa recién consumida. Una forma fácil de visualizar esto es midiendo su concentración de glucosa en sangre, pongamos, cada hora, y representándola en figuras como la siguiente:

La forma de este tipo de curvas es, pues, de vital importancia. Concretamente, el problema que se pretende resolver en el artículo y, de hecho, se resuelve, es el de determinar el área bajo una de estas curvas. El método propuesto consiste en rellenarla con pequeños trapecios y sumar las áreas de cada uno de ellos, como se aprecia en la figura:

Lo curioso del caso es que el método propuesto como novedoso, y bautizado nada menos que como “modelo de Tai”, se conoce desde tan antiguo que resulta difícil establecer la fecha concreta de su descubrimiento. Hay sospechas fundadas de que los Babilonios lo usaban para sus cálculos astronómicos; de lo que no cabe duda de que era un método bien conocido en los tiempos de Euler. En matemáticas se conoce con el nombre, mucho más humilde, de regla del trapecio.
Es posible que todo lo anterior les resulte familiar. En las matemáticas del instituto se estudia algo llamado integral. Las integrales sirven, entre otras cosas, para calcular el área bajo una curva. Es decir: existe un método (conocido desde finales del siglo XVII) enseñado en los libros de texto de secundaria, que responde a la pregunta de investigación que se plantea el artículo[1], y que constituye uno de los pilares de la rama matemática conocida como cálculo infinitesimal. En resumen, se publicó un artículo que redescubría una operación básica con tres siglos de retraso (como mínimo).
Que un artículo como este resultase publicado es, cuanto menos, chocante. Más chocante aún es saber que recibió una apreciable cantidad de citas por parte de colegas, que encontraron el “modelo de Tai” útil para su trabajo. Hubo también colegas que comentaron acertadamente que el artículo estaba redescubriendo (y rebautizando) la regla del trapecio. A estos, la autora responde enrocándose en su posición, considerando la regla del trapecio “mero sentido común” y un conocimiento tan irrelevante “que no es de Premio Nobel”. A pesar de esto, no tiene reparos en reclamar su nombre para el método de “sentido común” pocas líneas más abajo. El resto de respuestas van en la misma línea y tono, dejando claro que no estamos ante un problema de comunicación entre disciplinas. Lejos de ser retractado, las citas del artículo siguen aumentando gracias al revuelo formado, aunque fundamentalmente es citado como ejemplo de ciencia patológica.
Las reacciones habituales que he encontrado cuando he contado esta historia a mis colegas son risa, incredulidad, e incluso algunas veces indignación. Pero yendo un poco más allá de lo superficial, esta historia tiene varias lecturas interesantes.
Para empezar, pone de manifiesto que la falta de cultura científica se da también dentro de la comunidad científica. El hecho de que nadie en todo el proceso de publicación levantase la ceja ante un método con siglos de antigüedad, con un papel central en la historia de la ciencia y descrito en los libros de texto de secundaria, es prueba de ello.
Por otro lado, el problema original es obviamente un problema geométrico básico, que incluso tiene cierto “aroma” a geometría griega. La autora tiene un nivel de matemáticas suficiente para desarrollar desde cero un método aproximado que lo resuelve. Un vistazo a cualquier libro de matemáticas le habría ahorrado tiempo y esfuerzo. ¿Por qué no empezó por ahí?, ¿estamos quizá ante otra forma enrevesada de enfrentar un problema en esencia matemático, pero “dando la espalda a las matemáticas”?
Siendo un poco más sutiles, uno puede preguntarse si realmente es lícito “rescatar” un método conocido para aplicarlo dónde no se ha aplicado antes. Al fin y al cabo, el uso de métodos conocidos en áreas “exóticas” es la esencia de la investigación multidisciplinar. En el caso del artículo mencionado, casi todo el mundo opina que se cruzó una línea roja. Pero, ¿y un artículo que, por ejemplo, rescate un teorema matemático del siglo XIX para llegar a conclusiones sobre un modelo de crecimiento de plankton? En este caso casi todo el mundo opinará que se trata de una investigación totalmente lícita, a pesar de que la novedad de los resultados puede también ponerse en entredicho. Suele ser fácil ver en qué lado de la línea roja estamos, pero no es nada sencillo trazarla.
Y, por último, la anécdota deja patente que el proceso de revisión por pares dista mucho de ser perfecto. Es buena idea mantener un sano escepticismo a todos los niveles, incluso al leer artículos revisados, publicados… e incluso altamente citados.
Seguro que hay más opiniones. Les invito a dejarlas en los comentarios.
Este post ha sido realizado por Pablo Rodríguez (@DonMostrenco) y es una colaboración de Naukas.com con la Cátedra de Cultura Científica de la UPV/EHU.
Referencias, citas y más información:
[1] Cuando la ciencia se “disfraza” en forma de historia (véase el extraordinario ejemplo del podcast Catástrofe Ultravioleta o los eventos Naukas) y se rompe esta primera barrera, los resultados son sorprendentes: resulta que la ciencia no solamente interesa a casi todo el mundo, sino que también gusta.
[2] El concepto renacentista de integral es incluso más avanzado que el mostrado en el artículo de 1994, pues en este último se pasan por alto los problemas derivados de escoger anchuras arbitrarias para los trapecios (problema que las integrales evitan usando el concepto de límite para tomar rectángulos infinitamente estrechos).
M. M. Tai, “A Mathematical Model for the Determination of Total Area Under Glucose Tolerance and Other Metabolic Curves,” Diabetes Care, vol. 17, no. 2, pp. 152–154, Feb. 1994.
El artículo Redescubriendo las integrales en 1994 se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Redescubriendo el primer arte vasco: nuevos hallazgos, nuevas investigaciones
- ¿Puede ser culto alguien de Letras?
- El efecto Richardson, la clave del estudio moderno de los fractales
«Una copita de vino es buena para el corazón». Claro que sí, guapi.
Hemos escuchado tantas veces eso de que «Una copita de vino es buena para el corazón» que parece verdad. Recuerdo a mi abuela, que no solía tomar alcohol, diciendo que el vino era salud. En los días de fiesta, con las mejillas encendidas y los labios tintados, disfrutaba mojando un pedazo de pan en sus sopas de burro cansado. Las sopas de burro cansado son un postre típico gallego: vino tinto caliente con azúcar y migas de pan duro. Si es tradicional, tiene que ser bueno. Si toda la vida se ha dicho que el vino es bueno para el corazón, será cierto. ¿O no?

-
El origen de la creencia
Hay intereses de diversa naturaleza que han llevado a perpetuar hasta nuestros días la idea de que el vino es saludable, al menos una copita. Las bondades se las atribuímos a algunas de las sustancias que contiene, como flavonoides y antioxidantes como los polifenoles, entre ellos el más famoso es el resveratrol. Del resveratrol incluso se ha llegado a decir que era algo así como el elixir de la eterna juventud, que ayuda a prevenir daños en los vasos sanguíneos, que previene la obesidad y la diabetes, ambos factores de riesgo cardíaco. Ninguna de estas virtudes ha podido demostrarse con estudios en seres humanos.
El mito no surgió de la nada. Algunas de estas bondades del resveratrol se probaron en ratones, gusanos y moscas, y de ahí el resveratrol llegó con fuerza al mercado de los suplementos alimenticios. Pero se encontraron con un problema, y es que no es legal decir que un producto «ralentiza el envejecimiento celular» por llevar resveratrol, porque no funciona así en humanos. Pero sí se puede decir si contiene selenio. Y tampoco se puede decir del resveratrol que «ayuda al funcionamiento normal del corazón». En cambio, esto último sí se puede decir de la Vitamina B1. Añadir vitamina B1 a estos suplementos fue la treta que emplearon algunas marcas para poder afirmar legalmente que sus productos con resveratrol son buenos para el corazón.
De la tradición informativa e interesada sobre los beneficios del vino, a los modernos suplementos alimenticios, el caso es que seguimos creyendo que un consumo moderado de vino es saludable. Decir lo contrario es ser un aguafiestas e ir en contra de todo lo que se ha dicho hasta ahora. Pero, ¿qué dicen sobre el consumo moderado de vino las principales organizaciones de la salud? ¿Qué conslusiones se han extraído de los numerosos estudios científicos que se han hecho al respecto?
-
Lo que dice la ciencia sobre consumo de vino y salud
Ya en 2012 la Organización Mundial de la Salud publicaba en su informe Alcohol in the European Union que «el alcohol es perjudicial para el sistema cardiovascular». La Comisión Europea también publicó que «un consumo moderado de alcohol aumenta el riesgo a largo plazo de sufrir cardiopatías».
En 2014 la revista British Medical Journal publicaba una extensa revisión de 56 estudios epidemiológicos sobre consumo de alcohol. La conclusión fue clara y contundente: «el consumo de alcohol aumenta los eventos coronarios en todos los bebedores, incluyendo aquellos que beben moderadamente».
En 2016, en la revista BMC Public Health se publicó que cada año mueren 780.381 personas por enfermedades cardiovasculares atribuibles al consumo de alcohol.
Tampoco es cierto que el consumo moderado de alcohol previene la mortalidad, sino que «el bajo consumo de alcohol no ejerce beneficios netos en la mortalidad al compararlo con la abstinencia de por vida o el consumo ocasional de alcohol», tal y como se ha publicado en 2016 en la revista Journal of Studies on Alcohol and Drugs.
No sólo ha quedado claro que el consumo de vino incrementa el riesgo de sufrir cardiopatías, sino que múltiples estudios científicos han concluído que el consumo de alcohol está relacionado con otras patologías y enfermedades. Estas conclusiones son extrapolables a todas las bebidas alcohólicas: cerveza, ginebra, ron, etc.
Resulta que el consumo de bebidas alcohólicas también se relaciona con el riesgo de cáncer, con el mayor nivel de evidencia posible. La Organización Mundial de la Salud en su Informe Mundial de Situación sobre Alcohol y Salud publicado en 2015 concretó que «un consumo tan bajo como una bebida diaria causa un aumento significativo del riesgo de algunos tipos de cáncer».
En 2016 el Fondo Mundial para la Investigación del Cáncer detalló que «existen evidencias científicas sólidas de que el alcohol incrementa el riesgo de padecer 6 cánceres: mama, intestino, hígado, boca/garganta, esófago y estómago». Las conclusiones fueron rotundas y reveladoras. Hasta entonces se deconocían los mecanismos biológicos por los cuales el alcohol aumentaba el riesgo de padecer cáncer. En este estudio se descubrió que el vínculo entre consumo de alcohol y cáncer iba más allá de la estadística. «No se trata de un simple vínculo, sino de una relación causal bien establecida: el agente responsable directo del desarrollo de los cánceres citados es el consumo de alcohol, incluso a dosis relativamente bajas».

No es casualidad que en la imagen que figura en el documento informativo del Fondo Mundial para la Investigación del Cáncer aparezcan unas copas de vino. El vino es, sin duda, la bebida alcohólica sobre la que se han creado más mitos relacionados con la salud. Ya es hora de dejarlos atrás.
Conclusiones
Consumimos vino como parte de nuestra tradición cultural, como parte de los actos sociales, por sabor y por placer. Que cada cual juzgue si estas razones son buenas o no y valore los riesgos asociados que acarrean. En cambio, sabemos con certeza que la salud cardiovascular no es una razón por la que consumir vino, sino todo lo contrario. El consumo de vino, incluso el moderado, el de una copita no hace daño a nadie, aumenta el riesgo de padecer cardiopatías y produce hasta seis tipos de cáncer. Si quieres buscarte una excusa para tomarte esa copita de vino, que no sea tu salud. La razón que encuentres siempre será a costa de ella.
Si te interesa saber más:
¿Es sana esa “copita de vino” diaria?. Vídeo de Julio Basulto en el que se mencionan gran parte de las referencias que aparecen en este artículo.
Beber alcohol produce cáncer. Artículo de Juan Ignacio Pérez.
Consumo de alcohol y salud en el mundo. Artículo de Juan Revenga.
Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo «Una copita de vino es buena para el corazón». Claro que sí, guapi. se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Con los edulcorantes artificiales (casi) todo son ventajas
- El azúcar oculto en los alimentos
- Tomas poca estevia
Frank Stella, la forma del lienzo
En mi anterior entrada del Cuaderno de Cultura Científica de la Universidad del País Vasco / Euskal Herriko Unibertsitatea Mosaicos hexagonales para el verano se mostraban algunas obras de arte relacionadas con los mosaicos hexagonales, e incluso solo con el propio hexágono. En particular, se mencionaba a un artista abstracto y minimalista norteamericano, Frank Stella, y su obra Sydney Guberman (1964), cuya forma es hexagonal. Y es precisamente la forma de esta obra, no por el hecho de que sea hexagonal, sino porque no es el típico lienzo rectangular, lo que me ha hecho volver a mirar desde este espacio la obra de este artista.

“Emperatriz de la India” (1965), de Frank Stella, de la serie V del artista
La revolución artística que se produjo con la llegada de la abstracción en el siglo XX trajo consigo también una reflexión sobre la forma de la obra de arte, y en particular, del lienzo sobre el que se pintaba. Esta reflexión está muy presente en la obra del artista de Massachusetts (EE.UU.), Frank Stella, quien juega con la forma del lienzo, no solo rompiendo con la forma rectangular usual, sino haciendo que la forma del lienzo sea parte de la propia obra.
No estamos hablando simplemente de elegir otra forma para el lienzo sobre el que se va a pintar, como por ejemplo, en el Autorretrato con Endymion Porter (1635), del pintor flamenco Anton van Dyck (1599 – 1641), que es ovalado, sino de una ruptura total con las formas clásicas de la pintura, rectangular, ovalada o circular, y la incorporación de la forma como parte de la propia obra, de la propia creación artística.

“Autorretrato con Endymion Porter” (1635), de Anton van Dyck, en el Museo del Prado de Madrid
Frank Stella no es en único artista que juega con la forma de los “lienzos”, de hecho en la década de 1960 muchos artistas abstractos decidieron incorporar la reflexión de la forma del lienzo a sus obras, aunque sí es uno de los más significativos, y es del que vamos a mostrar algunas obras en esta entrada.
El pintor y grabador norteamericano Frank Stella nació en Malden, Massachusetts, en 1936. Si leemos un poco sobre la obra de este artista descubriremos que se inició en el expresionismo abstracto, movimiento artístico al que pertenece su serie de obras Black Paintings (pinturas negras), que están formadas por bandas negras paralelas, separadas por estrechas líneas blancas que realmente son espacios no pintados entre las blandas negras paralelas. Como podemos leer en la página The Art Story, Modern Art Insight [theartstory.org] este recurso artístico plantea una reflexión al espectador sobre la naturaleza bidimensional de la pintura, realizando así un camino inverso al que se produjo con la invención de la perspectiva en el renacimiento.
Las bandas negras paralelas de cada obra seguían un patrón diferente, por ejemplo en la siguiente obra, Matrimonio entre razón y miseria II (1959), las bandas negras tenían forma de U invertida, pero en general cada obra tenía su propio patrón geométrico.

“Matrimonio entre razón y miseria II” (1959), de Frank Stella, y que se encuentra en el MoMA
Una de las frases más famosas de Frank Stella para definir su arte es
“Mi pintura se basa en el hecho de que solo lo que se puede ver allí está allí… lo que ves es lo que ves”.
Esta serie de obras tuvo una gran importancia dentro del minimalismo, movimiento artístico dentro del cual Stella fue uno de sus artistas más significativos.
A partir de 1960 Frank Stella empezaría a utilizar aluminio y cobre para sus lienzos, y también pintaría bandas paralelas de diferentes colores, no solamente negras, como en su obra Harran II (1967), que pertenece a la serie de obras Protractor (trasportador). Se producirían sus primeras obras cuyos lienzos tendrían formas particulares, no rectangulares.

“Harran II” (1967), de Frank Stella, que pertenece al Museo Guggenheim y que tiene un tamaño considerable, 3 metros de alto por 6 metros de largo
A continuación, mostramos otra obra de Frank Stella perteneciente a la serie Protractor, Firuzabad (1970), cuando se exhibió en el Museo de Arte Moderno de San Francisco. En la imagen vemos al propio artista posando para la fotografía de Liz Mangelsdorf.

El artista Frank Stella delante de su obra “Firuzabad” (1970), que es el nombre de una ciudad iraní, en el Museo de Arte Moderno de San Francisco, en 2004
Una serie de obras de Frank Stella que es en sí misma una reflexión sobre la forma de los lienzos, es su serie Irregular polygons (polígonos irregulares), de mediados de la década de 1960. En esta serie de obras, Stella fusiona formas sencillas, para crear formas irregulares más complejas. De nuevo el color es una parte esencial de las obras.

“Moultonboro III” (1966), de Frank Stella, cuyo nombre hace referencia, al parecer, a un pueblo de New Hampshire (EE.UU.)
La obra Moultonboro III (1966) está formada por un triángulo trazado por una banda ancha amarilla y de interior también amarillo, aunque diferente al anterior para diferenciarlos, colocado en la parte superior izquierda de una forma de color rojo que nos sugiere un cuadrado, ya que no está completo sino que el espectador puede formarlo o no en su mente mientras observa la obra, como si descansara debajo del triángulo. Además, separando el cuadrado rojo y el triángulo amarillo se forma una banda en forma de algo similar a una letra Z, de color azul. El contraste entre formas y colores es un elemento esencial en las obras de la serie Irregular Polygons, que además crea una ilusión de objetos planos que saltan a la tercera dimensión superponiéndose, plegándose o arrugándose.
Stella hace varias versiones de esta obra, utilizando diferentes colores, al igual que con otras obras. Por ejemplo, en Moultonboro II el triángulo es blanco, con una banda ancha verde y el cuadrado es negro.

Fotografía de la exposición “Irregular Polygons 1965-66” de Frank Stella en el Toledo Museum of Art, en 2011. Las obras que aparecen son “Ossipee II” (1966), “Chocorua IV” (1966), “Effingham IV” (1966) y “Moultonville I”I (1966)
Los nombres de la serie Irregular Polygons son nombres de pueblos, y otros lugares, de New Hampshire.
Posteriormente, en series como Polish Villages (pueblos polacos), e influenciado por el constructivismo ruso, utiliza formas geométricas no tan sencillas como en la serie Irregular Polygons, creando imágenes cada vez más complejas. Los nombres de las obras de esta serie son nombres de pueblos polacos y las obras hacen referencia a las sinagogas destruidas por los Nazis.

“Olkienniki III” (1972), de Frank Stella, perteneciente a la serie “Polish Villages”
En obras posteriores, como en la serie Indian Birds (pájaros de la India), Stella traspasa el concepto de “pintura” para realizar obras más cercanas a lo podíamos llamar “esculturas verticales para paredes”, con una complejidad enorme.

“Jungli Kowwa” (1979), de Frank Stella, perteneciente a la serie “Indian Birds”
Pero volvamos a los lienzos geométricos de la década de los años 1960, donde realiza obras con formas geométricas sencillas a base de bandas anchas, como por ejemplo sencillos polígonos (triángulos, cuadrados, pentágonos, hexágonos,etc), realizados por bandas anchas, ya sean pintadas en negro o realizadas en aluminio o cobre.

Fotografía de Rudy Burckhardt de la exposición de Frank Stella en la Galería Leo Castelli en 1964

“Henry Garden” (1963), de Frank Stella, perteneciente a su serie realizada en aluminio, que consiste en una serie de octógonos concéntricos
Pero vamos a terminar esta pequeña introducción a la obra de lienzos con diferentes formas del artista norteamericano Frank Stella con algunas de sus esculturas geométricas. En la primera de estas esculturas, Estrella inflada y estrella de madera (2014), aparecen dos dodecaedros estrellados, realizados en aluminio y madera de teca.

“Estrella inflada y estrella de madera” (2014), de Frank Stella, dentro del International Sculpture Route Amsterdam – ARTZUID 2015
Y la segunda escultura Estrella negra (2014) es un icosaedro estrellado, realizado en fibra de carbono.

“Estrella negra” (2014), de Frank Stella, dentro de la exposición “Frank Stella: A Retrospective” en el Whitney Museum of American Art, fotografiada por Nic Lehoux
Bibliografía
1.- Frank Stella – Connections – Haunch of Venison – London, Art Splash Contemporary Art
2.- Liz Rideal, Cómo leer pinturas, una guía sobre sus significados y métodos, Blume, 2015.
3.- Entrada sobre Frank Stella en la página web The Art Story, Modern Art Insight
5.- Exposiciones de Frank Stella en la galería Leo Castelli
7.- International Sculpture Route Amsterdam – ARTZUID
8.- Anna Painchaud, Unbounded Doctrine, encountering the art-making career of Frank Stella, Arts Editor, 2015
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo Frank Stella, la forma del lienzo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Mosaicos hexagonales para el verano
- El caso de William & Frank Buckland
- Artistas que miran a las matemáticas
Sistemas nerviosos: las áreas sensoriales

Las áreas sensoriales son las que reciben y procesan información procedente de los receptores sensoriales, normalmente pertenecientes a los que denominamos “órganos de los sentidos”. Se denominan áreas sensoriales primarias a aquellas que reciben señales cuyo origen inmediato anterior es el tálamo. Como vimos aquí, el tálamo ejerce la función de estación de relevo de la información sensorial y de filtro -de acuerdo con su potencial relevancia- de dicha información. En general, cada hemisferio cerebral recibe información procedente del lado del cuerpo opuesto. Así, la corteza visual izquierda recibe las señales procedentes de la retina del ojo derecho.
Por otro lado, la información visual, auditiva y somatosensorial da lugar a la definición en la corteza de mapas sensoriales topográficos, de manera que la información procedente de células sensoriales adyacentes llega a neuronas corticales adyacentes también. Se pueden elaborar mapas sensoriales de todos los vertebrados y, lógicamente, a cada especie corresponde el suyo propio, que cuya configuración depende de la importancia relativa de cada modalidad sensorial para dicha especie. Los siluros, por ejemplo, tienen mapas sensoriales en el rombencéfalo con áreas muy extensas para los receptores gustativos de su superficie corporal y de boca y faringe. No obstante, la mayor parte de la información disponible se refiere a los mamíferos. A ellos, principalmente, nos referiremos a continuación.
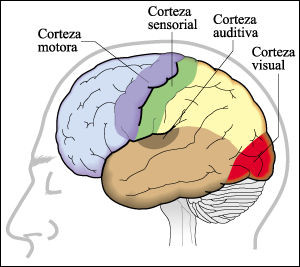
La información visual llega de los ojos hasta la denominada “corteza visual primaria” (V1) (área de Brodmann 17) tras pasar por el núcleo geniculado lateral del tálamo. La corteza visual primaria se encuentra en el lóbulo occipital (zona posterior) y en ella se configura un mapa (retinotópico), en el que la configuración espacial de los puntos que reciben las señales reproduce la de los fotorreceptores en la retina. La información visual es posteriormente procesada de manera parcial en diferentes áreas de la corteza, pues se trata de una información con varios componentes (color, posición, trayectoria, contexto, etc.) que son procesados de manera independiente hasta que otras áreas (asociativas) de la corteza recrean la imagen.
La corteza auditiva primaria se halla en el lóbulo temporal (áreas de Brodmann 41 y 42) y es, como su nombre indica, el área cortical encargada de un primer procesamiento de la información auditiva. La información llega de los oídos tras pasar por el núcleo geniculado medial del tálamo, y también aquí se halla definido un mapa sensorial, denominado tonotópico. En este caso, las células de la corteza próximas entre sí reciben información relativa a frecuencias de sonido similares; ha de tenerse en cuenta que la recepción de sonidos en el oído se produce de tal forma que los tonos se reciben con arreglo a una disposición espacial de los receptores (células pilosas). La corteza auditiva primaria –que identifica tono y volumen del sonido- se halla rodeada por la secundaria, y esta a su vez, por la terciaria. Cada una de ellas iría procesando aspectos cada vez más complejos de la información sonora.
Con la denominación de corteza somatosensorial se hace referencia a una franja de los lóbulos parietales del cerebro de mamíferos (áreas de Brodmann 1, 2 y 3) a la que llegan las denominadas sensaciones somáticas procedentes de receptores situados en la superficie corporal y en músculos y articulaciones. Se trata de receptores de tacto, presión (barorreceptores), temperatura (termorreceptores), dolor (nociceptores), los superficiales, y de posición (propioceptores), los musculares y articulares. En vertebrados no mamíferos la propiocepción es procesada en otras áreas encefálicas; así, en peces es el cerebelo el que procesa la información procedente de piel y aletas, y en tortugas y ranas son los ganglios talámicos los que generan respuestas somatotrópicas.
Como ocurre con la información visual y auditiva, cada región de la corteza somatosensorial recibe inputs de un área específica del cuerpo; a esas regiones se las denomina “áreas de representación”. Además, cuanto mayor es la densidad de receptores en una determinada zona del cuerpo, mayor es la superficie de la corteza dedicada a procesar esa información. Esa proporcionalidad y la disposición en que se encuentran las “áreas de representación” han permitido elaborar el correspondiente mapa somatotrópico, en el que se pueden localizar las diferentes sensaciones. También han permitido elaborar una forma de representación muy ilustrativa que corresponde a un cuerpo del animal en cuestión en la que el tamaño de cada parte del cuerpo es proporcional a la superficie de su correspondiente área de representación. Cuando la imagen representa una figura humana se denomina “homúnculo sensorial”.
La información olfativa llega, en primer lugar, al bulbo olfativo, donde es procesada parcialmente. Las células mitrales del bulbo olfativo envían las señales a diferentes áreas cerebrales siguiendo dos rutas principales: (1) una subcortical, que se dirige principalmente a regiones del sistema límbico, y (2) otra talámico-cortical. La ruta subcortical implica al hipotálamo, dada la importancia de los olores en el comportamiento alimenticio y sexual. La talámico-cortical, sin embargo, es importante para la identificación precisa de olores y su percepción consciente.
Aunque la información gustativa alcanza a diferentes áreas de la corteza, se considera que la responsable de la percepción del gusto es la corteza gustativa primaria. Se subdivide en dos subestructuras, la ínsula anterior (en la ínsula) y el opérculo frontal (en el giro frontal inferior del lóbulo frontal).
Finalmente, cada región de la corteza sensorial proyecta la información recibida, a través de la materia blanca, hacia áreas de la corteza próximas, donde es sometida, junto con la de otras regiones, a elaboración, análisis e integración. En dicha integración intervienen otros elementos (memoria, emociones evocadas, etc.) y, como consecuencia de ello, pueden elaborarse las correspondientes respuestas, motoras principalmente.
Fuentes:
Eric R. Kandel, James H. Schwartz, Thomas M. Jessell, Steven A. Siegelbaum & A. J. Hudspeth (2012): Principles of Neural Science, Mc Graw Hill, New York
Lauralee Sherwood, Hillar Klandorf & Paul H. Yancey (2005): Animal Physiology: from genes to organisms. Brooks/Cole, Belmont.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Sistemas nerviosos: las áreas sensoriales se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Sistemas nerviosos: el sistema central de vertebrados
- Sistemas nerviosos: el tálamo y el hipotálamo
- Sistemas nerviosos: el cerebro de vertebrados
La ley del gas ideal y la tercera ley de la termodinámica
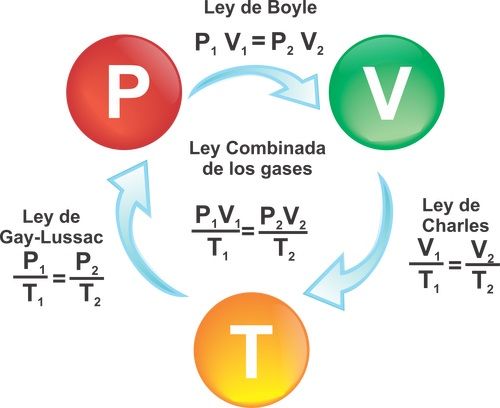
Boyle se dio cuenta de que si la temperatura de un gas cambia durante un experimento, la relación P = a/V ya no es correcta. Por ejemplo, la presión ejercida por un gas en un recipiente cerrado de tamaño fijo aumenta si el gas se calienta, aunque su volumen permanece constante. Sin embargo, si la temperatura de un gas se mantiene constante, entonces la regla de Boyle sí funciona. Así, modificamos la regla de la siguiente manera:
P = a/V, si T es constante (a)
Muchos científicos a lo largo del siglo XVIII también investigaron cómo, por ejemplo en un globo de paredes delgadas, los gases se expanden cuando se aporta calor, a pesar de que la presión sigue siendo la misma. Finalmente, se acumularon suficientes indicios como para formular una regla general sorprendentemente simple. El químico francés Joseph-Louis Gay-Lussac (1778-1850) encontró que todos los gases que estudió (aire, oxígeno, hidrógeno, dióxido de carbono, etc.) cambian su volumen de la misma manera. Si la presión se mantenía constante, entonces el cambio de volumen era proporcional al cambio de temperatura. Esto puede expresarse en símbolos:
ΔV ∝ ΔT, si P es constante (b)
Por otra parte, si el volumen se mantenía constante (usando, por ejemplo, un contenedor rígido), el cambio en la presión del gas era proporcional al cambio de la temperatura:
ΔP ∝ ΔT, si V es constante (c)
Los datos experimentales obtenidos por Boyle, Gay-Lussac y muchos otros científicos se expresan en las tres proporcionalidades, (a), (b) y (c). Éstas relacionan las tres características principales de una cantidad fija de un gas: la presión, el volumen y la temperatura, medidos cada uno desde cero, cuando una variable se mantiene constante. Introduciendo una nueva constante, k, estas tres proporcionalidades pueden unirse en una sola ecuación general conocida como ley del gas ideal.
P·V = k·T
Esta ecuación es uno de los descubrimientos más importantes sobre los gases, pero al usarla se debe tener un cuidado extremo con las unidades. La constante de proporcionalidad k depende del tipo de gas (en concreto de su masa molar); T, la temperatura del gas, tiene que ser dada en la escala absoluta, o Kelvin, donde, como ya mencionamos, T (K) = T (° C) + 273,15. La presión P es siempre la presión total (en unidades de N / m2, a la que se da el nombre de Pascal, abreviatura Pa), e incluye la denominada presión ambiente de la atmósfera. Esto es algo que se suele olvidar. Así, si inflo en neumático trasero de mi coche hasta los 2,2 ·105 Pa por encima de la presión atmosférica tal y como indica el fabricante, la presión real dentro del neumático es de 2,2 ·105 Pa + 1,0 ·105 Pa = 3,2 ·105 Pa.
La ecuación que relaciona P, V y T se denomina “ley” del gas ideal porque no es completamente exacta para gases reales a presiones muy bajas. Tampoco se aplica cuando la presión es tan alta, o la temperatura tan baja, que el gas está a punto de pasar a ser líquido. Por lo tanto, no es una ley de la física en el mismo sentido que la majestuosa ley de la conservación de la energía, que es válida en todas las circunstancias.
En realidad es simplemente es un resumen útil aproximado de resultados experimentales de las propiedades observadas de gases reales. No hay más que considerar lo que sucedería si intentamos bajar la temperatura del gas al cero absoluto; Es decir, T = 0 K (o, en Celsius, t = – 273,15 ° C). En este caso extremo, todo el término de la ecuación en el que está la temperatura sería cero. Por tanto, el término PV también debe ser cero. A presión constante, el volumen se reduciría a cero, lo que no tiene sentido si tenemos una cantidad de gas distinta de cero.
De hecho, todos los gases reales se vuelven líquidos antes de alcanzar esa temperatura. Tanto el experimento como la teoría termodinámica indican que es realmente imposible enfriar cualquier cosa -gas, líquido o sólido- exactamente a esta temperatura de T = 0 K. Este hecho se conoce como tercera ley de la termodinámica.
Sin embargo, una serie de operaciones de enfriamiento pueden producir temperaturas que se acercan mucho a este límite. En vista del significado único de la temperatura más baja para un gas que obedece a la ley del gas ideal, Lord Kelvin (William Thomson) propuso la escala de temperatura absoluta y puso su cero a – 273,15 ° C. Esta es la razón por la que la escala absoluta se denomina a veces escala de Kelvin, y por qué las temperaturas en esta escala se miden en kelvins.
La ley del gas ideal, P·V = k·T, es una ley fenomenológica, es decir, resume hechos experimentales sobre gases. La teoría cinética de los gases ofrece una explicación teórica de estos hechos. Para prepararnos para eso, necesitamos desarrollar un modelo cinético de un gas.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo La ley del gas ideal y la tercera ley de la termodinámica se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Carnot y los comienzos de la termodinámica (2)
- La segunda ley de la termodinámica
- Carnot y los comienzos de la termodinámica (1)
Gradualismo o saltacionismo… en evolución lingüística

El gradualismo y el saltacionismo son dos grandes corrientes de pensamiento en biología evolutiva. Los gradualistas sostienen que la evolución de las especies ocurre de forma gradual, mientras los saltacionistas defienden la idea de que los cambios son abruptos, y que antes y después de los mismos, prácticamente no se produce variación alguna durante largos periodos de tiempo; en otras palabras, que la evolución no ocurre poco a poco sino a saltos.
Se han planteado incógnitas similares en relación con la evolución de las lenguas. Hace unos años, un grupo liderado por el británico Mark Pagel analizó la evolución de diferentes grupos de lenguas: indoeuropeas (en Europa), bantúes (en África) y austronesias (en el Pacífico). Encontraron que los cambios más importantes ocurren en los periodos en que se produce la divergencia de distintas variedades dentro de una misma lengua y que acaban dando lugar a nuevas lenguas. Así, han llegado a la conclusión de que un tercio de la variación del vocabulario en las lenguas bantúes se ha producido en los periodos de diferenciación, y que esas proporciones han sido de un 20% en las lenguas indoeuropeas, y de un 10% en las austronesias.
La hipótesis que proponen para explicar ese fenómeno es que la diferenciación que da lugar a la aparición de nuevas lenguas es un proceso de evolución cultural que no ocurre, como pasa con otros, de manera pasiva. Según los autores, esa diferenciación tendría una cierta componente activa, una componente que obedecería al interés de las comunidades de hablantes por diferenciarse unas de otras. A eso se debería que en los momentos iniciales de la diferenciación los cambios se produzcan de forma especialmente rápida, haciéndose más graduales posteriormente.
Es interesante valorar las diferencias observadas entre las tres familias lingüísticas. Las distintas proporciones de diferenciación en las bifurcaciones dentro de cada familia de lenguas son coherentes con la idea de la componente activa en el proceso de generación lingüística. Allí donde la separación entre comunidades vino muy determinada por barreras físicas (todo un amplio mar separando diferentes archipiélagos), no era necesario acentuar las diferencias, pues las comunidades ya estaban separadas físicamente; y así, el proceso de diferenciación ha sido mucho más pasivo. Esto es, el mismo aislamiento de las comunidades actuaría diferenciando pasivamente a unas lenguas de otras. Muy probablemente las comunidades bantúes experimentaban, por comparación, una mayor necesidad de diferenciación cultural, por lo que la diferenciación de esas lenguas ha contado con una componente más activa que las de las otras familias.
Las lenguas, en todo el mundo, son algo más que meras herramientas de comunicación, tanto si nos gusta como si no.
Fuente:
Atkinson, Q., Meade, A., Venditti, C., Greenhill, S., Pagel, M. (2008): Language evolves in punctuational bursts. Science 319 (5863), p. 588. doi: 10.1126/science.1149683
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Gradualismo o saltacionismo… en evolución lingüística se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Sistemas nerviosos: evolución del tamaño de las regiones encefálicas
- Turquía prohíbe la enseñanza de la evolución – pero la ciencia no es un sistema de creencias
- Sistemas nerviosos: evolución del tamaño encefálico
Verdín, eucaliptos y cambio climático

Un estudio del Departamento de Biología Vegetal y Ecología de la UPV/EHU evidencia que los efectos del cambio climático, en este caso la escasez de agua en los sistemas acuáticos junto con la presencia de plantaciones de eucaliptos, están cambiando el metabolismo de dichos sistemas. Se trata, según Aingeru Martínez, uno de los autores del estudio, de otra evidencia de la alteración de los ciclos de nutrientes a nivel global.
El aumento de temperatura es, normalmente, el aspecto más destacado del cambio climático; sin embargo, no es el único. Las variaciones en el nivel de agua constituyen otro aspecto a tener en cuenta. Según Martínez, “se está observando que existen periodos cada vez más pronunciados y prolongados de escasez de agua en los sistemas acuáticos, lo cual es normal en regímenes áridos y mediterráneos; pero se está dando también en zonas de ambiente templado como la nuestra. Es importante saber qué impacto tiene eso sobre los ecosistemas acuáticos”.
El estudio contempla, además, el efecto que producen las plantaciones de monocultivo de Eucalyptus grandis, una de las especies de árboles más plantadas del mundo, en los ecosistemas acuáticos. Y es que las hojas de eucalipto, una vez sumergidas, transfieren al agua materia orgánica disuelta, “algo similar a lo que ocurre cuando hacemos una infusión”, aclara. Así es como se crean los lixiviados de hojarasca que, en el caso del eucalipto, “son muy recalcitrantes, ricos en compuestos secundarios complejos y aceites que son difícilmente metabolizables por las comunidades biológicas; incluso llegan a ser tóxicos”, explica Martínez. “Nos parecía importante unir estos dos aspectos: por una parte, el modo en el que puede afectar la escasez de agua, y por otra parte, el hecho de que los sistemas acuáticos estén rodeados de plantaciones de eucalipto”, añade.
La investigación se ha centrado en el análisis de los citados efectos en el biofilm, “el verdín que vemos en las piedras de ríos y embalses”, aclara Martínez. El biofilm es uno de los componentes básicos de las cadenas tróficas, y “juega un papel fundamental tanto en el ciclo biogeoquímico de la materia orgánica disuelta como en la transferencia de materia, nutrientes y energía a niveles tróficos superiores. Así, alteraciones en el metabolismo del biofilm podrían generar una reacción en cascada, y afectar al funcionamiento de los ecosistemas de agua dulce”, afirma Aingeru Martínez.
Para poder conocer los efectos de los lixiviados de hojarasca en el biofilm, han llevado a cabo un experimento en el que han sumergido sustratos artificiales colonizados por biofilm en cinco diferentes concentraciones de lixiviados de E. grandis, “a fin de simular las concentraciones que se pueden encontrar en los sistemas naturales según el grado de escasez de agua”. Han medido los efectos sobre el crecimiento, la respiración, la producción primaria, la concentración de nutrientes y la actividad exoenzimática. “Los efectos más significativos se observaron sobre la respiración y la producción primaria. Esto altera el metabolismo de la comunidad, ya que se vuelve más heterótrofa, es decir, existe un mayor consumo de oxígeno y liberación de CO2 al medio”.
Por lo tanto, debido a la importancia del biofilm sobre el funcionamiento de los sistemas de agua dulce, “se podría decir que los periodos de escasez de agua, junto con la presencia de plantaciones extensivas de eucaliptos, alteran el metabolismo y, por tanto, el funcionamiento de los sistemas de agua dulce a nivel mundial. Teniendo en cuenta la importancia de los sistemas acuáticos de agua dulce en el ciclo del carbono, a nivel global, se trataría de una evidencia más de que nuestras actividades están produciendo cambios en los ciclos de nutrientes a nivel global”.
Referencia:
Martínez A, Kominoski JS & Larrañaga A, (2017) “Leaf-litter leachate concentration promotes heterotrophy in freshwater biofilms: Understanding consequences of water scarcity”.. Science of the Total Environment. Vol. 599–600. Pages 1677–1684.. DOI: 10.1016/j.scitotenv.2017.05.043.
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Verdín, eucaliptos y cambio climático se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El declive de las praderas de algas por el cambio climático
- Del cambio climático
- “El cambio climático: ciencia, política y moral” por José Manuel Sánchez Ron
Retrodiagnósticos

Goya atendido por el doctor Arrieta (Francisco de Goya, 1820). La cartela de abajo reza (sic): “Goya agradecido, á su amigo Arrieta: por el acierto y esmero con qe le salvo la vida en su aguda y / peligrosa enfermedad, padecida á fines del año 1819, a los setenta y tres de su edad. Lo pintó en 1820” . Cuadro del Instituto de Arte de Mineápolis.
Acertar con los pronósticos o, lo que viene a ser lo mismo, predecir con éxito lo que ocurrirá no es fácil. Y en muchas ocasiones, tampoco lo es acertar con los diagnósticos. La dificultad aumenta cuando de lo que se trata es de indagar acerca de las enfermedades de personas desaparecidas hace tiempo. Eso es lo que intentan hacer en la Historical Clinicopathological Conference, que se celebra todos los años en la Facultad de Medicina de la Universidad de Maryland (EEUU), con personalidades de las que se sabe que sufrieron alguna enfermedad y se dispone de alguna información acerca de sus síntomas.
Cada año se escoge una figura histórica y se propone a un especialista que realice un diagnóstico a partir de la información disponible. Este año le ha tocado a Goya, y la especialista que ha tratado de diagnosticar su enfermedad ha sido Ronna Hertzano, experta en audición. Goya cayó enfermo de “cólico” en 1792 a la edad de 46 años. Un año más tarde una enfermedad misteriosa le obligó a guardar cama. Tenía dificultades de visión, pérdida de equilibrio, fuertes dolores de cabeza y pérdida de audición. Necesitó dos años para recuperarse, al cabo de los cuales quedó sordo para el resto de su vida.
La doctora Hertzano barajó la posibilidad de que se tratase de una intoxicación con plomo, pues lo utilizó con abundancia para pintar, pero en ese caso, los síntomas se hubieran prolongado en el tiempo, como le ocurrió con la sordera. Más probable que haberse intoxicado con plomo, Goya pudo haber contraído la sífilis, pero esta enfermedad muestra síntomas de deterioro neurológico progresivo a lo largo de muchos años, y no hay datos que avalen ese deterioro. Ronna Hertzano se ha inclinado finalmente por una enfermedad autoinmune, el síndrome de Susac. Se trata de una enfermedad muy rara que se caracteriza porque el paciente sufre alucinaciones, parálisis y pérdida de audición. El sistema inmune ataca pequeños vasos sanguíneos encefálicos y el daño puede extenderse a ojos y oídos. No suele durar más de tres años.
En la Historical Clinicopathological Conference se han diagnosticado otros personajes célebres. Lenin pudo haber muerto a causa de una ateroesclerosis cerebral acelerada. Darwin, quien padeció durante buena parte de su vida una molesta enfermedad gastrointestinal, pudo haber sufrido el denominado síndrome de vómitos cíclicos; se trata de una enfermedad de causa desconocida aunque con una cierta componente genética y que no tiene cura, pero cuyos síntomas pueden ser tratados en la actualidad. Poe pudo haber muerto de rabia o, quizás, de delirium tremens. Es probable que la enfermera Florence Nightingale sufriese un trastorno bipolar con rasgos psicóticos o, alternativamente, síndrome de estrés postraumático; la enfermedad se le declaró con 35 años cuando se encontraba en Turquía trabajando como enfermera del ejército británico en condiciones terribles. Mozart quizás falleció por culpa de una fiebre reumática aguda. Es muy posible que Beethoven sufriera sífilis, aunque también pudo haberse envenenado con plomo. Y Pericles pudo haber muerto de tifus. Estos son algunos de los personajes retrodiagnosticados en Maryland.
Tratar de diagnosticar una enfermedad de forma retrospectiva, como se hace en este congreso no deja de ser un divertimiento. Pero tiene su interés. Por un lado, puede arrojar luz acerca de las causas de la muerte de personajes históricos relevantes, lo que en algunos casos tiene importancia histórica. Pero tiene también interés científico, ya que se trata de un ejercicio sometido al escrutinio del resto de especialistas y, muy probablemente, sirve para mejorar las técnicas de diagnóstico que se aplican a los enfermos de hoy. Es, cuando menos, un espléndido ejercicio docente.
—————————-
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
————————
Una versión anterior de este artículo fue publicada en el diario Deia el 4 de junio de 2017.
El artículo Retrodiagnósticos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Ciencia a presión: Científicos que avalan patrañas

La expresión publish or perish (publica o perece) es de sobra conocida en el ámbito científico. Quiere expresar la importancia que tienen las publicaciones en los currículos del personal investigador. En ciencia no basta con hacer observaciones, obtener unos resultados y derivar conclusiones. Hay, además, que hacerlo público y, a poder ser, en medios de la máxima difusión internacional. La ciencia que no se da a conocer, que no se publica, no existe. El problema es que de eso, precisamente, depende el éxito profesional de los investigadores, sus posibilidades de estabilización y de promoción. De ahí la conocida expresión del principio.
El mundo de la comunicación tiene también sus normas. En comunicación se trata de que lo que se publica sea consumido. De la misma forma que la ciencia que no se publica no existe, en comunicación tampoco existen los contenidos que no se consumen: o sea, no existen los artículos que no se leen, los programas de radio que no se oyen, los de televisión que no se ven o los sitios web que no se visitan. En comunicación valdría decir “sé visto, oído o leído, o perece”.
Ambas esferas tienen ahí un interesante punto en común. Y por supuesto, en comunicación o difusión científica el ámbito de confluencia se aprecia en mayor medida aún. Confluyen aquí ambas necesidades, la de hacer públicos los resultados de investigación y, además, conseguir que lleguen a cuantas más personas mejor.
El problema es que la presión por publicar y por tener impacto comunicativo puede conducir tanto a unos como a otros profesionales, a adoptar comportamientos deshonestos, contrarios a la ética profesional e, incluso, a desvirtuar completamente el fin de la ciencia y de su traslación al conjunto del cuerpo social. Y también puede conducir, y de hecho ha conducido, a que se haya configurado un sistema de publicaciones científicas con patologías.
De todo esto se trató el pasado 31 de marzo en “Producir o perecer: ciencia a presión”, el seminario que organizarono conjuntamente la Asociación Española de Comunicación Científica y la Cátedra de Cultura Científica de la UPV/EHU.
1ª Conferencia
José Manuel López Nicolás, profesor de la Universidad de Murcia y divulgador científico: Científicos que avalan patrañas
Científicos que avalan patrañasEdición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Ciencia a presión: Científicos que avalan patrañas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Curso de verano “La ciencia de nuestras vidas”: Cuando la música era ciencia, por Almudena M. Castro
- Curso de verano “La ciencia de nuestras vidas”: Arte, literatura y ciencia, por Gustavo A. Schwartz
- Curso de verano “La ciencia de nuestras vidas”: La ciencia del habla, por Manuel Carreiras
Los límites del Hyperloop

Durante el pasado mes de julio hemos asistido a las primeras pruebas integradas de un sistema hyperloop en las instalaciones de Hyperloop One —la empresa más destacada de las que compiten por poner en marcha este sistema— en Las Vegas, Nevada. Pero ¿qué es un hyperloop? Es difícil no estar al menos vagamente familiarizado con la propuesta de un «quinto modo de transporte» realizada por el magnate Elon Musk, conocido por SpaceX y Tesla, en un white paper de 2013 [1] dado el tratamiento masivo que cualquier avance técnico o propuesta relacionada con el asunto tiene en todos los medios de comunicación.
En breve: un hyperloop es un sistema de cápsulas de transporte que se desplazan sin contacto a velocidades cercanas a la del sonido a través de un tubo en el que se ha evacuado el aire hasta llegar a condiciones de casi vacío, y que aceleran mediante motores de inducción lineales ubicados a intervalos regulares dentro de los tubos. Un sistema así puede sorprender por lo atrevido de la propuesta, pero una lectura rápida de las especificaciones técnicas y las estimaciones de costes avanzadas por Musk levanta, legítimamente, más de una ceja en la comunidad de expertos en transporte [2][3]. Más allá de análisis teóricos, los propios progresos de la empresa que más ha avanzado en la implementación física del concepto desvelan cuáles serán los problemas a los que tendrá que enfrentarse en un futuro inmediato y que tienen el potencial de dar al traste con todo el proyecto.
Durante la madrugada del sábado 29 de julio, Hyperloop One realizó su primera prueba de «fase 2» [4]. La cápsula de prueba denominada XP-1 recorrió un total de 437 metros en un tubo evacuado a una presión inferior a 100 Pa (la milésima parte de la presión atmosférica), alcanzando en el proceso una velocidad máxima de 310 km/h. El motor de inducción lineal utilizó para ello un estátor de 300 metros de longitud, de donde podemos deducir algún parámetro más de la prueba aplicando algo de cinemática elemental.
Suponiendo que la cápsula partió del reposo y que la aceleración impartida fue constante, resulta que debió estar sujeta a 12,36 m/s², unos 1,26 g. La frenada debió ser algo más intensa, de 2,76 g: afortunadamente, la XP-1 no es más que un chasis cubierto con una estructura hueca de fibra de vidrio [5]. Unos potenciales pasajeros habrían encontrado el viaje extremadamente poco confortable. No hay que olvidar, sin embargo, que la limitación de longitud que presenta el tramo de pruebas de Hyperloop One en Las Vegas prácticamente obliga a sostener aceleraciones y frenadas de semejante intensidad si se desea probar el sistema a cualquier velocidad significativa.

Vista frontal de la sección del tubo de pruebas de Hyperloop One. Fuente: Hyperloop One
Hyperloop One es un tanto parca ofreciendo datos técnicos relacionados con sus pruebas, aunque un poco más de estudio sobre el vídeo y los materiales de prensa publicados deberían permitir hacer alguna inferencia más allá de la cinemática del sistema. Será importante conocer con alguna precisión las dimensiones de la cápsula: en la documentación disponible se afirma que mide 8,69 metros de longitud y 2,71 metros de altura. Examinando las imágenes disponibles esta altura parece excesiva; además, el parámetro fundamental de la anchura de la cápsula, necesario para calcular su sección y sus características aerodinámicas, no aparece por ninguna parte. Un pequeño trabajo de estimación sobre el vídeo de la prueba permite conjeturar que el diámetro interior del tubo debe rondar los 4 metros, mientras que la cápsula misma debería tener una anchura de alrededor de 3 metros.
La altura del carenado parece no superar los 1,80 metros a la vista de las fotografías. Tomemos una altura de 2 metros para arrojar una sección transversal aproximada de 6 m²; el tubo mismo tendría una sección interior de 12,67 m². Estos datos son consistentes con la intención de Hyperloop One de centrarse en el segundo de los diseños propuestos por Musk: el hyperloop de mercancías —aunque Musk lo concibió como un medio mixto de viajeros y carga que podría transportar vehículos como (naturalmente) un Tesla S. El primer diseño, de menor sección y supuestamente de construcción más barata, sería prácticamente un homoducto [6] que lanzaría a un pequeño grupo de personas reclinadas en el interior de un tubo de 1,35 por 1,10 metros como si fueran fajos de billetes en un supermercado. En cualquier caso, la incertidumbre propia de las medidas nos permite estimar que la cápsula ocupa alrededor de la mitad de la superficie disponible en su desplazamiento. ¿Por qué es esto importante?
El límite de Kantrowitz
El mismo equipo de Elon Musk, en la redacción del artículo original que sirvió como pistoletazo de salida para la definición del hyperloop, resaltó un parámetro clave de dinámica de gases que resulta limitante en el diseño de un sistema de transporte que debe alcanzar velocidades transónicas —cercanas a las del sonido— en el interior de un tubo, por analogía con el flujo de aire a través de la boca de una turbina en un motor a reacción. Se trata del llamado «límite de Kantrowitz», por Arthur Kantrowitz, ingeniero estadounidense que derivó la expresión de un límite en el flujo de un gas a velocidades transónicas cuando atraviesa una zona en la que se fuerza una reducción en su sección [7]. Como el flujo del gas debe ser continuo, un estrechamiento supone un aumento correspondiente de su velocidad hasta alcanzar la velocidad local del sonido; en este momento el flujo de gas resulta obstruido.
En el hyperloop el límite de Kantrowitz puede visualizarse como un «efecto jeringa». En una jeringa, si se impide el flujo de aire a través de su boquilla, el émbolo no puede seguir avanzando si no es comprimiendo el aire que haya en su interior realizando un esfuerzo inconmensurable con el necesario para hacerlo avanzar en condiciones de flujo normal —es decir, con la boquilla sin tapar. El límite de Kantrowitz es, entonces, la velocidad a la que la sección mínima del hueco entre la cápsula y el tubo provoca un aumento súbito en la resistencia del aire, por poco que sea. De hecho, la ecuación del límite relaciona la razón entre el hueco citado y la sección interna del tubo con la velocidad, y ni siquiera tiene en cuenta la presión local del aire [8].
Las estimaciones que hemos realizado antes sobre las dimensiones de la cápsula XP-1 permiten averiguar la velocidad a la que el sistema debería encontrarse con el límite de Kantrowitz: ocurrirá alrededor de Mach 0,55, o suponiendo una temperatura interior del tubo de 20 °C, a 188 m/s², es decir, 677 kilómetros por hora. Una cifra algo decepcionante teniendo en cuenta que el relato de Hyperloop One de la prueba incluye la siguiente cita textual, un tanto fanfarronesca dadas las condiciones actuales de las instalaciones de ensayo:
With an additional 2000 meters of stator, we would have hit 1100 km per hour […]
Es decir, 2 kilómetros adicionales de aceleración habrían permitido alcanzar los 1100 km/h. Esto, simplemente, no es cierto salvo que el sistema disponga de potencia suficiente para arrastrar la cápsula más allá del pico de resistencia impuesto por la dinámica de gases, algo que sin duda dispararía el consumo energético de todo el conjunto mucho más allá de lo previsto, afectando de forma crítica a su viabilidad.
El artículo original de Musk discutió —correctamente— la pertinencia del límite de Kantrowitz en el sistema del hyperloop. Las velocidades previstas tanto por Musk como por Hyperloop One para el sistema se encuentran en el entorno de Mach 0,9 (aproximadamente 1100 km/h), lo que arroja una relación de sección libre frente a total de 0,99. Es decir, un hyperloop solo podría funcionar a la velocidad objetivo en el interior de un tubo gigantesco respecto a su propia sección transversal, eliminando así toda posible ventaja que la existencia del tubo pudiera conllevar. Pero Musk abordó el problema proponiendo una solución decididamente ingeniosa: ¿por qué no incorporar en el frontal de la cápsula un compresor axial similar al de los turborreactores? De esta forma, sería la propia cápsula la que evacuaría el aire que se fuera encontrando, aumentando así la sección libre en función de la tasa de compresión que proporcionara el sistema. Yendo un paso más allá, Musk y su equipo calcularon que el compresor debería ofrecer una relación de compresión de 20 a 1, y realizaron los cálculos necesarios para aprovechar parte del aire para los sistemas de soporte vital de la cápsula, a la vez que tenía en cuenta el resultado impuesto por la termodinámica para un gas que se comprime: un aumento de su temperatura.

Frontal de la cápsula de Hyperloop One. Obsérvese la ausencia de ningún tipo de estructura. En la fotografía, de izquierda a derecha, Josh Giegel y Shervin Pishevar, cofundadores de Hyperloop One. Fuente: Hyperloop One.
Sin embargo, una simple inspección de la cápsula XP-1 permite descartar que disponga de compresor axial alguno montado en su frontal —mostrado, por otro lado, en prácticamente todas las recreaciones artísticas de la cápsula del hyperloop como la que encabeza este artículo, realizada por Hyperloop One (aunque ya no puede encontrarse en su web). Esta falta de compresor es la que permite calcular con tanta seguridad a qué velocidad encontrará el límite de Kantrowitz; ahora bien, ¿no bastará con instalar un compresor en el frontal para solventar el problema? Después de todo, según afirmó a principios de año el Dirk Ahlborn, director de Hyperloop Transportation Technologies (y competencia de Hyperloop One en la carrera por traer a la realidad los tubos), «la tecnología [para construir un hyperloop] no es la cuestión —ya existe» [9].
Pues bien, esta afirmación es falsa. Hoy por hoy no existe un compresor axial con las características necesarias para equipar una cápsula de hyperloop como la que Hyperloop One está proponiendo, ni de hecho como ningún otro diseño. Los compresores de las turbinas utilizadas en aviación superan con frecuencia las relaciones de compresión de 20:1, pero funcionan con keroseno. Sin duda no es imposible desarrollar una turbina eléctrica que realice esa función, aunque la incógnita sobre su desarrollo obligaría a ser más prudente con los plazos y no realizar afirmaciones como las que acostumbran a hacer los participantes en la «carrera del hyperloop» —y a difundir, sin crítica ni comentario, los medios de comunicación. El consumo eléctrico de este teórico compresor eléctrico es también una incógnita, por más que simples cálculos termodinámicos permitan establecer un límite inferior.
Por esto, el balance energético total del sistema citado por Musk debe ser puesto claramente en duda. Si además tenemos en cuenta que el gasto energético mostrado para los diferentes medios de transporte en la primera figura del paper es clara ¿e intencionadamente? erróneo —en lo que respecta, al menos, al ferrocarril— no es ninguna insensatez dudar, como muchos llevamos tiempo haciéndolo, de la viabilidad del sistema en su conjunto.
Gastos energéticos por trayecto citados por Musk en su paper. Los valores «por pasajero y trayecto» y no por pasajero-kilómetro hacen la gráfica ambigua, aunque suponiendo que se refiere al proyecto de alta velocidad Los Ángeles-San Francisco, un valor más razonable basado en cálculos realistas [10] es al menos cuatro veces inferior (!) al reportado por Musk
¿Tener compresor o no tener compresor?
Llegados a este punto nos encontramos con una disyuntiva: o bien se desarrolla el compresor axial eléctrico necesario para el funcionamiento del sistema tal y como fue diseñado, o no. En el primer caso podríamos, teóricamente, incrementar la velocidad punta del sistema de transporte hasta un régimen cuasi-transónico. Nos encontraríamos entonces con una limitación termodinámica por la que pasa de puntillas el diseño original: como quiera que un gas sujeto a compresión incrementará fuertemente su temperatura, es necesario hacer algo con la energía adicional si no deseamos que la cápsula se transforme en una especie de horno de aire —un horno de aire es un artefacto ideal para hacer patatas fritas con muy poca grasa, pero no muy indicado para transportar personas o mercancías. Musk concibe un sistema de refrigeración basado en agua, un par de intercambiadores térmicos (intercoolers) y varios tanques dispuestos para almacenar agua y vapor, y los dimensiona de acuerdo con sus cálculos.
Un poco más adelante, en una sola línea de la descripción del sistema compresor y como pretendiendo que pase inadvertido (apartado 4.1.3) se afirma lo siguiente:
Water and steam tanks are changed automatically at each stop.
Es decir, «los tanques de agua y vapor son intercambiados [por otros frescos] automáticamente en cada parada». Este curioso y poco reportado (¿por trivial?) paso tiene una cierta reminiscencia a los depósitos de agua de las antiguas locomotoras de vapor. Tiene también el defecto de complicar la logística de la gestión de las cápsulas, algo que para mantener el flujo previsto de pasajeros del sistema tiene que realizarse con total precisión y a gran velocidad al objeto de mantener el flujo de pasajeros previsto que da sentido al sistema en su conjunto. Es, además, una complejidad a añadir al previsto cambio de batería tras cada viaje: como quiera que la cápsula no obtiene energía de la infraestructura como lo haría un tren eléctrico, toda la operación interna del sistema (compresor, intercambiadores de calor, válvulas y sistemas de soporte vital, entre otros) tiene que sustentarse con baterías.
El mismo Musk, a través de Tesla, su empresa automovilística, lleva ya años preconizando la creación de una infraestructura de intercambio rápido de baterías para sus coches eléctricos. Esto tendría la ventaja obvia de sustituir los potenciales largos tiempos de carga de las baterías de los vehículos por un futurista y automático intercambio robotizado. Sin embargo, la creciente disponibilidad de sistemas de carga rápida (y, potencialmente, la introducción de un punto clave de fallo en una conexión eléctrica fundamental en los vehículos, con el consiguiente y previsible descenso en la fiabilidad) ha impedido que esta tecnología se desarrolle [11]. Ni siquiera hay prototipos que puedan adaptarse para su uso en las cápsulas del hyperloop: cuánto menos los habrá si se trata de intercambiar baterías junto con tanques de aire y vapor de agua a presión y sobrecalentado, que deben conectarse no ya mediante un contacto eléctrico, sino mediante válvulas robustas.
La otra opción en la disyuntiva de diseño es olvidar el compresor frontal y operar el sistema a velocidades subsónicas por debajo de Mach 0,5. Un hyperloop que opere a una velocidad punta en el entorno de los 600 km/h podría ser factible, aunque está mucho menos claro que el sistema de transporte resultante sea atractivo en costes de construcción por km, costes de mantenimiento, consumo energético y confort respecto de su competencia más obvia, el tren de alta velocidad. Décadas de desarrollo por parte de empresas y organismos públicos en los EE.UU., Alemania, Japón y China han llevado al despliegue comercial de un sistema presentado por muchos expertos como «el transporte del futuro»: el tren de levitación magnética o maglev.
Hoy hay una línea en el mundo funcionando comercialmente como un tren de levitación magnética de alta velocidad: el Transrapid de Shanghai que cubre una distancia de 30,5 kilómetros en 8 minutos a una velocidad máxima récord de 430 km/h. El resto de los trenes de levitación magnética existentes en el mundo son líneas automáticas de baja o media velocidad, concebidas según el modelo people mover propio de grandes aeropuertos. En el futuro la Chūō Shinkansen [12][13], una línea de mayor alcance y más similar al perfil de transporte al que aspira hyperloop, deberá cubrir el trayecto Tokio-Nagoya-Osaka en algo más de una hora, alcanzando una velocidad punta de 505 kilómetros por hora. Según la planificación actual esta línea —una auténtica maravilla de la ingeniería, con más del 86% del trayecto en su primer tramo ejecutado en túnel— debería poner en servicio su primer tramo (Tokio-Nagoya) en 2027 y el segundo (Nagoya-Osaka) en 2045. No puedo dejar pasar la oportunidad de que estos y no otros son plazos realistas para una infraestructura de transporte puntera; en ningún caso lo son los que se están divulgando desde el entorno de hyperloop y Elon Musk.
De todos modos, la mayoría de expertos en sistemas de transporte opinan que los grandes proyectos de trenes de levitación magnética son «elefantes blancos» [14]: obras realizadas más como forma de señalar el prestigio de un país que como forma práctica de mover grandes flujos de personas entre ubicaciones populosas. El potencial incremento en la velocidad comercial de un sistema maglev requiere de unos costes por kilómetro consecuentemente elevados, que solo se justifican con una demanda de transporte extremadamente intensa. A falta de tales condiciones y con un riesgo tecnológico inexistente, el tren de alta velocidad se erige como la alternativa al transporte privado. Fiable [15] y maduro aunque todavía con margen de mejora, permite conectar entre sí centros urbanos separados por centenares de kilómetros con mínimo impacto ambiental y costes conocidos.
El concepto del hyperloop plantea, además de las aquí reseñadas, muchas otras dudas y limitaciones técnicas no menos importantes desde puntos de vista tecnológicos, operativos y de seguridad. Es por todo esto que puede afirmarse con rotundidad que hyperloop no ocurrirá. Desde luego no en cuatro años, como afirma Hyperloop One. Tampoco en veinte años —el mínimo razonable para un proyecto con tanta tecnología en el aire. Y quizá nunca.
Este post ha sido realizado por Iván Rivera (@Brucknerite) y es una colaboración de Naukas con la Cátedra de Cultura Científica de la UPV/EHU
Para saber más
[1] Musk, E. R. et al. (12/08/2013). Hyperloop Alpha. Visitado el 14/08/2017 en http://www.spacex.com/sites/spacex/files/hyperloop_alpha-20130812.pdf.
[2] Bradley, R. (10/05/2016). The Unbelievable Reality of the Impossible Hyperloop, MIT Technology Review. Visitado el 14/08/2017 en https://www.technologyreview.com/s/601417/the-unbelievable-reality-of-the-impossible-hyperloop/.
[3] Konrad, A. (18/11/2016). Leaked Hyperloop One Docs Reveal The Startup Thirsty For Cash As Costs Will Stretch Into Billions, Forbes. Visitado el 14/08/2017 en https://www.forbes.com/sites/alexkonrad/2016/10/25/hyperloop-one-seeks-new-cash-amid-high-costs/#4f78547d125c.
[4] Giegel, J., Pishevar, S. (02/08/2017). Hyperloop Gets More Real Every Time We Test, Hyperloop One. Visitado el 14/08/2017 en https://hyperloop-one.com/blog/hyperloop-gets-more-real-every-time-we-test.
[5] Hyperloop One. (10/08/2017). What Testing Has Taught Us. Visitado el 14/08/2017 en https://hyperloop-one.com/blog/what-testing-has-taught-us.
[6] «Homoducto», del latín homo (ser humano) y ductus (conducto), palabra acuñada por @Mssr_Pecqueux en conversación de Twitter https://twitter.com/brucknerite/status/733684888033984512.
[7] Kantrowitz, A., Coleman, duP. (05/1945). Preliminary Investigation of Supersonic Diffusers. Advance Confidential Report L5D20, National Advisory Committee for Aeronautics. Visitado el 14/08/2017 en http://www.dtic.mil/dtic/tr/fulltext/u2/b184216.pdf.
[8] Una expresión apropiada para el límite de Kantrowitz según se aplica al Hyperloop es:![]()
Donde Abypass es la sección libre, Atube la sección interna total, γ el factor de expansión isentrópica y M el número de Mach del flujo de aire (equivalente a la velocidad de avance de la cápsula).
[9] Carlström, V. (26/01/2017). HTT’s CEO says a hyperloop line will be up and running within three years: “The technology is not the issue – it already exists”, Business Insider Nordic. Visitado el 14/08/2017 en http://nordic.businessinsider.com/htts-ceo-says-a-hyperloop-line-will-be-up-and-running-within-three-years-the-technology-is-not-the-issue–it-already-exists-2017-1/
[10] García Álvarez, A. (01/2008). Consumo de energía y emisiones del tren de alta velocidad en comparación con otros modos. Vía Libre, (515). Visitado el 14/08/2017 en https://www.vialibre-ffe.com/PDF/Comparacion_consumo_AV_otros_modos_VE_1_08.pdf
[11] Korosec, K. (10/06/2015). Tesla’s battery swap program is pretty much dead, Fortune. Visitado el 14/08/2017 en http://fortune.com/2015/06/10/teslas-battery-swap-is-dead/
[12] Chuo Shinkansen Maglev Line. Railway Technology. Visitado el 14/08/2017 en http://www.railway-technology.com/projects/chuo-shinkansen-maglev-line/.
[13] JR Central (2012). The Chuo Shinkansen using the Superconducting Maglev System. JR Central Annual Report. Visitado el 14/08/2017 en http://english.jr-central.co.jp/company/ir/annualreport/_pdf/annualreport2012-05.pdf
[14] Binning, D. (11/02/2008). Maglev – the Great Debate, Railway Technology. Visitado el 14/08/2017 en http://www.railway-technology.com/features/feature1606/
[15] European Commision. (10/02/2017). Rail accident fatalities in the EU. Visitado el 14/08/2017 en http://ec.europa.eu/eurostat/statistics-explained/index.php/Rail_accident_fatalities_in_the_EU
El artículo Los límites del Hyperloop se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- En los límites del frío
- Cuántica y relatividad por todas partes
- ¿Por qué el Rover Curiosity es más lento que un caracol?
Más allá de los experimentos

Un error muy extendido, usado también como argumento a favor de algunas pseudociencias y en contra de ciertas teorías como la de la Evolución por Selección Natural, es postular que sólo puede ser conocimiento científico aquel que surge de un experimento. Según esta idea la ‘verdadera ciencia’ es la que sale de los laboratorios, de la comprobación de hipótesis en un entorno controlado con estricta determinación de variables sistemáticamente bien controladas para evitar la interacción. Todas las fuentes de error son localizadas y eliminadas, todas las fuentes de ruido minimizadas y cada variable independiente es determinada y su influencia sobre el fenómeno estudiado es medida; la ciencia es o debe ser como la física o la química, un ejercicio de extrapolación controlada a partir de casos limitados estudiados en laboratorio, porque el único conocimiento real es el que tiene base experimental.
En ocasiones se llega a discutir incluso la posibilidad de generalizar y se intenta argumentar que ninguna ley puede ser considerada verdaderamente científica a no ser que se pueda demostrar que se cumple en todos y cada uno de los casos; es el origen del ‘amimefuncionismo’ tan típico para defender pseudociencias como la homeopatía. En el fondo, y dada la imposibilidad práctica de cumplir esta condición, se trata de negar la existencia misma de la ciencia o el conocimiento: si es imposible generalizar es imposible saber, dado que cada caso concreto es independiente de todos los demás y cualquier abstracción es imposible. Si cada caso es un caso particular nunca podemos saber nada en general y el conocimiento es imposible: nihilismo epistemológico, o la ignorancia disfrazada de escepticismo extremo.
Igual ocurre con la exigencia de que todo conocimiento científico provenga de un experimento, que para empezar niega la consideración de ciencia a cualquier proceso histórico: como no podemos hacer un experimento que repita la historia de la Tierra la Evolución por Selección Natural no es una teoría científica. Como tampoco puede serlo el Big Bang, la tectónica de placas o la secuencia principal de la evolución estelar. En su interpretación más extrema hasta la historia humana sería imposible de conocer, ya que el Imperio Romano, las sociedades paleolíticas o el Siglo de Oro español son imposibles de reproducir experimentalmente. El pasado sería por tanto incognoscible.
Muchos de quienes usan este tipo de argumentos para defender las bondades de una pseudoterapia o como garrota contra Darwin no son conscientes de que en realidad están rechazando la existencia de cualquier posibilidad de conocimiento al hacerlo; tampoco es que a la mayoría de ellos les moleste demasiado. Llevado al extremo el nihilismo epistemológico haría también imposible cosas como perseguir a un criminal: en ausencia de testigos directos o grabaciones no habría ninguna forma de demostrar la comisión de un crimen, ya que ninguna pista sería suficiente prueba. No sólo el conocimiento, sino la misma sociedad dejaría de funcionar si nuestros criterios de confirmación fuesen tan estrictos. La exigencia de experimentación y de estudio caso por caso son formas de rechazo del intelecto mismo; incluso de los elementos clave de la Humanidad, una especie de auto odio en versión intelectual.
El universo que hay ahí fuera es cognoscible; las leyes existen, las generalizaciones son posibles y el experimento es una herramienta más a disposición de quien busca el conocimiento. A partir de casos concretos se pueden crear conclusiones generales que pueden ser útiles en presencia de nuevos casos. Lo ocurrido en el pasado deja pistas en el presente que pueden ser utilizadas para reconstruir lo ocurrido. Las leyes científicas existen y se pueden usar, aunque pocas sean inmutables y eternas. El cosmos es sutil, pero no malicioso, lo que nos permite usar la razón y fiarnos de las conclusiones obtenidas con ella incluso cuando se refieren a un pasado remoto. El avance de la ciencia nos demuestra que podemos conocer el universo y los intentos de rechazar esta idea para defender absurdas teorías no muestran más que la bancarrota intelectual de quienes están dispuestos a rechazar la idea misma de conocimiento sólo por no dar su brazo a torcer.
Sobre el autor: José Cervera (@Retiario) es periodista especializado en ciencia y tecnología y da clases de periodismo digital.
El artículo Más allá de los experimentos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Curso de verano “Las dos culturas y más allá”: El caso de la lingüística y las ciencias cognitivas
- Curso de verano “Las dos culturas y más allá”: Ciencia, Sociedad y Desarrollo
- Curso de verano “Las dos culturas y más allá”: Ciencia y Poder
Amelia quiere explorar el desierto
Sí, Amelia quiere explorar el desierto. Ha conseguido el patrocinio de una millonaria que le impone unas cuantas reglas para que agudice su ingenio. Las explicamos a continuación.
Amelia tiene a su disposición una cantidad ilimitada de gasolina almacenada en el lugar de salida, en el límite del desierto.
Para realizar su viaje, dispone de un jeep en el que puede transportar como máximo, en cada momento, una unidad de combustible. Con cada unidad de gasolina puede viajar una unidad de distancia; se supone que el consumo de combustible es constante.
En cualquier momento del viaje, Amelia puede dejar cualquier cantidad de combustible en un depósito para poder recogerlo más tarde al volver a pasar por allí. La mecenas le exige, además, que siempre que el jeep comience a salir del desierto debe regresar necesariamente al punto de partida.
Con todas estas normas impuestas, la pregunta es: ¿hasta dónde puede llegar Amelia en su paseo por el desierto?
Vamos a intentar ver que puede llegar tan lejos como quiera, solo con un poco de estrategia por su parte. Para ello, vamos a explicar lo lejos llegaría realizando tres viajes –saliendo tres veces del punto de partida– para describir después el caso general.
La estrategia de Amelia si realiza tres salidas
Amelia sale de la base una unidad de gasolina en el depósito del jeep y conduce 1/6 de unidades de distancia. Es decir, ha consumido la sexta parte del combustible. Deja 2/3 de unidades de combustible en un depósito, y regresa al punto de partida con el 1/6 de combustible que le queda.

Figura 1: Sobre el coche, en blanco aparecen las unidades de gasolina en el depósito, y en los bidones, en rojo, la cantidad de combustible almacenada. Fuente: Marta Macho Stadler
Amelia vuelve a cargar el depósito del jeep al máximo –es decir con una unidad de combustible– y conduce 1/6 de unidades de distancia. Ha gastado 1/6 de unidades de gasolina; llena el depósito del coche con 1/6 de combustible tomado del depósito, y vuelve a adentrarse en el desierto, dejando en el primer depósito 1/2 de unidades de fuel. Desde ese punto conduce 1/4 de unidades de distancia y deposita 1/2 unidad de gasolina en un segundo recipiente. Le quedan 1/4 de unidades de fuel, lo justo para llegar al primer bidón. De ese recipiente toma 1/6 de unidades de combustible –es decir, deja el primer bidón con 1/3 de unidades de fuel– y llega a la base con el depósito del coche vacío.
Figura 2 : Sobre el coche, en blanco aparecen las unidades de gasolina en el depósito, y en los bidones, en rojo, la cantidad de combustible almacenada. Fuente: Marta Macho Stadler
Amelia carga el coche con el máximo de gasolina, llega al primer bidón y utiliza 1/6 de combustible para volver a llenar el depósito del jeep –así, en el primer depósito, deja 1/6 de unidades de gasolina–. Llega al segundo recipiente tras recorrer 1/4 de unidades de distancia, y allí vuelve a llenar el vehículo con fuel, dejando en el segundo depósito 1/4 de unidades de combustible, y continúa su viaje hacia el interior del desierto. Tras recorrer 1/2 unidad de distancia, da la vuelta, llega al segundo recipiente gastando todo el combustible que le queda, usa el fuel del segundo recipiente para llegar al primero y de nuevo toma la gasolina del primer bidón para regresar al punto de partida.
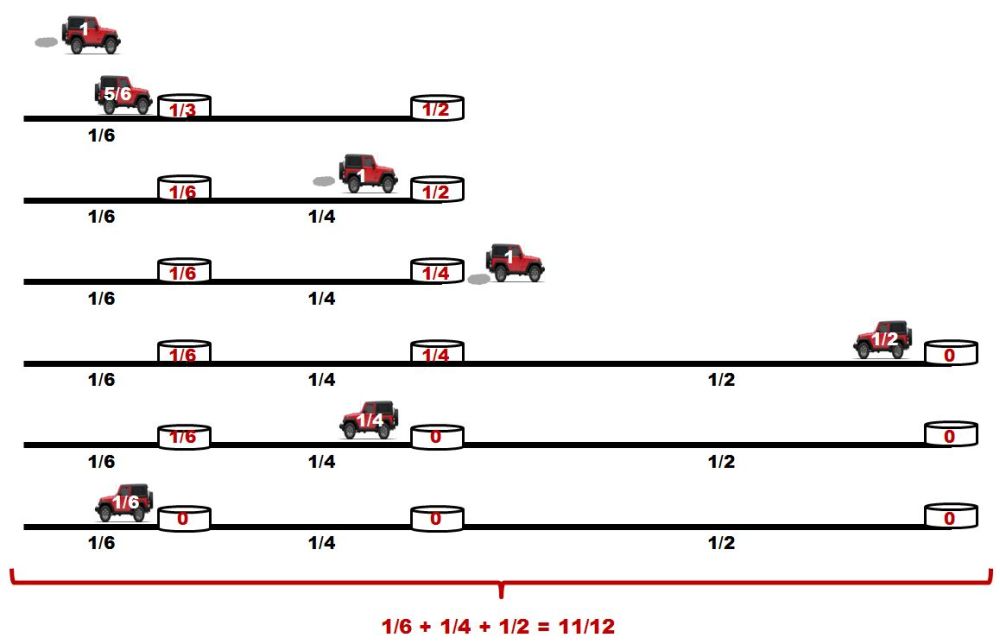
Figura 3: Sobre el coche, en blanco aparecen las unidades de gasolina en el depósito, y en los bidones, en rojo, la cantidad de combustible almacenada. Fuente: Marta Macho Stadler
Así, con estas tres idas y vueltas, Amelia se ha adentrado en el desierto 11/12 de unidades de distancia.
Entendiendo el caso general
La estrategia utilizada por Amelia con tres salidas desde el límite del desierto puede generalizarse para cualquier n:
-
El jeep realiza n viajes de ida y vuelta.
-
En la primera salida, viaja 1/(2n) de unidades de distancia, deja (n − 1)/n unidades de gasolina en el primer depósito, quedándose con el combustible justo para llegar a la base.
-
En cada una de las n − 1 siguientes salidas, y en dirección hacia el interior del desierto, Amelia va tomando de cada depósito el combustible necesario para llenar al máximo el jeep y llegar al siguiente depósito. Y al regresar, va tomando solo la gasolina suficiente para llegar al depósito anterior.
-
Esta operación la puede realizar n veces, dejando en su último viaje todos los bidones vacíos, y habiendo recorrido en la dirección del desierto
1/2 + 1/4 + 1/6 + … + 1/(2n) = 1/2 (1 + 1/2 + 1/3 + … + 1/n)
de unidades de distancia.
Recordemos que 1 + 1/2 + 1/3 + … + 1/n es el n-ésimo número armónico,la suma parcial n-ésima de la serie armónica, que es una serie divergente.
¿Y que tiene esto que ver con el viaje de Amelia? Si la exploradora utiliza la estrategia anteriormente descrita, podrá adentrarse en el desierto todo lo que desee, porque para n suficientemente avanzado,
1/2 (1 + 1/2 + 1/3 + … + 1/n)
es tan grande como se desee… Como el desierto, sea cual sea el que ha elegido Amelia, tiene dimensiones finitas, la exploradora puede recorrerlo por completo. Solo necesita suficiente tiempo –que no sobrepase su tiempo de vida–: Amelia completará su aventura. Aunque es probable que arruine a su mecenas y, sobre todo, que desperdicie un combustible precioso de manera un tanto caprichosa…
Más información:
-
Jeep problem, Wikipedia
-
Jeep problem, Wolfram Math World
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Amelia quiere explorar el desierto se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Mestizajes: ¿Cómo sabe una metáfora? Poética y ciencia, por Amelia Gamoneda
- ¿Quién quiere vivir para siempre?
- El diablo y Simon Flagg, una lectura ligera para el verano
Sistemas nerviosos: el cerebro de vertebrados

Áreas de Brodman en un cerebro de primate
El cerebro, que se desarrolla a partir del telencéfalo embrionario, es la estructura encefálica de vertebrados que ha alcanzado en mamíferos su máximo desarrollo. Contiene, a su vez, el bulbo olfatorio, los ganglios basales, el hipocampo y la corteza cerebral.
El prosencéfalo de todos los vertebrados posee una estructura en láminas denominada pallium. El pallium de agnatos (lampreas), peces condrictios (tiburones) y anfibios obedece a un esquema básico general, consistente en dos hemisferios unidos por una región denominada septum. Cada uno de los hemisferios asemeja un cilindro formado por tres capas, en cuyo interior quedan cavidades llenas de líquido denominadas ventrículos. La capa que da al ventrículo y la que da al exterior son de materia blanca, y la que queda entre ellas, de materia gris. En el resto de los grupos (peces teleósteos, reptiles, aves y mamíferos) se produce una fuerte modificación del esquema básico, debido al crecimiento diferencial de diferentes zonas del pallium original en cada uno de ellos. En mamíferos se diferencian cuatro zonas en el contorno de la forma cilíndrica antes mencionada, que se denominan pallium dorsal, medio, ventral y lateral, cuyo desarrollo daría lugar, respectivamente, al neocortex, el hipocampo, la amígdala y la corteza olfativa. El neocortex es la región que alcanza un mayor desarrollo de todas ellas.
El cerebro es un órgano con simetría bilateral y su desarrollo en mamíferos da forma a dos mitades o hemisferios cerebrales que, en los placentarios, se encuentran conectadas por el corpus callosum, una especie de “autopista de información” por la que se estima atraviesan unos 300 millones de axones neuronales. Cada hemisferio cerebral consiste en una fina capa de materia gris (corteza o córtex cerebral) que cubre una capa gruesa interna de materia blanca (médula cerebral). En el interior de la materia blanca se encuentra otra región de materia gris, los ganglios basales. La materia gris está formada por cuerpos neuronales empaquetados, sus dendritas y células gliales. La materia blanca está formada por ramos o fascículos de axones cubiertos de vainas de mielina. El color blanco se debe a la vaina de mielina, que está formada por lípidos.
Simplificando, se puede decir que la materia gris procesa la información, o sea, integra inputs de diferentes procedencias y elabora nuevas señales, mientras que la blanca la conduce, esto es, envía las señales a otros destinos. Las fibras de la materia blanca transmiten información de una zona a otra de la corteza o, también, a zonas que no se encuentran en ella. Es así como se produce la integración que permite el procesamiento de las señales que se reciben y la consiguiente elaboración de respuestas.
En los grupos de mamíferos en que alcanza su máximo desarrollo, la corteza cerebral presenta múltiples hendiduras o pliegues, lo que permite que aumente de forma considerable el número de neuronas que alberga. En lo que a su configuración tisular se refiere, es una estructura dispuesta en seis capas (procedentes del pallium dorsal), y se organiza en columnas verticales que se extienden perpendicularmente hasta la materia blanca, a dos milímetros de profundidad desde la superficie de la corteza. Se cree que cada una de esas columnas constituye un “equipo” formado por las neuronas contenidas en ella, cada una de las cuales desempeñaría una función en la tarea propia de la columna. Las diferencias funcionales entre unas y otras columnas tienen su reflejo en diferentes grosores de alguna de las seis capas.
Cada mitad de la corteza cerebral se divide en cuatro lóbulos: occipital, temporal, parietal y frontal, nombres que hacen referencia a los correspondientes huesos del cráneo. Los lóbulos occipitales, que se encuentran en la parte posterior, son los responsables del procesamiento inicial de las señales visuales. La información sonora se recibe, en primera instancia, en los lóbulos temporales, que tienen una disposición lateral a ambos lados de la cabeza. Los lóbulos parietales y frontales se encuentran en la parte superior del encéfalo y están separados por el denominado surco central del cerebro, un pliegue o invaginación profunda que discurre de arriba abajo hacia la mitad de la superficie lateral de cada hemisferio. Los lóbulos parietales quedan en la parte posterior, detrás del surco central, mientras los frontales quedan por delante. Los parietales reciben y procesan la información sensorial. Los frontales desempeñan varias tareas: (1) actividad motora de carácter voluntario; (2) producción vocal en los mamíferos que poseen esta capacidad; y (3) funciones superiores, como planificación y otras.
Si bien la descripción de la anatomía cortical por lóbulos resulta útil en una primera aproximación, suele recurrirse a las denominadas “áreas de Brodmann” para una caracterización más precisa. Un área de Brodmann es una región de la corteza del cerebro de primates definida por su estructura histológica, organización celular y citoarquitectura. Hay 52 áreas de Brodmann, aunque alguna está, a su vez, subdividida en dos áreas, y alguna de ellas sólo se halla presente en primates no humanos.
Fuentes:
Eric R. Kandel, James H. Schwartz, Thomas M. Jessell, Steven A. Siegelbaum & A. J. Hudspeth (2012): Principles of Neural Science, Mc Graw Hill, New York
Lauralee Sherwood, Hillar Klandorf & Paul H. Yancey (2005): Animal Physiology: from genes to organisms. Brooks/Cole, Belmont.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Sistemas nerviosos: el cerebro de vertebrados se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Sistemas nerviosos: el sistema central de vertebrados
- Sistemas nerviosos: el sistema periférico de vertebrados
- Sistemas nerviosos: el tálamo y el hipotálamo
Presión y volumen de un gas

Terminábamos la entrega anterior preguntándonos por qué las bombas de pistón manuales, también llamadas bombas de elevación o aspirantes, no pueden elevar el agua más de 10 metros y cuestionándonos por qué funcionaban. Estas preguntas se resolvieron a lo largo del siglo XVII gracias al trabajo experimental de varios investigadores, entre ellos, Torricelli (un alumno de Galileo), Guericke, Pascal, y Boyle.
Para 1660, estaba bastante claro que el funcionamiento de una bomba de aspirante depende de la presión del aire. Al eliminar un poco de aire por encima del agua por la acción de la bomba, simplemente se reduce la presión en la parte superior del agua que está dentro del tubo sumergido en el pozo. Como inicialmente la presión es la atmosférica, eso quiere decir que la acción de la bomba consigue que ahora haya una presión inferior a la atmosférica por encima de la columna de agua que está en el tubo. Es entonces la presión que ejerce la atmósfera en la masa de agua del pozo la que fuerza a que el agua suba por el tubo hasta que se igualan las presiones (la presión dentro del tubo es ahora la de la columna de agua que está por encima del nivel de la superficie del agua del pozo más lo que quede de presión atmosférica). Una buena bomba puede reducir la presión en la parte superior del tubo a casi cero. La presión atmosférica puede, por tanto, forzar el agua del tubo a elevarse considerablemente por encima del nivel del agua del pozo.
Pero ocurre que la presión atmosférica al nivel del mar no es lo suficientemente grande como para soportar una columna de agua de más de 10 m de altura. Como el mercurio es casi 14 veces más denso que el agua, la misma presión atmosférica solo podría soportar una columna 14 veces más pequeña, esto es, de aproximadamente 0.76 m (760 mm). Resulta que esta altura está muy bien para construir un instrumento con el que medir la presión atmosférica.

Por lo tanto, gran parte de la investigación del siglo XVII sobre la presión atmosférica se realizó con una columna de mercurio, un barómetro de mercurio. Torricelli diseñó el primero de estos barómetros. La altura de la columna de mercurio que puede ser soportada por la presión del aire no depende del diámetro del tubo, es decir, no depende de la cantidad total de mercurio, sino sólo de su altura. Esto puede parecer extraño al principio. Para entenderlo, debemos considerar la diferencia que existe entre presión y fuerza. La presión se define como la magnitud de la fuerza (F) que actúa perpendicularmente (esto lo indicamos con el símbolo ┴ como subíndice) sobre una superficie dividida por el área (A) de esa superficie, P = F┴ / A , y se mide, por tanto, en N/m2.

Por lo tanto, una fuerza grande puede producir una presión pequeña si se distribuye por un área muy grande. Por ejemplo, se puede caminar sobre la nieve sin hundirse en ella si se emplean raquetas de nieve Por otra parte, una pequeña fuerza puede producir una gran presión si se concentra en un área pequeña. El tacón de los zapatos de tacón de aguja puede producir una presión enorme, mayor que la hay debajo de la pata de un elefante; de hecho, pueden perforar suelos de madera y alfombras con mucha facilidad.
En definitiva, la medida de la presión no se ve afectada por el área de la sección transversal del tubo del barómetro ni por el peso (que es una fuerza) de la masa de mercurio en la columna, porque la presión es precisamente el cociente entre las dos. En una columna de mercurio que pese el doble que otra porque el tubo sea el doble habrá la misma presión porque el área será también el doble.
Este tipo de variables que no dependen de la masa se llaman intensivas. Existe otro tipo de variables, las llamadas extensivas que si dependen de la cantidad de materia, como el volumen. Pero sabemos que si aumentamos la presión, por ejemplo soplando más en un globo, el volumen puede aumentar. Es muy interesante esta relación de propiedades intensivas y extensivas.
En 1661, dos científicos ingleses, Richard Towneley y Henry Power, descubrieron una importante relación básica. Encontraron que en un globo de paredes delgadas, la presión ejercida por un gas es inversamente proporcional al volumen ocupado por ese gas. Duplicar la presión (al dejar entrar más gas) duplicará el volumen del globo. Usando P para la presión y V para el volumen, esta relación es P = a /V, donde a es una constante de proporcionalidad; también lo podemos escribir, P·V = a .

Si el volumen de una cantidad dada de aire en un globo es reducido a la mitad (por ejemplo, comprimiéndolo), la presión ejercida por el gas en el interior se duplica. Por otro lado, si se dobla el volumen del recipiente cerrado con una cierta cantidad de aire dentro, la presión interior se reduce a la mitad. Robert Boyle confirmó esta relación mediante multitud de experimentos. Es una regla empírica, ahora generalmente conocida como la ley de Boyle. Sin embargo, la ley se aplica exactamente sólo bajo condiciones especiales, como veremos.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Presión y volumen de un gas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:El encéfalo humano

El encéfalo de un ser humano adulto tiene una masa de entre 1,2 kg y 1,4 Kg, lo que representa alrededor de un 2% de la masa corporal total. Su volumen viene a ser de 1260 cm3 en los hombres y 1130 cm3 en las mujeres, aunque hay una gran variabilidad entre individuos. A pesar de representar un 2% de la masa corporal, consume alrededor de un 20% de la energía que gasta todo el organismo.
Ese gasto energético tan alto tiene su origen en la frenética actividad que desarrollan las aproximadamente noventa mil millones de neuronas que posee. Cada neurona mantiene con las vecinas del orden de cinco mil conexiones sinápticas. El número total de tales conexiones se encuentra, quizás, entre 2 x 1014 y 3 x 1014. Un encéfalo normal puede establecer y deshacer un millón de conexiones por segundo.
Hace uso de un conjunto de sensores capaces de recibir información en forma de variaciones de presión, radiaciones electromagnéticas y sustancias químicas. Los propios sensores convierten esa información en señales bioeléctricas que consisten en despolarizaciones transitorias, de magnitud constante, que se desplazan con frecuencias variables a lo largo de las membrana de las neuronas que conectan los sensores con el encéfalo. Éste, una vez recibidas, filtra y prioriza las señales en función del interés de la información que contienen o del peligro que indican. Y a partir de esa información y de la que posee almacenada en sus circuitos, reconstruye –o recrea- el entorno en el que se encuentra. Siempre que el cuerpo aguante, puede almacenar información durante un siglo, catalogándola automáticamente y editándola cuando se necesita. De hecho, modifica esa información cualitativa y cuantitativamente cada vez que accede a ella, y construye a partir de ella un “yo” cada vez que se hace consciente al despertar.
Gobierna un sistema de mensajería química de gran complejidad y coordina la actividad de al menos sesicientos músculos. Mediante esas herramientas se ocupa de organizar el procesamiento de energía, de gobernar las actividades conducentes a la reproducción del organismo en el que se encuentra y, por supuesto, de preservar su misma existencia, aunque a esta último fin dedica normalmente un esfuerzo mínimo.
El resto de su capacidad la dedica a relacionarse con otros encéfalos, valorar el sentido de la existencia y aprender de la experiencia y de semejantes a los que ni siquiera ha llegado a conocer.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo El encéfalo humano se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas: