

El sonido del viento
Cuando se habla de los orígenes del arte, o de “Arte Prehistórico”, la primera imagen que se nos viene a la cabeza se suele parecerse mucho a una pintura: las Cuevas de Altamira por ejemplo, de 18 mil años de antigüedad, ocupan un lugar privilegiado en el imaginario colectivo. En algunos casos, habrá también quienes piensen en esculturas paleolíticas, como la Venus de Willendorf de 28 mil años de antigüedad. Es mucho menos habitual pensar en otras formas artísticas y, sin embargo, se han encontrado flautas de hueso de hace 43 mil años que sitúan a la música en los orígenes mismos del pensamiento simbólico humano en Europa.

La cifra resulta apabullante y aún así se piensa que la primera música que hicieron los humanos debe de ser todavía más antigua. Lo más probable es que los primeros músicos no fuesen flautistas, sino cantantes. Para producir melodías, los humanos comenzamos por controlar nuestra voz y luego, probablemente, añadimos algo de percusión (como palmadas, o golpes contra cualquier objeto). Pero estas voces y estas palmadas, evidentemente, no se ha conservado, así que hoy la primera evidencia que tenemos de la música son huesos perforados: huesos de buitre o de oso que, con toda probabilidad funcionaron como flautas.
Esto nos da una pista de por qué son precisamente los instrumentos de viento los más antiguos conservados. Para empezar, pueden fabricarse usando materiales rígidos, no perecederos (al contrario que las cuerdas, por ejemplo, que suelen estar hechas con tripas o pelo de animal). Pero además, son muy fáciles de construir. Para fabricar un instrumento de viento sólo se necesita viento (claro) y un tubo. El viento lo llevamos todos de serie en los pulmones y para conseguir un tubo, basta con encontrar un hueso de animal o alguna caña hueca y rígida. En realidad, la única función de este tubo es la de “contener” el aire, dando cabida a ciertas longitudes de onda, su material y forma exacta son poco cruciales. Toda la magia de los instrumentos de viento tiene lugar más allá del tubo, en uno de sus extremos: el lugar donde el aire se “excita” y comienza a vibrar.
Existen distintas maneras de poner en marcha esta vibración y cada una de ellas da lugar a un timbre característico. Por eso, la forma en que se excita el aire es el verdadero criterio que distingue a las familias de instrumentos de viento. Es muy probable que todos hayáis oído hablar de instrumentos de viento madera y viento metal. La paradoja de estas etiquetas es que poco tienen que ver con el material de que están hechos los instrumentos. Las flautas traveseras de las orquestas contemporáneas, por ejemplo, suelen estar hechas de plata u oro incluso y, sin embargo, la flauta pertenece a la familia del viento madera. Por su parte, dentro del viento metal, encontramos instrumentos tan poco dúctiles o brillantes como las caracolas o las vuvuzelas.
 Steve Turre tocando un instrumento de viento metal… poco convencional.
Steve Turre tocando un instrumento de viento metal… poco convencional.Lo que caracteriza en realidad a los instrumentos de viento metal es que el sonido procede de la vibración de los labios del instrumentista. La presión procedente de la boca fuerza al aire a pasar por un mínimo hueco que se abre y cierra constantemente gracias a la elasticidad de los labios. Lo que viene siendo una pedorreta. O lo que sucede cuando dejamos escapar el aire de un globo mientras estiramos la goma junto a la salida: la membrana flexible lucha por recuperar su posición mientras el aire sale intermitentemente. Esa intermitencia puede ser más rápida o más lenta, según lo tensa que esté la goma. Por eso, cuanto más estiramos el globo, más agudo es el sonido resultante (mayor es la frecuencia de las oscilaciones de la presión). Del mismo modo: los trompetistas, trompistas y demás instrumentistas de viento metal, pueden modificar la tensión de sus labios para obtener distintas notas.
Dentro del viento madera, por su parte, encontramos distintas maneras de romper el aire. La flauta, por ejemplo, funciona mediante un bisel: una pieza rígida y afilada que fuerza al aire a desviarse en un sentido u otro, generando nuevamente una oscilación periódica de la presión más comúnmente conocida como sonido.

También son instrumentos de viento madera los que utilizan lengüetas para sonar. La lengüeta (o caña) es una pieza semirígida que interrumpe el paso del aire de manera intermitente gracias al principio de Bernoulli: cuando el aire fluye junto a ella, la presión disminuye y atrae a la lengüeta. Al ser esta flexible, se curva en la dirección del flujo e interrumpe su paso, la velocidad del aire disminuye y la presión vuelve a aumentar. Esto devuelve la lengüeta a su posición inicial y así el ciclo vuelve a empezar.
Existen distintos tipos de cañas y lengüetas, pero generalmente se clasifican como simples, dobles o libres, dependiendo de si se apoyan contra una superficie rígida, contra una segunda caña o si oscilan libremente obstruyendo por sí mismas el flujo del aire. Algunos instrumentos dentro de este grupo son el saxofón (lengüeta simple), la gaita (lengüeta doble) o la armónica (lengüeta libre). Los timbres, como puede verse, son enormemente diferentes pero si he de elegir uno, yo me quedo con la dulzura y la enorme versatilidad del clarinete.
Sobre la autora: Almudena M. Castro es pianista, licenciada en bellas artes, graduada en física y divulgadora científica
El artículo El sonido del viento se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La física del sonido orquestal
- Máquinas inteligentes (I): Del molino de viento al test de Turing
- En Marte el viento crea montañas
Kaisa-talo, geometría en la biblioteca
Esa fuerza interior se transmite de forma brillante hacia fuera en las dos fachadas, especialmente en la que da a la calle Kaisaniemenkatu. Una trama de pequeñas ventanas cuadradas dan una luz muy tamizada interrumpida por unos grandes ventanales de formas parabólicas por la que se introduce la luz hacia el espacio central.
Alberto Corral
La biblioteca de la Universidad de Helsinki es la biblioteca universitaria multidisciplinaria más grande de Finlandia. Funciona como un instituto independiente e incluye la Biblioteca Central –llamada Kaisa-talo, es decir, casa Kaisa en finés– y las bibliotecas de los campus de Kumpula, de Meilahti y de Viikki.
 Fachada principal (este) de Kaisa-talo. Fotografía: Inés Macho Stadler.
Fachada principal (este) de Kaisa-talo. Fotografía: Inés Macho Stadler.Kaisa-talo reúne las colecciones de libros y documentos de las facultades de arte, derecho, teología y ciencias sociales de la Universidad de Helsinki; está situada en el centro del campus. El solar que alberga esta biblioteca estaba antes ocupado por un centro comercial –construido en dos fases en 1973 y 1984 y posteriormente demolido– que era poco respetuoso con el paisaje urbano debido a su fachada de cemento. Los niveles subterráneos, antes ocupados por los aparcamientos, han sido conservados y forman parte de la biblioteca como zona de mantenimiento y almacenaje.
La firma de arquitectos Anttinen Oiva de Helsinki se presentó en 2007 a un concurso para diseñar el nuevo edificio que iba a alojar la biblioteca central de la universidad de esta ciudad, y lo ganó. En 2011 la propuesta de Anttinen Oiva comenzó a construirse como parte de La Capital de Diseño Mundial, un proyecto de promoción de ciudades patrocinado por el Consejo Internacional de Sociedades de Diseño Industrial (International Council of Societies of Industrial Design, World Design Organization) en el que la ciudad elegida – en el año 2012 fue Helsinki– tiene la oportunidad mostrar sus logros de innovación en diseño y sus estrategias urbanas. Kaisa-talo fue inaugurada el 3 de septiembre de 2012.
 Fachada oeste de Kaisa-talo. Fotografía: Inés Macho Stadler
Fachada oeste de Kaisa-talo. Fotografía: Inés Macho StadlerEl exterior del edificio es de ladrillo rojo –caracteriza el modernismo finlandés– y respeta la altura de los edificios colindantes, lo que le ayuda a integrarse en su entorno. Situado en una cuesta, Kaisa-talo tiene forma de L y siete pisos. Su entrada principal está en el lado este, dos pisos por encima de los accesos a las tiendas situadas en la fachada opuesta. La fachada este posee un arco catenario que ocupa cuatro pisos y otro similar invertido aparece en la fachada oeste. Las paredes exteriores albergan grandes ventanales curvos y también numerosas ventanas pequeñas y cuadradas que forman una retícula uniforme que contrasta con la zona curvilínea.
 Small Worlds (2012). Imagen: Wikimedia Commons.
Small Worlds (2012). Imagen: Wikimedia Commons.{kind=link}
Ya en el interior del edificio, en el hall de entrada se sitúa un mural de 18 metros, donado por el Consejo de Arte del Estado: Small Worlds realizado por las artistas Terhi Ekebom y Jenni Rope. Esos Pequeños mundos, algunos de ellos enlazados mediantes estrechos caminos, quizás aludan a los muchos espacios interconectados en la biblioteca.
Una impresionante escalera en forma de espiral comunica los pisos principales de la biblioteca, exceptuando el centro logístico y las instalaciones de mantenimiento bajo tierra a los que se accede fundamentalmente por ascensor.
 Escalera interior en forma de espiral. Fotografía: Inés Macho Stadler
Escalera interior en forma de espiral. Fotografía: Inés Macho StadlerEn la entrada principal, se observan dos grandes vacíos: unos en forma de elipse –que van disminuyendo su tamaño al subir de piso en piso– y otros en forma de parábola e hipérbola –que van aumentando a medida que se sube en el edificio–. Ambos proporcionan luz natural además de comunicar las diferentes alturas del edificio.
 Vacío interior en forma de elipse. Fotografía: Inés Macho Stadler
Vacío interior en forma de elipse. Fotografía: Inés Macho StadlerEn las referencias pueden verse numerosas fotografías en las que se aprecian los detalles descritos anteriormente. El siguiente video del arquitecto Alberto Corral realiza un buen recorrido por el interior del edificio.
Nota: Un especial agradecimiento a mi hermana Inés por hablarme de Kaisa-talo y cederme las fotografías utilizadas en esta anotación.
Referencias
-
Sinikara, K. & Lukkari, A-M., A case study on a post-occupancy evaluation of the new Helsinki University Main Library en Post-Occupancy Evaluation of Library Buildings, Latimer, K. & Sommer, D. (eds.). IFLA Publications Series 169 (2015) 175-191
-
Alberto Corral, Kaisa-talo, un edificio único en Helsinki, Blog, 23 febrero 2014
-
Mara Corradi, Anttinen Oiva y la Helsinki University Main Library (Kaisa house), Floornature, 29 julio 2015
-
Amy Frearson, Curving voids pierce the floors of Anttinen Oiva Architects’ Helsinki library, DeZeen, 13 noviembre 2014
-
Manuela Londoño Laserna y Juliana Marroquín DeCastro, Biblioteca Universidad de Helsinki. Sede Centro, Unidad taller de Cartagena, 2013
-
Imágenes para prensa, Universidad de Helsinki
-
Kaisa-talo, Wikipedia (consultado el 14 julio 2019)
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Kaisa-talo, geometría en la biblioteca se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La geometría de la obsesión
- El tamaño sí importa, que se lo pregunten a Colón (o de la geometría griega para medir el diámetro de la Tierra)
- Quad: pura geometría
El descubrimiento de los rayos X
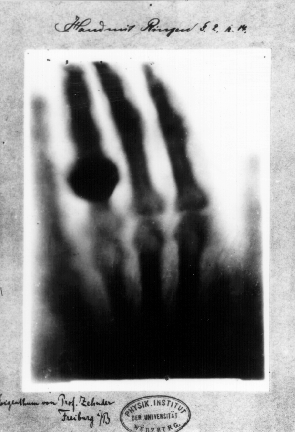
 Fuente: Wikimedia Commons.
Fuente: Wikimedia Commons.En 1895, Wilhelm Konrad Röntgen hizo un descubrimiento que lo sorprendió primero a él y luego a todo el mundo. Al igual que el efecto fotoeléctrico, no encajaba con las ideas aceptadas sobre las ondas electromagnéticas y, finalmente, también requirió la introducción de los cuantos para una explicación completa. Las consecuencias del descubrimiento de los rayos X para la física atómica, la medicina y la tecnología fueron enormes.
El 8 de noviembre de 1895, Rontgen estaba experimentando con los nuevos rayos catódicos, al igual que muchos físicos de todo el mundo. Según un biógrafo [*]:
. . . había cubierto el tubo de cristal en forma de pera [un tubo de Crookes] con trozos de cartón negro, y había oscurecido la habitación para probar la opacidad de la cubierta de papel negro. De repente, a aproximadamente un metro del tubo, vio una débil luz que brillaba en un pequeño banco que sabía que estaba cerca. Muy emocionado, Rontgen encendió una cerilla y, para su sorpresa, descubrió que la fuente de la misteriosa luz era una pequeña pantalla de platino-cianuro de bario depositada en el banco.
El platino-cianuro de bario, un mineral, es uno de los muchos productos químicos que se sabe que producen fluorescencia (emiten luz visible cuando se ilumina con luz ultravioleta). Pero no había ninguna fuente de luz ultravioleta en el experimento de Röntgen. Se sabía además que los rayos catódicos viajan solo unos pocos centímetros en el aire. Por lo tanto, ni la luz ultravioleta ni los propios rayos catódicos podrían haber causado la fluorescencia. Röntgen dedujo que la fluorescencia involucraba la presencia de rayos de un nuevo tipo. Los llamó rayos X, ya que los rayos eran de naturaleza desconocida.
En una intensa serie de experimentos sistemáticos durante las siguientes 7 semanas Röntgen determinó las propiedades de esta nueva radiación. Informó de sus resultados el 28 de diciembre de 1895 en un artículo cuyo título (traducido) es «Sobre un nuevo tipo de rayos». El artículo de Röntgen describía casi todas las propiedades de los rayos X que se conocen.
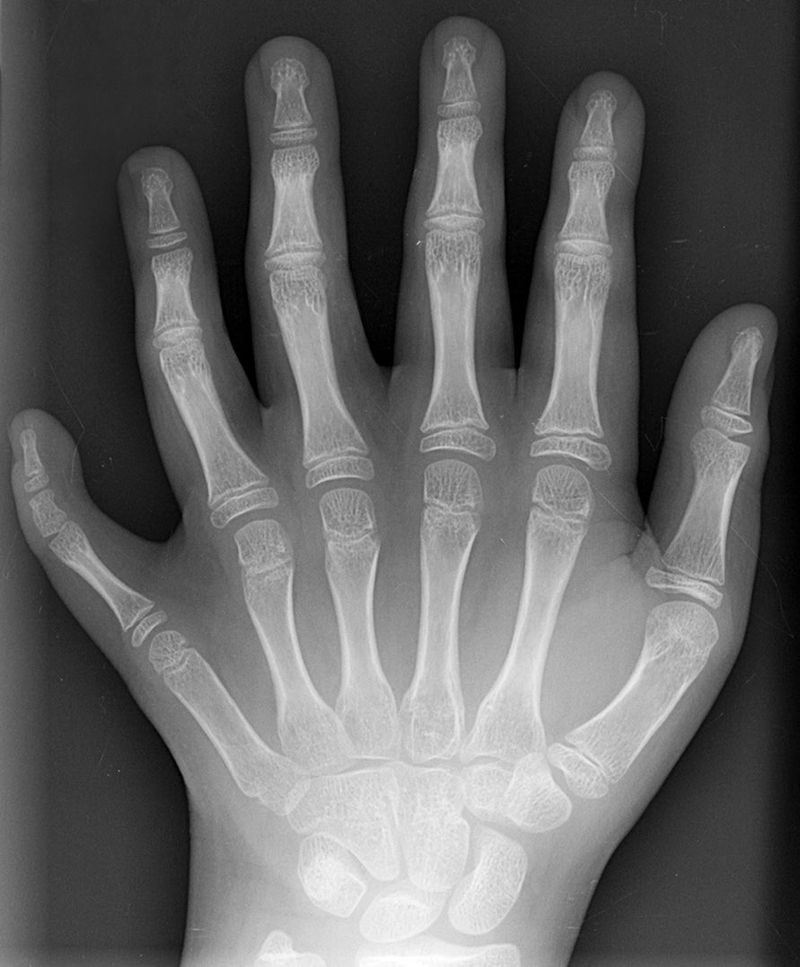
 Hand mit Ringen (mano con anillos). Impresión de la primera radiografía médica tomada por Wilhelm Röntgen usando rayos X. Corresponde a la mano de su mujer y fue tomada el 22 de diciembre de 1895. Röntgen se la regaló a Ludwig Zehnder del Physik Institut de la Freiburg Universität el 1 de enero de 1896.
Hand mit Ringen (mano con anillos). Impresión de la primera radiografía médica tomada por Wilhelm Röntgen usando rayos X. Corresponde a la mano de su mujer y fue tomada el 22 de diciembre de 1895. Röntgen se la regaló a Ludwig Zehnder del Physik Institut de la Freiburg Universität el 1 de enero de 1896.Röntgen describió el método para producir los rayos y probó que se originan en la pared de vidrio del tubo, donde los rayos catódicos lo golpean. Demostró que los rayos X viajan en línea recta desde su lugar de origen y que oscurecen una placa fotográfica. Informó detalladamente de la capacidad variable de los rayos X para penetrar en diversas sustancias como el papel, la madera, el aluminio, el platino y el plomo. Su poder de penetración era mayor en los materiales “ligeros” (papel, madera, carne) que en los materiales “densos” (platino, plomo, hueso). Describió y exhibió fotografías que mostraban «las sombras de los huesos de la mano, de un conjunto de pesas dentro de una pequeña caja, y de un pedazo de metal cuya inhomogeneidad se hace evidente con los rayos X.» Dio una descripción clara de las sombras proyectadas por los huesos de la mano sobre la pantalla fluorescente. Röntgen también informó que los rayos X no se desviaban por la presencia de un campo magnético. Tampoco constató reflexión, refracción o interferencia usando aparatos ópticos ordinarios.
 Experimentando con rayos X. Fuente: William J. Morton & Edwin W. Hammer (1896) «The X-ray, or Photography of the Invisible and its value in Surgery», American Technical Book Co., New York, fig. 54 / Wikimedia Commons
Experimentando con rayos X. Fuente: William J. Morton & Edwin W. Hammer (1896) «The X-ray, or Photography of the Invisible and its value in Surgery», American Technical Book Co., New York, fig. 54 / Wikimedia CommonsJ.J. Thomson descubrió una de las propiedades más importantes de los rayos X uno o dos meses después de que los rayos se diesen a conocer. Encontró que cuando los rayos pasan a través de un gas, lo convierten en un conductor de electricidad. Thomson atribuyó este efecto a «una especie de electrólisis, la molécula se divide o casi se divide por los rayos de Röntgen». Hoy sabemos que los rayos X, al pasar a través del gas, liberan electrones de algunos de los átomos o moléculas del gas. Los átomos o moléculas que pierden estos electrones se cargan positivamente. Siguiendo con el símil electrolítico a estas moléculas cargadas se las llamó iones porque se parecen a los iones positivos de la electrólisis, y de ahí que se diga que el gas está “ionizado”. Además, los electrones liberados pueden unirse a átomos o moléculas previamente neutros, cargándolos negativamente.
Röntgen y Thomson descubrieron, independientemente que los cuerpos electrificados pierden sus cargas cuando el aire a su alrededor se ionizado por los rayos X. (Ahora es fácil ver por qué: el cuerpo electrificado atrae iones de la carga opuesta presentes en el aire ionizado). La velocidad de descarga depende de la intensidad de los rayos (ya que de ella depende la cantidad de ionización). Por lo tanto, esta propiedad se usó, y se sigue usando, como un medio cuantitativo conveniente para medir la intensidad de un haz de rayos X. Este descubrimiento implicaba, pues, que se podían realizar mediciones cuantitativas cuidadosas de las propiedades y efectos de los rayos X.
Nota:
* Hay varias versiones del descubrimiento. Incluso existe una de consenso que no es más válida que la que ofrecemos. Lo cierto es que la única persona presente era Röntgen, él no lo contó a nadie que tomase notas de ello de forma fidedigna y fiable y dejó dicho que sus notas de laboratorio, que podrían haber arrojado algo de luz [nótese el ingeniosísimo juego de palabras], se destruyesen a su muerte. La cuestión es que los elementos fundamentales de todas las narraciones (tubo de Crookes, cartón negro y pantalla de platino-cianuro de bario) están presentes.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo El descubrimiento de los rayos X se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La luz se propaga en línea recta pero los rayos de luz no existen
- Rayos X y gamma
- El tubo de rayos catódicos, auge y caída de una pieza clave del siglo XX
La certeza de la incertidumbre en los informes del IPCC
El año 2018 fue el más caluroso de la historia moderna de la Tierra. Batió el récord de temperatura media global desbancando al año 2017, el cual había superado la espectacular marca del año 2016. El listón de temperaturas elevadas en nuestro planeta está llegando a límites, paradójicamente, escalofriantes. Los que seguimos – con preocupación – la evolución del clima global hemos observado cómo la Organización Meteorológica Mundial (OMM) ha ido informando que durante los últimos 22 años se han batido 20 récords de temperatura media. Y que esta tendencia va en aumento: la Tierra acumula 400 meses seguidos de temperaturas superiores a la media histórica, sumando más de 33 años consecutivos por encima de la referencia del siglo XX.
El cambio climático puede considerarse una certeza y ello supone una verdadera amenaza para el mundo que conocemos. Una amenaza que, además, todo indica que ha sido generada principalmente por la actividad industrial humana. El informe especial “Global Warming of 1,5 ºC” del IPCC, publicado a finales de 2018, no da lugar a dudas: estima que esta actividad ha aumentado la temperatura del planeta en aproximadamente 1ºC con respecto a los niveles preindustriales. En unos pocos decenios, la concentración de CO2 en la atmósfera ha aumentado más del 30%, superando los 400 ppm y batiendo el récord datado hace 3 millones de años. No se trata de una evolución natural del clima: la evidencia es abrumadora y el consenso de la comunidad científica es prácticamente unánime.
Sin embargo, así como el cambio climático pasado es avalado por el histórico de datos recogidos a lo largo del último siglo, para conocer el futuro de este no hay observación posible. Si queremos estimar los posibles escenarios a los que se enfrenta nuestro planeta, dependemos casi exclusivamente de modelos de simulación compleja, los cuales están compuestos por un conjunto de submodelos en continuo desarrollo por centros como la NASA, la UK Met Office, o el Beijing Climate Center.
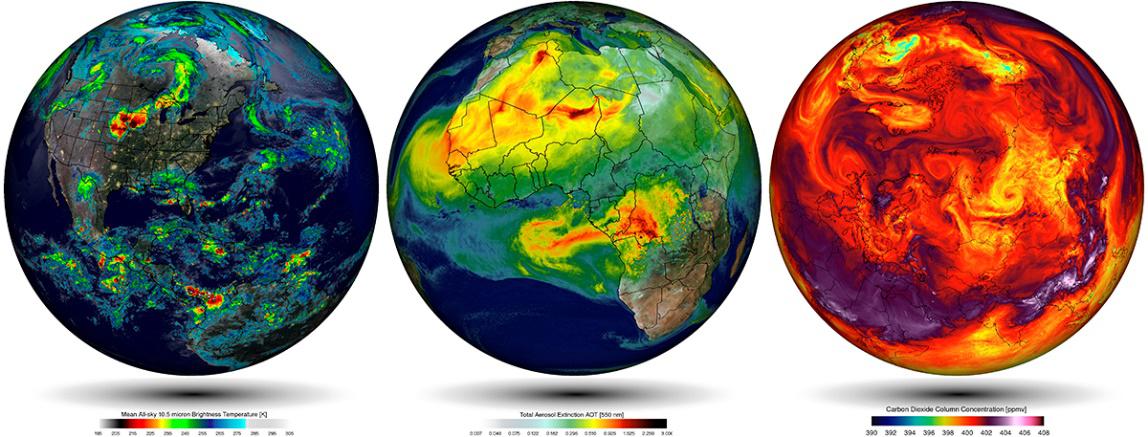 Simulaciones empleando el modelo climático del Goddard Earth Observing System (GEOS-5) de la NASA. Fuente: William Putman, NASA/Goddard
Simulaciones empleando el modelo climático del Goddard Earth Observing System (GEOS-5) de la NASA. Fuente: William Putman, NASA/GoddardEstas simulaciones se rigen por un corpus teórico introducido previamente. Por ejemplo, en el caso de las simulaciones atmosféricas este corpus es construido con (i) las leyes de movimiento de Newton aplicadas en elementos finitos de fluidos, (ii) la ley de la conservación de la masa, y (iii) ecuaciones termodinámicas que permiten calcular el efecto calorífico en cada parcela de aire a través de valores parametrizados de la radiación solar. Estas tres componentes se traducen en ecuaciones diferenciales parciales no-lineales de solución analítica irresoluble, por lo que se aplican métodos numéricos que discretizan las ecuaciones continuas y permiten determinar una aproximación a la solución de estas a través técnicas de modelización y simulación computacional.
En conjunto con otros submodelos, como la simulación del ciclo del carbono o el movimiento tectónico, estas simulaciones se utilizan para construir posibles escenarios futuros, que son una herramienta utilizada para la toma de decisiones en política de mitigación o de adaptación medioambiental, ya sea en forma de monetización del carbón o de aplicación de estrategias de geoingeniería, por ejemplo. Sin embargo, a pesar de que los mecanismos que gobiernan el cambio climático antropogénico son bien entendidos, estas proyecciones presentan incertidumbre en la precisión de sus resultados. Su cuantificación es, precisamente, la principal herramienta para comunicar el (des)conocimiento de expertos a políticos.
La literatura especializada establece hasta siete fuentes de inseguridad epistémica que determinan el grado de incertidumbre: (a) la estructura de los modelos que sólo permiten describir un subconjunto de componentes e interacciones existentes, (b) aproximaciones numéricas, (c) resolución limitada que implica que los procesos de microescala tengan que ser parametrizados y, por tanto, tengan que describir su efecto − sin resolver realmente el proceso− en términos de cuantificaciones disponibles a gran escala, (d) variabilidad natural interna, (e) observación de datos, (f) condiciones iniciales y de contorno, y (g) escenario económico futuro. Todas estas fuentes de incertidumbre se derivan de la existencia de diferentes representaciones del clima para cada uno de los distintos modelos.
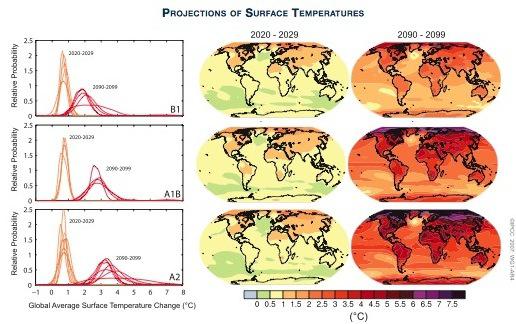 Fuente: Policymaker Summary of The Phisical Science Basis (4th IPCC Report)
Fuente: Policymaker Summary of The Phisical Science Basis (4th IPCC Report)
La primera impresión que genera esta incertidumbre en el público general es que el cambio climático es una hipótesis, de algún modo, incierta. Sin embargo, los modelos de incertidumbre presentados en los sucesivos informes del Grupo I del IPCC no se presentan para dilucidar si el cambio climático es incierto o no, sino para informar de la calidad de los modelos obtenidos y trasladar la toma de decisiones políticas fuera del proceso de obtención de resultados por parte de decenas de miles de científicos.
Parece claro que el futuro no podemos conocerlo a ciencia cierta y, como diría Zygmunt Bauman, la única certeza que tenemos es la incertidumbre. Ello no impide, sin embargo, que podamos estimar de forma más o menos robusta el futuro plausible que nos espera. Por ello, acompañar los resultados de las simulaciones con modelos probabilísticos de incertidumbre no es una muestra de debilidad, sino un instrumento que permite comunicar esas estimaciones de manera transparente, sin comprometer la investigación científica con cuestiones políticas, sociales o éticas. Se trata de una actividad que los científicos y el IPCC consideran como un ejemplo de rigor, a pesar de que haya mercaderes de la duda que la exploten como una debilidad. Y es que la certeza de la incertidumbre en los informes del IPCC consiste, paradójicamente, en que es la única forma disponible para hacer que las proyecciones del clima que nos espera sean lo más certeras posible.
Para saber más:
Winsberg, Eric (2018), Philosophy and Climate Science, New York: Cambridge University Press.
Sobre el autor: José Luis Granados Mateo es investigador predoctoral en Historia y Filosofía de la Ciencia en UPV/EHU.
El artículo La certeza de la incertidumbre en los informes del IPCC se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El clima, los informes y la política
- Migraciones…¿vegetales?
- ¿Una charla? ¿de ciencia?, prefiero el bar…
La enfermedad del hígado graso no alcohólico, una gran desconocida
Jenifer Trepiana, Saioa Gómez-Zorita, María P. Portillo, Maitane González-Arceo
La enfermedad del hígado graso no alcohólico (EHGNA) consiste en una acumulación excesiva de grasa en las células del hígado o hepatocitos (más del 5% del peso del hígado sería grasa) sin un consumo excesivo de alcohol, siendo en la actualidad la causa más frecuente de enfermedad hepática (Ahmed, 2015). Puede presentarse como esteatosis (acumulación de grasa) simple o como esteatohepatitis, situación de mayor gravedad que comporta ya inflamación y un inicio de fibrosis.
La prevalencia de la esteatosis simple oscila entre un 14% y un 30% en la sociedad occidental, aunque es probable que sea mayor ya que como muchos pacientes son asintomáticos, en ocasiones no son diagnosticados (Abd El-Kader SM y El-Den Ashmawy EM, 2015).
¿Cómo se desarrolla la EHGNA?
El hígado graso no alcohólico comprende numerosas lesiones hepáticas, comenzando con la esteatosis simple, que supone el 80-90% de los casos. Hay que destacar que el hígado graso no alcohólico se desarrolla de una manera progresiva y lenta, siendo la esteatosis simple reversible, y pudiendo dejar de progresar. Sin embargo, en el 10-20% de los pacientes avanza hasta la siguiente etapa llamada esteatohepatitis o inflamación del hígado. De la misma manera, la esteatohepatitis puede no seguir progresando o, por el contrario, puede evolucionar mediante la aparición de fibrosis a su etapa final, llamada cirrosis, con riesgo de desarrollar carcinoma de hígado en el peor de los casos (Hashimoto et al., 2013).
Lo que ocurre en la esteatosis simple, es que la excesiva acumulación de lípidos en el hígado lo hace vulnerable a otras agresiones como el estrés oxidativo, provocado por un desequilibrio entre los radicales libres y la disponibilidad de antioxidantes, además de promover la liberación de moléculas que producen inflamación provocando esteatohepatitis. En la esteatohepatitis, aparece inflamación y daño en las células de manera crónica que puede cursar con fibrosis (formación excesiva de un tejido llamado tejido conectivo para intentar reparar la víscera). Según estudios científicos, un 41% de los pacientes que sufren la EHGNA desarrollan fibrosis (Ekstedt et al., 2006). Por otra parte, el riesgo de padecer hepatocarcinoma en los pacientes con EHGNA que no sufren cirrosis es mínimo (de 0-3% en 20 años), mientras que en pacientes con cirrosis el riesgo asciende a 12,8% en 3 años (White et al., 2012).
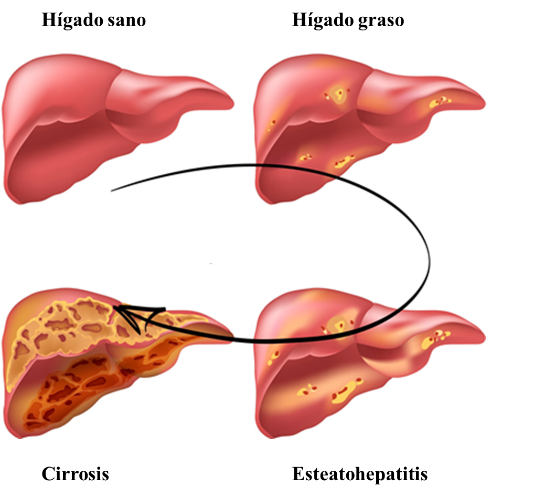 Figura 1. Esquema de los estadios de la enfermedad del hígado graso. Modificado de: Non Alcoholic Fatty Liver Disease NAFLD. Preventicum (2016).
Figura 1. Esquema de los estadios de la enfermedad del hígado graso. Modificado de: Non Alcoholic Fatty Liver Disease NAFLD. Preventicum (2016).Al analizar la morfología del hígado de pacientes que sufren EHGNA tras una biopsia, se observa una acumulación de grasa en las células del hígado (hepatocitos) en forma de triglicéridos. Se ha aceptado que el criterio mínimo para diagnosticar la EHGNA mediante el estudio con microscopía de este órgano, es que el hígado contenga una cantidad mayor al 5% de hepatocitos esteatóticos (Neuschwander-Tetri y Caldwell, 2003), es decir que más de un 5% de las células del hígado contengan una gran cantidad de grasa en su interior. Así, mediante estas técnicas de imagen, se puede clasificar la EHGNA en diferentes tipos, desde una esteatosis simple, hasta esteatohepatitis con o sin fibrosis.
Centrándonos más en lo que le ocurre al hepatocito, podemos decir que normalmente, la esteatosis en el hígado graso no alcohólico, es de tipo macrovesicular. Esto es, que el hepatocito contiene una única gota grande de grasa, o varias gotas de grasa algo más pequeñas, lo que provoca el desplazamiento del núcleo de la célula a la periferia (extremos) del hepatocito. Sin embargo, en la esteatosis de tipo microvesicular, el núcleo se mantiene en el centro del hepatocito con diminutas gotículas de grasa presentes en la célula (Brunt y Tiniakos, 2010). Este último tipo, no suele ser la forma más típica de esteatosis, encontrándose sobre todo en los hepatocitos más pequeños o en los que no se encuentran en las zonas donde la esteatosis es más prominente. Cuando se da esta situación, el paciente suele tener peor pronóstico. En alguna ocasión, también puede ocurrir que se produzca una esteatosis mixta, donde se encuentran hepatocitos con una esteatosis macrovesicular, a la vez que encontramos grupos de hepatocitos con esteatosis microvesicular.
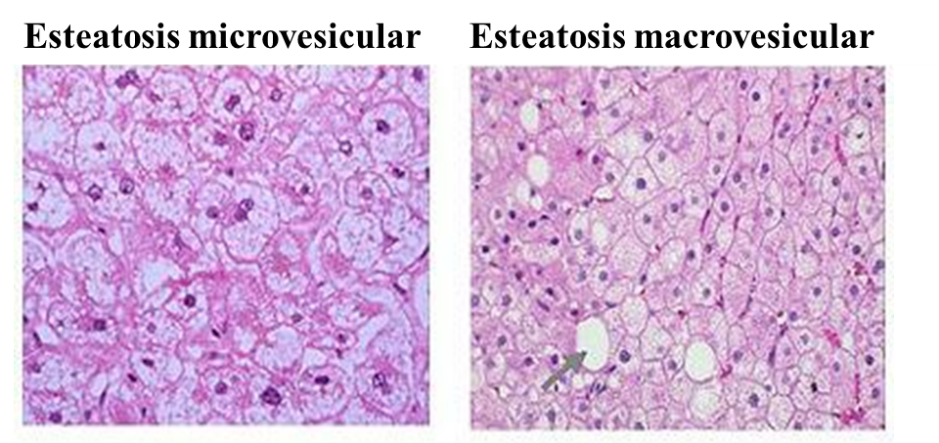 Figura 2. Esteatosis microvesicular y macrovesicular. Análisis mediante técnicas de imagen. Mofrad P, Sanyal, A. Nonalcoholic Fatty Liver Disease. Medscape (2003).
Figura 2. Esteatosis microvesicular y macrovesicular. Análisis mediante técnicas de imagen. Mofrad P, Sanyal, A. Nonalcoholic Fatty Liver Disease. Medscape (2003).
¿Qué factores influyen en el desarrollo de esta enfermedad?
El origen de la EHGNA no está claro, aunque probablemente sea la resistencia a la insulina la causa principal. Otros factores de riesgo asociados con el hígado graso son el sobrepeso y la obesidad, la dislipemia (altos niveles de colesterol y/o triglicéridos en sangre), y la diabetes mellitus tipo 2. Hay que tener en cuenta que la EHGNA afecta a todos los segmentos de la población, no solo a los adultos, y también a la mayoría de los grupos raciales. Se estima que entre el 74% y el 80% de los individuos obesos presentan hígado graso. Además de la obesidad, la presencia de diabetes mellitus tipo 2 incrementa no solo el riesgo, sino también la severidad de la EHGNA (Angulo, 2002). Esto quiere decir, que la diabetes mellitus tipo 2 constituye un perfil metabólicamente desfavorable para los pacientes que presentan EHGNA, aumentando el riesgo de sufrir enfermedades cardiovasculares.
¿Cómo se detecta la EHGNA?
Como hemos indicado al inicio, con mucha frecuencia, la EHGNA cursa de manera asintomática, y cuando produce síntomas estos son bastante inespecíficos. Por ello, muchas veces pasa desapercibida, tanto para los médicos como para los pacientes. El síntoma más frecuente es dolor en la zona abdominal derecha y fatiga.
Para la detección de la EHGNA, primeramente se suelen valorar las transaminasas hepáticas (AST, aspartatoaminotransferasa y ALT, alaninaaminotransferasa), que se suelen encontrar aumentadas. No obstante, aunque los niveles de transaminasas son lo primero que se analiza mediante una extracción de sangre del paciente, no son consideradas buenos marcadores ya que en algunos individuos con esteatosis los niveles de transaminasas en sangre no están elevados, incluso en algunos pacientes con cirrosis tampoco lo están. Además, solo pueden indicar daño hepático en general, no siempre teniendo que ir asociado a la EHGNA. Por otro lado, la AST aparece en otros tejidos como el corazón o el músculo esquelético, por lo que en caso de que se eleve, también puede deberse a una alteración en otros órganos o tejidos. También se recurre a técnicas de imagen para ayudar en el diagnóstico de la enfermedad o para la detección de hepatomegalia (hígado más grande de lo normal), como son la ecografía, TAC (Tomografía Axial Computarizada) o RMN (Resonancia Magnética), siendo esta última la más eficaz en su diagnóstico. Estas pruebas de imagen son útiles para saber si hay infiltración de grasa en el hígado, pero presentan la limitación de que no muestran si el hígado presenta inflamación o fibrosis.
Por ello, el mejor método de diagnóstico es la biopsia, que además permite conocer el grado de EHGNA del paciente. No obstante, dado que se trata de una técnica invasiva, únicamente se suele realizar en aquellos pacientes que muestran signos de estar en un estadio avanzado de enfermedad hepática (por ejemplo, cirrosis) o en aquellos pacientes que presentan mayor probabilidad de esteatohepatitis. Una limitación de esta técnica es que las lesiones hepáticas sufridas no son uniformes en todo el hígado, lo que dificulta el análisis de las biopsias. Es decir, según de qué zona del hígado se tome la muestra, el diagnóstico puede variar.
Ante la necesidad de detectar la EHGNA sin tener que recurrir a la biopsia hepática, se está profundizando en el estudio de biomarcadores para analizar la función hepática de una manera no agresiva para el organismo. Entre ellos encontramos marcadores específicos para la fibrosis, como la medición de concentraciones de proteínas implicadas en la fibrolisis o rotura del tejido fibrótico (colagenasas, α2-macoglobulina, MMPs, C3M) o de proteínas que participan en la fibrogénesis o generación del tejido fibrótico (colágeno tipo IV, pro-C3/C5). En la práctica clínica se suelen utilizar diversos test como el SteatoTest que calcula el grado de esteatosis hepática en pacientes con riesgo metabólico elevado, el FibroTest que valora los niveles de fibrosis y cirrosis, así como el grado de inflamación del hígado, y el NashTest que predice la presencia o ausencia de esteatohepatitis. Los marcadores que se analizan mediante estos tests son la α2-macroglobulina, haptoglobina, apolipoproteína A1, bilirrubina total, ALT, GGT, glucosa en ayunas, triglicéridos, y colesterol. Estos parámetros se ajustan a la edad, sexo, peso y tamaño del paciente. Estos índices y biomarcadores pueden ser útiles no solo para el diagnóstico de la enfermedad, sino también para estudiar la evolución de esta y los efectos del tratamiento.
¿Qué se puede hacer para prevenir la EHGNA?
Es importante remarcar que para la prevención de la EHGNA la principal medida es evitar los factores de riesgo asociados a la enfermedad (obesidad, dislipemia, resistencia a la insulina). Para ello son esenciales una rutina de ejercicio físico en nuestro día a día y llevar una dieta equilibrada.
Tratamientos en la actualidad
Actualmente, no existe un tratamiento específico para la EHGNA. Por ello, lo que se suele hacer es tratar los factores causales, es decir, la obesidad, y otros componentes del síndrome metabólico, como son la hipertensión (mediante el tratamiento farmacológico con estatinas), la diabetes mellitus y la dislipemia. Al igual que en el caso de la prevención, una dieta equilibrada y la actividad física serán los pilares básicos para tratar el hígado graso no alcohólico.
Además, se ha comprobado que seguir un patrón de alimentación mediterráneo se asocia con una menor probabilidad de presentar esteatosis y esteatohepatitis (Aller et al., 2015).
Recomendaciones en el estilo de vida
-
Pérdida de peso: 3-5% en la esteatosis simple y 7-10% en la esteatohepatitis (Jeznach-Steinhagen et al., 2019).
-
Reducción del consumo de hidratos de carbono simples (
-
Reducción de la grasa saturada de la dieta. Una dieta rica en grasas saturadas, intensifica el estrés oxidativo en el organismo, aumentando la inflamación en la zona afectada por la esteatosis. Sin embargo, el consumo de ácidos grasos poliinsaturados del grupo n-3 (omega 3) mejora la esteatosis hepática (Dasarathy et al., 2015).
-
Aumento del consumo de antioxidantes, presentes en altas cantidades en frutas y verduras.
-
Evitar la cantidad de alcohol ingerida. Dado que un abuso del alcohol provoca un desarrollo rápido de la enfermedad, se recomienda la abstinencia del alcohol.
Tratamientos farmacológicos
Como se ha mencionado anteriormente, algunos tratamientos farmacológicos están dirigidos a reducir las enfermedades asociadas al hígado graso, como son la diabetes, obesidad, y desordenes lipídicos.
-
Suplementación con vitaminas, especialmente aquellas que son antioxidantes como la vitamina E (precaución con las dosis elevadas ya que pueden tener efectos secundarios graves). Debido a la dosis empleada la vitamina E o α-tocoferol se incluye dentro de los tratamientos farmacológicos para tratar esta enfermedad.
-
Fármacos antidiabéticos: pioglitazone, rosiglitazona, liraglutide, metformina, etc. (al igual que en el caso anterior pueden tener efectos secundarios).
En la actualidad están siendo probados en diversos ensayos clínicos fármacos novedosos como el agonista del receptor Farnesoil X, o el agonista de PPARα y PPARδ (estudios en fase 2).
Referencias bibliográficas
Ahmed M. Non-alcoholic fatty liver disease in 2015. World J Hepatol. 18;7(11):1450-9 (2015).
Abd El-Kader SM, El-Den Ashmawy EM. Non-alcoholic fatty liver disease: The diagnosis and management. World J Hepatol. 28;7 (6):846-58 (2015).
Hashimoto E, Taniai M, Tokushige K. Characteristics and diagnosis of NAFLD/NASH. J Gastroenterol Hepatol. 28 Suppl 4:64-70 (2013).
Non Alcoholic Fatty Liver Disease NAFLD. Preventicum (2016).
Ekstedt M, Franzén LE, Mathiesen UL, Thorelius L, Holmqvist M, Bodemar G, Kechagias S. Long-term follow-up of patients with NAFLD and elevated liver enzymes. Hepatology. 44(4):865-73 (2006).
White DL, Kanwal F, El-Serag HB. Association between nonalcoholic fatty liver disease and risk for hepatocellular cancer, based on systematic review. Clin Gastroenterol Hepatol. 10(12):1342-1359 (2012).
Neuschwander-Tetri BA, Caldwell SH. Nonalcoholic steatohepatitis: summary of an AASLD Single Topic Conference. Hepatology. 37(5):1202-19 (2003).
Brunt EM, Tiniakos, DG. Histopathology of nonalcoholic fatty liver disease. World J Gastroenterol. 14;16(42):5286-96 (2010).
Mofrad P, Sanyal, A. Nonalcoholic Fatty Liver Disease. Medscape (2003).
Angulo P. Nonalcoholic fatty liver disease. New Engl. J. Med. 346:1221-1231 (2002).
Aller R, Izaola O, Luis DD. La dieta mediterránea se asocia con la histología hepática en pacientes con enfermedad del hígado graso no alcohólico. Nutrición Hospitalaria, 32: 2518-2524 (2015).
Jeznach-Steinhagen A, Ostrowska J, Czerwonogrodzka-Senczyna A, Boniecka I, Shahnazaryan U, Kuryłowicz A. Dietary and Pharmacological Treatment of Nonalcoholic Fatty Liver Disease. Medicina 55, 166 (2019).
Mager D, Iñiguez I, Gilmour S, Yap J, The effect of a low fructose and low glycemic index/load (FRAGILE) dietary intervention on indices of liver function, cardiometabolic risk factors, and body composition in children and adolescents with nonalcoholic fatty liver disease (NAFLD). J. Parenter. Enteral. Nutr. 39, 73–84 (2015).
Dasarathy S, Dasarathy J, Khiyami A, Yerian L, Hawkins C, Sargent R, McCullough A.J. Double-blind randomized placebo-controlled clinical trial of omega 3 fatty acids for the treatment of diabetic patients with nonalcoholic steatohepatitis. J. Clin. Gastroenterol. 49, 137–144 (2015).
Sobre las autoras:
Jenifer Trepiana1, Saioa Gómez-Zorita1,2, María P. Portillo1,2, Maitane González-Arceo1
1 Grupo de Nutrición y Obesidad. Departamento de Farmacia y Ciencias de los Alimentos. Facultad de Farmacia. Universidad del País Vasco (UPV/EHU)
2 Centro de Investigación Biomédica en Red de la Fisiopatología de la Obesidad y Nutrición (CiberObn)
El artículo La enfermedad del hígado graso no alcohólico, una gran desconocida se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Avances contra la enfermedad de hígado graso no alcohólica
- Una ecuación para determinar la grasa en el hígado a partir de una resonancia
- Consolider-Gran Telescopio Canarias: Cómo comunicar Astrofísica
El problema de Josefo o cómo las matemáticas pueden salvarte la vida

Imagina que sois 41 soldados, que estáis rodeados y que todo el mundo menos el jefe quiere suicidarse antes que rendirse. En esta tesitura se encontraba Josefo cuando se le ocurrió una forma matemática de salvar su vida. La Ikerbasque Research Fellow Luz Roncal, del BCAM, te lo explica usando magia.
Quizás sea el número más famoso de la historia. Lo cierto es que el número Pi, representado por la letra griega π, es una de las constantes matemáticas más importantes que existen en el mundo, estudiada por el ser humano desde hace más de 4.000 años. La fascinación que ha suscitado durante siglos es tal que el popular número cuenta con su propio día en el calendario, así el mes de marzo se celebra el Día de Pi en todo el planeta.
Este evento internacional vino de la mano del físico estadounidense Larry Shaw, quien lanzó en 1988 la propuesta de celebrar esta efeméride. La forma en la que se escribe el 14 de marzo en inglés y euskera coincide con los tres primeros dígitos de la famosa constante matemática. (3-14 martxoaren 14 en euskara / 3-14 march, 14th en inglés) y además, la celebración coincide con la fecha del nacimiento de Albert Einstein. En 2009, el congreso de EEUU declaró oficialmente el 14 de marzo como el Día Nacional de Pi.
Actualmente, el Día de Pi es una celebración mundialmente conocida que sobrepasa el ámbito de las matemáticas. Este número irracional, que determina la relación entre la longitud de una circunferencia y su diámetro, concierne a múltiples disciplinas científicas como la física, la ingeniería y la geología, y tiene aplicaciones prácticas sorprendentes en nuestro día a día.
Este 2019 nos unimos de nuevo al festejo con el evento BCAM–NAUKAS, que se desarrolló a lo largo del 13 de marzo en el Bizkaia Aretoa de UPV/EHU. BCAM-NAUKAS contó durante la mañana con talleres matemáticos para estudiantes de primaria y secundaria y durante la tarde con una serie de conferencias cortas dirigidas al público en general.
Este evento es una iniciativa del Basque Center for Applied Mathematics -BCAM, enmarcada en la celebración de su décimo aniversario, y de la Cátedra de Cultura Científica de la Universidad el País Vasco.
Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo El problema de Josefo o cómo las matemáticas pueden salvarte la vida se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Dinosaurios
La Facultad de Ciencias de Bilbao comenzó su andadura en el curso 1968/69. 50 años después la Facultad de Ciencia y Tecnología de la UPV/EHU celebra dicho acontecimiento dando a conocer el impacto que la Facultad ha tenido en nuestra sociedad. Publicamos en el Cuaderno de Cultura Científica y en Zientzia Kaiera una serie de artículos que narran algunas de las contribuciones más significativas realizadas a lo largo de estas cinco décadas.

 Imagen: Pixabay
Imagen: PixabayLos dinosaurios son un grupo natural de organismos ( o clado), lo que significa que todos ellos comparten un antecesor común. Poseen un conjunto de caracteres anatómicos que permite reconocerlos y diferenciarlos de otros grupos de vertebrados. Por ejemplo, los dinosaurios se caracterizan por presentar un acetábulo perforado, es decir, una cavidad en la pelvis donde se articula la cabeza del fémur (hueso del muslo).
A diferencia de los reptiles actuales, como cocodrilos y lagartos, los dinosaurios no reptaban. Sus miembros estaban dispuestos en posición vertical, de manera similar a los mamíferos. Esto les confería una locomoción más eficaz. Además, poseían un metabolismo elevado y eran animales adaptados a un modo de vida activo.
Gracias a los fósiles conservados en las rocas sabemos que los primeros dinosaurios aparecieron hace unos 230 millones de años, durante el Triásico. A inicios del Jurásico, los dinosaurios pasaron a ser los reptiles dominantes sobre la tierra firme. Se diversificaron durante el Jurásico y el Cretácico [Triásico, Jurásico y Cretácico son las tres divisiones o periodos geológicos que componen la Era Secundaria o Mesozoico]. A finales del Cretácico, hace 66 millones de años, los dinosaurios se extinguieron, junto con otros organismos tanto terrestres como marinos, durante una de las mayores crisis biológicas que ha sufrido la vida en la Tierra. Solo las aves sobrevivieron a la extinción en masa de finales del Cretácico.
Tyrannosaurus, Triceratops, Stegosaurus y Diplodocus son algunos de los dinosaurios más conocidos. Todos ellos eran terrestres. Ningún dinosaurio vivió en el mar. Sólo las aves, que son dinosaurios muy especializados, han adquirido la capacidad de volar. Los dinosaurios desarrollaron una sorprendente diversidad de tamaños, así como una gran disparidad morfológica. Los dinosaurios terrestres más pequeños eran del tamaño de una paloma, mientras que algunos de los saurópodos más grandes medían 30 metros de longitud y se estima que su masa corporal superaba las 50 toneladas, lo que los convierte en los mayores animales que han existido sobre la tierra firme. Había dinosaurios carnívoros, vegetarianos, omnívoros, e incluso insectívoros. Muchos de ellos eran bípedos, otros cuadrúpedos, y algunos podían incluso adoptar ambos tipos de locomoción.
Sin contar las aves, se han descrito más de mil especies de dinosaurios en el registro fósil (conjunto de evidencias conservadas en las rocas) del Mesozoico. Gracias a la labor que realizan los paleontólogos (trabajos de campo, laboratorio y gabinete), cada año se describen de 30 a 40 especies nuevas. Es probable que aún no conozcamos ni la mitad de las especies de dinosaurios que realmente existieron.
Desde que se definieron los primeros dinosaurios hace casi dos siglos hasta la actualidad, su imagen científica ha ido evolucionando con el tiempo. En un principio fueron considerados lagartos gigantescos, más tarde reptiles cuadrúpedos similares a grandes mamíferos, y a finales del siglo XIX se los imaginaba como reptiles-canguros saltadores. Este cambio conceptual en el conocimiento científico sobre los dinosaurios ha tenido reflejo en la iconografía paleontología, así como en la literatura y el cine. Durante mucho tiempo se pensó que eran animales lentos, torpes y estúpidos condenados a extinguirse. El renovado interés por los dinosaurios (“Dinosaur Rennaissance” en inglés), que se inició a finales de la década de 1960 y continúa en nuestros días, se ha materializado en profundos cambios en las ideas sobre su biología, léase anatomía, metabolismo, comportamiento, relaciones de parentesco y pseudoextinción a finales del Cretácico.
Jurassic Park, saga cinematográfica iniciada en 1993, supone el punto álgido de lo que se ha dado en llamar “dinomanía” o pasión popular por los dinosaurios. La película aumentó el interés por los dinosaurios y su investigación científica, despertando muchas vocaciones paleontológicas entre los niños que la vieron, por lo que cabe hablar de una generación “Parque Jurásico”. Hoy en día, la paleontología de los dinosaurios es una disciplina en pleno desarrollo, con muchos especialistas trabajando en el tema, y donde se aplican nuevas tecnologías (por ejemplo, escaneado y modelización en tres dimensiones) que permiten abordar aspectos novedosos de la biología de los dinosaurios. Cabe destacar el carácter multidisciplinar de la investigación actual y la presencia cada vez mayor de mujeres paleontólogas, particularmente en áreas que están experimentando un rápido crecimiento, como la paleohistología (estudio de la microestructura ósea de los organismos del pasado) o la paleontología molecular (estudio de restos orgánicos fósiles). Los resultados de la investigación paleontológica sobre los dinosaurios están a la orden del día. Los debates científicos sobre su origen, su apariencia, el color de su piel o sus plumas, su termofisiología, la causa o causas de su extinción (con excepción de las aves), el origen del vuelo, etc., son temas fascinantes que interesan al público y tienen amplio eco en los medios de comunicación.
Los dinosaurios no solo tuvieron un tremendo éxito evolutivo durante el Jurásico y el Cretácico, sino que algunas formas adaptadas al vuelo como las aves son, con algo más de 10.000 especies, el grupo más diversificado de tetrápodos en la naturaleza actual.
 Reconstrucción de un paisaje de finales del Cretácico con la fauna de dinosaurios de Laño (Condado de Treviño). En primer plano, el anquilosaurio enano Struthiosaurus. Detrás, una pareja de Lirainosaurus, titanosaurio definido a partir de los fósiles hallados en este yacimiento. Al fondo, un terópodo persigue a dos ornitópodos. Esta asociación es típica de los yacimientos de dinosaurios del sur de Europa de hace unos 70 millones de años. Ilustración original del paleoartista Raúl Martín coloreada por Gonzalo De las Heras (Diario El Correo), usada con permiso.
Reconstrucción de un paisaje de finales del Cretácico con la fauna de dinosaurios de Laño (Condado de Treviño). En primer plano, el anquilosaurio enano Struthiosaurus. Detrás, una pareja de Lirainosaurus, titanosaurio definido a partir de los fósiles hallados en este yacimiento. Al fondo, un terópodo persigue a dos ornitópodos. Esta asociación es típica de los yacimientos de dinosaurios del sur de Europa de hace unos 70 millones de años. Ilustración original del paleoartista Raúl Martín coloreada por Gonzalo De las Heras (Diario El Correo), usada con permiso.Por último, solemos pensar que el descubrimiento de dinosaurios solo se da en tierras exóticas, cuando en nuestro entorno cercano hay yacimientos paleontológicos de gran relevancia, como es el caso de la cantera de Laño (Condado de Treviño). Este yacimiento es una ventana abierta al mundo de finales del Cretácico, cuando Europa era un archipiélago formado por islas de diferentes tamaños separadas por mares cálidos poco profundos. En Laño se han hallado fósiles pertenecientes a una decena de especies de dinosaurios (incluyendo un nuevo titanosaurio: Lirainosaurus astibiae), junto con otros vertebrados continentales, como peces óseos, anfibios, lagartos, serpientes, tortugas, cocodrilos, pterosaurios y mamíferos. El estudio del yacimiento ofrece información de primera mano sobre cómo eran las faunas de dinosaurios y otros vertebrados continentales hace aproximadamente 70 millones de años.
Para saber más:
S.L. Brusatte, “Dinosaur Paleobiology”, Wiley-Blackwell (2012).
X. Pereda Suberbiola (2018) “Dinosaurios y otros vertebrados continentales del Cretácico final de la Región Vasco-Cantábrica: cambios faunísticos previos a la extinción finicretácica”, en A. Badiola, A, Gómez-Olivencia & X. Pereda Suberbiola, “Registro fósil de los Pirineos occidentales. Bienes de interés paleontológico y geológico. Proyección social”, Servicio Central de Publicaciones del Gobierno Vasco, Vitoria-Gasteiz, pp. 83-98.
Sobre el autor: Xabier Pereda Suberbiola es Doctor en Ciencias Geológicas e investigador del Departamento de Estratigrafía y Paleontología de la Facultad de Ciencia y Tecnología de la UPV/EHU.
El artículo Dinosaurios se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Dinosaurios quijotescos o con nombre de princesa
- Las plumas estaban en los dinosaurios desde el principio
- ¿Se podrían recuperar los dinosaurios como en Parque Jurásico?
Ha llegado el final de la cosmética «sin»
 Foto: Pixabay
Foto: PixabayDesde el 1 de julio de 2019 ha entrado en vigor una nueva normativa en cosmética que se ha propuesto acabar con la desafortunada estrategia del «sin».
Hay consumidores que no saben qué son los parabenos, pero no los quieren. Desconocen la historia que ha llevado a algunos laboratorios cosméticos a utilizar como reclamo el ‘sin parabenos’, y la consecuencia de esto es que estas sustancias cuyo uso está permitido y es seguro, se perciben como sustancias perjudiciales para la salud. Esto ocurre también con las sales de aluminio de los desodorantes, los sulfatos o con los conservantes, entre otros.
La estrategia publicitaria del «sin» se fundamenta en el miedo. Es lo que los científicos hemos convenido en denominar ‘quimiofobia’, miedo a la química. Funciona porque se sirve de grandes males de la sociedad: la desinformación y la incultura.
La libertad de elegir solo nos la garantiza el conocimiento. Pero cuando el conocimiento requerido es suficientemente profundo, y el caso que nos ocupa lo es, la mejor forma de afrontarlo es tomando medidas que faciliten las elecciones. O al menos, que garanticen que estas elecciones se basan en criterios acertados.
Esa es la razón por la que se ha decidido regular las reivindicaciones de los productos cosméticos. Una historia de reglamentos, informes y documentos técnicos que comenzó en 2009 y que ha llegado hasta nuestros días.
- La historia de cómo se regulan las reivindicaciones de los productos cosméticos
En 2009 se publicó el Reglamento (CE) No 1223/2009. En el artículo 20 sobre «reivindicaciones de producto» es donde por primera vez figuran dos puntos referidos en exclusiva a este asunto:
En el primer punto se dice que en el etiquetado, en la comercialización y en la publicidad de los productos cosméticos no se utilizarán textos, denominaciones, marcas, imágenes o cualquier otro símbolo figurativo o no, con el fin de atribuir a estos productos características o funciones de las que carecen.
En el segundo punto se dice que la Comisión adoptará una lista de criterios comunes para las reivindicaciones que podrán utilizarse en los productos cosméticos. Como muy tarde, el 11 de julio de 2016 la Comisión presentaría al Parlamento Europeo y al Consejo un informe sobre el uso de las reivindicaciones con arreglo a los criterios comunes adoptados. En función de ese informe se crearía un grupo de trabajo para afrontar los problemas observados. Y ese fue el plan que seguimos.
En 2013 se publicó el Reglamento (UE) No 655/2013. Este reglamento tenía como objetivo desarrollar el artículo 20 del R 1223/2009. Aquí se estableció un marco legal con unos criterios comunes basados en la honradez, veracidad e imparcialidad, entre otros.
Finalmente en 2016 se publicó el Informe de la Comisión al Parlamento Europeo y al Consejo sobre las reivindicaciones relativas a los productos basadas en criterios comunes en el ámbito de los cosméticos. El resultado de este informe fue que el 10% de las reivindicaciones sobre productos cosméticos analizadas no se consideraron conformes con los criterios comunes establecidos en el R 655/2013.
Como consecuencia de esto, en 2017 el grupo de trabajo presentó un Documento técnico sobre reivindicaciones de productos cosméticos que incluye 4 anexos. El anexo III se refiere exclusivamente a los cosméticos «sin».
La aplicación de estos criterios sobre los cosméticos «sin» entró en vigor el 1 de julio de 2019. A partir de ese momento está prohibido introducir en el mercado nuevos productos y lotes antiguos que no cumplan con los criterios actuales. Aun así, los lotes de producto que ya estuviesen en el mercado antes del 1 de julio, no serán retirados. Por este motivo, durante un tiempo podremos encontrar productos comercializados que no cumplan la nueva norma. Serán de lotes distribuidos antes del 1 de julio.
 Foto: Pixabay
Foto: Pixabay-
Cuáles son los nuevos criterios sobre las reivindicaciones de cosméticos «sin»
Las reivindicaciones «sin» o reivindicaciones con significado similar no deberán de efectuarse en ingredientes cuyo uso está prohibido en productos cosméticos por el R 1223/2009. Por ejemplo, la reivindicación ‘sin corticosteroides’ no debe de estar permitida ya que la legislación de productos cosméticos de la UE prohíbe los corticosteroides.
En caso de reivindicaciones sobre la ausencia de grupos de ingredientes con funciones definidas en el R 1223/2009, como conservantes y colorantes, el producto no debe de contener ningún ingrediente que pertenezca a ese grupo. Si se sostiene como reivindicación que el producto no contiene un ingrediente específico, el ingrediente no debe de estar presente ni liberarse. Por ejemplo, la reivindicación ‘sin formaldehído’ no debe de estar permitida si el producto contiene un ingrediente que libera formaldehído, como por ejemplo la diazolidinil urea.
Las reivindicaciones «sin» no deberán de permitirse cuando se refieran a un ingrediente que no suele usarse en el tipo concreto de producto cosmético. Por ejemplo, ciertas fragancias suelen contener una cantidad de alcohol tan elevada que no es necesario usar conservantes adicionales. En este caso, sería deshonesto resaltar en publicidad el hecho de que cierta fragancia no contiene conservantes.
Las reivindicaciones «sin» tampoco deben de permitirse cuando impliquen propiedades garantizadas del producto, en función de la ausencia de ingredientes, que no pueden darse. Por ejemplo, no está permitida la reivindicación ‘sin sustancias alergénicas/sensibilizadoras’ porque no puede garantizarse la ausencia completa del riesgo de una reacción alérgica y el producto no debe de dar la impresión de que sí.
Las reivindicaciones «sin» dirigidas a grupos de ingredientes no deben de permitirse si el producto contiene ingredientes con funciones múltiples y entre ellas está la función mencionada en la reivindicación «sin». Por ejemplo, no puede usarse la reivindicación ‘sin perfume’ cuando un producto contenga un ingrediente que ejerza función aromatizante en el producto, sin importar sus otras posibles funciones en el producto.
Otro ejemplo de este punto es la reivindicación ‘sin conservantes’. Esta no debe de usarse cuando un producto contenga ingredientes con efecto protector frente a microorganismos, aunque estos no estén incluidos en el anexo V de la lista de conservantes del Reglamento 1223/2009. Este es el caso del alcohol, que puede tener actividad conservante aunque no esté contemplado como tal en la lista del anexo V. Así que, si el alcohol es el que actúa como conservante, está prohibida la reivindicación ‘sin conservantes’.
Con respecto al ‘sin conservantes’ hay alguna excepción demostrable. Si hay pruebas de que el ingrediente concreto o la combinación de dichos ingredientes no contribuye a la protección del producto, podría ser adecuado usar la reivindicación, como por ejemplo, resultados de un challenge test de la fórmula sin el ingrediente concreto.
Las reivindicaciones «sin» no deberán de permitirse cuando impliquen un mensaje denigrante, sobre todo cuando se basan principalmente en una presunta percepción negativa sobre la seguridad del ingrediente o grupo de ingredientes. Por ejemplo, el uso de parabenos es seguro y está permitido. Si se considera el hecho de que todos los productos cosméticos deben de ser seguros, la reivindicación ‘sin parabenos’ no debe de aceptarse, ya que es denigrante para el grupo total de parabenos. Otro ejemplo similar es el del fenoxietanol y el triclosán. Ambos son seguros y su uso está permitido. Por ello, la reivindicación ‘sin’ en dichas sustancias no debe de aceptarse ya que denigra sustancias autorizadas.
Las reivindicaciones «sin» solo deben de estar permitidas cuando facilitan una elección informada para un grupo específico de usuarios. Por ejemplo, está permitido el ‘sin alcohol’ en un enjuague bucal diseñado como producto para la familia. También puede usarse el ‘sin ingredientes de origen animal’ para productos diseñados para veganos. O ‘sin acetona’, por ejemplo en esmalte de uñas, para usuarios que quieren evitar este olor concreto porque les resulta molesto.
-
Conclusión
A partir del 1 de julio de 2019, que es cuando entró en vigor la aplicación de estos nuevos criterios, estará prohibido distribuir los clásicos cosméticos «sin», como el ‘sin parabenos’, el ‘sin sulfatos’, el ‘sin sales de aluminio’ o el ‘sin conservantes’. Ya no se podrá denigrar ingredientes de curso legal, insinuar que son perjudiciales o que hay productos inseguros en el mercado. Es cuestión de semanas que todos estos productos desaparezcan. Que por fin los lineales estén ocupados por productos que se vendan por lo que tienen, no por lo que no tienen.
Si esto pone fin a esa clase de publicidad, a algunos se les acabará el negocio. Quien no tiene nada mejor que vender, venderá miedo. A los que no necesitaban de esa publicidad, ha llegado el momento de vender virtudes.
Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo Ha llegado el final de la cosmética «sin» se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Los parabenos usados en cosmética son seguros
- Los cosméticos no se testan en animales
- Estimada OCU: recuerda que NO se pueden utilizar las cremas solares del año pasado
Los ritmos primos de Anthony Hill
El pasado mes de mayo, aprovechando la exposición de la artista Esther Ferrer en Tabakalera (Donostia), Esther Ferrer, 2, 3, 5, 7, 11, 13, 17, 19, 23…, dedicamos dos entradas del Cuaderno de Cultura Científica a su serie de obras Poema de los números primos, en la cual utiliza los números primos como herramienta en el proceso de creación artística:
i) Poema de los números primos
ii) Poema de los números primos (2)
En la entrada de hoy vamos a hablar de otro artista que también ha utilizado los números primos en la creación de una de sus obras de arte, es el artista británico Anthony Hill.
 Relief construction (1960-62), de Anthony Hill, obra realizada en aluminio y plástico sobre un tablero de madera, de dimensiones 110 x 91 x 5 cm. Obra e imagen de la Tate Gallery
Relief construction (1960-62), de Anthony Hill, obra realizada en aluminio y plástico sobre un tablero de madera, de dimensiones 110 x 91 x 5 cm. Obra e imagen de la Tate Gallery
Anthony Hill nació en Londres en 1930, formó parte del movimiento artístico de los constructivistas británicos y estuvo relacionado con el Grupo Sistemas. Heredero del arte concreto, Anthony Hill utiliza las matemáticas en el proceso creativo artístico. Tiene un profundo conocimiento de esta ciencia, publicando incluso algunos artículos de investigación matemática, como el artículo On the number of crossings in a complete graph (Proceedings of the Edinburgh Mathematical Society 13, n. 4, p. 333-338, 1963), junto al matemático Frank Harary, o siendo elegido Honorary Research Fellow en el Departamento de Matemáticas del University College de Londres.
La obra que vamos a analizar en esta entrada es Prime Rhythms / Ritmos primos (1959 -1962).
 Rhythms / Ritmos primos (1959 -1962), de Anthony Hill, realizada en plástico laminado y de unas dimensiones de 91.5 x 91.5 x 1.9 cm. Imagen del artículo del artista A View of Non-Figurative Art and Mathematics and an Analysis of a Structural Relief
Rhythms / Ritmos primos (1959 -1962), de Anthony Hill, realizada en plástico laminado y de unas dimensiones de 91.5 x 91.5 x 1.9 cm. Imagen del artículo del artista A View of Non-Figurative Art and Mathematics and an Analysis of a Structural ReliefEsta obra está inspirada en los números primos y, más concretamente, en los números primos gemelos. Recordemos que los números primos son aquellos números que solamente se pueden dividir por 1 y por ellos mismos. Así, por ejemplo, el número 30 no es un número primo ya que se puede dividir por 2, 3, 5, 6, 10 y 15, además de por 1 y 30, o tampoco el 33, divisible por 3 y 11, mientras que el número 13 sí es primo, ya que solamente es divisible por el 1 y él mismo, al igual que los números 2, 3, 5, 7, 11, 17 o 19. Por motivos formales el número 1 es considerado no primo en matemáticas, aunque en esta obra Anthony Hill lo va a incluir el en grupo de los números primos.
Lo primero que hace el artista británico es considerar todos los números impares menores que 100 (tengamos en cuenta que los números pares, con la excepción del 2, son siempre compuestos, es decir, no primos) y dividir este grupo en dos subgrupos, los primos y los compuestos. Resulta que hay exactamente la misma cantidad de elementos en cada subgrupo, en concreto, veinticinco.
Números primos impares menores que 100:
1, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97.
Números compuestos impares menores que 100:
9, 15, 21, 25, 27, 33, 35, 39, 45, 49, 51, 55, 57, 63, 65, 69, 75, 77, 81, 85, 87, 91, 93, 95.
A continuación, Anthony Hill toma un cuadrado, considera la línea intermedia y marca 50 líneas horizontales, igualmente espaciadas, de forma que cada una de ellas es un número impar menor que 100, desde el 1 hasta el 99. Aunque cada línea es un número impar, los números impares primos los considera a la izquierda y los números impares no primos a la derecha, como se muestra en la siguiente imagen esquemática de los primeros números.
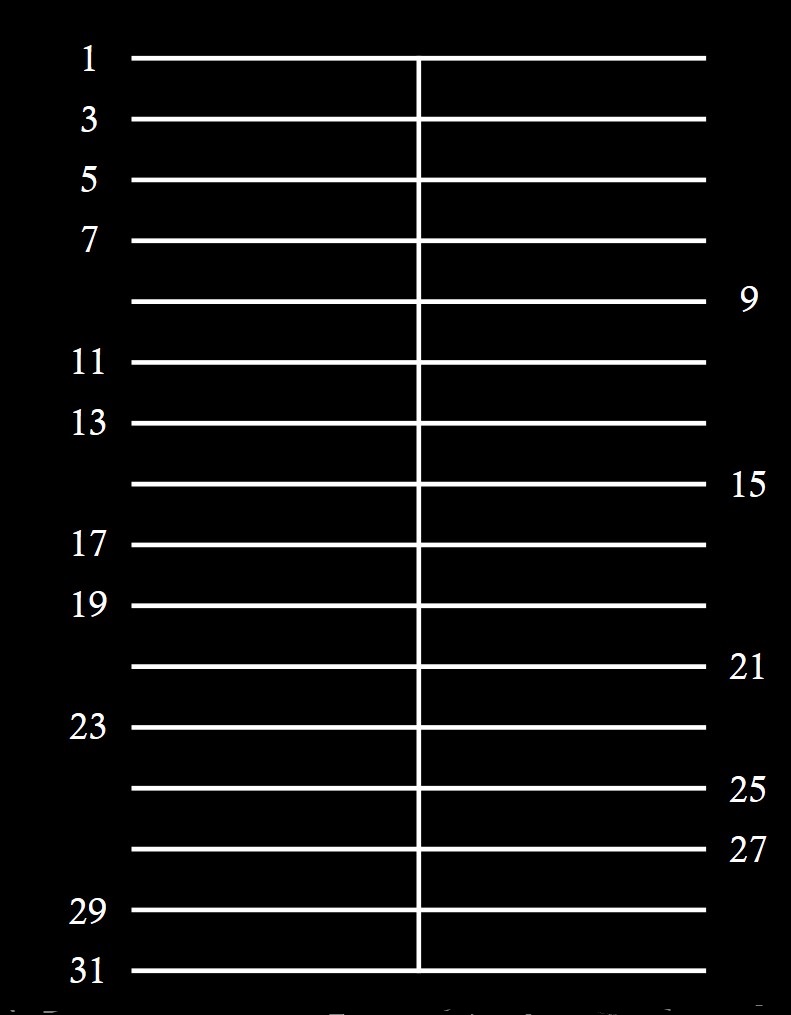
El siguiente paso fue considerar los números primos gemelos, que son aquellos números primos que están lo más cerca posible (con la excepción del 2 y el 3), es decir, con tan solo un número par entre ellos, como las parejas 11 y 13, 17 y 19, 41 y 43, 59 y 61, 71 y 73. Anthony Hill considera los números primos (impares) gemelos, que además son menores de 100, como se ve en la siguiente imagen, en la parte de la izquierda. Observemos que, al considerar solo números impares, los números primos gemelos son números consecutivos, 1 y 3, 3 y 5, 5 y 7, 11 y 13, 17 y 19, y 29 y 31, en la siguiente imagen.
Por otra parte, Anthony Hill considera los números no primos impares consecutivos, que podríamos denominar ahora “números compuestos impares gemelos”. Como por ejemplo el par 25 y 27, que se puede ver en la parte de la derecha de la imagen, aunque hay más, como 33 y 35.

La siguiente acción es pintar de negro las zonas, o bandas entre líneas paralelas, que se corresponden a números gemelos, para los números primos, a la izquierda, y para los números impares no primos, a la derecha, y las demás bandas de color blanco. Podemos apreciar la construcción en la siguiente imagen.

Por lo tanto, sin marcar la separación entre las zonas que hemos realizado en el anterior esquema explicativo, podemos realizar la siguiente recreación de la obra Prime Rhythms / Ritmos primos de Anthony Hill.
 Recreación de la obra Prime Rhythms / Ritmos primos (1959 – 1962), de Anthony Hill, realizada por mí mismo, Raúl Ibáñez
Recreación de la obra Prime Rhythms / Ritmos primos (1959 – 1962), de Anthony Hill, realizada por mí mismo, Raúl IbáñezTerminamos la entrada mostrando una obra de Anthony Hill relacionada con los grafos, The Nine – Hommage à Khlebnikov / El nueve, homenaje a Khlebnikov (1976).
 The Nine – Hommage à Khlebnikov / El nueve, homenaje a Khlebnikov (1976), de Anthony Hill, realizada en plástico laminado, con un tamaño de 91.5 x 91.5 x 1.9 cm. Imagen del artículo del artista A View of Non-Figurative Art and Mathematics and an Analysis of a Structural Relief
The Nine – Hommage à Khlebnikov / El nueve, homenaje a Khlebnikov (1976), de Anthony Hill, realizada en plástico laminado, con un tamaño de 91.5 x 91.5 x 1.9 cm. Imagen del artículo del artista A View of Non-Figurative Art and Mathematics and an Analysis of a Structural ReliefBibliografía
1.- Anthony Hill, A View of Non-Figurative Art and Mathematics and an Analysis of a Structural Relief, Leonardo, Vol. 10, No. 1, pp. 7-12, 1977.
2.- Alan Fowler, A Rational Aesthetic. The Systems group and associated artists, Southampton City Art Gallery, 2008.
3.- Michael Holt, Mathematics in Art, Littlehampton Book Services, 1971.
4.- Raúl Ibáñez, Las Matemáticas como herramienta en la creación artística (conferencia), Curso de verano de la UPV/EHU, “Cultura con M de matemáticas, una visión matemática del arte y la cultura”, 2019.
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo Los ritmos primos de Anthony Hill se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Buscando lagunas de números no primos
- Criptografía con matrices, el cifrado de Hill
- El poema de los números primos (2)
El dilema del efecto fotoeléctrico
 ¿Clásica o moderna? He ahí la cuestión. Imagen: Wikimedia Commons
¿Clásica o moderna? He ahí la cuestión. Imagen: Wikimedia CommonsHemos visto que la explicación de Einstein del efecto fotoeléctrico cuadra muy bien con las observaciones experimentales. Pero cuadra muy bien cualitativamente, es decir, explica lo que ocurre de forma genérica. Otra cosa muy distinta es que el modelo fotónico de Einstein explique cuantitativamente la observaciones. Solo entonces cabe hablar de un modelo realmente bueno.
Era necesario pues comprobar experimental y cuantitativamente el modelo de Einstein, en concreto dos afirmaciones claves:
a) La energía cinética máxima de los electrones es directamente proporcional a la frecuencia de la luz incidente; y
b) El factor de proporcionalidad h que relaciona la energía del fotón E con la frecuencia f (E = hf )es realmente el mismo para todas las sustancias.
 Millikan y Einstein en 1932. Fuente: Wikimedia Commons
Millikan y Einstein en 1932. Fuente: Wikimedia CommonsDurante 10 años, los físicos experimentales intentaron realizar las pruebas cuantitativas necesarias. Una dificultad experimental era que el valor de la función de trabajo W para un metal cambia mucho si hay impurezas (por ejemplo, una capa de óxido del metal) en la superficie. Finalmente, en 1916, Robert A. Millikan estableció que existe una relación en forma de línea recta entre la frecuencia de la luz absorbida y la energía cinética máxima de los fotoelectrones, como lo exige la ecuación de Einstein.
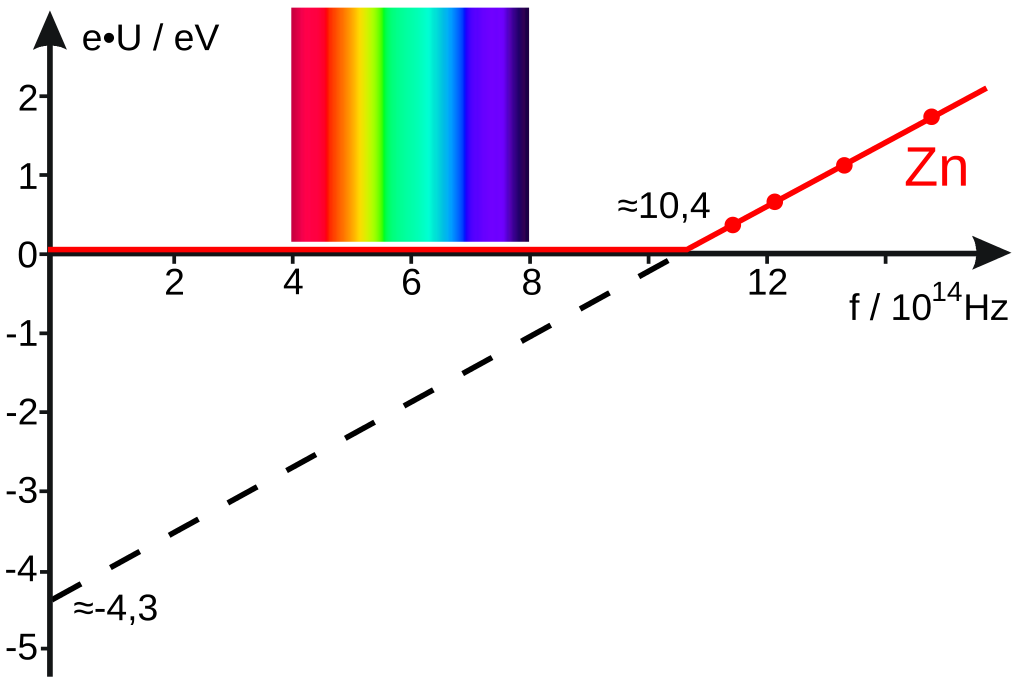
Si Ecmax se representa en el eje y y f a lo largo del eje x, entonces la ecuación de Einstein (Ecmax = hf – W) tiene la forma familiar de la ecuación para una línea recta y = mx + b. En una gráfica de la ecuación de Einstein, la pendiente debe ser igual a h, y la intersección con el eje y (f = 0) debe ser igual a -W. Esto es exactamente lo que encontró Millikan. Vemos en la imagen los datos para el zinc. La imagen es de Wikimedia Commons.
Para obtener sus datos, Millikan diseñó un aparato en el que la superficie fotoeléctrica del metal se obtenía por un corte en vacío. Un electroimán situado fuera de la cámara de vacío manipulaba una cuchilla dentro de la cámara para realizar los cortes. Este dispositivo, bastante complejo, era imprescindible para garantizar que se obtenía una superficie reproducible de metal puro.
Las líneas rectas que obtuvo Millikan para diferentes metales tenían la misma pendiente, h, aunque las frecuencias umbral (relacionadas con W) fuesen diferentes.
El valor de h obtenido a partir de los experimentos de Millikan eran, como hemos dicho, igual para distintos metales. De hecho también era el mismo encontrado por otros experimentos independientes. Este resultado sorprendió antes que ha nadie al propio Millikan, firme partidario de la teoría clásica de la luz. Su experimento demostró convincentemente que el modelo fotónico de la luz era correcto hasta donde se podía comprobar. El efecto fotoeléctrico dio como fruto dos premios Nobel, uno para Einstein por la teoría y otro para Millikan, por el experimento.
 Albert Einstein recibe la Medalla Max Planck de manos de…Max Planck (1929). Era la primera vez que se entregaba la distinción creada por la Sociedad Alemana de Física; se otorgó en esta primera edición a los dos teóricos. El primero en recibirla fue Max Planck, quien, a continuación hizo entrega de la suya a Einstein. Fuente: Institute for Advanced Study.
Albert Einstein recibe la Medalla Max Planck de manos de…Max Planck (1929). Era la primera vez que se entregaba la distinción creada por la Sociedad Alemana de Física; se otorgó en esta primera edición a los dos teóricos. El primero en recibirla fue Max Planck, quien, a continuación hizo entrega de la suya a Einstein. Fuente: Institute for Advanced Study.Pero, ¿qué era esta h?
Históricamente, la primera sugerencia de que la energía en la radiación electromagnética está «cuantificada» (viene en cantidades, cuantos, definidas) no aparece en el modelo fotónico del efecto fotoeléctrico. Lo hizo en estudios sobre el calor y la luz irradiados por los sólidos calientes. Max Planck introdujo el concepto de cuanto de energía (aunque en un contexto diferente) a finales de 1899, 5 años antes de la teoría de Einstein. Es por esto que a la constante h se la conoce como constante de Planck.
Planck trataba de explicar cómo la energía térmica (y la luz) irradiada por un cuerpo caliente está relacionada con la frecuencia de la radiación. La física clásica (termodinámica y electromagnetismo del siglo XIX) no podía explicar los hechos experimentales. Planck descubrió que los hechos solo podían interpretarse suponiendo que los átomos, al irradiar, cambian su energía no en cantidades variables continuas, sino en cantidades discretas, en paquetes. El modelo fotónico del efecto fotoeléctrico de Einstein puede considerarse como una extensión y aplicación de la teoría cuántica de Planck de la radiación térmica. La gran diferencia y punto esencial es que Einstein postuló que el cambio en la energía del átomo E que se transporta está localizada en un fotón de energía E = hf, donde f es la frecuencia de la luz emitida por el átomo, como si el fotón fuese una partícula, en lugar de estar repartida por toda la onda de luz.
El éxito del modelo fotónico del efecto fotoelectrico ponía a toda la comunidad científica ante un verdadero dilema. Según la teoría ondulatoria clásica, la luz consiste en ondas electromagnéticas que se extienden continuamente a lo largo del espacio. Esta teoría tuvo mucho éxito en la explicación de los fenómenos ópticos (reflexión, refracción, polarización, interferencia). La luz se comporta como una onda experimentalmente, y la teoría de Maxwell da buena cuenta de este comportamiento ondulatorio. Pero la teoría de Maxwell no puede explicar el efecto fotoeléctrico. La teoría de Einstein, que postula la existencia de cantidades discretas de energía luminosa, sí explica el efecto fotoeléctrico, pero no otras propiedades de la luz, como la interferencia.
O sea, que había dos modelos de luz cuyos conceptos básicos parecían contradecirse entre sí. Según uno la luz es un fenómeno ondulatorio; según el otro la luz tiene propiedades similares a las partículas. Cada modelo tenía sus éxitos y sus limitaciones. La solución de este problema tendría consecuencias enormes para toda la física y tecnologías modernas en general y para nuestra comprensión de los átomos en concreto.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo El dilema del efecto fotoeléctrico se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La explicación de Einstein del efecto fotoeléctrico
- La incompatibilidad del efecto fotoeléctrico con la física clásica
- El desconcertante efecto fotoeléctrico
Por qué a veces confesamos cosas que, en realidad, nunca hicimos
Los que tenemos la suerte de no haber tenido un encontronazo serio con la justicia (y que así siga muchos años…) solo conocemos una sala de interrogatorios por haberla visto en las películas así que nuestro conocimiento sobre el tema debería ser puesto en cuarentena. Sin embargo, gracias a la abundante oferta de documentales sobre crímenes reales que incluyen escenas reales de interrogatorios, confesiones y juicios, no es difícil hacerse una idea, al menos aproximada, de cómo funciona el asunto.
Un sospechoso, más o menos atolondrado por el impacto del crimen sucedido, responde a una serie de preguntas más o menos amables o agresivas según avanza la investigación y, como resultado de la astucia del que pregunta y la suya propia, termina confesando el crimen. Y ante la confesión, ¡ajá, crimen resuelto!
¿Verdad? ¿Acaso no es una confesión la prueba definitiva? Solamente evidencias físicas muy contundentes pueden revertir una confesión, rastros de ADN que inequívocamente sitúen a otro sospechoso en el lugar de los hechos o al dueño de la confesión en otro lugar diferente. Excepto eso, una confesión es todo lo que parecería necesario para resolver un delito. Al fin y al cabo, ¿quién reconocería haber hecho algo grave, un asesinato, una violación, si no lo hubiese hecho? ¿Y por qué?

¿Son fiables todas las confesiones?
Saul Kassin es psicólogo en la universidad de justicia criminal John Jay de Nueva York y uno de los principales expertos mundiales en interrogatorios y falsas confesiones. La revista Science ha dedicado recientemente un reportaje a su trabajo, en el que cuenta por qué algo aparentemente tan contraintuitivo como que un sospechoso se autoinculpe de un crimen que no cometió no solo es algo más común de lo que podríamos pensar, sino que tiene una causa que la psicología puede explicar.
Las confesiones siempre se han considerado el indicador máximo de la culpabilidad, incluso aunque se conocen casos históricos de falsas autoacusaciones. Científicamente la primera alerta al respecto está fechada en 1908, cuando Hugo Müsterberg, reputado psicólogo de la Universidad de Harvard de la fecha ya alertó de “confesiones inciertas bajo el efecto de poderosas influencias”. Sin embargo, fue a finales de los años 80 con la introducción en los juzgados de las evidencias basadas en técnicas de reconocimiento de ADN para exonerar a condenados que en realidad eran inocentes cuando se empezó a vislumbrar cómo de frecuente podía ser el problema.
Kassin ha dedicado su carrera a este tema. Estudió y se doctoró en psicología, y cómo investigador postdoctoral, analizando la forma en que los jurados toman decisiones, quedó sorprendido con el poder que tiene una confesión para prácticamente garantizar un veredicto de culpabilidad.
Al mismo tiempo empezó a preguntarse si era posible analizar cuántas de esas confesiones eran reales. Comenzó a estudiar una técnica de interrogatorio llamada Reid, por uno de sus autores, John Reid, basada en un método publicado en 1962 y que es una forma habitual de entrenar a los agentes que se dedican a este área del trabajo policial. “Me quedé horrorizado. Era como los estudios sobre la obediencia de Milgram, pero peor”.
Bajo presión de la autoridad, hacemos lo que no haríamos
Echemos un paso atrás. Stanley Milgram, psicólogo de la Universidad de Yale, llevó a cabo una serie de estudios sobre la conducta en la década de los 60 en los que se animaba a los participantes a aplicar descargas eléctricas sobre otros sujetos si consideraban que éstos no estaban aprendiendo lo suficientemente deprisa. Los voluntarios, que no sabían que esas descargas en realidad eran falsas y creían estar causando dolor real a sus compañeros, resultaron estar sorprendentemente dispuestos a hacerlo si una persona a la que consideraban con autoridad sobre ellos se lo pedía.
El manual para interrogar de Reid parece diferente al principio. La técnica comienza con una evaluación previa en la que el interrogador hace una serie de preguntas, algunas irrelevantes y otras más sustanciosas, mientras busca en el interrogado determinadas señales de que esté mintiendo, como evitar el contacto visual o cruzarse de bazos. Después va la fase dos, considerada el interrogatorio formal. Aquí el que pregunta sube el tono, acusando al sospechoso repetidamente, pidiendo detalles concretos e ignorando los momentos en que niega su implicación. Al mismo tiempo ofrece su simpatía y comprensión, minimizando las implicaciones morales del crimen, pero no las legales, facilitando el momento de la confesión. “Esto no habría pasado si ella no te hubiese faltado al respeto” y cosas así.
 Foto: nihon graphy / Unsplash
Foto: nihon graphy / Unsplash“¿He pulsado yo esa tecla?”
Esta es la fase que Kassim relacionaba con el experimento de Milgram: una figura de autoridad presionando para causar un daño, solo que en vez de a un tercero, aquí sería a uno mismo al admitir una culpabilidad que no es propia. Kassim sospechaba que esa presión autoritaria podía llevar a veces a realizar confesiones falsas.
Para averiguarlo, en los años 90 decidió modelar en el laboratorio la técnica Reid con estudiantes voluntarios, creando lo que llamó el experimento del bloqueo informático: hacía a los estudiantes seguir órdenes rápidas ante un ordenador, avisándoles de que tenía un fallo y que si pulsaban la tecla Alt, el ordenador se bloquearía. Esto era falso en parte: el ordenador estaba programado para bloquearse en todas las pruebas. Cuando ocurría, el investigador acusaba al estudiante que estuviese haciendo la prueba en ese momento de haber apretado la tecla Alt.
Al principio, ninguno de los estudiantes confesaba. Luego fue introduciendo distintas variaciones basadas en esas técnicas de interrogatorios policiales. A veces, por ejemplo, un policía le decía falsamente a un sospechoso que tenían un testigo del crimen, haciéndole dudar de su versión de los hechos. Funcionó en el caso de Marty Tankleff, adolescente estadounidense que en 1988 llegó a casa y se encontró a sus padres apuñalados en la cocina, su madre muerta y su padre en coma. La policía le consideró el principal sospechoso y tras horas interrogándole sin éxito le dijeron que su padre había despertado en el hospital y había dicho que fue él quién lo hizo (aunque no era verdad, su padre murió sin despertar del coma). Completamente en shock y dudando de sus propios recuerdos, Tankleff confesó y pasó 20 años en la cárcel antes de que nuevas evidencias sirviesen para exonerarle.
Ante un testigo o en espera de más pruebas
Un impacto de ese tipo no se podía generar en el laboratorio, pero Kassin sí podía aliarse con un “testigo” que asegurase haber visto al estudiante apretar la tecla en cuestión, y resultó que esos estudiantes confesaban el doble de veces que aquellos que hacían la prueba en presencia de un testigo que aseguraba no haber visto nada. En determinadas circunstancias, prácticamente todos los estudiantes que trabajaban ante un testigo acusatorio falso terminaban confesando.
Algunos estudiantes terminaban tan convencidos de haber causado el bloque que sin querer inventaban explicaciones y justificaciones, y algunos internalizaban tanto su fallo que se negaban a creer al investigador cuando este les contaba la verdad sobre la prueba.
Otro truco policial puede ser, no mentir sobre las evidencias disponibles, pero si advertir de que se están esperando más pruebas, por ejemplo, un análisis de rastros de ADN encontrados en la escena del crimen. Ante esa situación, que intuitivamente daría al acusado inocente más razones para defenderse y resistir, muchos se derrumban y confiesan, precisamente para liberarse de la presión en ese momento y confiando en que la posterior llegada de nuevas pruebas servirá para exonerarles.
Kassin creó una variante de la prueba del ordenador para testar estas situaciones: además de acusar al estudiante de haber apretado la tecla Alt, les decía que el registro de las teclas pulsadas estaba grabado y que podrían consultarlo muy pronto. El número de estudiantes que confesaba se disparó, precisamente porque querían salir de allí en ese momento y esperaban que la posterior consulta del registro les liberase de culpa. En ese sentido, la confianza en el correcto funcionamiento del sistema y en la propia inocencia pueden ser factores de riesgo de terminar realizando una confesión falsa.
Otros experimentos: jóvenes, adictos o enfermos mentales, los más vulnerables
Existen algunas críticas obvias a estos experimentos. Por ejemplo, que en este contexto de pruebas universitarias difícilmente se temen las mismas consecuencias, o estas son tan obvias ante una falsa confesión que en el entorno de una investigación criminal, o que pulsar una tecla sin querer es relativamente común y eso puede hacer que alguien dude de su propia versión de los hechos, algo que no parece igual de probable cuando hablamos de cometer el asesinato, por ejemplo, de tus propios padres.
Por eso otros investigadores han buscado cómo complementarlos. Es el caso de Melissa Russano, psicóloga social en la Universidad Roger Williams en Rhode Island. Ella diseñó un experimento en el que se pedía a una serie de voluntarios que resolviesen un conjunto de problemas de lógica, algunos en grupo y otro de manera individual. Ante de empezar se dejó bien claro que bajo ningún concepto era aceptable ayudar a los estudiantes que debían trabajar solos, a algunos de los cuales se les había instruido previamente para mostrar muchas dificultades y disgusto ante las pruebas. Esto llevó a algunos de sus compañeros a echarles una mano, lo cuál suponía una clara violación de las reglas.
En esos experimentos los que ayudaban sabían que estaban saltándose las reglas, y confesar conllevaba ciertas consecuencias ya que se había roto el código de conducta de las sesiones. Pero, igual que Kassin, Russano observó que un interrogatorio acusatorio podía provocar falsas confesiones. Ella y sus colegas probaron otro truco habitual en los interrogatorios policiales: el de la minimización de la carga emocional o moral de la falta cometida, diciendo cosas como que “seguro que no te has dado cuenta de cómo de serio era lo que estabas haciendo”, y con eso consiguieron que la tasa de falsas confesiones subiese un 35%.
Otros investigadores, como Gísli Gudjónsson, detective islandés y psicólogo en el King’s College de Londres, han explicado que determinados factores hacen a algunos individuos más susceptibles que a otros a este tipo de presión. Por ejemplo, enfermedades mentales, ser muy jóvenes o la adicción a sustancias hacen que algunas personas estén más dispuestas a dudar de su propia memoria y a confesar bajo presión cosas que no han cometido.
Richard Leo, profesor de derecho de la Universidad de San Francisco en California, y Rochard Ofshe, por entonces en la Universidad de California Berkeley, describieron en varios informes una “persuasión” hacia la confesión: confesiones que eran resultado de situaciones en las que un sospechoso, destrozado tras horas de interrogatorio, entra en un camino mental en el que empieza a creer en su propia culpa aunque sea falsa. Es un fenómeno especialmente pronunciado entre adolescentes que son impresionables y fácilmente intimidables por una figura autoritaria.
Las confesiones quizá no sean lo más importante
Entre todos consiguieron crear un cuerpo de evidencias suficientes que hicieron que en torno al año 2010 Kassin y varios colegas americanos y británicos escribieron un documento para la Asociación Americana de Psicología advirtiendo del riesgo de coacción en estos interrogatorios y sugiriendo algunas reformas, como por ejemplo prohibiendo las mentiras por parte de los investigadores, limitando el tiempo que podían durar esos interrogatorios y exigiendo la grabación de éstos de principio a fin.
De hecho, cuestionaban el valor de las confesiones como tal y ponían en duda lo idóneo de que eso sea lo que busquen principalmente los investigadores, señalando que ante el peso de otro tipo de pruebas forenses o de otro tipo, quizá seguir utilizando las confesiones como la principal medida de la culpabilidad no solo sea un riesgo, sino que además no sea lo más inteligente.
Para la espectacularidad de un asesino que por fin confiesa siempre nos quedarán las series policiales.
Referencias
This psychologist explains why people confess to crimes they didn’t commit – Science
Migram Experiment – Simple Psychology
Inside interrogation: The lie, the bluff, and false confessions – American Psychology Association
Marty Tankleff – Wikipedia
Investigating True and False Confessions Within a Novel Experimental Paradigm – Psychological Science
The Psychology of False Confessions: Forty Years of Science and Practice – Wiley Online Library
The Social Psychology of Police Interrogation: The Theory and Classification of True and False Confessions – Studies in Law, Politics, and Society
Police-Induced Confessions: Risk Factors and Recommendations – Law and Human Behaviour
Sobre la autora: Rocío Pérez Benavente (@galatea128) es periodista
El artículo Por qué a veces confesamos cosas que, en realidad, nunca hicimos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- ¿Por qué si nunca hemos vivido mejor que ahora el mundo nos parece cada vez peor?
- Realidad conexa, porque todo está conectado.
- Nunca es tarde
Los dioses moralizantes no crearon los grandes estados
Los grandes dioses, propios de religiones moralizantes, aparecieron mucho después de que se desarrollasen entidades políticas de gran complejidad social. Esta es la principal conclusión de un estudio publicado hace unos meses en la revista Nature por un amplio equipo de investigadores. Sus resultados refutan la conocida tesis de que fue la adopción de divinidades moralizantes lo que facilitó el desarrollo de grandes entidades políticas. La tesis rechazada sostenía que los códigos morales de inspiración religiosa habían servido para promover la convivencia y cooperación dentro de sociedades heterogéneas y que sin ellos, esas sociedades habrían sido inviables.
 El Juicio de Osiris representado en el Papiro de Hunefer (ca. 1275 a. C.). Anubis, con cabeza de chacal, compara el peso del corazón del escriba Hunefer con el de la pluma de la verdad en la balanza de Ma’at. Tot, con cabeza de ibis, escriba de los dioses, anota el resultado. Si el corazón es más ligero que la pluma, a Hunefer se le permitirá pasar a la otra vida. Si no es así, será devorado por la quimera Ammyt, compuesta por partes de cocodrilo, león e hipopótamo, que espera expectante. Fuente British Musem / Wikimedia Commons
El Juicio de Osiris representado en el Papiro de Hunefer (ca. 1275 a. C.). Anubis, con cabeza de chacal, compara el peso del corazón del escriba Hunefer con el de la pluma de la verdad en la balanza de Ma’at. Tot, con cabeza de ibis, escriba de los dioses, anota el resultado. Si el corazón es más ligero que la pluma, a Hunefer se le permitirá pasar a la otra vida. Si no es así, será devorado por la quimera Ammyt, compuesta por partes de cocodrilo, león e hipopótamo, que espera expectante. Fuente British Musem / Wikimedia CommonsLa primera aparición de deidades moralizantes se produjo en Egipto, alrededor de 2.800 aC (II Dinastía), donde Ma’at era venerada como la diosa de la verdad, la justicia, la moralidad y el equilibrio. A esta siguieron apariciones esporádicas de cultos locales a lo largo y ancho de Eurasia (Mesopotamia, 2.200 aC; Anatolia, 1500 aC; China, 1000 aC), antes de que comenzase la expansión de importantes religiones durante el primer milenio aC con el Zoroastrismo y el Budismo, seguidos más tarde por el Cristianismo y el Islam. Aunque estos dos credos acabarían siendo adoptados por numerosas sociedades, ya existían en muchas de ellas dioses moralizantes como es el caso de los romanos desde 500 aC.
Utilizaron información sobre 414 unidades políticas independientes de 30 regiones geográficas, para un periodo que va del comienzo del Neolítico a la época industrial o colonial. Caracterizaron cada una de las sociedades mediante un índice de complejidad social (establecido a partir del registro arqueológico y escrito) y en virtud de la existencia (o no) de divinidades moralizantes (como el Dios de Abraham) o de sistemas equivalentes de creencias que inspiraron alguna forma de castigo, de origen sobrenatural, de las transgresiones morales (como el karma en el Budismo). Esta segunda posibilidad la basaron en la existencia de normas, basadas en la creencia en entes sobrenaturales, que promovían la reciprocidad, la justicia y la lealtad intragrupal.
Encontraron que la complejidad social antecedía a las divinidades moralizantes y que predecía su adopción. De hecho, la complejidad crecía mucho más rápido antes de la aparición de los dioses que después. Observaron también que la deidad moralizante era adoptada dentro del siglo siguiente a la superación de un cierto umbral de complejidad social (60% del máximo), que corresponde a lo que los autores denominan una megasociedad (aproximadamente un millón de habitantes). Y de entre las sociedades de las 10 regiones que no adoptaron dioses moralizantes solo el imperio Inca (61% de la complejidad máxima) superó el umbral de megasociedad.
La adopción de deidades moralizantes tampoco fue –como a veces se ha propuesto- consecuencia de la bonanza económica que trajeron una agricultura y ganadería cada vez más eficientes durante la llamada Era Axial (primer milenio aC), ya que en Egipto, Mesopotamia y Anatolia fueron adoptados antes de 1500 aC.
Los autores del estudio conceden mucha importancia a los rituales. Su celebración frecuente, así como la vigilancia institucionalizada de su cumplimiento, propia de religiones con varios niveles jerárquicos, antecedió a las grandes religiones unos 1.100 años en promedio. Creen que fueron esos rituales y su reforzamiento por las autoridades religiosas el elemento que permitió unificar numerosas poblaciones por primera vez en la Historia, al favorecer la aparición de identidades comunes en el interior de grandes estados. Los dioses moralizantes llegaron después y aunque no fuesen ellos la causa de la evolución de megasociedades, fueron una adaptación cultural clave para favorecer la cooperación en su seno, algo de especial importancia en sociedades multiétnicas.
Fuente: H. Whitehouse et al (2019): Complex societies precede moralizing gods throughout world history. Nature 568: 226-229.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Los dioses moralizantes no crearon los grandes estados se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- ¿Cinco o seis grandes?
- Retrospectiva de un cuadro: El festín de los dioses
- ¿Por qué son tan grandes las ballenas?
Metamateriales, invisibilidad y la capa de Harry Potter

La invisibilidad, los metamateriales y la capa de Harry Potter tienen en común… exacto, las matemáticas. El Ikerbasque Research Fellow Pedro Caro, del BCAM, lo explica.
Quizás sea el número más famoso de la historia. Lo cierto es que el número Pi, representado por la letra griega π, es una de las constantes matemáticas más importantes que existen en el mundo, estudiada por el ser humano desde hace más de 4.000 años. La fascinación que ha suscitado durante siglos es tal que el popular número cuenta con su propio día en el calendario, así el mes de marzo se celebra el Día de Pi en todo el planeta.
Este evento internacional vino de la mano del físico estadounidense Larry Shaw, quien lanzó en 1988 la propuesta de celebrar esta efeméride. La forma en la que se escribe el 14 de marzo en inglés y euskera coincide con los tres primeros dígitos de la famosa constante matemática. (3-14 martxoaren 14 en euskara / 3-14 march, 14th en inglés) y además, la celebración coincide con la fecha del nacimiento de Albert Einstein. En 2009, el congreso de EEUU declaró oficialmente el 14 de marzo como el Día Nacional de Pi.
Actualmente, el Día de Pi es una celebración mundialmente conocida que sobrepasa el ámbito de las matemáticas. Este número irracional, que determina la relación entre la longitud de una circunferencia y su diámetro, concierne a múltiples disciplinas científicas como la física, la ingeniería y la geología, y tiene aplicaciones prácticas sorprendentes en nuestro día a día.
Este 2019 nos unimos de nuevo al festejo con el evento BCAM–NAUKAS, que se desarrolló a lo largo del 13 de marzo en el Bizkaia Aretoa de UPV/EHU. BCAM-NAUKAS contó durante la mañana con talleres matemáticos para estudiantes de primaria y secundaria y durante la tarde con una serie de conferencias cortas dirigidas al público en general.
Este evento es una iniciativa del Basque Center for Applied Mathematics -BCAM, enmarcada en la celebración de su décimo aniversario, y de la Cátedra de Cultura Científica de la Universidad el País Vasco.
Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Metamateriales, invisibilidad y la capa de Harry Potter se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Neandertales
La Facultad de Ciencias de Bilbao comenzó su andadura en el curso 1968/69. 50 años después la Facultad de Ciencia y Tecnología de la UPV/EHU celebra dicho acontecimiento dando a conocer el impacto que la Facultad ha tenido en nuestra sociedad. Publicamos en el Cuaderno de Cultura Científica y en Zientzia Kaiera una serie de artículos que narran algunas de las contribuciones más significativas realizadas a lo largo de estas cinco décadas.
Los neandertales fueron cazadores recolectores que habitaron Europa, Oriente Medio y parte de Asia durante más de 150 mil años, hasta que desaparecieron hace unos 30-40 mil años. Físicamente eran de estatura media, con un promedio de 166 cm los hombres y 154 cm las mujeres, pero más robustos y con los cuerpos más anchos. Tenían una gran capacidad craneal, la frente huidiza, dos grandes arcos óseos por encima de los ojos, entre otros numerosos rasgos anatómicos que nos permiten diferenciarlos de nuestra especie. El uso de nuevas tecnologías, nos está permitiendo conocer con mayor detalle la anatomía de estos humanos (Figura 1).
 Figura 1. Izquierda: Fotografía del molde del esqueleto de Kebara 2 (Madrid Scientific films). Derecha: Reconstrucción virtual del tórax de Kebara 2 (escala = 5 cm). Figura originalmente publicada por Gómez-Olivencia et al. (2018). Licencia Creative Commons 4.0.
Figura 1. Izquierda: Fotografía del molde del esqueleto de Kebara 2 (Madrid Scientific films). Derecha: Reconstrucción virtual del tórax de Kebara 2 (escala = 5 cm). Figura originalmente publicada por Gómez-Olivencia et al. (2018). Licencia Creative Commons 4.0.Los neandertales soportaron cambios climáticos muy severos: momentos glaciares, y momentos interglaciares (como el actual), pero en general habitaron una Europa algo más fría que la actual. A pesar de eso, y en contra de la creencia tradicional, no estaban especialmente adaptados al frío, y de hecho la mayor parte de los descubrimientos se localizan en latitudes templadas, especialmente en la península ibérica, el sudoeste de Francia, la península itálica y el levante mediterráneo. Los neandertales habitaron gran cantidad de ecosistemas: cazaban gamos y gacelas en zonas de bosque mediterráneo de Oriente medio, mamuts, renos y caballos en las llanuras de Bélgica o cabras montesas en la cordillera cantábrica. Conocemos muy bien los animales que consumían ya que se han encontrado muchos restos de huesos con marcas de corte junto con herramientas de piedra (industria lítica) en muchos yacimientos, especialmente en las cuevas que usaron como refugio. De hecho, los análisis de estos restos de fauna y el análisis de los isótopos estables del colágeno de sus huesos indican que los neandertales, junto con los leones, leopardos y hienas, eran grandes depredadores. Es más, en algunas ocasiones, también se alimentaban de sus congéneres, y por tanto, practicaban el canibalismo (Figura 2).
 Figura 2. Fémur neandertal (Fémur III) del yacimiento de Goyet (Bélgica) que presenta marcas de corte (c1,c2) y marcas de haber sido usado como retocador de hueso (b1,b2). Figura originalmente publicada por Rougier et al. (2016) Licencia Creative Commons 4.0.
Figura 2. Fémur neandertal (Fémur III) del yacimiento de Goyet (Bélgica) que presenta marcas de corte (c1,c2) y marcas de haber sido usado como retocador de hueso (b1,b2). Figura originalmente publicada por Rougier et al. (2016) Licencia Creative Commons 4.0.Los neandertales también se alimentaban de vegetales y usaban la madera para hacer herramientas (ver más abajo). Como, en general, la materia vegetal se descompone más fácilmente que los huesos, no tenemos mucha información de qué plantas consumían. El estudio al microscopio del sarro de varios dientes fósiles neandertales ha permitido saber que consumían dátiles, semillas de hierbas y plantas acuáticas, y además se ha visto que cocinaban estos vegetales. Esto no debería sorprendernos, ya que existen numerosas evidencias del uso del fuego por parte de los neandertales. En ciertos yacimientos excepcionales, como Abric Romaní en Barcelona, se han conservado hogares de distintos tamaños y se ha podido hacer estudios más precisos de su situación espacial. Estos estudios ponen en evidencia distintos usos del espacio de este yacimiento durante las distintas ocupaciones que se produjeron durante miles de años, con la presencia de fuegos más grandes como zonas centrales de los campamentos o de fuegos tipo brasero en zonas de dormitorio.
Los animales cazados, además de alimento proporcionaban pieles para vestirse así como huesos que después eran usados como herramientas para tallar, como percutores blandos. Los neandertales tallaban distintos tipos de rocas que podían conseguir directamente o mediante intercambio con otros grupos. El estudio de la industria lítica ha aportado evidencias de diferencias culturales entre distintos grupos neandertales que habitaban Europa en un mismo momento, así como evolución cultural de estos grupos a lo largo del tiempo. Todo esto nos habla de comportamientos flexibles, que por un lado se amoldarían a los distintos ecosistemas que habitaban y a sus recursos, pero también de nos habla de transmisión cultural independiente del entorno que habitaban. Por ello, más de que cultura neandertal, en singular, deberíamos hablar de culturas neandertales, en plural.
Los neandertales en Pirineos occidentales
En esta región se han encontrado evidencias de ocupaciones de estas poblaciones en distintos yacimientos, tanto en cueva como al aire libre. Solamente en tres de estos yacimientos se han encontrado restos humanos: Axlor (Bizkaia), Lezetxiki (Gipuzkoa) y Arrillor (Araba/Álava), en su mayoría restos de dientes. El yacimiento de Aranbaltza III, además de proporcionar evidencia de distintas ocupaciones neandertales ha preservado la presencia de un palo cavador de más de 70 mil años (Figura 3).
 Figura 3. a) Fotografía mostrando la punta del palo cavador inmediatamente después de haber sido desenterrada. b) conservación actual. Figura originalmente publicada por Rios-Garaizar et al. (2018). Licencia Creative Commons 4.0
Figura 3. a) Fotografía mostrando la punta del palo cavador inmediatamente después de haber sido desenterrada. b) conservación actual. Figura originalmente publicada por Rios-Garaizar et al. (2018). Licencia Creative Commons 4.0Este es un descubrimiento excepcional porque, tal y como apuntábamos anteriormente, los objetos de madera no fosilizan frecuentemente. Además, el yacimiento de Axlor ha proporcionado ejemplos de explotación y consumo de un águila real (Figura 4), un cuervo, un lince y un lobo, indicando que además de animales herbívoros los Neandertales también podían cazar aves y carnívoros por su carne o su piel.
 Figura 4. Fragmento proximal de fémur de águila real (Aquila chrysaetos) del nivel IV de Axlor, donde se pueden ver dos zonas (A1,A2) con marcas de corte. Figura originalmente publicada por Gómez-Olivencia et al. (2018). Licencia Creative Commons 4.0.
Figura 4. Fragmento proximal de fémur de águila real (Aquila chrysaetos) del nivel IV de Axlor, donde se pueden ver dos zonas (A1,A2) con marcas de corte. Figura originalmente publicada por Gómez-Olivencia et al. (2018). Licencia Creative Commons 4.0.Origen y desaparición
El origen de los Neandertales se encuentra en poblaciones que habitaron Europa en el Pleistoceno Medio hace medio millón de años. De hecho, en el yacimiento de la Sima de los Huesos, en la Sierra de Atapuerca, con una cronología de 430 mil años, encontramos la primera población con características neandertales claras, especialmente en la cara, la mandíbula y los dientes y en algunos rasgos del esqueleto postcraneal. En cambio, la causa de la extinción de los neandertales es todavía desconocida. Se han planteado varias hipótesis para la misma, incluyendo competencia por parte de nuestra especie (incluyendo razones demográficas), o altas tasas de endogamia en los Neandertales. Hoy en día sabemos que los Neandertales interactuaron y se cruzaron con otros grupos humanos. Sabemos que se mezclaron con los enigmáticos Denisovanos, un grupo humano que sólo es conocido por su ADN, así como con nuestra especie, ya que ciertas poblaciones de nuestra especie conservamos un pequeño porcentaje de ADN neandertal. Aunque se ha avanzado mucho en el conocimiento de estos humanos fósiles desde la primera vez que se describieron sus restos, hace más de 150 años, todavía queda mucho más por conocer.
Para saber más:
A. Galarraga (2018) “…eta neandertalek sua piztu zuten”. https://aldizkaria.elhuyar.eus/erreportajeak/eta-neandertalek-sua-piztu-zuten/
A. Gómez-Olivencia, et al. (2018) “3D virtual reconstruction of the Kebara 2 Neandertal thorax”. Nature communications 9(1), 4387. DOI: 10.1038/s41467-018-06803-z
A. Gómez-Olivencia, et al. (2018) “First data of Neandertal bird and carnivore exploitation in the Cantabrian Region (Axlor; Barandiaran excavations; Dima, Biscay, Northern Iberian Peninsula)”. Scientific Reports. 8, 10551. DOI: 10.1038/s41598-018-28377-y
J. Rios-Garaizar (2018) Arqueobasque
J. Rios-Garaizar et al. (2018) “A Middle Palaeolithic wooden digging stick from Aranbaltza III, Spain” PLOS ONE. 13, e0195044. DOI:10.1371/journal.pone.0195044
H. Rougier et al. 2016. Neandertal cannibalism and Neandertal bones used as tools in Northern Europe. Scientific Reports. 6, 29005. DOI: 10.1038/srep29005
Sobre el autor: Asier Gómez es investigador Ramón y Cajal en el Departamento de Estratigrafía y Paleontología de la Facultad de Ciencia y Tecnología de la UPV/EHU.
El artículo Neandertales se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Por qué nos fascinan los neandertales
- La cronología de la desaparición de los neandertales
- Neandertales ¿crónica de una muerte anunciada?, por María Martinón-Torres
Escuchar Mozart no te hará más listo

En 1993 se publicó en Nature uno de los artículos científicos que más impacto social ha tenido de las últimas décadas. Tres investigadores de la Universidad de California habían reclutado a un grupo de 36 estudiantes universitarios para resolver una serie de tests que involucraban razonamiento espacial. Tras escuchar durante 10 minutos una sonata de Mozart, los estudiantes parecían ver incrementada ligeramente su habilidad (8-9 puntos más de CI) en comparación con otros dos grupos de control: estudiantes que habían escuchado un disco de relajación o que habían permanecido en silencio durante el mismo tiempo1.
Poco importó que el estudio no se realizase en ningún momento con bebés, que el efecto de mejora no durase más de 15 minutos o que, de hecho, no hablase de inteligencia. Tras cientos de titulares en prensa y aún más malentendidos, la idea popular que caló era muy distinta a la del artículo original y mucho más vendible: escuchar a Mozart te hace más listo, sobre todo si lo escuchas siendo un niño pequeño. A mediados de la década de los 90, cientos de CDs, libros interactivos y cascos adaptables para vientres de embarazadas invadían ya los escaparates de todo el mundo bajo un sello común: el “efecto Mozart”.
Antes de que os lo sigáis preguntando, dejadme despejar cualquier remanente de duda: el efecto Mozart no existe, no tiene fundamento científico, ni siquiera en su limitada versión publicada en 1993. Estudios posteriores han intentado replicar el resultado original con un éxito más bien variable2. En 1999, un meta-análisis basado en 16 de dichos estudios3 concluyó que el efecto, de haberlo, resultaba despreciable. En 2010 un nuevo meta-análisis4 llegó a una conclusión parecida basándose, esta vez, en 40 estudios previos.
Algunos psicólogos han apuntado que el “efecto Mozart” podría tratarse, más bien, de una especie de “efecto buen rollo”5 (“enjoyment arousal” en la literatura científica): al estar de buen humor (por haber escuchado, por ejemplo, una música que nos gusta) somos capaces de resolver ciertas tareas con mayor facilidad. Esto podría explicar los resultados variables a la hora de replicar el estudio de Nature de 1993: quizás, solo los sujetos que disfrutaban de la música de Mozart veían mejorada su habilidad espacial.
En esta línea, otros estudios han mostrado que el efecto Mozart tiene, de hecho, poco que ver con Mozart: los mismos resultados pueden obtenerse escuchando cualquier otro tipo de música6 o, incluso, leyendo historias de Stephen King. Esto último se ha probado tal cual7: en un estudio de 2001, se medían las habilidades espaciales de los sujetos tras permanecer 10 minutos en silencio o tras escuchar 10 minutos de Mozart, de Schubert o un relato de Stephen King. Los resultados variaban, sí, pero lo hacían en función de las preferencias del sujeto. Es decir, lo único importante es que la actividad resultase agradable, que los participantes en el test se pudiesen de buen humor.
Por supuesto, hoy en día todo el mundo habla del “efecto Mozart” y no del “efecto Stephen King” y a estas alturas de la película, con tantos estudios realizados y tantos meta-análisis descartando el mito, cabe preguntarse por qué siguen vendiéndose CDs con carátulas tan feas: ¿por qué caló tanto y aún hoy sigue calando el efecto Mozart?
Existen varias posibles explicaciones y todas ellas explotan algún tipo de sesgo o prejuicio, de esos que tanto nos gusta utilizar para no pensar. Para empezar, el efecto Mozart encaja muy bien con otros mitos muy arraigados, como el determinismo infantil8: la idea de que lo que nos sucede en etapas tempranas del desarrollo tiene consecuencias irreversibles durante el resto de la vida (este mito es probablemente anterior a Freud pero qué duda cabe de que él ayudó a popularizarlo). También resuena con una creencia mucho más antigua que atribuye poderes mágicos a la música: si es capaz de “amansar a las fieras”, ¿por qué no iba a hacer más listos a los bebés? Para colmo, el efecto Mozart promete efectos espectaculares a cambio de ningún esfuerzo y sin consecuencias negativas posibles. Curar lo incurable sin efectos secundarios, ¿os suena de algo?
Pero entre todos los motivos por los que el efecto Mozart es hoy conocido por todos, la figura del propio compositor juega un papel muy importante. Para empezar porque, debido a nuestra herencia romántica, seguimos creyendo en los artistas genio, verdaderos héroes de la historia cuyo legado es irrepetible e inconfundible. Cuando la realidad es que cualquier sonata de Mozart no es muy distinta a las de otros compositores de su tiempo. Con melodías preciosas, no me malinterpretéis, Mozart era un compositor estupendo… y un hijo del Clasicismo como lo fueron antes que él Haydn o Salieri (podéis probar, si no, a resolver este test9). El hecho de que popularmente se atribuyan semejantes poderes a su música no deja de ejemplificar la creencia de que los genios tienen habilidades mágicas (y no sólo los que salen de una lámpara).
Para colmo, Mozart fue un niño prodigio. Y por el mismo razonamiento erróneo que lleva a los seguidores de la homeopatía a creer que lo similar cura lo similar, otros pueden pensar que quizás el genio se contagia. Después de todo, fue el puro azar lo que llevó a unos investigadores de California a elegir una sonata de Mozart y no, pongamos, un tango de Gardel, para realizar sus experimentos sobre razonamiento espacial. De no haber sido así, quizás los titulares no hubiesen resonado tanto ni se hubiesen vendido tantos CDs. Quizás entonces, la gente seguiría escuchado a Mozart por el único motivo sensato que sigue habiendo para hacerlo: no porque nos haga más listos, sino porque afortunadamente nos hace más felices.
Referencias:
1 Music and Spatial Task Performance. Frances H. Rauscher, Gordon L. Shaw & Catherine N. Ky. Nature, 1993.
2 The mystery of the Mozart effect: Failure to replicate. K.M. Steele, K. E. Bass, & M. D. Crook. Psychological Science, 1999.
3 Prelude or requiem for the ‘Mozart effect’? Christopher F. Chabris. Kenneth M. Stelle, Simone Dalla Bella, Isabelle Peretz. Nature, 1999
4 Mozart effect–Shmozart effect: A meta-analysis. Jakob Pietschnig, Martin Voracek & Anton K. Formann. Intelligence 2010
5 Arousal, mood, and the Mozart effect. William Forde Thompson, E. Glenn Schellenberg, Gabriela Husain. Psychological Science, 2001.
6 Music Listening and Cognitive Abilities in 10‐ and 11‐Year‐Olds: The Blur Effect. E. Glenn Schellenberg & Susan Hallam. Annals of the New York Academy of Sciences, 2005
7 The Mozat effect: an artifact of preference. Kristin M. Nantais & E. Glenn Schellengerg.
8 Three seductive ideas. Kagan, J. (1998). Cambridge, MA: Harvard University Press.
9 Scientific comparison of Mozart and Salieri. M. V. Simkin
Sobre la autora: Almudena M. Castro es pianista, licenciada en bellas artes, graduada en física y divulgadora científica
El artículo Escuchar Mozart no te hará más listo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El caso de Wolfgang Amadeus Mozart
- Lo que la magia esconde
- Los parabenos usados en cosmética son seguros
Infinitos monos
El teorema de los infinitos monos
de Borel-Cantelli
enuncia esta posibilidad:
si un infinito número de monos mecanografiaran
por un intervalo infinito de tiempo
podrían escribir cualquier texto posible.
Todo lo que incluye este poema.
Todas las palabras que alguna vez me has dicho.
José Manuel Gallardo

Este bello poema se titula Infinitos monos. Variación III. Pertenece al poemario Infinitos monos (El Desvelo, 2016) de José Manuel Gallardo, que la editorial presenta del siguiente modo:
Infinitos monos es un poemario sobre la comunicación y sus (im)posibilidades: «Las palabras que forman el poema,/ estas palabras, sacadas de contexto / en cualquier otro lugar podrían salvar vidas / quizá, o condenarlas.», pero también una visión sobre la vida como viaje, sobre la importancia de la mirada sobre los otros y sobre nosotros mismos. Era inevitable, por lo tanto, que en este poemario del autor madrileño hiciera acto de presencia una reflexión sobre el amor, incursión en la que alcanza gran profundidad, sirviéndose para ello de versos tranquilos y doblemente libres: libres por su composición técnica y libres por el espíritu que los insufla vida.
El libro comienza con el poema-prólogo titulado Infinitos monos, que va acompañado de cuatro variaciones. En este preámbulo el autor deja claro que, en número, las posibilidades de comunicación –combinando palabras– son inconcebibles, aunque no infinitas. Explica así la esencia del teorema de los infinitos monos y los objetivos de su poemario.
 Imagen: Wikimedia Commons
Imagen: Wikimedia Commons
El teorema de los infinitos monos afirma que con “suficiente” tiempo –tiempo infinito– un chimpancé pulsando al azar las teclas de una máquina de escribir podría redactar –con probabilidad 1– cualquier texto, por ejemplo, El Quijote de Miguel de Cervantes.
Esta idea fue planteada por Émile Borel en 1913 (ver 1., página 194) que intentaba ilustrar con esta metáfora la cabida de un suceso altamente improbable:
Concevons qu’on ait dressé un million de singes à frapper au hasard sur les touches d’une machine à écrire et que, sous la surveillance de contremaîtres illettrés, ces singes dactylographes travaillent avec ardeur dix heures par jour avec un million de machines à écrire de types variés. Les contremaîtres illettrés rassembleraient les feuilles noircies et les relieraient en volumes. Et au bout d’un an, ces volumes se trouveraient renfermer la copie exacte des livres de toute nature et de toutes langues conservés dans les plus riches bibliothèques du monde. Telle est la probabilité pour qu’il se produise pendant un instant très court, dans un espace de quelque étendue, un écart notable de ce que la mécanique statistique considère comme le phénomène le plus probable. Supposer que cet écart ainsi produit subsistera pendant quelques secondes revient à admettre que, pendant plusieurs années, notre armée de singes dactylographes, travaillant toujours dans les mêmes conditions, fournira chaque jour la copie exacte de tous les imprimés, livres et journaux, qui paraîtront la semaine suivante sur toute la surface du globe. Il est plus simple de dire que ces écarts improbables sont purement impossibles.
[Imaginemos que se ha adiestrado a un millón de monos para pulsar al azar las teclas de una máquina de escribir y que, bajo la supervisión de capataces analfabetos, estos monos mecanógrafos trabajan con diligencia diez horas al día con un millón de máquinas de escribir de varios tipos Los capataces analfabetos recogerían las hojas ennegrecidas y las encuadernarían en volúmenes. Y al cabo de un año, estos volúmenes conseguirían contener la copia exacta de libros de todo tipo e idiomas conservados en las bibliotecas más ricas del mundo. Tal es la probabilidad de que se produzca durante un instante muy corto, en un espacio de cierta extensión, una diferencia notable de lo que la mecánica estadística considera el fenómeno más probable. Suponer que la desviación así producida subsistirá durante unos segundos equivale a admitir que, durante varios años, nuestro ejército de monos mecanógrafos, trabajando siempre en las mismas condiciones, proporcionará todos los días la copia exacta de todos los papeles impresos, libros y periódicos, que aparecerán la siguiente semana en todo el mundo. Es más simple decir que estas diferencias improbables son puramente imposibles.]
Más adelante esta idea sufrió varias reformulaciones conduciendo a la noción de infinito. Desde una cantidad infinita de monos tecleando durante un tiempo infinito hasta un único chimpancé inmortal –que podríamos llamar Tristam… ¿por qué no?–, mecanografiando sin tregua, este trabajo generaría cualquier texto imaginable y, además, infinitas veces.
Volviendo al poemario Infinitos monos, tras el prólogo, el texto de Gallardo prosigue en tres partes: Elementos de la comunicación –una reflexión sobre la comunicación, con algún guiño a la química, al caos, al determinismo o a la lógica–, En el camino –que incluye poemas en los que se habla de la vida como un viaje: la familia, el desarraigo, la soledad, etc.– y Escápate conmigo –sobre el amor y desamor–. El autor incluye algunas referencias a las matemáticas –teoría del caos, teoría de cuerdas, procesos estocásticos, etc.–, la física –principio de incertidumbre de Heisenberg, el gato de Schrödinger, difracción, etc.– o la química –por ejemplo, uno de los poemas se titula Alótropos de carbón e incluye una ‘pequeña lección’ de química del carbono–.
¿Quizás es el mono Tristam, el inmortal, el autor de Infinitos monos?
Referencias
-
Émile Borel. La mécanique statique et l’irréversibilité. J. Phys. Theor. Appl., 1913, 3 (1), 189-196
-
Teorema del mono infinito, Wikipedia (consultado el 29 de junio de 2019)
-
Marta Macho Stadler, Infinitos monos, de José Manuel Gallardo, DivulgaMAT, 2016
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Infinitos monos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:¿Es posible el arte sin ciencia?
En un rincón del litoral donostiarra donde los estratos de la corteza terrestre descienden y se ocultan bajo el mar Cantábrico, para emerger de nuevo sobre la isla Santa Clara, se narra una historia de tierra, mar y viento. “El Origen”, fascinación del escultor Eduardo Chillida Juantegui.
El “Peine del Viento”, es la XV obra de un dilatado proceso creativo fruto de la reflexión, ensayos con formas y materiales, y aquel “Origen” como lugar condicionante. Su trabajo evolucionó, desde diseños rígidos y estáticos hacia figuras más orgánicas, y su posterior simplificación.
Influenciado tanto por movimientos artísticos, como por los avances científicos en el campo de la metalurgia, el artista se valió de las propiedades del acero Cor-ten, que contiene aditivos mejorando así su tenacidad y resistencia a la corrosión. El material genera una barrera protectora de herrumbre en la superficie, optimizándolo ante la corrosión atmosférica. Su característico color rojizo y meteorización paulatina visibiliza el inevitable “bagaje del tiempo” en su piel. Idea que el artista plasmó integrando el proceso de degradación material en el conjunto, realzado por manchas en las bases rocosas.
 Imagen: Arte y ciencia. Interacción entre el proceso creativo del escultor Eduardo Chillida Juantegui y los avances científicos en el acero al cobre, aplicados en la creación del conjunto escultórico “Peine del viento XV”. Se justifica la elección del acero Cor-Ten por sus propiedades materiales y el modo en el que se degrada a causa de las condiciones atmosféricas adversas de su ubicación. (Ilustración: Amaia Torres Piñeiro)
Imagen: Arte y ciencia. Interacción entre el proceso creativo del escultor Eduardo Chillida Juantegui y los avances científicos en el acero al cobre, aplicados en la creación del conjunto escultórico “Peine del viento XV”. Se justifica la elección del acero Cor-Ten por sus propiedades materiales y el modo en el que se degrada a causa de las condiciones atmosféricas adversas de su ubicación. (Ilustración: Amaia Torres Piñeiro)
El arte y la ciencia convergen en este lugar donostiarra, donde la historia y la naturaleza son protagonistas.
Referencias consultadas:- Díaz Ocaña, Iván (2013). Corrosión atmosférica de aceros patinables de nueva generación. Tesis doctoral. Universidad Complutense de Madrid, Facultad de Ciencias Químicas, Departamento de Ciencia de los Materiales e Ingeniería Metalúrgica.
- Elósegui Itxaso, José María (1977). El Peine del Viento de Eduardo Chillida en San Sebastián. Ingeniería de su colocación. Donostia – San Sebastián. Fundación Kutxa.
Autora: Amaia Torres Piñeiro (@amaia_torres), alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2018/19
Artículo original: El Peine del Viento de Chillida: materia, forma y lugar. Déborah García, Cuaderno de Cultura Científica, 28 de octubre de 2016.
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
El artículo ¿Es posible el arte sin ciencia? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- #Naukas16 La cultura
- Arte & Ciencia: Cómo descubrir secretos que esconden las obras de arte
- Arte & Ciencia: Química y Arte, reacciones creativas
La explicación de Einstein del efecto fotoeléctrico
 Si conocemos la función de trabajo de los materiales y las frecuencias de la luz incidente podríamos determinar qué materiales emiten electrones al ser expuestos a la luz, como el titanio de colores de las cubiertas del Hotel Marqués de Riscal. Foto: Wikimedia Commons
Si conocemos la función de trabajo de los materiales y las frecuencias de la luz incidente podríamos determinar qué materiales emiten electrones al ser expuestos a la luz, como el titanio de colores de las cubiertas del Hotel Marqués de Riscal. Foto: Wikimedia Commons
La explicación del efecto fotoeléctrico fue el trabajo principal citado en cuando se le concedió el premio Nobel de Física en 1921 a Albert Einstein. La explicación de Einstein, propuesta en 1905, desempeñó un papel importante en el desarrollo de la física atómica. Basó su teoría en una hipótesis muy atrevida, ya que pocos de los detalles experimentales se conocían en 1905. Además, el punto clave de la explicación de Einstein contradecía las ideas clásicas de la época.
Einstein asumió que la energía de la luz no estaba distribuida uniformemente en todo el frente de onda en expansión (como suponía la teoría clásica). En cambio, la energía de la luz se concentraría en «paquetes» separados. Además, la cantidad de energía en cada una de estas regiones no sería una cantidad cualquiera, sino una cantidad definida de energía que es proporcional a la frecuencia f de la onda luminosa. El factor de proporcionalidad sería una constante (símbolo h); se llama constante de Planck por razones que veremos más adelante.
Por lo tanto, en el modelo que propone Einstein, la energía luminosa en un haz de frecuencia viene en paquetes, cada uno cona energía E = hf, donde h = 6,626·10-34 J / s. La cantidad de energía radiante de cada paquete se llama cuanto de luz o cuanto de energía luminosa. Como cuanto de energía luminosa es muy largo, más tarde se le daría un nombre, fotón.
No hay una explicación más clara o más directa que la del propio Einstein en al artículo original de 1905 [1]. Presentamos a continuación una cita del mismo, en traducción libre y con la notación adaptada a la que venimos utilizando:
[…]De acuerdo con la idea de que la luz incidente se compone de cuantos con energía hf, la expulsión de los rayos catódicos [fotoelectrones] por luz se puede entender de la siguiente manera. Los cuantos de energía penetran en la capa superficial del cuerpo y su energía se convierte, al menos en parte, en energía cinética de electrones. La imagen más simple es que un cuanto de luz cede toda su energía a un solo electrón; Asumiremos que esto sucede[…]. Un electrón provisto de energía cinética dentro del cuerpo puede haber perdido parte de su energía cinética en el momento en que llega a la superficie. Además, se debe suponer que cada electrón, al abandonar el cuerpo, tiene que realizar una cantidad de trabajo W (que es característica del cuerpo). Los electrones expulsados directamente desde la superficie y en ángulos rectos tendrán las mayores velocidades perpendiculares a la superficie. La energía cinética máxima de uno de estos electrones es
Ecmax = hf – W
Si la placa C se carga a un potencial positivo, Vp , lo suficientemente grande para evitar que el cuerpo pierda carga eléctrica, debemos tener que
Ecmax = hf – W = eVp ,
donde e es la magnitud de la carga electrónica[…]
Si la fórmula derivada es correcta, entonces Vp , cuando se representa gráficamente en función de la frecuencia de la luz incidente, debe producir una línea recta cuya pendiente debe ser independiente de la naturaleza de la sustancia iluminada. […]
A la primera ecuación en la cita anterior se la suele conocer como ecuación fotoeléctrica de Einstein. Veamos si esta ecuación y el modelo fotónico de Einstein pueden explicar los resultados experimentales que la física clásica no puede:
1. De acuerdo con la ecuación fotoeléctrica, la energía cinética de los fotoelectrones es mayor que cero solo cuando la energía del fotón hf es mayor que el trabajo W, que es el trabajo que debe realizar el electrón contra las fuerzas de atracción del material del cátodo en el que se encuentra para escapar de él. La energía requerida para escapar del metal se conoce como la función de trabajo. Por lo tanto, solo se puede emitir un electrón cuando la frecuencia de la luz incidente es mayor que un cierto valor mínimo que corresponde al trabajo requerido para escapar del metal. Usando símbolos, la frecuencia mínima o umbral f0 viene definida para cada material por la igualdad h f0 = W.
2. Según el modelo fotónico de la luz de Einstein, es un fotón individual de frecuencia f el que expulsa a un electrón si f > f0 . Como la intensidad de la luz es proporcional al número de fotones en el haz de luz y el número de fotoelectrones expulsados es proporcional al número de fotones incidentes en la superficie, la cantidad de electrones expulsados (y con ella la corriente fotoeléctrica) es proporcional a la intensidad de la luz incidente. [2]
3. En el modelo de Einstein, la energía luminosa se concentra en una serie de cuantos de luz (fotones). Por tanto no se necesita tiempo para que el electrón acumule energía luminosa. En efecto, los cuantos transfieren su energía inmediatamente a los fotoelectrones, que escapan de la superficie casi inmediatamente.
4. Finalmente, la ecuación fotoeléctrica predice que cuanto mayor sea la frecuencia de la luz incidente mayor será la energía cinética máxima de los electrones expulsados. Esto es así porque la energía del fotón es directamente proporcional a la frecuencia de la luz. La energía mínima necesaria para expulsar un electrón es la energía requerida para que el electrón escape de la superficie del metal. Esto explica por qué la luz de una frecuencia menor que la frecuencia f0 no puede expulsar ningún electrón. La energía cinética del electrón que se escapa es la diferencia entre la energía del fotón absorbido y la energía perdida por el electrón al escapar de la superficie: si la priemera no compensa a la segunda el electrón se queda donde está
Notas:
[1] Einstein, A. (1905) Über einen die Erzeugung und Verwandlung des Lichtes betreffenden heuristischen Gesichtspunkt Annalen der Physik 17, 132-149
[2] Ojo, no todos los fotones en un haz de luz incidente golpean un electrón haciendo así que se emita desde el metal. Solo del orden de 1 de cada 50 fotones lo consigue. Esto es muy importante para la ingeniería y el diseño de experimentos, pero para lo que a nosotros nos interesa no es necesario que pase de nota a pie de página.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo La explicación de Einstein del efecto fotoeléctrico se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La incompatibilidad del efecto fotoeléctrico con la física clásica
- El desconcertante efecto fotoeléctrico
- El principio de relatividad (y 4): la versión de Einstein
Azul… ¿Serendipia?
Berlín, año 1704. El químico e inventor de pinturas suizo Johann Jacob Diesbach se encuentra trabajando en el laboratorio. ¿Su objetivo? Elaborar una laca rojiza a partir de cochinillas. Sin embargo, el destino es caprichoso, por lo menos para algunos. Tras un tiempo trabajando en la elaboración del pigmento rojizo, casi había conseguido su meta cuando al pobre Diesbach se le truncó el experimento. Se le acabó la ceniza que tenía que emplear para finalizar su labor.
No obstante, no todo acaba ahí. Como en toda buena historia llegó la salvación, con nombre de Johann Conrad Dippel. Dippel, compañero de trabajo, o más bien jefe de Diesbach, le prestó un material de sustitución denominado aceite Dippel, un aceite obtenido mediante la destilación destructiva de huesos. Y funcionó. Bueno, no exactamente.
Aunque su propósito final fuera una laca rojiza, de la mezcla realizada salió un azul excepcional, lo que hoy en día conocemos como el azul de Prusia (Fe7N18C18). Y fue así como nació, por un caso de serendipia, una sustancia azul que ha inspirado a diversidad de artistas en la creación de obras de arte muy conocidas. ¿Sabríais decirme cuáles?
https://culturacientifica.com/app/uploads/2019/06/Johann-Jacob-Diesbach-y-el-azul-prusia.mp4Imagen: Johann Jacob Diesbach y el azul de Prusia (1704). (Animación: Ainhoa Caporossi Esteibar)
Referencias consultadas:- Bartoll, Jens (2008). The early use of Prussian Blue in paintings. 9th International Conference on NDT of Art, Jerusalem Israel, 25-30 Mayo 2008.
- Wikipedia: Azul de Prusia (fecha de consulta: 01/2019).
————————————
Autora: Ainhoa Caporossi Esteibar (@laveceria), alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2018/19
Artículo original: Ensayo sobre el azul. Oskar González, Cuaderno de Cultura Científica, 23 de septiembre de 2017.
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
El artículo Azul… ¿Serendipia? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Nacionalismo, ideología y religión
“Nada mejor para explicar una cosa problemática que inventar otra tan problemática y darla como indiscutible. Es el procedimiento de todas las sectas religiosas”.
Pío Baroja. En «El mundo es ansí», 1912.
“Cuando se trata de controlar a los seres humanos no hay mejor instrumento que las mentiras. Porque los humanos viven según sus creencias y las creencias pueden ser manipuladas.”
Michael Ende.
“La gente se radicaliza porque prefiere sentir a razonar.”
Anna Rosling, 2018.
Creer en algo, sea lo que sea. Lo más popular y extendido en sociedades y culturas es la religión. Juan Ignacio Pérez escribió hace un tiempo en el Cuaderno de Cultura Científica que, a esta necesidad de creer, la ciencia responde con dos hipótesis. La primera afirma que nuestra especie está predispuesta a creer en otros mundos, en seres sobrenaturales, en dioses, en la vida después de la muerte, en todo aquello que las religiones sistematizan y ofrecen a sus seguidores en forma, que conocemos bien, de credo indiscutible.
La religión sería una consecuencia de la habilidad de la especie humana para concretar la relación entre causa y efecto. Y, por ello, si buscamos respuestas a los enigmas que hemos planteado en el párrafo anterior, encontramos la respuesta en milagros, fantasmas o, si se quiere, en la religión. como dice Juan Ignacio Pérez, “las creencias religiosas serían un subproducto del modo en que funciona nuestro cerebro”.
 Actuación de la Orquesta y Coro del Tabernáculo Mormón en Temple Square en el Centro de Conferencias de los Santos de los Últimos Días (Salt Lake City, Utah, Estados Unidos). Fuente: Wikimedia Commons
Actuación de la Orquesta y Coro del Tabernáculo Mormón en Temple Square en el Centro de Conferencias de los Santos de los Últimos Días (Salt Lake City, Utah, Estados Unidos). Fuente: Wikimedia Commons
En consecuencia, Dimitrios Kapogiannis y sus colegas, del Instituto Nacional del Envejecimiento de Baltimore, han buscado en el cerebro las redes neuronales relacionadas con las creencias religiosas. Estas redes se integran en las áreas cerebrales relacionadas con la cognición social, el lenguaje y el razonamiento lógico, y no son específicas solo de la religión.
Obtienen más detalle cuando investigan, con resonancia magnética, el cerebro de voluntarios que se declaran creyentes o no creyentes. Localizan la relación íntima con Dios en la corteza del lóbulo temporal medio, el miedo a Dios en la corteza orbitofrontal, y las dudas sobre la existencia de Dios en el pecuneus del lóbulo parietal. La doctrina religiosa activa las áreas del lenguaje como, por ejemplo, la muy conocida área de Broca.
Para conocer el detalle de esta relación entre cerebro y religión, Michael Ferguson y su grupo, de la Universidad de Utah, lo han estudiado en un caso muy concreto, los mormones. Han escaneado el cerebro de 19 voluntarios que se declaran mormones devotos. Han encontrado que, cuando practican su religión asistiendo a actos de la congregación, se activan el núcleo accumbens, la corteza prefrontal ventromedial, y las regiones frontales relacionadas con la atención.
Algo parecido han encontrado Mario Beauregard y Vincent Paquette, de la Universidad de Montreal, en los cambios del electroencefalograma en monjas carmelitas cuando rezan y alcanzan lo que denominan una experiencia mística. Parece que la devoción activa una asociación entre ideas abstractas, el sistema de recompensa del cerebro y los procesos de atención de emociones. La doctrina motiva la conducta del devoto y la recompensa.
En conclusión, como proponía Juan Ignacio Pérez, las creencias religiosas activan en el cerebro redes de neuronas que ya existían y que provocan atención, cognición, emoción y recompensa que, sabemos, se activan también con otros estímulos diferentes a la religión.
Vamos a por la segunda propuesta del texto de Juan Ignacio Pérez: las creencias religiosas han contribuido a la cohesión de los grupos humanos y, por ello, han ayudado a su supervivencia y, en último término, al éxito evolutivo. Tienen, por tanto, las religiones o, en general, las ideologías un gran valor adaptativo. Hay ejemplos muy antiguos sobre la utilización de la religión para cohesionar grupos o, si se quiere, de pueblos y países enteros. Por ejemplo, Jorg Wagner contaba en 2018 la historia del rey Antíoco I del reino Comagene, ahora en el centro sur de Turquía, que hace más de 2000 años se autoproclamó como dios para mantener unido a su pueblo. Los habitantes tenían dos orígenes, persa y griego, y dos religiones y Antíoco los unió nombrándose dios y creando toda una religión alrededor de su persona.
 Judíos ortodoxos en Jerusalén (Israel). Foto: Blake Campbell / Unsplash
Judíos ortodoxos en Jerusalén (Israel). Foto: Blake Campbell / Unsplash
Incluso, como proponen Jesse Graham y Jonathan Haidt, de la Universidad de Virginia, las personas religiosas se sienten felices y lo son por sentir que pertenecen a una congregación, a un grupo social cohesionado por la religión y su práctica. En resumen, los que siguen una religión forman parte de comunidades organizadas que cooperan y se mantienen en torno a seres sobrenaturales. Veamos algunos ejemplos que ilustran esta segunda propuesta.
La religión simplifica el control aquellos que no cumplen con las reglas de la moralidad en una sociedad. Tanto los incumplimientos, o pecados, como los castigos, infiernos y demás, vienen de dioses sobrenaturales y todopoderosos que se encuentran por encima de todos y de todo. Según Andra Craciun, de la Universidad de Bucarest, las personas religiosas pertenecen a grupos que organizan actividades conjuntas como reuniones donde se pasea, desfila, canta o baila. Estas actividades provocan en quien participa confianza, cooperación y sacrificio. Y también recompensa como encontró Uffe Schjodt, de la Universidad de Aarhus, en Dinamarca, cuando escaneó el cerebro de los que rezan, con la repetición de unos textos ya establecidos. El cerebro lo premia con secreción de dopamina y con bienestar a quienes practican su religión. O a quienes repiten eslóganes en una manifestación o en un partido de fútbol.
Además de supervivencia, para conseguir el éxito evolutivo se necesita una reproducción eficaz, y Ara Norentayan y su grupo, de la Universidad de La Columbia Británica en Vancouver, han comparado los ateos y el número de hijos que tienen con quienes se declaran religiosos. Después de revisar los datos de 82 países han encontrado que, de media, los que asisten a un culto religioso una vez por semana tienen 2.5 hijos mientras que los que no van nunca tienen 1.7 hijos. O, también, en Suiza y en el censo de 2000, los cristianos, hindúes, musulmanes y judíos tienen, de media, 3 hijos, y los judíos ateos tienen 1.5 hijos. Incluso los judíos Haredim, de Israel y más ortodoxos, tienen 6-8 hijos de media.
Lo habitual es que los hijos tengan, en principio, la misma religión que sus padres y, por tanto, los devotos de alguna religión, al tener más hijos que los que no siguen ningún culto, la transmiten a más individuos de la siguiente generación.
Ayuda al éxito en la reproducción, en nuestra cultura, una buena situación económica que lleva a tener más recursos para criar a los hijos. En un repaso en 81 países, las personas que consiguen con rapidez prosperidad económica son los que muestran una creencia más fuerte en el cielo y en el infierno. Sobre todo cuenta la creencia en el infierno. Y, además, rechazan más el fraude fiscal, el soborno, el adulterio y la mentira.
Una de las características psicológicas más interesantes de las personas religiosas es que consideran que sus creencias no se pueden probar por medio de la ciencia, no son falsables en el sentido de Popper. La religión solo se debe basar en la fe de sus seguidores, no en evidencias externas. Lo estudiaron Justin Friesen y sus colegas, de la Universidad de Waterloo, en Canadá, y encontraron que la religión, y también las ideologías políticas, se basan en otros motivos y, sobre todo, en que mantienen una determinada imagen del mundo y son el soporte de una identidad de grupo concreta. Friesen comenta que, cuando se dice que unas creencias religiosas o políticas no son demostrables por la ciencia, no se disgusta a sus seguidores sino que, incluso, se refuerza su aceptación de esas creencias.
Además, de la religión, la ideología también sirve para compactar un grupo. Una de las ideologías políticas más debatidas en estos días es el nacionalismo, por lo que supone en relación con los estados nación actuales como por su fuerza en crear sentimientos y reforzar el grupo de pertenencia. Sin embargo, la definición de nacionalismo no es fácil. Por ejemplo, el Diccionario de la Lengua da dos acepciones: 1. Sentimiento fervoroso de pertenencia a una nación y de identificación con su realidad y con su historia. 2. Ideología de un pueblo que, afirmando su naturaleza de nación, aspira a constituirse como Estado. O en el Diccionario Espasa de Sinónimos y Antónimos de 1997: Nacionalismo: Patriotismo, regionalismo, tradicionalismo, civismo, chauvinismo, patriotería, xenofobia, fanatismo. O, también, en Wikipedia, donde, y según Ernest Gellner, “el nacionalismo es un principio político que sostiene que debe haber congruencia entre la unidad nacional y la política”, o, si se quiere, “el nacionalismo es una teoría de legitimidad política que prescribe que los límites étnicos no deben contraponerse a los políticos”.
 Eugène Delacroix «La libertad guiando al pueblo» (1830). Óleo sobre lienzo, 260 x 325 cm. Sobre esta obra Delacroix escribió: «He emprendido un tema moderno, una barricada, y si no he luchado por la patria, al menos pintaré para ella.» La lucha a la que se refiere es el alzamiento del pueblo de París el 28 de julio de 1830 contra la supresión del parlamento por parte de Carlos X. Fuente: Wikimedia Commons
Eugène Delacroix «La libertad guiando al pueblo» (1830). Óleo sobre lienzo, 260 x 325 cm. Sobre esta obra Delacroix escribió: «He emprendido un tema moderno, una barricada, y si no he luchado por la patria, al menos pintaré para ella.» La lucha a la que se refiere es el alzamiento del pueblo de París el 28 de julio de 1830 contra la supresión del parlamento por parte de Carlos X. Fuente: Wikimedia Commons
Algo parecido define Bert Bonikowsky, de la Universidad de Harvard, con un enfoque más personal: nacionalismo es un grupo de significados subjetivos y de orientaciones afectivas que dan a los individuos un sentido de sí mismos y guían sus interacciones sociales y sus elecciones en política. Para Bonikowsky, el nacionalismo en política y para políticos es, como ideología, un principio político que propone que las unidades nacional y política deben ser congruentes. El mundo debe estar dividido en naciones identificables, que cada persona pertenezca a una nación, y que la nacionalidad del individuo influya en cómo piensa y actúa y siente. En la práctica política, el nacionalismo es una llamada a la lealtad, a la atención y solidaridad del pueblo para cambiar como se ven a sí mismos, movilizar lealtades, promover energías y articular demandas. Para el resto de los ciudadanos, los que no se sienten nacionalistas, el nacionalismo como política crea, a menudo, una percepción de superioridad nacional y una orientación hacia la dominación y, por tanto, el rechazo. Como práctica es un conjunto heterogéneo de prácticas y posibilidades que están disponibles en la vida cultural y política moderna.
Sobre este asunto escribía Javier Elzo en el Deia en 2018: No acabo de ver la distinción entre algo dado, la nación, y un sentimiento, la patria. También la Constitución une ambos conceptos en el mismo artículo: “Artículo 2. La Constitución se fundamenta en la indisoluble unidad de la nación española, patria común e indivisible de todos los españoles”. Como ven, aparecen patria y nación en el mismo párrafo.
Hace unos meses, en noviembre de 2018, en los actos del centenario de la Primera Guerra Mundial, el presidente francés Emmanuel Macron reabrió el debate. Proclamó que “el patriotismo es el exacto contrario al nacionalismo. El nacionalismo es su traición… Diciendo que nuestros intereses primero y qué importan los de otros, se borra lo que una nación tiene de más precioso, lo que la hace vivir, lo que la lleva a ser grande, los más importante: sus valores morales”. También George Orwell avisó, en 1945, que no hay que confundir nacionalismo y patriotismo. En su texto Orwell se refiere, es obvio por el tiempo y lugar en que lo escribe, al nacionalismo supremacista nazi recién derrotado en la Segunda Guerra Mundial al que une, por su experiencia vital, a los comunistas soviéticos. Su definición de nacionalismo lo deja muy claro: “Cuando digo nacionalismo me refiero antes que nada al hábito de pensar que los seres humanos se pueden clasificar como si fueran insectos y que masas enteras integradas por millones o decenas de millones de personas se pueden etiquetar sin problema alguno como “buenas” o “malas”.
Pero, en segundo lugar –y esto es mucho más importante-, me refiero al hábito de identificarse con una única nación o entidad, situando a esta por encima del bien o del mal, y negando que exista cualquier otro deber que no sea favorecer sus intereses.”
Todo lo escrito hasta aquí sobre el nacionalismo quizá ayude a comprender por qué es una ideología que provoca sentimientos tan profundos que, a la vez, ayudan a aumentar la cohesión del grupo social. Sin embargo, tanto la ideología política como la religión pueden llegar al fanatismo y, como escribió Gilbert K. Chesterton en 1910, se llega a “la incapacidad de concebir seriamente la alternativa de una proposición” y, por tanto, “es fanático solamente cuando no puede comprender que su dogma es un dogma, aunque sea verdad”. Así, la ideología, en la práctica, llena el día a día con charlas con y sobre dogmas, rituales simbólicos, compromisos con las instituciones y prácticas a cumplir. Con el nacionalismo como forma civil de religión puede pasar que coloque la nación por encima de otras afiliaciones colectivas.
Fue a principios del siglo XIX, hacia 1830, tal como lo cuenta Karen Armstrong, cuando los nuevos Estados nación provocaron bajo una profunda contradicción: por una parte, eran laicos, pero las nuevas naciones despertaban emociones casi religiosas. En último término, la patria era una manifestación divina, el depósito de la esencia del pueblo y, por tanto, eterna. Daba a los seres humanos la inmortalidad que buscaban porque, la patria, existía desde el inicio del tiempo y continuaría tras su muerte Además, el Estado se había creado para contener la violencia pero la nación se utilizó como argumento para desencadenarla. En fin, si podemos definir lo sagrado como aquello por lo que se está dispuesto a morir, la nación era el valor supremo, lo divino en la tierra.
En ese momento, en el siglo XIX, en el entorno de la aparición del Estado nación que describe Karen Armstrong, cuando Ernest Renan escribió que ni la raza, ni la lengua, ni la religión, ni la geografía bastan para explicar una nación, como resume Marc Bassets en El País, sino que debe suponer un hecho tangible y cotidiano, que los ciudadanos expresen que quieren seguir una vida en común. O, si se quiere, que esa ideología contribuye a la cohesión de las personas en el grupo. O, como de nuevo nos dice Renan, que “existencia de una nación es un plebiscito cotidiano”, aunque se refería a su tiempo, es decir, al Estado nación.
Así, la aceptación de, por ejemplo, la Primera Guerra mundial fue aceptada con entusiasmo. Demuestra lo difícil que es resistirse a las emociones de la religión y, ya hace un siglo, a las del nacionalismo, la nueva fe laica. Es obvio que el nacionalismo llega con facilidad a un fervor casi religioso, especialmente en momentos tensos y emocionales.
Quizá la obsesión, religiosa o política, tenga relación con la química del cerebro. Hay algunas personas que tienden a aceptar creencias sin fundamentos como manías conspiranoicas, lo paranormal o las pseudociencias. Según Katharina Schmack y sus colegas, de la Universidad Médica Charité de Berlín, hay una relación entre la concentración de dopamina, neurotransmisor cerebral, y el apoyo a creencias sin fundamentos científicos.
Trabajan con 102 voluntarios, de ellos 53 son mujeres, y la edad media es de 25 años. A la vez que estudian los genes COMT, que regulan la degradación de la dopamina, les hacen encuestas sobre sus creencias. Los resultados muestran que, cuanto más alta es la concentración de dopamina, mayor es la tendencia a aceptar creencias sin apoyo científico.
 Sala del órgano de la Cueva de Neptuno (Cerdeña, Italia). ¿Qué ves? Fuente: Wikimedia Commons
Sala del órgano de la Cueva de Neptuno (Cerdeña, Italia). ¿Qué ves? Fuente: Wikimedia Commons
Todos tendemos, como cuentan Philipp Sterzet y sus colegas, del Colegio Universitario de Londres, a ver lo que esperamos ver, lo que buscábamos es lo que, a menudo, encontramos. Hay, por tanto, que preguntarse si nuestro sistema de creencias y opiniones se ve sesgado por lo que esperamos, incluso por estados patológicos o por mentiras y engaños de otros. Así, por ejemplo, varios factores influyen en hechos o creencias que nos interesan o nos dejan más o menos indiferentes. Geoffrey Goodwin y John Dailey, de las universidades de Pennsylvania y Princeton, respectivamente, han encontrado que se aceptan con facilidad sucesos negativos como orinar sobre monumentos, mentir o hacer el saludo nazi. Tienen menos aceptación los hechos positivos como salvar a alguien que se ahoga o donar fondos a una ONG. Y todavía menos se puntúa lo que está en debate en la actualidad como el aborto o la eutanasia. Por ello, hay personas que piensan que sus creencias morales son objetivas y, por tanto, hechos verdaderos del mundo real. Y, en cambio, otras aceptan que sus creencias pueden ser, simplemente, preferencias morales personales.
En los debates sobre creencias se interviene para ganarlos o para aprender. En los debates para aprender, una elección personal y subjetiva, se escucha y, a menudo, se llega a un acuerdo. En los debates para ganar, lo importante son los objetivos, los hechos que nos son opiniones ni opinables, se escucha menos y no se consiguen acuerdos. Incluso, en los debates para ganar se tiende a parecer muy objetivo en las argumentaciones ya que, como solo hay una respuesta correcta, las demás están equivocadas. Uno se pregunta si los asuntos políticos en debate tienen una respuesta correcta o si todo es relativo. Estamos en el tiempo del tribalismo creciente.
El mejor debate es el cooperativo, con intención de llegar a un acuerdo, pero no siempre debe ser así. Es inútil el debate cooperativo sobre la homeopatía, o sobre las pseudociencias en general, o sobre el cambio climático o, si se quiere, sobre la existencia del cielo y el infierno. En los debates se debe ser cooperativo pero no equidistante sobre asuntos claramente falsos o indebatibles. En el debate cooperativo o para aprender, más parece que puede haber otras respuestas correctas y que no existe una verdad objetiva.
Es fácil de entender lo que revelan los estudios de Justin Friesen y sus colegas, de la Universidad de Waterloo, en Canadá, cuando aseguran que, muchas personas con una ideología interiorizada, consideran que sus creencias no se pueden, ni quizá deben, probar por la ciencia, con la falsabilidad en el sentido de Popper. En sus encuestas, Friesen y su equipo obtuvieron, para las ideologías, los mismos resultados que para la religión: las personas solo se deben basar en la fe y no en la realidad externa. Las personas con ideología establecida buscan, como la religión, una determinada imagen del mundo, la estabilidad en su modo de vida y, también, el soporte de una identidad concreta para sentirse integradas en un grupo. Cuando se afirma que una religión o una ideología no se pueden demostrar por la ciencia, no se disgusta a sus seguidores sino que, por el contrario, se refuerza su aceptación de esa creencia, sea religión o ideología.
Este rechazo al método científico se basa en lo que Geoffrey Munro, de la Universidad Towson, de Inglaterra, denomina la “excusa de la impotencia científica”. Es el rechazo de cualquier argumento científico en contra de la propia creencia y, además, el rechazo es previo, antes de analizarlo o debatirlo. Y, en último término, provoca la pérdida de credibilidad en el método científico y en la ciencia. Munro propone su hipótesis después de trabajar con 84 universitarios voluntarios y plantearles un debate sobre la homosexualidad en un estudio que, en general, trata de enjuiciar la calidad de la información basada en la ciencia. Así, las propias creencias provocan el rechazo a la ciencia.
Por tanto, hay quien afirma que sus opiniones son las únicas correctas y, además, sienten que lo son porque ellos son los mejor informados sobre ese asunto, sea el que sea, tal como han estudiado Michael Hall y Kaithin Raimi, de la Universidad de Michigan en Ann Arbor. Es curioso que, para los que piensan que sus ideas no son superiores a las de otros, también subestiman sus conocimientos sobre ese asunto. Sin embargo, los que se sienten superiores y que saben mucho, tienden a perder la oportunidad de aprender más. En general, los que sienten que sus creencias son objetivas, o sea, hechos, no debaten pues no ven la necesidad ya que consideran que su opinión es la correcta.
En resumen, quien piensa que su opinión es única y la mejor, pierde oportunidades de aprender más sobre ese tema, es fácil que se convierta en un obstáculo para conseguir que se debata en asuntos políticos.
Y, es evidente, que la interacción social cambia lo que se siente sobre la certeza de las opiniones propias. Los experimentos del grupo de Matthew Fisher, de la Universidad de Yale, muestran que las opiniones debatidas en un grupo que coopera se consideran menos objetivas que si en el grupo se compite por demostrar la verdad. O sea, quien coopera, acepta argumentos sin mayores problemas, y quien compite y no coopera quiere la verdad absoluta para apropiarse de ella.
Nos podemos acercar a la relación entre la religión y la ideología política con los estudios de Paola Bressan y su grupo, de la Universidad de Padua, en Italia, y que comenta Julio Rodríguez en su blog La bitácora del Beagle. Tanto la religiosidad como las ideas conservadoras presentan una dificultad en interpretar lo que se sale de lo habitual o, si se quiere, el azar en el entorno. Las investigaciones de este grupo llevaron a David Amodio y sus colegas, de la Universidad de Nueva York, a estudiar el funcionamiento del cerebro en liberales y conservadores y a concluir que los liberales tienen una onda de potenciales cerebrales que revela mayor sensibilidad para responder a conflictos. Por supuesto, es una propuesta en debate y queda mucho por conocer sobre las diferencias en la neurocognición según la ideología.
Creencias, religión e ideología están relacionadas, por lo menos en el principio de su desarrollo, tal como propone Joseph Henrich, de la Universidad de la Columbia Británica en Canadá. Lo explica Juan Ignacio Pérez en el Cuaderno de Cultura Científica. Una persona con prestigio difunde con más facilidad sus ideas en su grupo. Si, además, está dispuesto a sufrir por sus creencias. Incluso a llegar al martirio, lo conseguirá con más eficacia y difusión. Por ello, al principio de las religiones y de las ideologías con éxito suele haber una persona de prestigio que sufre. A través del sufrimiento, las creencias, la ideología y la religión llegan mejor al grupo. Las derrotas llegan mejor al imaginario popular que las victorias. Como escribe Francisco Javier Caspistegui en un texto sobre la ciudad, el campo y el tradicionalismo español, “la moral de la derrota es un elemento necesario para conseguir el objetivo último, que no es otro que la recuperación de aquello que se juzga más positivo de los buenos viejos tiempos”.
Referencias:
Alonso, J.R. 2019. Religiosidad y teoría de la mente. Neurociencia Blog 2 febrero.
Amodio, D.M. et al. 2007. Neurocognitive correlates of liberalism and conservatism. Nature Neuroscience 10: 1246-1247.
Anónimo. 2019. Nacionalismo. Wikipedia 16 junio.
Armstrong, K. 2015. Campos de sangre. La religión y la historia de la violencia. Paidós. Barcelona. 575 pp.
Atkinson, Q.D. & P. Bourrat. 2011. Beliefs about God, the afterlife and morality support the role of supernatural policing in human cooperation. Evolution and Human Behavior 32: 41-49.
Bassets, M. 2018. Patriotismo, nacionalismo y todo lo contrario. El País 20 noviembre.
Beauregard, M. & V. Paquette. 2008. EEG activity in Carmelite nuns during a mystical experience. Neuroscience Letters 444: 1-4.
Bonikowski, B. 2016. Nationalism in settled times. Annual Review of Sociology 42: 427-449.
Boyer, P. & B. Bergstrom. 2008. Evolutionary perspectives on religión. Annual Review of Anthropology 17: 111-130.
Bressan, P. et al. 2008. Visual attentional capture predicts belief in a meaningful worl. Cortex 44: 1299-1306.
Caspistegui Gorasurreta, F.J. 2002. “Esa ciudad maldita, cuna del centralismo, la burocracia y el liberalismo”: La ciudad como enemigo en el tradicionalismo español. En “Actas del Congreso Internacional Arquitectura, Ciudad e Ideología Antiurbana”, p. 71-86. Escuela Técnica Superior de Arquitectura Universidad de Navarra. Pamplona.
Craciun, A. 2014. Research review regarding religious beliefs and their role in one’s psychological life. Romanian Journal of Experimental Applied Psychology 5: 65-72.
Dawkins, R. 2007. El espejismo de Dios. Ed. Espasa Calpe. Madrid.
Ferguson, M.A. et al. 2018. Reward, salience, and attentional networks are activated by religious experience in devout Mormons. Social Neuroscience 13: 104-116.
Fisher, M. et al. 2016. The influence of social interaction on intuitions of objectivity and subjectivity. Cognitive Science DOI: 10.1111/cogs.12380
Fisher, M. et al. 2018. El tribalismo de la verdad. Investigación y Ciencia mayo: 74-77.
Friesen, J.P. et al. 2014. The psychological advantage of unfalsifiability: The appeal of untestable religious and political ideologies. Journal of Personality and Social Psychology doi: 10.1037/pspp0000018
Gilead, M. et al. 2018. That’s my truth: Evidence for involuntary opinion confirmation. Social Psychological and Personality Science DOI: 10.1177/194855018762300
Goodwin, G.P. & J.M. Darley. 2012. Why are some moral beliefs perceived to be more objective tan others? Journal of Experimental Social Psychology 48: 250-256.
Graham, J. & J. Heidt. 2010. Beyond beliefs: Religions bind individuals into moral communities. Personality and Social Psychology Review 10: 140-150.
Hall, M.P. & K.T. Raimi. 2018. Is belief superiority justified by superior knowledge? Journal of Experimental Social Psychology 76: 290-306.
Henrich, J. 2009. The evolution of costly displays, cooperation and religión: credibility enhancing displays and their implications for cultural evolution. Evolution and Human Behavior 30: 244-260.
Kapogiannis, D. et al. 2009. Cognitive and neural foundations of religión belief. Proceedings of the National Academy of Sciences USA 106: 4876-4881.
Kapogiannis. D. et al. 2009. Neuroanatomical variability of religiosity. PLOS ONE 4: e7180.
Kapogiannis, D. et al. 2014. Brain networks shaping religious belief. Brain Connectivity 4: 70-79.
Kramer, P. et al. 2011. Belief in God and in strong government as accidental cognitive by-products. Behavioral and Brain Sciences 34: 31-32.
Munro, G.D. 2010. The scientific impotence excuse: Discounting belief-threatening scientific abstracts. Journal of Applied Social Psychology 40: 579-600.
Norenzayan, A. et al. 2016. The cultural evolution of prosocial religions. Behavioral and Brain Sciences 39: 1-65.
Orwell, G. 1945. Notas sobre el nacionalismo. Polemic: A Magazine of Philosophy, Psychology & Aesthetics 1: octubre.
Pérez, J.I. 2017. El terrorismo como sacerdocio. Cuaderno de Cultura Científica 15 mayo.
Pérez, J.I. 2017. ¿Nacidos para creer? Cuaderno de Cultura Científica 29 mayo.
Purzycki, B.G. et al. 2016. Moralistic gods, supernatural punishment and the expansion of human sociality. Nature doi: 10.1038/nature16980
Rodríguez, J. 2018. Una unión psicológica entre religión y política. La bitácora del Beagle Blog SciLogs 11 diciembre.
Schjodt, U. et al. 2008. Rewarding prayers. Neuroscience Letters 443: 165-168.
Schmack, K. et al. 2015. Linking unfounded beliefs to genetic dopamine availability. Frontiers in Human Neuroscience 9: 521.
Sterzer, P. et al. 2008. Believing is seeing: expectations alter visual awareness. Current Biology 18: R697-R698.
Wagner, J. 2018. Antíoco I: la religión como instrumento de cohesión social. Investigación y Ciencia abril: 68-74.
Sobre el autor: Eduardo Angulo es doctor en biología, profesor de biología celular de la UPV/EHU retirado y divulgador científico. Ha publicado varios libros y es autor de La biología estupenda.
El artículo Nacionalismo, ideología y religión se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas: