

Revistas predadoras y la Ley de Goodhart

Ilustración de Dusan Petricic
Cuando una medida se convierte en un objetivo deja de ser una buena medida, dice la Ley de Goodhart, bien conocida en el campo de la sociología. Y si lo pensamos un poco es lógico:Los humanos somos, bueno, humanos, de manera que consciente o inconscientemente tendemos a tomar el camino del mínimo esfuerzo hacia el cumplimiento de nuestros objetivos. Si el objetivo es una medida concreta buscaremos la manera de alcanzarla con el menor coste para nosotros, tenga o no tenga sentido desde el punto de vista de la intención original; como en el viejo chiste soviético, si el objetivo de la factoría es hacer 1.000 toneladas de tornillos podemos cumplirlo fabricando un único tornillo de 1.000 toneladas, aunque sea perfectamente inútil y absurdo en el contexto de la planificación global. Y si en algo somos buenos los humanos es en buscar atajos, simplificaciones, recortes y reinterpretaciones para justificar casi cualquier manipulación de esta clase.
Por eso cualquier medida que se designa como objetivo es susceptible de ser retorcida del modo más torticero posible, y por eso deja de ser una buena medida de lo que ocurre en el sistema: porque automáticamente deja de tener valor como indicación objetiva de su estado. Esta es la razón de que el número de publicaciones se haya convertido en una pésima medida del estado de un sistema de investigación, y de la existencia de un nuevo fenómeno como son las famosas ‘revistas predadoras’. Un resultado previsible según la ley de Goodhart.
Si el modo de avanzar en lo profesional y de recibir mejor financiación para la investigación científica es aumentar el número de publicaciones (maximizar esta medida en particular) los científicos se encuentran con un poderoso incentivo para manipular esta variable. Si pueden estirar los resultados de un experimento a tres publicaciones en lugar de a una, lo harán; si pueden maximizar los resultados de su tesis en términos de número de artículos publicados tienen que hacerlo. Si lo que cuenta a la hora de obtener un puesto de trabajo o de conseguir una beca es el número de artículos publicados quien no lleve a cabo este tipo de estrategias resultará perjudicado en la carrera y se quedará atrás. Las plazas, y los proyectos, serán para quien sí lo haga.
Aquí es donde surgen las ‘revistas predadoras’, que simplemente aprovechan esta necesidad de millones de investigadores de todo el mundo para sacar dinero. Lo que ofrecen es simple: publicar artículos de baja o nula calidad de modo rápido y sin muchas preguntas a cambio de dinero. Muchos investigadores cuentan con presupuestos para publicar, ya que algunas revistas (incluso de la máxima calidad) cobran por la publicación. Estas ‘revistas predadoras’ tan sólo obvian la parte cara del asunto: la revisión por pares, el análisis de calidad previo, y proporcionan una vía para a cambio de dinero añadir de modo sencillo una línea al currículo. Dotadas de nombres rimbombantes que suenan legítimos, con frecuencia radicadas en países como China o la India y a veces complementadas por congresos y seminarios de nombre impresionante y calidad nula estas revistas cubren un nicho de mercado: el de los investigadores desesperados por cumplir con el requisito de número de publicaciones que se les impone.
El resultado, por supuesto, es que el sistema completo deja de funcionar. Los criterios de calidad casi han desaparecido reemplazados por criterios basados en la pura cantidad; el dar mayor puntuación a las revistas de alto impacto no basta, porque ahora es el impacto de las revistas lo que se ha pervertido (siguiendo la Ley de Goodhart). Los currículos se alargan y en el fárrago de publicaciones resulta muy difícil separar el grano (las revistas serias que son leídas por otros científicos) de la paja (las predadoras que nadie lee). Los requisitos de mínimos se hacen astronómicos, como los recientes de la ANECA española que de media exigen 130 artículos para cualificarse para la categoría de catedrático. Y la medida, que se supone que sirve para garantizar una producción científica razonable, se hace completamente irrelevante e incluso contraproducente. Hasta tal punto que ahora es necesario luchar contra la proliferación de ‘revistas predadoras’ que, como malas hierbas, amenazan con ahogar el sistema científico convencional.
Sobre el autor: José Cervera (@Retiario) es periodista especializado en ciencia y tecnología y da clases de periodismo digital.
El artículo Revistas predadoras y la Ley de Goodhart se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Flujo de manuscritos entre revistas científicas
- La contradicción de la publicación
- Qué es un dato: la longitud de un hueso
Algo raro pasa alrededor de Gliese 436
En el imaginario colectivo los planetas de un sistema solar giran alrededor de su estrella en el mismo plano, y este plano es también el plano ecuatorial de la estrella. La estrella también gira, y su eje de giro se alinea con los ejes de giro de las órbitas planetarias, dando la impresión de un sistema bien ordenado. Pero el universo es caprichoso en sus creaciones.

Gliese 436 es una estrella de la que se ha escrito mucho, ya que alberga un planeta del tamaño de Neptuno, Gliese 436b, que se evapora como un cometa. En una investigación cuyos resultados se publican ahora en Nature, un equipo de investigadores encabezados por Vincent Bourrier, de la Universidad de Ginebra (Suiza), demuestran que, además de su enorme nube de gas, el planeta Gliese 436b también tiene una órbita muy especial. Es “polar”: en lugar de orbitar en el plano ecuatorial de la estrella, el planeta pasa casi por encima de los polos estelares.
La inclinación orbital es la última pieza de un rompecabezas que ha desconcertado a los astrónomos durante 10 años: a diferencia de los planetas del Sistema Solar cuyas órbitas forman círculos casi perfectos (aunque sean en realidad elipses), la de Gliese 436b forma una elipse muy plana, es decir, su distancia a la estrella varía mucho a lo largo de su órbita.
Gliese 436b está sometido a enormes fuerzas de marea porque pasa increíblemente cerca de su estrella, apenas el 3% de la distancia que separa la Tierra del Sol. La estrella Gliese 436 es una enana roja cuya vida activa es muy larga, por lo que las fuerzas de marea que induce deberían haber conseguido haber acercado la órbita del planeta a un círculo pero, por alguna razón, no lo ha hecho.
¿Y cual podría ser la causa?
Las arquitecturas orbitales de los sistemas planetarios son registros fósiles que nos dicen cómo se han formado y evolucionado. Un planeta perturbado por el paso de una estrella cercana o por la presencia de otros planetas masivos en el sistema mantendrá un registro, por así decirlo, en su órbita. La existencia de un planeta desconocido, más masivo y distante que lo perturbase explicaría no solo por qué Gliese 436b no está en una órbita circular, sino también por qué está en una órbita polar.
Los mismos cálculos que apuntan a esta conclusión también predicen que el planeta no siempre ha estado tan cerca de su estrella, sino que podría haberse acercado recientemente (en términos astronómicos). Por lo tanto, el “planeta que se evapora” no siempre se habría evaporado, sino que habría sido empujado hacia la estrella por la gravedad de un planeta compañero aún no detectado. La caza no ha hecho más que empezar.
Referencia:
Vincent Bourrier et al (2017) Orbital misalignment of the Neptune-mass exoplanet GJ 436b with the spin of its cool star Nature doi: 10.1038/nature24677
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
Este texto es una colaboración del Cuaderno de Cultura Científica con Next
El artículo Algo raro pasa alrededor de Gliese 436 se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La habitabilidad de las exotierras alrededor de estrellas enanas rojas
- ¿Qué pasa si me río de todo?
- Catástrofe Ultravioleta #16 RARO
¡Es la Aritmética!
El niño y los sortilegios es una fantasía lírica (en dos partes para solistas y coros con orquesta) de Maurice Ravel sobre un libreto de la escritora Sidonie Gabrielle Colette. Se estrenó en Montecarlo el 21 de marzo de 1925 y, un año más tarde, se presentó en el Teatro de la Ópera Cómica de París.

Portada diseñada por André Hellé para la primera edición de la ópera. Imagen: Wikipedia.
{kind=link}
En 1916, Jacques Rouché, en ese momento el director de la Ópera de París, solicitó a su amiga Colette que escribiera un libreto para ballet, de ambiente fantástico, sobre los sueños de un niño perseguido por animales y objetos por él maltratados: Ballet pour ma fille. Ravel fue elegido para musicalizar la historia. Pero, debido a problemas personales, abandonó el proyecto hasta 1919, año en que retomó el libreto y descubrió sus posibilidades, decidiendo crear una ópera y no un ballet.
El niño y los sortilegios es una sucesión de cuadros independientes que mezclan diferentes géneros musicales: jazz, foxtrot, ragtime, polka, dúo maullador, vals y música coral. Para reproducir las numerosas onomatopeyas del libreto de Colette, Ravel utilizó instrumentos poco habituales, como un rallador de queso, una carraca con manivela, crótalos, bloques de madera, látigo,…
La obra tiene lugar en el interior de una casa en Normandía. El protagonista, el niño, intenta, con pereza, hacer sus deberes. A ver que las tareas no están terminadas, la madre castiga al niño dejándole como merienda una taza de té y un trozo de pan duro. Al quedarse solo, el protagonista demuestra su enojo rompiendo objetos y maltratando a los animales domésticos. Aburrido, se recuesta sobre un sillón; en ese momento entran en acción los sortilegios a los que alude el título: el sillón comienza a danzar con una silla, los muebles lo imitan enfadados con el protagonista,… El niño, atemorizado, llora. De las páginas de un libro por él destrozado acude una princesa a consolarlo, aunque le reprocha su conducta. Ella desaparece para ocupar su lugar un viejo amenazante, que le plantea problemas matemáticos para resolver: es la Aritmética. Sale la luna, el gato y la gata se unen en un ceremonioso dueto amoroso. Los animales que habitan el jardín desafían y amenazan al niño: entablan extraños diálogos, realizan frenéticas danzas, con tanta euforia que hieren a una ardilla. El niño, conmovido, ayuda al roedor. El resto de los animales, al ver el acto de compasión del protagonista, comienzan a dudar de su maldad. Lo acompañan hasta la casa, finalizando de este modo los sortilegios: el niño regresa al mundo real, reclamando a gritos la presencia de su madre.
En una de las escenas, las matemáticas son las encargadas de atormentar al niño.
[…] (Los patea. Voces chillonas salen de entre las páginas que dejan ver a las gesticulantes figuritas de los números. De un álbum abierto como un techo, salta un viejecillo jorobado, de nariz ganchuda, barbado, vestido con números, sombrero en forma de “pi”, ceñido con una cinta métrica y armado con una regla. Sostiene un libro de madera que golpea cadenciosamente. Baila mientras recita fragmentos de problemas.)
EL VIEJECILLO: ¡Dos grifos de agua fluyen a un tanque! ¡Dos ómnibus dejan una estación a veinte minutos de intervalo, valo, valo, valo! ¡Una campesina, sina, sina, sina, lleva todos sus huevos al mercado! ¡Un mercader de telas, telas, telas, telas, vende seis metros de trapo! (ve al niño y se le acerca de una manera malévola.)
EL NIÑO: (aterrado) ¡Dios mío! ¡Es la Aritmética!
EL VIEJECILLO, LOS NÚMEROS: ¡Tica, tica, tica! (Danzan alrededor del niño multiplicando sus maléficos pases.) Once más seis: ¡veinticinco! Cuatro más cuatro: ¡dieciocho! Siete por nueve: ¡treinta y tres!
EL NIÑO: (sorprendido) ¿Siete por nueve, treinta y tres?
LOS NÚMEROS: (levantando las hojas y chillando) Siete por nueve: ¡treinta y tres! etc.
EL NIÑO: (con audacia) Tres por nueve: ¡cuatrocientos!
EL VIEJECILLO: (balanceándose para mantener el ritmo) Milímetro, centímetro, decímetro, decámetro, hectómetro, kilómetro, miriámetro. ¡Sin fallar! ¡Qué felicidad! ¡Millones, billones, trillones, y fracciones!
LOS NÚMEROS, EL VIEJECILLO: ¡Dos grifos de agua fluyen a un tanque! etc.
LOS NÚMEROS: (hacen bailar al niño con ellos) Tres por nueve: ¡treinta y tres! Dos por seis: ¡veintisiete! ¿Cuatro más cuatro?… ¿Cuatro más cuatro?…Cuatro por siete: ¿cincuenta y nueve? Dos por seis: ¡treinta y uno! Cinco por cinco: ¡cuarenta y tres! Siete más cuatro: ¡cincuenta y cinco! (Giran desenfrenadamente. El niño, aturdido, cae al suelo. El Viejecillo y el coro se retiran.) Cuatro más cuatro: ¡dieciocho! Once más seis: ¡veinticinco!
(El niño se sienta con dificultad. La luna ilumina la habitación. El gato negro se desliza bajo el sillón. Se estira, bosteza y se relame. El niño no lo ve pues, cansado, tiene la cabeza apoyada en un taburete. El gato juega, haciendo rodar una bola de estambre. Se acerca al niño e intenta jugar con su cabeza rubia como si fuera una pelota.)
EL NIÑO: ¡Oh! ¡Mi cabeza! ¡Mi cabeza! […]
Es una lástima que las matemáticas se perciban sistemáticamente como una ‘maldición’… ¡incluso en la ópera!
Os dejo debajo la original versión de Giovanni Munari y Dalila Rovazzani, de esta escena de El niño y los sortilegios:
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo ¡Es la Aritmética! se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Sistemas respiratorios: los pigmentos respiratorios

Cangrejo (Cancer productus ) visto desde abajo. El color púrpura lo proporciona la hemocianina, un pigmento respiratorio.
Llamamos pigmentos respiratorios a un grupo de proteínas que tienen la propiedad de combinarse de forma reversible con oxígeno molecular. Por esa razón, pueden transportar oxígeno, captándolo en un lugar y liberándolo en otro. Todos los pigmentos respiratorios son metaloproteínas, o sea, proteínas que contienen átomos metálicos. Y los llamamos pigmentos porque, al menos en algunos momentos, tienen un color intenso.
El O2 tiene una solubilidad relativamente baja en agua, por lo que es muy limitada la capacidad de las disoluciones acuosas, como son la hemolinfa o el plasma sanguíneo, para transportar oxígeno. Gracias a los pigmentos respiratorios de los que los animales se han dotado, la capacidad de la sangre o equivalente para transportarlo es muy superior a la que tendrían sin ellos, y pueden satisfacer las necesidades que se derivan de altos niveles de actividad metabólica. Para hacernos una idea de lo que representa su contribución, 100 ml de sangre humana contienen, al salir del pulmón, 0,4 ml de O2 en forma disuelta y 19,6 ml combinados con la hemoglobina. O sea, la denominada capacidad de oxígeno de la sangre se multiplica por cincuenta gracias a su pigmento. Es cierto que los mamíferos somos los animales en los que la contribución del pigmento es máxima y que en otros puede ser muy inferior, pero en cualquier caso, se trata de una contribución importante.
Cuando un pigmento respiratorio se encuentra combinado con el oxígeno decimos que está oxigenado y, en caso contrario, que está desoxigenado. No utilizamos los términos oxidado y reducido para denominar esos dos estados alternativos. La combinación del oxígeno con un pigmento no es químicamente equivalente a una oxidación. En una oxidación los electrones de los átomos metálicos del pigmento son parcialmente transferidos a la molécula de oxígeno, pero no es una transferencia completa como la que ocurre en una oxidación. De hecho, si la molécula de pigmento se oxidase realmente perdería su capacidad para transportar oxígeno. Utilizamos los prefijos oxi- y desoxi- para denominar a las dos formas del pigmento: oxihemoglobina y desoxihemoglobina, por ejemplo. Hay cuatro tipos o categorías de pigmentos respiratorios: hemoglobinas, hemocianinas, hemeritrinas y clorocruorinas. Cada una de esas categorías agrupa a compuestos relacionados, no a estructuras químicas únicas.
Existen notables similitudes entre la forma en que los pigmentos respiratorios se unen al oxígeno y la forma en que las enzimas se unen a sus sustratos. En ambos casos la unión ocurre en sitios específicos, y se produce mediante enlace débil no covalente. Al unirse el O2 con el pigmento, este modifica ligeramente su conformación, como ocurre con las enzimas. Igualmente, en ambos casos cabe hablar de afinidad, que en este caso refleja la facilidad con la que el oxígeno se une al pigmento. Los pigmentos se puede unir con otras sustancias, también en sitios específicos, y esa unión modifica sus propiedades y la facilidad con que se combina con el oxígeno; a esas sustancias se las denomina moduladores alostéricos. Las moléculas de pigmento suelen estar formadas por dos o más subunidades. Las subunidades son proteínas unidas entre sí mediante enlaces no covalentes. Cada subunidad tiene un sitio de unión para el oxígeno y muestran cooperatividad entre los sitios de unión de las diferentes subunidades. Quiere ello decir que la unión de una molécula de oxígeno al sitio de unión de una subunidad, modifica la facilidad con la que otros sitios se combinan con otras moléculas de O2. Esas variaciones se producen como consecuencia de los cambios conformacionales antes citados.
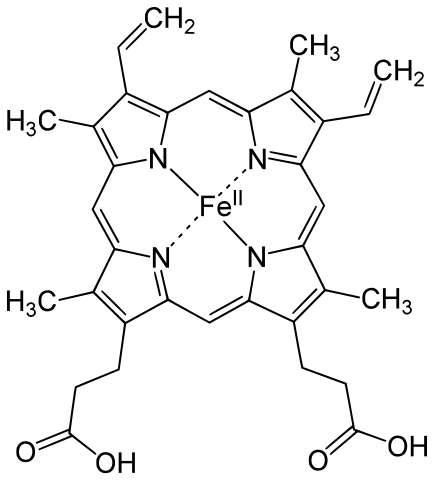
Grupo hemo
Las hemoglobinas y las clorocruorinas consisten en largas cadenas de aminoácidos (globinas) unidas de forma no covalente a sendos grupos prostéticos (grupos hemo) que son metaloporfirinas. El grupo prostético es común a todos los pigmentos de una misma categoría, ya sean hemoglobinas o clorocruorinas, y es ahí donde se produce la unión con el oxígeno. Los pigmentos de una misma categoría difieren en las cadenas polipeptídicas. De hecho, la diversidad de propiedades y funciones de unas y otras hemoglobinas, por ejemplo, tiene su origen en las diferentes estructuras de sus cadenas. Los grupos hemo de las hemoglobinas y de las clorocruorinas son metaloporfirinas en las que el metal es el hierro. Las clorocruorinas tienen la particularidad de ser verdes en disoluciones diluidas y rojas en concentradas. Las hemoglobinas son rojas. Las hemocianinas son la segunda categoría pigmentaria más común. A diferencia de hemoglobinas y clorocruorinas, no tienen grupo hemo. Y además, en vez de hierro contienen cobre, que se encuentra unido directamente a la proteína. El sitio de unión con la molécula de O2 contiene dos átomos de metal. Cuando se encuentran desoxigenadas carecen de color, y cuando están combinadas con el O2 son azules. Por último tenemos las hemeritrinas, que, como las hemocianinas, carecen de grupo hemo. El metal de estas es el hierro, también ligado directamente a la proteína.
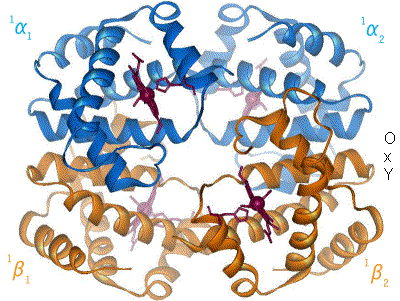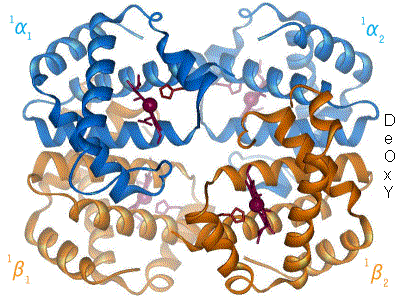
Esquema básico de la hemoglobina humana. Se muestran las dos parejas de globinas, α y β, y los cambios de estructura al enlazarse el oxígeno (no mostrado)
El pigmento respiratorio mejor conocido es la hemoglobina humana. La de un individuo adulto consta de cuatro subunidades (se dice que es tetramérica) cuyas globinas están formadas por algo más de 140 aminoácidos. Se conocen más de un centenar de formas mutantes, la mayoría de las cuales solo difiere de la forma normal en un único aminoácido. El peso molecular de las subunidades se encuentra entre 16000 y 17000 daltons. La sangre adulta contiene dos tipos de globinas, denominadas α (141 aminoácidos) y β (146 aminoácidos), de manera que en una molécula de hemoglobina hay dos de cada tipo. Hemos especificado que los datos anteriores corresponden a la hemoglobina de personas adultas, porque a lo largo del desarrollo, desde la fase embrionaria hasta semanas después del nacimiento, cambian de manera notable su composición y características. En otras especies no es raro que coexistan más de una variedad de hemoglobina en la sangre, cada una con diferentes características en lo relativo a su unión con el O2; esa variedad permite a los animales que la poseen transportar oxígeno en un amplio rango de condiciones ambientales.
Fuentes:
Richard W. Hill, Gordon A. Wyse & Margaret Anderson (2004): Animal Physiology. Sinauer Associates, Sunderland
John D. Jones (1972): Comparative physiology of respiration. Edward Arnold, Edinburgh
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Sistemas respiratorios: los pigmentos respiratorios se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Sistemas respiratorios: los límites a la difusión de los gases
- Sistemas respiratorios: la emergencia de un doble sistema circulatorio
- Sistemas respiratorios: la ventilación de los pulmones de mamíferos
El principio de constancia de la velocidad de la luz
El principio de relatividad es uno de los dos postulados a partir de los cuales Einstein derivó las consecuencias de la teoría de la invariancia, popularmente llamada de la relatividad. El otro postulado se refiere a la velocidad de la luz, y es especialmente importante cuando se comparan las observaciones entre dos marcos de referencia inerciales, aquellos marcos de referencia que están en reposo o se mueven con una velocidad uniforme relativa entre sí, ya que dependemos principalmente de la luz para hacer observaciones.

Cuando Einstein dejó la secundaria a la edad de 15 años, estudió por su cuenta para poder ingresar en el Instituto Politécnico Federal de Zúrich (Suiza). Probablemente fue durante esta época cuando Einstein consideró por primera vez un experimento mental importante. Se preguntó qué pasaría si pudiera moverse lo suficientemente rápido en el espacio como para alcanzar un rayo de luz. Maxwell había demostrado que la luz es una onda electromagnética que se propaga a la velocidad de la luz. Si Albert pudiera viajar en paralelo y a su misma velocidad no vería una onda propagándose. En cambio, vería los “valles” y las “crestas” de la onda fija y estacionaria con respecto a él. Esto contradecía la teoría de Maxwell, en la que no era posible ese paisaje “estacionario” en el espacio libre. De estas y otras consideraciones principalmente teóricas, Einstein concluyó en 1905 que la teoría de Maxwell debía ser reinterpretada: la velocidad de la luz tiene que ser exactamente la misma, debe ser una constante universal, para todos los observadores, independientemente de si se mueven (con velocidad constante) respecto a la fuente de la luz. Esta idea revolucionaria se convirtió en el segundo postulado de la relatividad especial de Einstein, el principio de constancia de la velocidad de la luz:
La luz y todas las demás formas de radiación electromagnética se propagan en el espacio vacío con una velocidad constante c que es independiente del movimiento del observador o del cuerpo emisor.
Lo que Einstein está diciendo es que ya estemos moviéndonos a una velocidad uniforme hacia, o alejándonos de una la fuente de luz, o de si nos movemos en paralelo o no a un haz de luz, siempre mediremos exactamente el mismo valor para la velocidad de la luz en el vacío, que es exactamente de 299.792.458 m/s [1] . A esta velocidad se le dio el símbolo c de “constante”. Si la luz viaja a través del vidrio o el aire su velocidad será algo más lenta, pero la velocidad de la luz en el vacío es una de las constantes físicas universales.
Es importante recordar que este principio solo se aplica a los observadores y las fuentes que están en marcos de referencia inerciales. Esto significa que se están moviendo a una velocidad uniforme o están en reposo uno con relación al otro [2].
Veamos una implicación inmediata de este principio tan simple, en el que empiezan a intuirse las peculiaridades de la teoría de la invariancia que la apartan de nuestro sentido común. Para ello hagamos unos pocos experimentos mentales muy sencillos.
Imaginemos que Mónica está sobre una plataforma con ruedas moviéndose a una velocidad uniforme de 5 m/s hacia Esteban, que permanece estático en el suelo. Mientras Mónica se mueve, arroja una pelota de tenis a Esteban a una velocidad para Mónica de 7 m/s. Esteban la atrapa, pero justo antes de hacerlo, rápidamente mide su velocidad [3]. ¿Qué velocidad obtiene? La respuesta, obviamente, es 5 +7 = 12 m/s, ya que las dos velocidades se suman.
Hagamos otro experimento. Mónica está en la plataforma alejándose a 5 m/s de Esteban. Nuevamente lanza la pelota a 7 m/s para ella a Esteban, quien nuevamente mide su velocidad antes de atraparla. ¿Qué velocidad mide ahora? Esta vez es -5+7 = 2 m/s, donde hemos adoptado la convención de que las cosas que se mueven hacia Esteban tienen velocidad de signo positivo y las que se alejan de signo negativo. Las velocidades se suman de nuevo [4]. Todo muy convencional e intuitivo.
Ahora intentemos estos mismos experimentos usando rayos de luz en lugar de pelotas de tenis. Cuando Mónica se mueve hacia Esteban, le apunta con el haz de un lápiz láser [5]. Esteban tiene un detector de luz que también mide la velocidad de la luz. ¿Qué velocidad de la luz mide? Mónica y Esteban se sorprenden al descubrir que Einstein tenía razón: la velocidad es exactamente la de la luz, ni más ni menos [6]; la velocidad de la plataforma no se ha añadido a c. Obtienen la misma velocidad c cuando la plataforma se aleja de Esteban. De hecho, incluso si aumentan la velocidad de la plataforma hasta casi la velocidad de la luz misma [3], la velocidad de la luz medida sigue siendo la misma, c,en ambos casos. Por extraño que parezca, la velocidad de la luz (o de cualquier onda electromagnética) siempre tiene el mismo valor, c,sin importar la velocidad relativa de la fuente y el observador.
En las próximas entregas veremos algunasde las consecuencias a las que llegó Einstein cuando juntó los dos postulados fundamentales de la teoría de la relatividad especial, el principio de relatividad y el principio de constancia de la velocidad de la luz en el vacío.
Notas:
[1] La exactitud de esta cifra es una convención moderna, ya que la unidad de longitud se deriva de la velocidad de la luz.
[2] El autor comprende que se pone pesado con estas repeticiones, y pide disculpas por ello. Pero considera imprescindible que la persona que lea cualquiera de estas entregas independientemente del resto sea en todo momento consciente de los límites de aplicación de las ideas que se discuten.
[3] Una licencia que permite el hecho de que esto solo sea un experimento mental
[4] Las restas no existen, son siempre sumas, lo que cambia es el signo de los factores.
[5] Asumimos que Mónica evita los ojos de Esteban y que ambos usan protección ocular adecuada durante el experimento.
[6] Despreciamos el pequeñísimo, pero no nulo, efecto del aire sobre la velocidad de la luz para no tener que realizar el experimento en el espacio.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo El principio de constancia de la velocidad de la luz se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El principio de relatividad (y 4): la versión de Einstein
- El principio de relatividad (2): la versión de Galileo
- El principio de relatividad (1): movimiento relativo
El filósofo que baila con las sepias
Antonio Martínez Ron, lector

Encontrar un libro de filosofía que se entienda y que además te atrape con su lectura no es fácil en los tiempos que corren. Y eso es lo que consigue Peter Godfrey-Smith con “Otras mentes. El pulpo, el mar y los orígenes profundos de la consciencia”, publicado por Taurus. Uno de los principales méritos del libro es precisamente el de centrarse en un asunto que no suele ser tema de conversación en el ascensor y convertirlo en algo apasionante. Durante más de 200 páginas el autor nos adentra en la evolución de los sistemas nerviosos y la naturaleza misma de la consciencia a partir de su experiencia con los cefalópodos. ¿Se imagina usted enfrascado en las andanzas de pulpos y sepias en el fondo del mar? Al principio yo tampoco, y terminé lamentando que se el libro se acabara tan rápido.
“Otras mentes” es un libro escrito por alguien que sabe de biología y además sabe pensar, una tarea para lo que la mayoría de nosotros ni sacamos tiempo ni estamos entrenados. Se agradece su sencillez y lucidez a la hora de explicar los procesos evolutivos que han llevado a los seres vivos a desarrollar diferentes soluciones para navegar por el mundo e interactuar con el entorno. Su comprensión sobre estos procesos es tan profunda que uno tiene la impresión de que los explica con más destreza que muchos especialistas con años de divulgación a sus espaldas.
El libro es un soplo de aire fresco por muchos motivos, pero el principal es la magistral mezcla entre dos campos del conocimiento, biología y filosofía, que deberían solaparse con más frecuencia de lo que estamos acostumbrados. A partir de lo que le han enseñado los pulpos en sus horas de inmersión en aguas australianas, Godfrey-Smith es capaz de hacernos pensar en lo que somos nosotros mismos y en lo que otorga al pensamiento consciente su singularidad. Para ello no nos habla de las frías abstracciones y enrevesadas entelequias a las que nos tienen habituados la mala filosofía y la mala neurociencia, sino que toma un punto de partida terrenal y cercano: ¿cómo integran otros seres sus experiencias sensoriales? ¿Cómo sería estar dentro del cuerpo de otra criatura, si es que acaso esto significa algo?
El resultado es como asomarse a un abismo en el que el artificio del “yo” se desvanece por momentos ante la certidumbre de que existen otras integraciones sensoriales cuya naturaleza no terminamos de entender, un viaje fascinante entre sepias con nombres de pintores expresionistas, pulpos que escupen a sus captores y calamares que nos miran con el interés que lo haría un alienígena. Y, sobre todo, un pequeño ejercicio de humildad para recordarnos que no somos únicos y que quizá la vida muestra una particular tendencia a crear sistemas conscientes, no solo aquí, sino en otros rincones del universo.
Ficha:
Autor: Peter Godfrey-Smith
Título: Otras mentes. El pulpo, el mar y los orígenes profundos de la consciencia
Año: 2017
Editorial: Taurus / Colección: Pensamiento
En Editoralia personas lectoras, autoras o editoras presentan libros que por su atractivo, novedad o impacto (personal o general) pueden ser de interés o utilidad para los lectores del Cuaderno de Cultura Científica.
El artículo El filósofo que baila con las sepias se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Jan van Helmont, filósofo por el fuego (1)
- Las cartas de Darwin: El capitán y el filósofo
- ¿Es el universo un holograma?, y otras grandes preguntas de la ciencia actual
¿Y si el cambio climático nos termina haciendo a todos más simpáticos?

Foto: Pxhere
Tienen las personas nacidas en el sur de España fama de ser alegres, abiertas a lo nuevo, amistosas y ‘echás p’alante’, especialmente comparadas con las del norte, más reservadas, calmadas, y conservadoras. En esto se mezclan los tópicos y las costumbres. También se mezcla la ciencia: según un estudio reciente, la temperatura del lugar en el que crecemos modela nuestro hábitos y con ello nuestra personalidad.
Esto nos sorprende apenas, porque la idea de que el clima afecta a nuestro estado de ánimo no es una novedad: está demostrado que los meses de invierno, más fríos y oscuros, generan estados similares a la depresión, especialmente en países nórdicos donde la luz del sol pasa meses en los que apenas brilla, mientras que al volver el calor los ánimos se elevan y nos sentimos llenos de energía.
El nuevo estudio sugiere que la cosa tiene mucha más miga de la que creíamos, y que el clima puede incluso modelar nuestra personalidad, y esto tendría una consecuencia inesperada: ¿si sigue avanzando el cambio climático, cambiará también nuestra personalidad?

Si tuviésemos que quitar paladas de nieve para salir de casa por las mañanas, ¿seríamos más huraños? Foto: US Air Force.
Pero vayamos por partes. Investigaciones anteriores ya habían señalado que muchos aspectos de la personalidad humana varían de una región geográfica a otra: unas culturas son más acogedoras que otras, unas disfrutan más las actividades en el exterior que otras, unas disfrutan más relacionándose con otras personas que otras… Las causas de estas diferencias era lo que aun estaba por aclarar.
Una posible explicación es la temperatura media a la que viven las distintas culturas. Eso es lo que apunta este estudio, realizado por científicos de la Universidad de Pekín: que puesto que la temperatura es una cosa que varía de forma muy marcada a lo ancho y sobre todo a lo alto del globo, impacta en la personalidad de la gente a través de su influencia en sus hábitos cotidianos. No se trata, según los autores, de mirar simplemente si las personas han crecido en climas fríos o calientes; también de si lo han hecho en climas templados (unos 22 grados de media) o extremos, ya sea por arriba o por abajo.
El paper contempla de hecho dos estudios distintos, llevados a cabo en dos países enormes pero muy diferentes, Estados Unidos y China, para evitar que en las conclusiones se mezclasen otros factores, como las diferencias culturales o económicas que también pudiesen afectar a la personalidad de las personas. Analizaron datos de 5.500 personas de 59 ciudades chinas diferentes, y de 1,66 millones de personas de 12.500 códigos postales estadounidenses. Trazaron relaciones entre sus respuestas a tests de personalidad y las temperaturas medias de los lugares donde habían crecido.
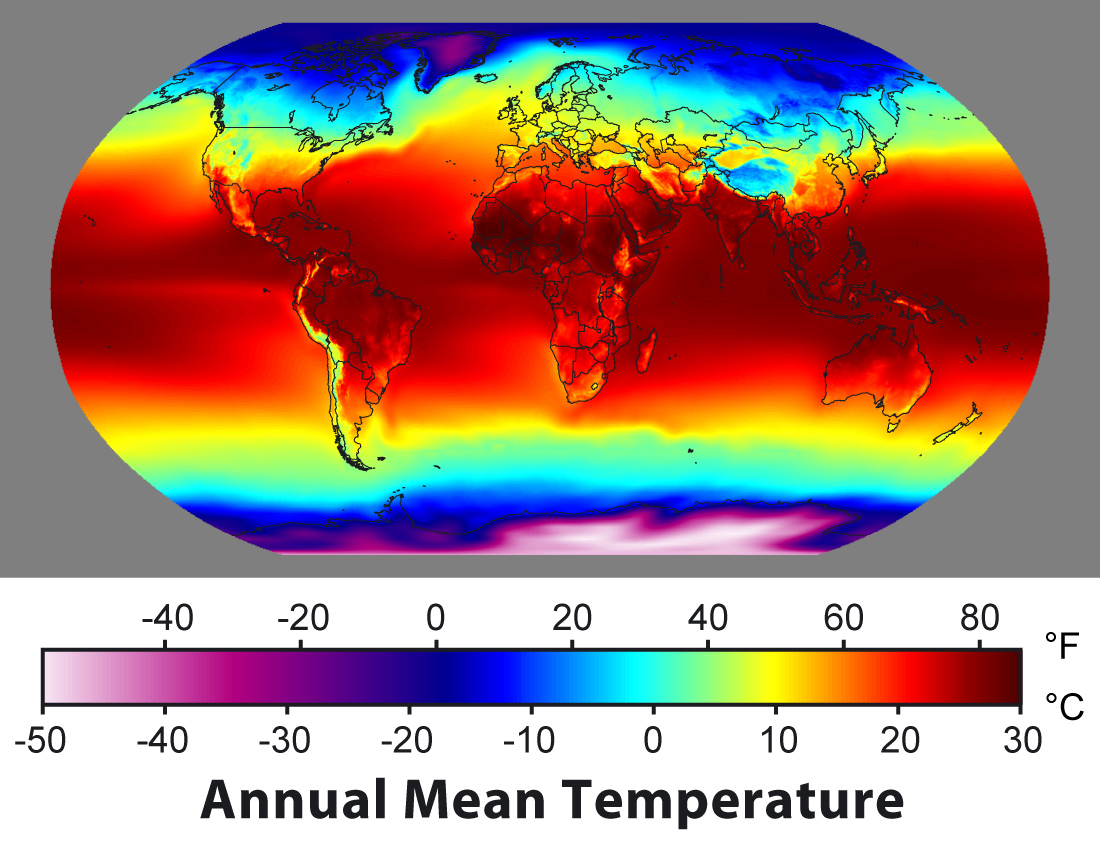
Mapa mundial de temperaturas medias
Los resultados mostraron que las personas crecidas en climas con temperaturas templadas eran generalmente más afables, responsables, emocionalmente estables, extrovertidos y abiertos a nuevas experiencias, y que lo eran en ambos países sin importar su edad, género o ingresos económicos.
“Crecer en temperaturas cercanas a la comodidad psicofisiológica óptima anima a los individuos a pasar más tiempo en el exterior, y por tanto influye en su personalidad”, concluyen los autores.
Claro que aun hay algunas cosas a tomar con cautela en este tema. Por ejemplo, el estudio señala los habitantes de regiones chinas con climas más duros (Heilongjiang, Xinjang o Shandong ) son más colectivistas y se preocupan más por la comunidad, en comparación con sus compatriotas de zonas más templados (Sichuan, Guangdong o Fujian); mientras que los habitantes estadounidenses de zonas más extremas (Dakota del Norte y del Sur, Montana o Minnesota) son más individualistas que sus compatriotas de zonas más templadas (Hawaii, Luisiana, California o Florida).

¿Nos hará el cambio climático más simpáticos, abiertos y emocionalmente estables? Foto: Pxhere
Esto pone de manifiesto que el clima no es la única variable, y que también las condiciones económicas, entre otras muchas cosas, parecen tener algún impacto en cómo somos.
No es solamente que la relación entre clima y personalidad no sea todopoderosa. Es que insinuar que lo es nos pone ante una situación un poco incómoda: ¿si el clima moldea nuestra personalidad, y el clima está cambiando, cambiará nuestra personalidad con él? ¿Nos encaminamos hacia un mundo en el que todos seremos más afables, extrovertidos y aventureros? ¿Tan maleables resultamos por la temperatura?
Los autores son conscientes de este problema, y dejan la puerta abierta a seguir investigando: “a medida que el cambio climático continúa a través del mundo, podríamos observar cambios asociados en la personalidad humana. Las preguntas sobre la extensión de esos cambios esperan respuesta en futuras investigaciones”.
Referencia:
Wenqi Wei, Jackson G. Lu, Lei Wang. Regional ambient temperature is associated with human personality. Nature Human behaviour, 27 de noviembre de 2017. doi: 10.1038/s41562-017-0240-0
Sobre la autora: Rocío Pérez Benavente (@galatea128) es periodista
El artículo ¿Y si el cambio climático nos termina haciendo a todos más simpáticos? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Del cambio climático
- Verdín, eucaliptos y cambio climático
- “El cambio climático: ciencia, política y moral” por José Manuel Sánchez Ron
Las epidemias del pasado… y del futuro

“La plaga de Atenas” de Michiel Sweerts. Alrededor de 1652.
Tras las guerras médicas, finalizadas en 448 a.e.c. con la derrota del ejército persa de Artajerjes I y la Paz de Calias, Atenas se encontraba en su máximo apogeo. Pericles, seguramente la máxima figura política de la Grecia clásica, gobernaba un imperio marítimo y, a decir del historiador Tucídides, lo hacía con talento y prudencia. Y sin embargo, la era de Pericles llegaría a su fin 17 años después, en parte al menos, por una serie de malas decisiones promovidas por el “primer ciudadano”.
En 431 a.e.c. Esparta, que lideraba una confederación de ciudades del Peloponeso, tuvo que apoyar a sus aliadas Mégara y Corinto que habían sido perjudicadas por Atenas, y atacó por tierra con sus hoplitas. Pericles había preparado a Atenas fortificando la ciudad y construyendo los dos “Muros Largos” que protegían el corredor hasta el Pireo, el puerto por el que afluían a la ciudad los suministros que necesitaba. Atenas era inferior a Esparta en tierra, pero tenía la flota más poderosa del Egeo y era, además, muy rica. Cuando la coalición lacedemonia atacó el Ática, las gentes de toda la región se refugiaron en el interior del recinto amurallado. A los 150.000 atenienses se les unieron entre 200.000 y 250.000 nuevos pobladores. En el verano de 430 se declaró una epidemia terrible que asoló la ciudad.
Tenemos noticias precisas de la epidemia gracias a Tucídides, quien sufrió en su persona la enfermedad. Los enfermos se arrastraban por las calles y morían cerca de las fuentes –a donde iban a beber-, y en los templos, donde se hacinaban los refugiados. “Morían como ovejas” escribe Tucídides. Pericles perdió a sus dos hijos legítimos, y él mismo también cayó enfermo y murió en el otoño de 429.
Se desconoce cuál es el patógeno que causó la epidemia. El mal surgió, según Tucídides, en Etiopía; se desplazó por el valle del Nilo hasta Egipto; y desde allí, por mar, llegó a Atenas a través del Pireo. Acabó con la vida de un tercio de los atenienses.
Según el epidemiólogo Paul Ewald, de la Universidad de Louisville (EEUU), la conocida como Gran Plaga de Atenas puede darnos una idea de cómo pueden desarrollarse las enfermedades más peligrosas para los seres humanos en el futuro. Frente a la extendida creencia de que las peores pandemias serán las que causen patógenos procedentes de animales –como el ébola o las gripes aviares- Ewald sostiene que esos patógenos no han convivido suficiente tiempo con los seres humanos como para haber desarrollado mecanismos eficaces para transmitirse entre personas. Los virus y bacterias con que convivimos producen síntomas e inducen respuestas por nuestra parte que facilitan mucho su dispersión.
Por esa razón, Ewald piensa que, en buena lógica evolutiva, es más probable que sean los virus y bacterias con los que más tiempo llevamos coevolucionando, y que han desarrollado buenos mecanismos de dispersión los que, bajo determinadas condiciones, puedan generar peligrosas epidemias. Enfermedades como el cólera, la viruela y las causadas por Staphylococcus aureus serían las mejores candidatas a protagonizar una pandemia peligrosa. Para que eso ocurra bastaría con que su capacidad de transmisión y virulencia se vieran favorecidas, tanto por las condiciones ambientales –grandes números de personas hacinadas- como por la aparición de alguna cepa de especial peligrosidad. Por esa razón, Ewald considera importante evitar condiciones que faciliten a los patógenos aumentar su virulencia y transmisibilidad, como las que se dan en hospitales hacinados o en grandes campos de refugiados. Porque puede que las epidemias del futuro se produzcan de modo similar a como lo hicieron en el pasado.
Fuentes:
Javier Murcia Ortuño (2007): De banquetes y batallas, Alianza Editorial, Madrid.
Wendy Orent (2017): How plagues really work Aeon.
El artículo Las epidemias del pasado… y del futuro se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Otra ventana al futuro
- ¿Se puede predecir el éxito futuro de un científico?
- El futuro ya no es lo que era
Naukas Bilbao 2017 – Guillermo Peris: Los trapecistas del genoma
En #Naukas17 nadie tuvo que hacer cola desde el día anterior para poder conseguir asiento. Ni nadie se quedó fuera… 2017 fue el año de la mudanza al gran Auditorium del Palacio Euskalduna, con más de 2000 plazas. Los días 15 y 16 de septiembre la gente lo llenó para un maratón de ciencia y humor.

Guillermo Peris nos habla de la consecuencias que tienen para los humanos los saltos que pegan dentro del genoma algunos genes, unos trapecistas llamados transposones.
Guillermo Peris ''Los trapecistas del genoma''Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Naukas Bilbao 2017 – Guillermo Peris: Los trapecistas del genoma se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Naukas Bilbao 2017- Daniel Torregrosa: ¡Estamos rodeados!
- Naukas Pro 2017: Carlos Briones y el origen de la vida
- Naukas Bilbao 2017, en directo
¿Son eficientes las plantas de energía marina?

La planta de energía marina o planta undimotriz de Mutriku es la única instalación comercial (no es un prototipo) en el mundo que funciona inyectando energía eléctrica generada por las olas a la red de manera regular. Está en funcionamiento desde el año 2011 y el estudio del grupo EOLO de la UPV/EHU ha analizado su comportamiento en el periodo 2014-2016. “Es importante conocer el funcionamiento real de la planta undimotriz, analizar cómo se comporta la tecnología empleada, y observar qué carencias y ventajas presenta para contribuir en su mejora”, afirma Gabriel Ibarra Berastegi, el autor principal del estudio. “La extracción de energía de las olas se encuentra en sus inicios y varios tipos de dispositivos y tecnologías se encuentran actualmente en desarrollo. Entre ellas, la tecnología OWC (Oscillating Water Column) empleada en Mutriku”, añade.

En la tecnología OWC, no son las olas las que mueven las turbinas directamente, sino una masa de aire comprimido que estas empujan. Se trata de una estructura cuya parte superior forma una cámara de aire y cuya parte inferior está sumergida en el agua. De esta manera, la turbina aprovecha el movimiento provocado por la ola tanto cuando viene como cuando se va, y el generador al que está acoplada inyecta la energía en la red. “Las turbinas generan electricidad que se vende de manera regular a la red eléctrica. En el caso de Mutriku, sucede en el 75% del tiempo. Hay ciertos parones cuando las olas son muy calmadas o incluso cuando son demasiado fuertes”, explica Ibarra.

La investigación se ha centrado en el estudio y análisis de los datos operacionales facilitados por el Ente Vasco de la Energía, que es quien gestiona la planta.
Una vez analizados y ordenados esos datos, “hemos visto que un indicador de rendimiento es el Factor de Capacidad (FC), que permite comparar distintas tecnologías de producción eléctrica”, explica el investigador principal del artículo. “En este caso, hemos calculado el FC de la planta de Mutriku y su valor es de 0,11, mientras que las instalaciones de energía eólica tienen un FC del orden de 0,2-0,3 y las solares de 0,4. Ello indica —apunta Ibarra— que la tecnología OWC de Mutriku necesita mejorar su FC para poder lograr situarse al nivel de los valores del resto de las fuentes de energías renovables”. “Creemos que la manera de lograrlo es mejorar la regulación y control de la velocidad de giro de las turbinas, es decir, gestionar adecuadamente la velocidad con la que gira la turbina en relación a las olas que vienen”, concluye.
Según Gabriel Ibarra, “estas conclusiones obtenidas a partir de los datos de una planta real como la de Mutriku, representan un avance que permite enfocar e identificar los siguientes pasos a dar para que la tecnología OWC alcance su madurez, facilitando así su penetración e implementación”.
Referencia:
G. Ibarra-Berastegi, J. Sáenz, A. Ulazia, P. Serras, G. Esnaola, C. García-Soto (2017) Electricity production, capacity factor, and plant efficiency index at the Mutriku wave farm (2014-2016) Ocean Engineering doi: 10.1016/j.oceaneng.2017.10.018
El artículo ¿Son eficientes las plantas de energía marina? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Robots más eficientes energéticamente sin pérdida de precisión
- Se intuye la conservación de la energía (1)
- Se establece el principio de conservación de la energía
¡Iniesta de mi vida!
Uno de mis objetivos como divulgador científico es mostrar a la sociedad que la ciencia forma parte de sus vidas. Para ello divulgo la importancia del progreso científico en el desarrollo de fármacos, alimentos, ropa, dispositivos móviles y otro instrumentos sin los cuales sería imposible disfrutar de la calidad de vida que tenemos. Creo que entre muchos lo hemos conseguido. Una parte mayoritaria de la sociedad tiene claro que detrás de cada uno de los ejemplos que he citado se encuentra la ciencia. En los últimos tiempos he dado un paso más allá e intento mostrar al ciudadano como el progreso científico y tecnológico también se encuentra en lugares aparentemente alejados del mismo como, por ejemplo, una procesión de Semana Santa, un simple sándwich de queso o la embestida de un toro de lidia. Con ese objetivo hoy toca hablar de la ciencia y tecnología que esconde el deporte rey: el fútbol.
Todos nosotros nos acordamos lo que hicimos en momentos puntuales de nuestras vidas. El atentado de las Torres Gemelas o el golpe de Estado del 23-F son fechas que jamás se nos olvidarán. Tampoco donde estábamos la noche del 11 de julio de 2010, el día que la Selección Española se proclamó por primera y única vez en su historia Campeona del Mundo de Fútbol.

Iniesta celebrando el gol durante la final
Aquel día vi el partido con los ojos del gran aficionado al fútbol que soy pero también, y aunque ustedes no lo crean, con los ojos de un científico. Mi reacción como aficionado no creo que les interese pero sí las dos conclusiones científico-tecnológicas que saqué tras el partido. La primera es que la ciencia se encuentra muy presente en el fútbol moderno. La segunda es que sin el progreso científico y tecnológico poco de lo ocurrido aquella noche en Johannesburgo hubiese sido posible. Se lo demostraré analizando desde el punto de vista de la ciencia y la tecnología lo que ocurrió en el minuto 116 de partido, momento en el que Andrés Iniesta marcó el gol que nos hizo campeones del mundo.
La presencia de la ciencia en el gol de Iniesta comenzó mucho antes de la final de Sudáfrica. Disciplinas como la medicina, la fisioterapia y, sobre todo, la psicología, fueron cruciales para que Andrés marcara el gol que jamás olvidaremos. Los tratamientos psicológicos no solo ayudan a motivar al futbolista. También a mantener la frialdad en momentos de máxima tensión como los muchos que hubo en el Mundial de 2010 donde ganamos casi todos los partidos por la mínima.
¿Y cómo ayudó la psicología a Andrés Iniesta? Ayudándolo a recuperarse muscular y mentalmente de un año dificilísimo. La lesión que sufrió meses antes Iniesta en el Barça y la muerte de su gran amigo Dani Jarque erosionó tanto su estado físico y mental que estuvo a punto de no ser convocado para ir al Mundial. Como Andrés reconoce en este fantástico capítulo del programa “Informe Robinson” el apoyo de médicos y fisioterapeutas, tanto del Barça como de la selección española, fueron vitales para que se recuperara a tiempo… y también para que superara la pequeña lesión que tuvo en el primer partido del Mundial ante Suiza que le impidió jugar el siguiente contra Honduras.
Un partido del que pocos se acuerdan pero que pudo dejarnos sin la copa de campeones del mundo fue el de octavos de final contra Paraguay. Aquel día otra disciplina científica, la estadística, tuvo un papel prioritario. A falta de media hora para el final el árbitro pitó un claro penalti contra España. Si hubiese marcado Cardozo, el jugador paraguayo encargado de lanzar la pena máxima, habría sido dificilísimo remontar. Sin embargo Casillas se lanzó al lado adecuado y detuvo el balón con una seguridad pasmosa.
La intuición y el azar tuvieron mucho que ver pero la ciencia también. Como se observa en el siguiente vídeo Casillas, tras detener el penalti, miró al banquillo y dedicó su decisiva parada a Pepe Reina, el portero suplente. ¿Por qué? Porque antes del partido Reina había estudiado detenidamente la forma de tirar los penaltis de Cardozo. Tras visionar muchos vídeos del jugador paraguayo había llegado a la conclusión de que casi todos los tiraba a la izquierda del portero. Se lo dijo a Iker desde el banquillo antes del lanzamiento, Casillas le hizo caso y atrapó el balón. Pura estadística.
Centrémonos en el gol de Iniesta en la final. La jugada más importante de la historia del fútbol español comenzó en el área española con un pase de Carles Puyol a Jesús Navas que recibió el esférico muy lejos de la portería rival. El balón que se empleó en el Mundial de Sudáfrica 2010, el controvertido Jabulani, ha sido uno de los más discutidos en la historia de los mundiales. Su inestable vuelo fue criticado por muchos porteros que no veían la forma de controlarlo… y es que en el diseño de los balones modernos la aerodinámica tiene mucho que decir. Polímeros como el poliuretano o el etiilvinilacetato se han sumado (y en algunos casos sustituido) al nailon, poliéster, caucho y algodón. Las modernas tecnologías de unión de los materiales que forman los balones les otorgan mayor redondez y mejor resistencia al agua. Además, las ranuras integradas de los modernos balones proporcionan buenas características de vuelo, corrigiendo los errores del Jabulani y haciéndolos más estables.

Jabulani
Tras recibir el esférico de Puyol, Jesús Navas hizo una carrera por la banda de más de 30 metros gracias a su potente zancada… y a la química de los nuevos materiales de las camisetas que mejoran el rendimiento deportivo de los futbolistas. Los jugadores holandeses, al ver que eran mas lentos que el extremo andaluz, intentaron agarrarlo pero no pudieron con la fuerza del sevillano ni con la elasticidad de la camiseta. La presencia en las equipaciones actuales de un compuesto químico como el elastano, también llamado lycra o spandex, las hace más elásticas. Sin esta fibra sintética, que en realidad es un copolímero uretano-urea, Navas no hubiese podido seguir corriendo al ser agarrado. Además, la ausencia de este material o un defecto en la fabricación provoca que las camisetas terminen desgarradas como le ocurrió en la pasada Eurocopa a 7 jugadores de la selección Suiza, lo que trajo nefastas consecuencias para la empresa responsable de la equipación.
{kind=link}
El poliéster de las camisetas modernas provoca que sean transpirables y no retengan tanto el sudor como ocurría antiguamente con la ropa de algodón. La final del Mundial de Sudáfrica fue intensísima y tras 120 minutos trepidantes los jugadores acabaron casi deshidratados. ¿Se imaginan que todo el sudor hubiese quedado retenido en la camiseta? Muchos de ellos no hubiesen acabado el partido. Tampoco podemos olvidar la importancia de la presencia en las camisetas del poliuretano, compuesto que actúa como aislante térmico y es resistente al agua. En el Mundial de Fútbol 2010, donde la selección española jugó muchos partidos en condiciones climáticas muy diferentes, su papel fue fundamental.

La química de una camiseta de fútbol
La fantástica conducción del balón que hizo Navas fue posible gracias a la calidad del jugador pero también al buen césped del Soccer City, el campo de fútbol de Johannesburgo donde se jugó la final. La botánica, la biotecnología y la química agrícola ayudan a que los campos actuales se encuentren en perfecto estado y no tengan nada que ver con los irregulares terrenos donde se jugaron otros mundiales anteriormente. Las nuevas variedades de hierba, los fertilizantes y los modernos sistemas de regadío hacen que el balón circule a las mil maravillas.
Sin lugar a dudas, una de las grandes revoluciones del fútbol moderno reside en los campos con césped híbrido. De hecho el Mundial de Sudáfrica 2010 fue el primero donde se empleó este tipo de césped en varias sedes. En el césped híbrido predomina el natural (95%) sobre el sintético (5%) pero las millones de fibras artificiales implantadas por todo el campo tienen un efecto trascendental. Estas fibras se entrelazan con el césped natural logrando que el terreno de juego sea más resistente y más estable a la degradación, permitiendo una frecuencia de juego superior. Además, el césped híbrido tiene una mayor densidad vegetal por lo que el color verde es mucho más intenso. Pero la característica más importante para el futbolista de los céspedes híbridos es que tienen mayor capacidad de amortiguación, lo que reduce el número de lesiones.
Tras su maravillosa carrera Jesús Navas, exhausto, entregó el balón a Andrés Iniesta. El manchego hizo algo de lo que poco se ha hablado pero que fue crucial en el gol. Cuando recibió el balón se encontró rodeado de cuatro jugadores holandeses pero se deshizo de ellos dando un taconazo. Cesc Fábregas, que estaba a su espalda, quedó completamente solo con el esférico. La visión periférica de Iniesta es uno de sus valores añadidos… y también se entrena.
El equipo alemán del Hoffenheim utiliza en sus entrenamientos un sistema llamado ‘Helix’ que pone a prueba la visión periférica de los futbolistas. Se trata de una especie de simulador formado por una pantalla circular de 180 grados en la que van apareciendo jugadores realizando diferentes acciones del juego. Los jugadores, que emplean unas Google Glass en los entrenamientos, deben reconocer quiénes son los oponentes, quiénes son sus compañeros y definir sus acciones para pensar rápidamente cómo crear una situación de pase o cómo dejar atrás a sus rivales.
Cesc Fábregas, el jugador que recibió el balón procedente del taconazo de Iniesta gracias a su visión periférica, es uno de esos jugadores procedentes de La Masía que tienen lo que se conoce como el “ADN azulgrana”. Me refiero a intentar tener la posesión del balón el máximo tiempo posible. Desde que Cruyff fue nombrado entrenador del Barca ese es el sello de identidad del equipo azulgrana que luego adaptaron a la sección española Luis Aragonés y Vicente del Bosque.
Hay dos grandes culpables de que durante todos los partidos de la selección en el Mundial de Sudáfrica la posesión del balón cayera del lado español. Uno de ellos es la gran calidad de sus jugadores… el otro, las matemáticas. La disposición geométrica de los jugadores de “la Roja” a lo largo del terreno de juego fue perfecta y los diagramas de Voronoi (una construcción geométrica que permite construir una partición del plano euclídeo y que en el caso del fútbol muestran el espacio controlado por cada jugador) y las triangulaciones de Delaunay (una red de triángulos conexa y convexa que en el deporte rey conecta los jugadores con líneas), estaban presentes por todo el campo.
La aplicación al fútbol de estos conceptos matemáticos, asociados a la geometría computacional, es la clave de los famosos rondos de la selección que tanto daño hicieron a los rivales. Potentes selecciones como Portugal o Alemania sufrieron muchísimo ante “las matemáticas de la roja”. En el siguiente vídeo, del que tuve conocimiento gracias al blog del gran divulgador Francisco Villatoro, se aprecia la importancia de la geometría en la presión y posterior robo del balón, dos aspectos importantísimos en el juego de la selección española. Tras el saque inicial el equipo rojo presiona, fuerza un error del equipo azul y gana el control del balón. El centrocampista del equipo rojo abre espacio en el centro del campo, logrando tras un par de pases crear una oportunidad que acaba en gol.
Pero además de las matemáticas se necesita algo más para tener la posesión del balón: calidad técnica en los jugadores. Pocas veces se han juntado en un mismo equipo futbolistas con la técnica de Xavi Hernández. Busquets, Silva, Xabi Alonso, Navas, Iniesta, Fábregas, Villa, etc. Sus grandes virtudes son el perfecto control del balón, la rapidez de desplazamiento que imprimen al esférico y la precisión en el pase al “primer toque”, cualidades que muchos equipos entrenan con ayuda de modernas tecnologías.
En el siguiente vídeo se observa cómo hay equipos que emplean el innovador “Footbonaut” en sus centros de entrenamiento. Se trata de una caja de 20 metros cuadrados con cuatro máquinas que ‘disparan’ balones a diferentes velocidades y trayectorias hacia los futbolistas. El jugador tiene que recibir la pelota y en dos toques enviarla hacia el panel indicado de los 64 que tiene la estructura. Este instrumento es fundamental a la hora de realizar transiciones rápidas, con un máximo de dos toques seguidos de pase o tiro.
Mediante aplicaciones informáticas la máquina recoge los aciertos y errores de cada jugador y almacena la información. Posteriormente el entrenador analiza los resultados y elige qué jugadores son los que mejor se adaptan a su sistema de juego… y es que el fútbol no es ajeno al Big Data. Gracias al mismo los entrenadores conocen al instante cuantos pases correctos e incorrectos han dado sus jugadores, la distancia recorrida por cada uno, los futbolistas que mejor se acoplan al sistema defensivo u ofensivo diseñado, etc. El Big Data, que ha entrado de lleno en el fútbol moderno, también le sirve a los clubes para recoger información sobre futuros fichajes.
Sigamos con el gol de Iniesta. Fábregas, tras recibir el taconazo del jugador de Fuentealbilla, devolvió con ese primer toque que ya hemos visto como se entrena el balón a Jesús Navas. El sevillano, exhausto, dio un pase a Fernando Torres. El “Niño” realizó un centro al área buscando a Iniesta que se había desmarcado… pero se equivocó. Torres golpeó el balón suavemente y con el empeine de su pie derecho. El esférico salió en línea recta siguiendo la primera Ley de Newton, según la cual un cuerpo se mueve en la misma dirección y a la misma velocidad hasta que se le aplica una fuerza que lo haga variar de dirección. Como no apareció ninguna fuerza, el balón siguió su trayectoria rectilínea hasta que fue interceptado por un rival.
¿Qué hubiese ocurrido si Fernando Torres hubiese golpeado el esférico con el exterior del pie derecho (en lugar de con el empeine) imprimiéndole más fuerza, elevación y, sobre todo, mayor efecto? Que gracias al Efecto Magnus la pelota hubiese llegado a Iniesta, que se había desmarcado perfectamente buscando la región óptima de Voronoi.
En un lado del balón el aire se hubiese movido en dirección contraria al giro del mismo, aumentando la presión. En el otro lado el aire se movería en la misma dirección del giro de la pelota, creando un área de baja presión. Como consecuencia de la diferencia de presiones hubiese aparecido una fuerza perpendicular a la dirección de la corriente de aire. Esto hubiese provocado que el balón se curvara hacia la zona de baja presión y cambiara su trayectoria, superando a la defensa holandesa y dejando solo a Andrés Iniesta delante del portero gracias a la física del Efecto Magnus.
Para explicar el Efecto Magnus en el fútbol tradicionalmente se muestra el mítico gol de Roberto Carlos a la selección francesa que pueden observar aquí. También se aprecia en un gol de la selección española en el Mundial de Sudáfrica, concretamente en el que marcó David Villa a Chile en el tercer partido del Mundial y que nos dio el pase a octavos de final. En este enlace pueden verlo.
Pero hoy les voy a mostrar una joya donde se aprecia mucho mejor el Efecto Magnus. Se trata del gol que marcó Mohd Faiz Subri, jugador del Penang que milita en la liga de Malasia, y que ganó el Premio Puskas al mejor gol del 2016. Alucinante.
Desgraciadamente en Sudáfrica Torres no golpeó correctamente el balón y este fue interceptado por un defensa holandés. Por fortuna para el equipo español el esférico cayó de nuevo en los pies de Cesc Fábregas que, haciendo gala de su entrenada precisión, dio un pase perfecto a Andrés Iniesta dejándolo solo ante el portero holandés… y se armó la mundial, nunca mejor dicho.
Iniesta golpeó con fuerza el balón, que salió con una aceleración tremenda de su bota derecha y se coló en la portería holandesa… lo que tampoco hubiese ocurrido sin ayuda de los nuevos materiales con los que se fabrican las botas actuales y de su avanzada tecnología. Las botas modernas, mucho más ligeras que las antiguas, han mejorado la fricción entre el pie y la pelota favoreciendo el control, el pase y la precisión del tiro. Además de ser muy ligeras, las nuevas zapatillas se adaptan al pie como un guante y tanto las lengüetas, las suelas y los tacos están preparados para los innumerables disparos, giros y cambios de ritmo del fútbol moderno. Incluso para conseguir que el balón adquiera una gran aceleración ya no hace falta la fuerza con la que los jugadores de épocas pasadas golpeaban el esférico. Los innovadores materiales con los que se elaboran las botas son capaces de conseguir gran aceleración con mucho menor potencia de disparo. El balón disparado por Iniesta salió con tal aceleración de su bota derecha que dobló las manos del portero.
Lo que ocurrió después ya lo saben. Yo me abalancé sobre mi vecino rompiéndole una costilla y mi paisano José Antonio Camacho, en la retransmisión que hizo televisión de la final, gritó la célebre frase que ha quedado grabada para la eternidad: “¡¡Iniesta de mi vida!!”.
Estimados lectores, lo ocurrido en el gol de Iniesta en la final del Mundial de 2010 demuestra que la ciencia, la tecnología y el fútbol van cogidos de la mano… y es necesario que la sociedad sepa que el progreso científico y tecnológico se encuentra presente hasta en los sitios más insospechados. Disciplinas como la medicina, la química, la física, la informática, la fisioterapia, la óptica, las matemáticas, la botánica, el big data, la psicología y muchas otras aparecieron en el momento más importante de la historia del fútbol español que hizo feliz a millones de personas. Más de diez años después los avances científicos y tecnológicos siguen revolucionando el fútbol.
Sin embargo, después de Sudáfrica 2010 no hemos vuelto a ganar un Mundial. ¿Por qué? Porque en el fútbol, al igual que en el mejor de los laboratorios, el progreso científico no se pone de manifiesto si no está detrás el talento humano. A buen entendedor…
Este post ha sido realizado por José M. López Nicolás (@ScientiaJMLN) y es una colaboración de Naukas.com con la Cátedra de Cultura Científica de la UPV/EHU.
El artículo ¡Iniesta de mi vida! se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:El frustrante viaje de un átomo de carbono, mención especial del jurado “On zientzia”
“El frustrante viaje de un átomo de carbono” de Julio Ruiz Monteagudo recibió la mención especial del jurado en la 7ª edición de los premios On zientzia. El ciclo del carbono puede explicarse de muchas maneras, pero pocas serán tan musicales, divertidas y didácticas como este vídeo de poco más de 4 minutos.
¿Tienes una idea genial para explicar un concepto científico en un vídeo? ¿Quieres ver tu trabajo emitido en televisión? La Fundación Elhuyar y el Donostia International Physics Center (DIPC) han organizado la octava edición de On zientzia, un concurso de divulgación científica y tecnológica enmarcado en el programa Teknopolis, de ETB. Este certamen pretende impulsar la producción de vídeos cortos y originales que ayuden a popularizar el conocimiento científico.
On zientzia tendrá tres categorías. El mejor vídeo de divulgación recibirá un premio de 3.000 euros. Para impulsar la producción de piezas en euskera, existe un premio de 2.000 euros reservado a la mejor propuesta realizada en ese idioma. Por último, con el objetivo de impulsar la participación de los estudiantes de ESO y Bachillerato, hay un premio dotado con 1.000 euros para el mejor vídeo realizado por menores de 18 años.
Los vídeos han de tener una duración inferior a los 5 minutos, se pueden realizar en euskera, castellano o inglés y el tema es libre. Deben ser contenidos originales, no comerciales, que no se hayan emitido por televisión y que no hayan resultado premiados en otros concursos. El jurado valorará la capacidad divulgativa y el interés de los vídeos más que la excelencia técnica.
Las bases las encuentras aquí. Puedes participar desde ya hasta el 25 de abril de 2018.
Edición realizada por César Tomé López
El artículo El frustrante viaje de un átomo de carbono, mención especial del jurado “On zientzia” se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Fallos científicos en el cine, mejor vídeo de divulgación joven “On zientzia”
- El mecanismo de la vida, mejor vídeo de divulgación joven “On zientzia”
- Soy esa bacteria que vive en tu intestino, mejor vídeo de divulgación “On zientzia”
La potencia sin control no sirve de nada

«La potencia sin control no sirve de nada». Este es el eslogan de la que, con toda probabilidad, ha sido la campaña publicitaria de neumáticos más exitosa de la historia. Fue realizada en 1995 por la agencia de publicidad Young & Rubicam para Pirelli.
Uno de los cometidos pretendidos en el diseño de automóviles es que se mantengan pegados a la carretera. Esto se logra sobre todo gracias a la aerodinámica, de manera que, al aumentar la potencia el automóvil no se separe del suelo. Podríamos decir que la aerodinámica de un automóvil sería la contraria a la de un avión.

La aerodinámica es fundamental, sobre todo en los coches deportivos y de competición, pero, no hay que olvidar la importancia de los neumáticos. Mi padre, que se dedicó durante años a la industria del neumático, siempre dice que «los neumáticos son la única parte del coche que está en contacto directo con la carretera», por eso son tan importantes. No le falta razón.
Utilizamos ruedas desde hace miles de años, pero la idea de ponerle caucho en el borde exterior es relativamente nueva. Fue a principios del siglo XIX cuando por primera vez se utilizó este polímero natural para recubrir las ruedas de madera. Antiguamente se enfundaban en cuero o metal.
El caucho se obtiene de varios tipos de plantas, pero principalmente se extrae del látex que surge de los cortes hechos del tronco de Hevea brasiliensis. En la década de 1920 los laboratorios de Bayer inventarían el caucho sintético.
El caucho natural se somete a varios procesos sucesivos como la coagulación, el lavado y el refinado. El caucho natural resulta poco elástico y se reblandece fácilmente con el calor. Se desgasta con rapidez, así que su futuro no parecía muy prometedor.
El químico Charles Goodyear dedicó varios años de su vida a investigar el caucho. En 1839 descubrió el vulcanizado, que es un procedimiento que consiste en calentar el caucho en presencia de azufre en polvo. En resultado final es que las moléculas elásticas de caucho se quedan unidas entre sí mediante puentes de azufre. De esta manera se consigue un caucho más duro y resistente sin perder elasticidad. El vulcanizado es el proceso químico que dio origen a los neumáticos que utilizamos hoy en día.
Desgraciadamente Charles Goodyear no patentó su invento. El ingeniero Thomas Hancock, habiendo llegado más tarde a la misma conclusión se hizo con la patente en 1843. Fue entonces cuando se hicieron populares las ruedas de goma maciza.
Charles Goodyear sigue estando asociado al mundo del neumático debido a que una empresa de éxito de la industria de la automoción tomó su nombre. Sin embargo, esta compañía no tiene ninguna relación con él.
Hasta entonces los neumáticos eran de color claro, por lo que se ensuciaban con facilidad y comprometían la estética. En 1885 la empresa Goodrich decidió fabricar ruedas de color negro. Al tintar el caucho se hizo un descubrimiento sorprendente, los neumáticos negros duraban más. Esto es debido a que el tinte negro absorbe los rayos ultravioletas que son, en parte, los causantes del agrietamiento del caucho.
La primera rueda neumática —llena de aire— fue patentada en 1845 por el ingeniero Robert W. Thomson. Sin embargo, no fue hasta 1888 que el ingeniero John Boyd Dunlop, desarrolló el primer neumático con cámara de aire. Lo inventó para envolver las ruedas del triciclo que su hijo de nueve años usaba para ir a la escuela por las calles bacheadas de Belfast. Esas precarias cámaras de aire consistían en unos tubos de goma hinchados. Envolvió los tubos con una lona y los pegó sobre las llantas de las ruedas del triciclo. Patentó el neumático con cámara de aire en 1889. Había ganado en comodidad, aun así, al neumático le faltaban algunos obstáculos por vencer. Era muy trabajoso repararlos, ya que estaban adheridos a la llanta.
En 1891, Édouard Michelin, quien era conocido por su trabajo con el caucho vulcanizado, decidió desarrollar un neumático que pudiera separarse de la llanta y así facilitar el trabajo. Los neumáticos de Michelin resultaron tan prácticos que al año siguiente ya eran los que utilizaban la mayoría de ciclistas. Poco después también los llevarían los carruajes. En 1946, la compañía Michelin desarrolló el método de construcción de neumáticos radiales que supusieron un antes y un después en la conducción deportiva.

En los años 40 se incluyeron nuevos materiales en la composición del neumático, como el rayón, el nailon y el poliéster. Cuando terminó la segunda guerra mundial, se empezó a trabajar en la fabricación de un neumático que sellara herméticamente sobre la rueda, lo que al fin eliminó la necesidad de acompañarlos de cámara de aire. La evolución fue vertiginosa, propiciada en gran medida por la Fórmula 1. En los neumáticos modernos se utilizan más de doscientos materiales distintos, entre ellos el acero, la fibra de carbono o el kevlar. En la actualidad el caucho vulcanizado lo encontramos, sobre todo, en la superficie del neumático.

En automoción —y en otros aspectos de la vida— sigue siendo muy certero eso de que «la potencia sin control no sirve de nada». En las vallas publicitarias y en prensa, bajo este eslogan de Pirelli salía una magnífica imagen del deportista Carl Lewis con zapatos de tacón. En la versión televisiva del anuncio, la planta de sus pies estaba cubierta de caucho.
Y es que, entre otros aspectos ingenieriles, los neumáticos y en consecuencia la ciencia del caucho es fundamental para el control de la conducción. Al fin y al cabo, como dice mi padre, es la única parte del coche que está en contacto directo con el asfalto. Cuando vamos en coche los neumáticos son nuestros pies en el suelo.
Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo La potencia sin control no sirve de nada se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- ¿La publicidad no sirve para nada?, ¡ja!
- Potencia y eficiencia de una máquina
- Fotovoltaicos siempre a máxima potencia
Una hiperlente que permite ver un virus en la superficie de una célula viva
Imagina que te digo que existe una lente óptica tan potente, una hiperlente, que permite ver detalles del tamaño de un pequeño virus en la superficie de una célula viva en su entorno natural. Suena increíble, tanto más cuanto más sepas de biología o de física, pero existe realmente.

Una representación artística de una hiperlente que permite ver una célula viva con detalle. Arriba a la izquierda, la estructura cristalina del nitruro de boro hexagonal (hBN). Imagen de Keith Wood, Vanderbilt University
La ciencia y la ingeniería han desarrollado muchos instrumentos capaces de producir imágenes con resolución a nanoescala, como microscopios basados en flujos de electrones y otros llamados de fuerza atómica. Sin embargo, estos instrumentos son incompatibles con organismos vivos, ya que, o bien operan bajo un alto vacío, o exponen las muestras a niveles nocivos de radiación, o requieren técnicas letales de preparación de muestras como la liofilización o extraen las muestras de su entorno natural basado en disoluciones.
La razón principal para desarrollar las llamadas hiperlentes (lentes ópticas con una resolución mucho menor que la longitud de onda de la luz empleada) es la posibilidad de que pudiesen proporcionar imágenes detalladas de las células vivas en sus entornos naturales utilizando luz de baja energía que no las dañe. El trabajo realizado por un equipo de investigadores encabezado por Alexander Giles, del Laboratorio de Investigación Naval de los Estados Unidos, ha llevado la construcción de hiperlentes un paso más allá simplemente purificando el material a niveles que hace unas décadas eran inimaginables.
El material óptico empleado es el nitruro de boro hexagonal (hBN), un cristal natural con propiedades de hiperlente. La mejor resolución que se había conseguido previamente usando hBN fue de 36 veces más pequeña que la longitud de onda infrarroja utilizada: aproximadamente el tamaño de la bacteria más pequeña. El nuevo trabajo describe mejoras en la calidad del cristal que mejoran su capacidad en un factor de diez.
Los investigadores lograron esta mejora al fabricar cristales de hBN usando boro isotópicamente purificado. El boro natural contiene dos isótopos que difieren en peso en aproximadamente un 10 por ciento, una combinación que degrada significativamente las propiedades ópticas del cristal en el infrarrojo.
Los científicos calculan que una lente hecha de su cristal purificado puede, en principio, capturar imágenes de objetos de 30 nanómetros de tamaño. Para poner esto en perspectiva, un pelo humano tiene entre 80.000 y 100.000 nanómetros de diámetro. Un glóbulo rojo humano tiene aproximadamente 9.000 nanómetros y los virus varían de 20 a 400 nanómetros.
La física de las hiperlentes es bastante compleja. El nivel de detalle con el que los microscopios ópticos pueden generar imágenes está limitado por la longitud de onda de la luz y el índice de refracción del material de la lente. Cuando esto se combina con los factores de apertura de la lente, la distancia desde el objeto a la lente y el índice de refracción del objeto bajo observación, se traduce en un límite óptico típico de aproximadamente la mitad de la longitud de onda utilizada para la obtención de las imágenes.
En las longitudes de onda infrarrojas utilizadas en este experimento, este “límite de difracción” es de aproximadamente 3.250 nanómetros. Este límite puede superarse mediante el uso de hBN debido a su capacidad para soportar polaritones de fonones superficiales, partículas híbridas formadas por fotones de luz que se acoplan con átomos del cristal que poseen carga y vibran. Estos polaritones tienen longitudes de onda mucho más cortas que la luz incidente.
El problema con el uso de polaritones ha sido siempre la rapidez con la que se disipan. Mediante el uso de cristales de hBN hechos con un 99% de boro isotópicamente puro, los investigadores han podido comprobar que existe una reducción drástica de las pérdidas ópticas en comparación con los cristales naturales, es decir, que aumenta el tiempo de vida del polaritón, lo que les permite viajar el triple de distancia. Este mayor recorrido se traduce en una mejora significativa en la resolución de las imágenes. El análisis teórico de los investigadores sugiere que es posible incluso otro factor de mejora de diez adicional.
En 1654, Anton van Leeuwenhoek utilizó uno de los primeros microscopios para descubrir el mundo desconocido hasta ese momento de la vida microscópica. Este resultado en el desarrollo de hiperlentes es un paso importante para llevar el descubrimiento de van Leeuwenhoek a un nivel completamente nuevo, que permitirá a los biólogos observar directamente los procesos celulares en acción, como virus invadiendo células o células inmunes que atacan invasores extraños, abriendo innumerables posibilidades en la investigación biomédica.
Referencia:
Alexander J. Giles et al (2017) Ultralow-loss polaritons in isotopically pure boron nitride Nature Materials doi: 10.1038/nmat5047
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
Este texto es una colaboración del Cuaderno de Cultura Científica con Next
El artículo Una hiperlente que permite ver un virus en la superficie de una célula viva se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Otra pieza en el puzle de la fotosíntesis
- Cómo fabricar hielo extraterrestre y verlo molécula a molécula
- Estroncio en la leche
La artista Anni Albers, The Walking Dead y la teoría de nudos
Las personas que han visitado durante las últimas semanas el Museo Guggenheim de Bilbao han tenido la suerte de poder disfrutar de una exposición interesante e inspiradora, “Anni Albers, tocar la vista” (6 de octubre de 2017 – 14 de enero de 2018). Esta exposición nos acerca a la obra de la artista de origen alemán, afincada en Estados Unidos, Anni Albers (1899-1994), quien seguramente sea la artista textil más importante del siglo XX, aunque también trabajó otras técnicas como el grabado, la pintura o el diseño de joyas.

Anni Albers, “Estudio para Colgadura no realizada” (sin fecha), Gouache sobre papel, The Josef and Anni Albers Foundation
La exposición está compuesta por alfombras y colgaduras textiles, telas, diagramas geométricos, dibujos y estudios para el diseño de obras textiles, joyas, aguatintas, litografías, serigrafías e impresiones offset, acuarelas y otros tipos de pinturas, en las cuales la geometría juega un papel fundamental.
Las personas que deseen más información sobre la exposición pueden visitar la página del Museo Guggenheim-Bilbao Anni Albers, tocar la vista o ver los cuatro videos que el museo ha colgado en su canal de youtube y que están aquí.

Anni Albers, “Segundo movimiento V” (1972), Aguatinta, The Josef and Anni Albers Foundation
La visita a la exposición Anni Albers, tocar la vista fue una experiencia enriquecedora. Descubrí a una artista excepcional y disfruté de unas creaciones artísticas increíbles. Tengo ganas de volver para sumergirme de nuevo en el arte de Anni Albers, y descubrir más sobre los procesos creativos, claramente conectados con las matemáticas, de esta artista. Aunque muchas de las obras de la exposición despertaron la curiosidad de mi mirada matemática, me gustaría destacar aquí la serie de obras dedicadas a los “nudos”, como su litografía Enredada (1963),
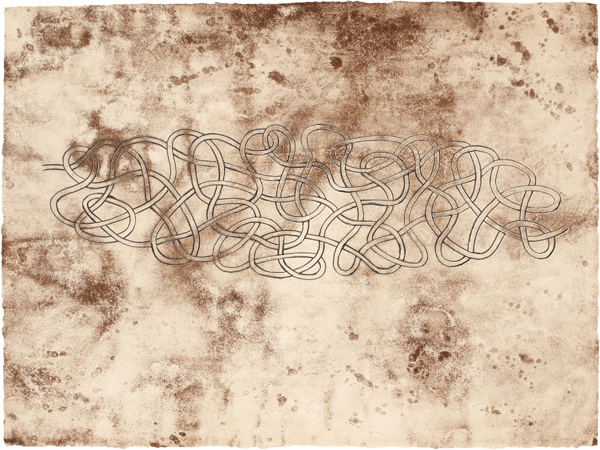
Anni Albers, “Enredada” (1963), litografía, The Josef and Anni Albers Foundation
o su, también litografía, Sin título (1963),

Anni Albers, “Sin título” (1963), litografía, The Josef and Anni Albers Foundation
que rápidamente me recordaron a la teoría de nudos de las matemáticas. De hecho, esta última obra me hizo recordar la fotografía realizada por un microscopio electrónico de un fragmento anudado del ácido desoxirribonucleico, ADN, cuyo estudio es uno de los campos de aplicación de la teoría de nudos.

Fotografía de un fragmento de ADN anudado visto con un microscopio electrónico, realizada por Steven A. Wasserman y Nicholas R. Cozzarelli
La teoría de nudos, que ya mencionamos brevemente en la entrada del Cuaderno de Cultura Científica La topología modifica la trayectoria de los peces, es una rama de la topología que se dedica al estudio matemático de los nudos, que surgió en el siglo XX, aunque tiene sus orígenes en el siglo XIX con el trabajo de matemáticos como el alemán Carl Friedrich Gauss (1777-1855), su alumno Johann B. Listing (1808-1882) o el inglés Peter G. Tait (1831-1901). La teoría de nudos tiene numerosas e importantes aplicaciones fuera de las matemáticas, como por ejemplo en biología molecular, medicina, mecánica estadística, física de polímeros y de cristales, teoría física de cuerdas, criptografía, o ciencias de la computación.
La idea matemática de nudo es una abstracción matemática de lo que sería un nudo físico. Se coge una cuerda, se anuda de una forma más o menos enrevesada y se pegan los extremos. Desde el punto de vista matemático nos interesa la línea cerrada que describe la cuerda, sin tener en cuenta el grosor de la misma, es decir, un nudo es una línea curva anudada cerrada, que no tiene puntos de intersección, en nuestro espacio tridimensional.
Como estamos hablando de nudos en topología, esto significa que podemos deformar estirando o encogiendo la línea, es decir, la cuerda, y cambiándola de forma en el espacio, lo cual no altera el nudo, siempre que no se corte o pegue la misma. De hecho, se dice que dos nudos son equivalentes, que para nosotros es tanto como decir que “son iguales desde el punto de vista topológico”, cuando se puede deformar un nudo en el otro de forma continua, es decir, sin realizar cortes, ni pegar.
El nudo más simple es cuando cogemos la cuerda y unimos los extremos sin anudar, es decir, es la circunferencia, en la que no existe un nudo como tal, podríamos decir que es el no-nudo. Cualquier deformación espacial de la circunferencia, como en la imagen de abajo realizada con el juguete Tangle, sigue siendo el no-nudo.

Cuatro deformaciones en el espacio del nudo trivial, realizadas con el juguete Tangle, luego los cuatro nudos resultantes son equivalentes entre sí, son el mismo nudo, el no-nudo
El nudo más sencillo no trivial es el nudo de trébol, que es cuando hacemos un nudo sencillo a la cuerda y después anudamos los extremos. Es imposible deformarlo al nudo trivial sin cortar la cuerda y volver a pegarla, luego topológicamente el no-nudo y el nudo de trébol no son el mismo, no son equivalentes.

Nudo de trébol en el espacio tridimensional. Jim Belk, de wikimedia
El nudo de trébol es un símbolo muy común desde la antigüedad, ya que su versión plana es la triqueta, o triquel, que fue ampliamente utilizada, por ejemplo, en el arte celta, en la religión cristina, como símbolo de la trinidad (padre, hijo y espíritu santo), en una de las versiones del Valnout alemán, que se relaciona con el dios Odín, o en el Mjolnir, martillo del dios Thor de la mitología nórdica. Y hoy en día nos la encontramos con mucha frecuencia en la cultura popular, por ejemplo, en la katana de Michonne de la serie de TV Walking Dead, así como en muchas otras series, películas o video juegos.

La katana de Michonne, de la serie The Walking Dead, tiene el símbolo de la triqueta, que es el nudo de trébol
Para estudiar los nudos se utilizan representaciones gráficas planas de los mismos, que son proyecciones sobre el plano de los nudos tridimensionales, como si les hiciéramos una fotografía. Se utilizan solo las proyecciones buenas, las llamadas regulares, en las que solamente hay un número finito de puntos dobles (cruces) como puntos singulares. En las proyecciones no regulares perderíamos parte de la información del nudo. Estas representaciones se llaman diagramas del nudo. Son líneas continuas en el plano, que solo se pintan discontinuas cuando esa parte del nudo pasa por debajo de la que ya está pintada, como se muestra en los siguientes ejemplos. También podemos pensar en los diagramas de los nudos, como la representación de un nudo, como cuerda anudada, que apoyamos en una superficie plana.
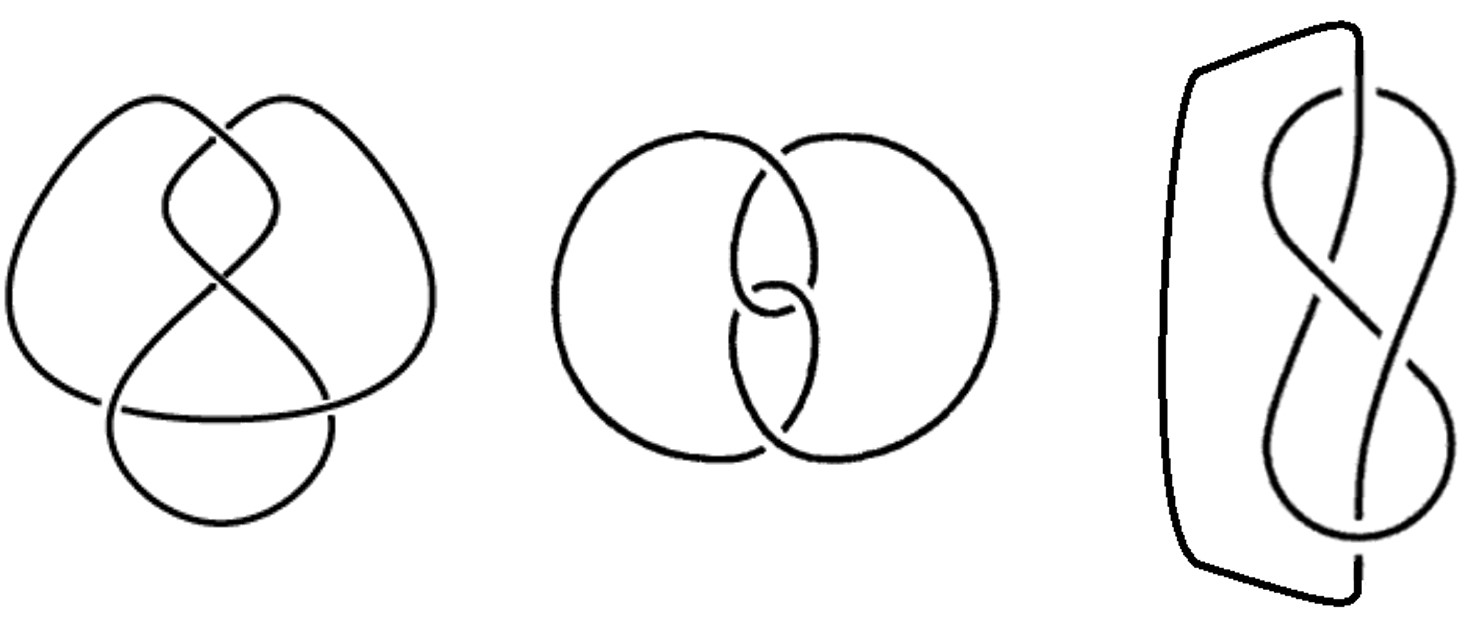
Tres diagramas diferentes del nudo de Saboya, o nudo del ocho
El nudo de Saboya, o nudo del ocho, que aparece en la anterior imagen, es un nudo cuyo diagrama tiene cuatro cruces, el diagrama del trébol tenía solamente tres, y se llama así porque aparece en el escudo de armas de la Casa de Saboya.

Escudo de armas de la Casa de Saboya con distintas copias del diagrama del nudo de ocho, o de Saboya
A continuación, mostramos el diagrama del nudo de la obra Sin título (1963), de Anni Albers.

La teoría de nudos estudia las propiedades topológicas de los nudos, en particular, el problema más importante es la clasificación de los diferentes nudos que existen, el cual incluye el problema de reconocimiento, es decir, determinar cuándo dos nudos son equivalentes, para lo cual se desarrollan herramientas matemáticas que nos permitan saber cuándo dos nudos son, o no, equivalentes (el mismo desde el punto de vista topológico).
En particular, deberemos de estudiar cuando dos diagramas corresponden a nudos equivalentes. Por ejemplo, nos podemos preguntar si un diagrama complejo como el que aparece en la imagen de abajo, y que se conoce como nudo gordiano de Haken, es topológicamente equivalente al no-nudo, es decir, que no hay nudo, solamente está enmarañado. El propio matemático alemán Wolfgang Haken, conocido por demostrar junto al matemático estadounidense Kenneth Appel el teorema de los cuatro colores, demostró que efectivamente dicho nudo es equivalente al no-nudo.

Nudo gordiano de Haken
En la década de 1920, que fueron los inicios de la teoría de nudos, el matemático alemán Kurt Reidemeister (1893-1971), dio una primera herramienta para determinar cuándo dos diagramas correspondían a nudos equivalentes. Demostró que:
“Dos diagramas representan nudos equivalentes si, y sólo si, se puede pasar de uno a otro mediante un número finito de transformaciones del tipo I, II y III (que se muestran a continuación).”
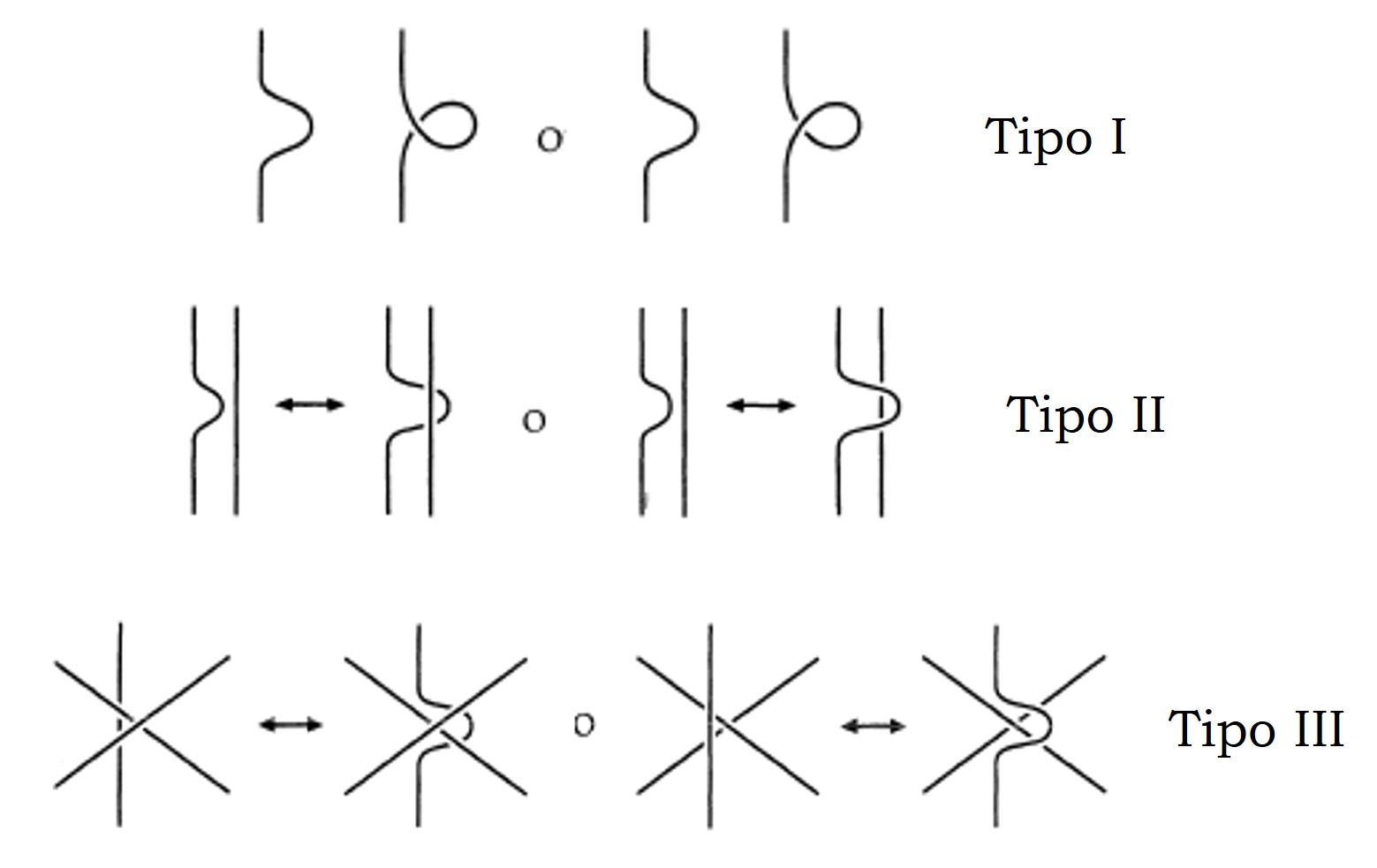
Transformaciones de Reidemeister de tipo I, II y III de los diagramas de nudos
A continuación, vemos un nudo con tres cruces que es equivalente al nudo de trébol, puesto que mediante una serie de movimientos de Reidemeister puede transformarse uno en otro, como se muestra en la siguiente imagen.
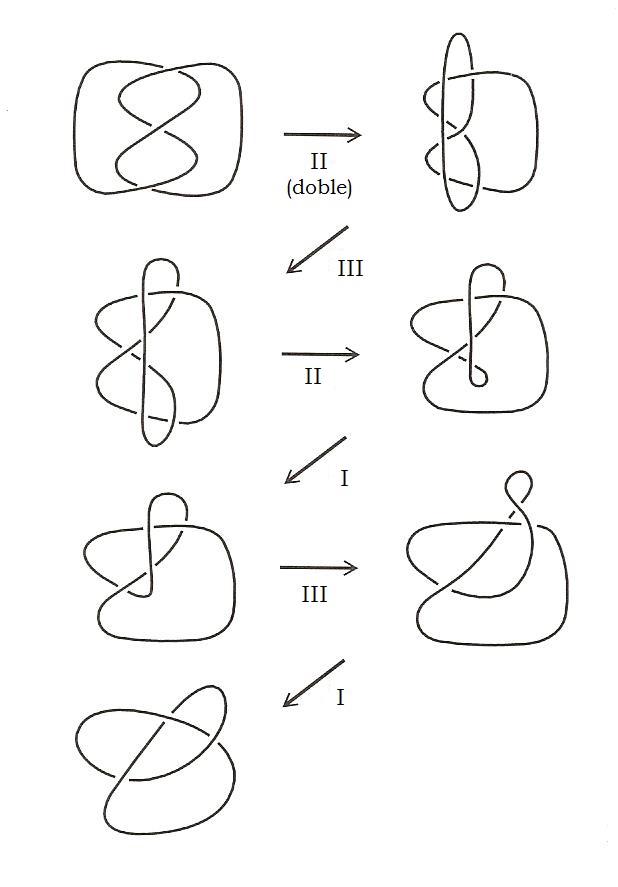
Los movimientos de Reidemeister transforman el diagrama con tres cruces inicial en el diagrama del nudo de trébol, luego ambos son equivalentes, corresponden al mismo nudo topológico
Existe un tipo especial de nudos, aquellos que son equivalentes a su imagen especular. Se llaman nudos anfiquirales. La imagen especular de un nudo es aquella que se obtiene como reflejo en un espejo, es decir, es el nudo simétrico respecto a un plano del espacio. Dado el diagrama de un nudo, entonces el diagrama del nudo imagen especular del primero es igual salvo que tiene los cruces dados la vuelta, es decir, la línea continua se convierte en discontinua, y la discontinua en continua.
El nudo de Saboya es un nudo anfiquiral, como se muestra en la siguiente imagen, mientras que el nudo de trébol puede demostrarse que no es anfiquiral.
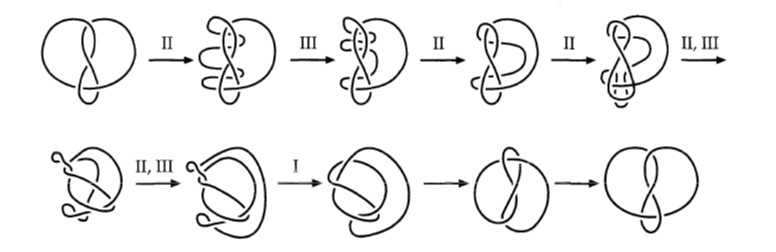
Otra división importante de los nudos de cara a su estudio y clasificación es en nudos primos y nudos compuestos. La idea es descomponer los nudos en otros más simples, los llamados nudos primos, que son los que no se pueden descomponer en otros más simples aún y a partir de los cuales se generan todos los demás, y entonces centrar el estudio general de los nudos en estos.
Por lo tanto, tenemos dos “operaciones” con nudos, que son una inversa de la otra, la descomposición y la suma conexa. Un nudo se descompone mediante una esfera (en el diagrama plano sería una circunferencia) que corta transversalmente al nudo en dos puntos, por los que se corta el nudo generándose dos partes disjuntas, cada una de las cuales se cierra de nuevo al pegar los dos puntos extremos mediante un segmento, generándose así dos nudos. Un nudo es primo si no se puede descomponer en dos nudos no triviales.
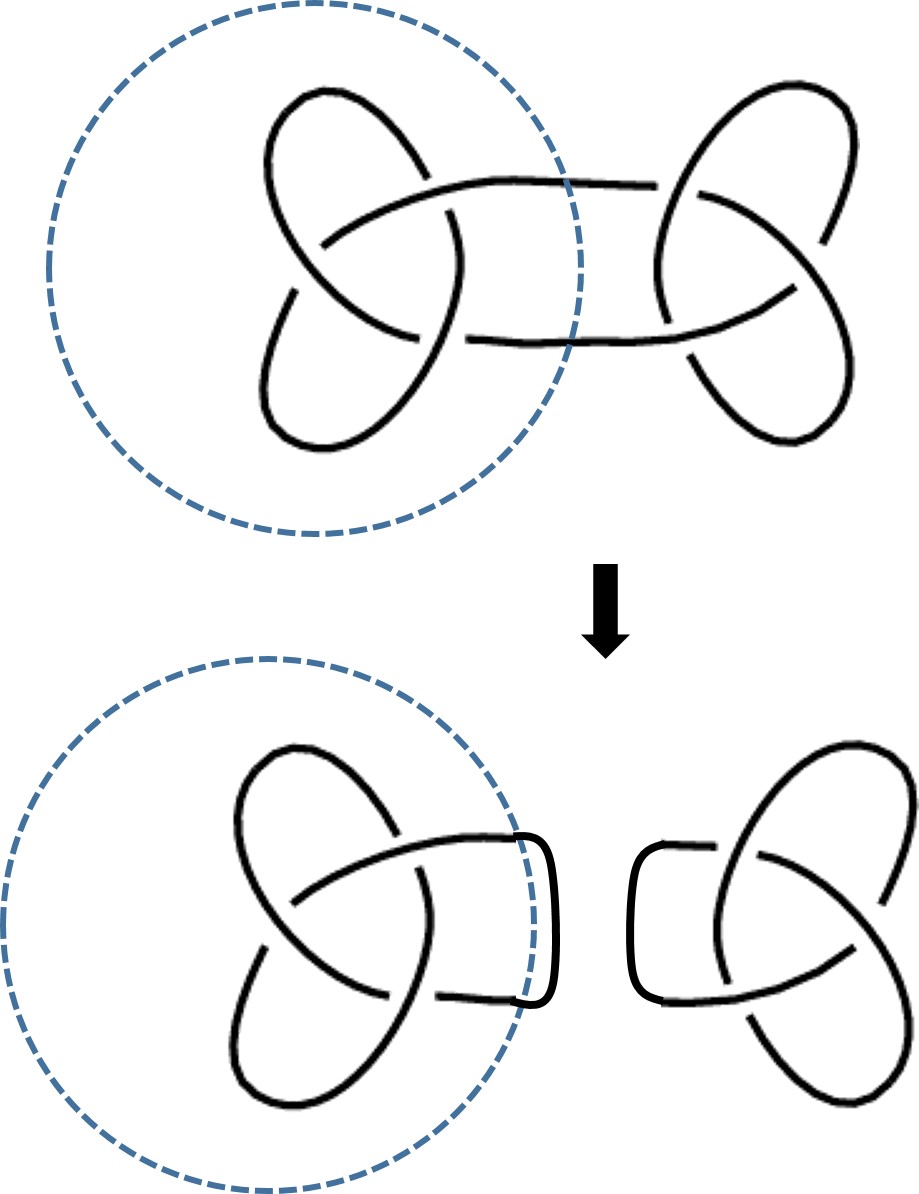
Descomposición del conocido como nudo de la abuela en dos copias del nudo de trébol
Cualquier nudo no primo se obtiene mediante la operación inversa a la anterior, la suma conexa, a partir de un número finito de nudos primos. En la imagen siguiente vemos la suma conexa del nudo de trébol y de su imagen especular, que es el nudo de rizo o nudo cuadrado.
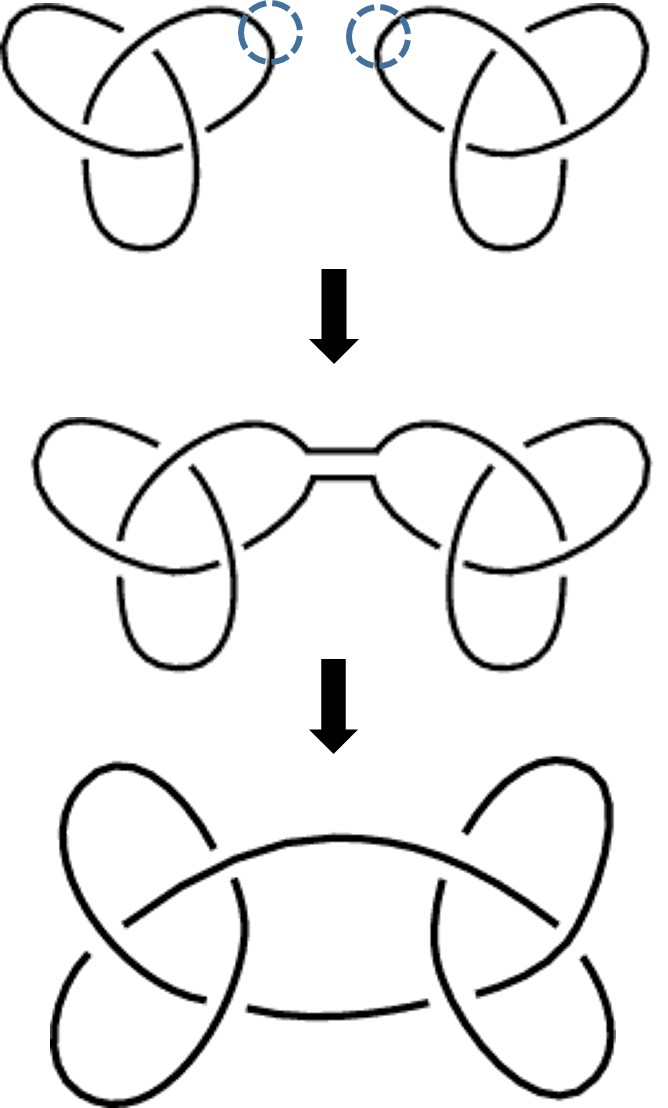
Suma conexa del nudo de trébol y su imagen especular, que es el nudo de rizo, o nudo cuadrado
El nudo de la abuela, que es la suma conexa de dos copias del nudo de trébol, es un nudo no anfiquiral, mientras que el nudo de rizo, que es la suma conexa del nudo de trébol y su imagen especular, sí es anfiquiral. En consecuencia, ambos nudos no son equivalentes.
Algunos de los nombres de los nudos matemáticos, como el nudo del ocho, el nudo de la abuela, el nudo de rizo, el nudo del cirujano o el nudo del amor verdadero, entre otros, derivan de los nombres de los nudos físicos, los nudos utilizados en la navegación y en muchas otras actividades de nuestra sociedad, como la escalada, la medicina, la costura o la decoración, desde la antigüedad.
Según el diccionario de la RAE, un nudo (físico) es un “lazo que se estrecha y cierra de modo que con dificultad se pueda soltar por sí solo, y que cuanto más se tira de cualquiera de los dos cabos, más se aprieta”. En matemáticas, para estudiar cómo de anudado está un nudo se unen los dos cabos del mismo, cerrando el nudo y no dejando que se pueda deshacer.
Poster de estilo vintage con nudos marineros, entre los que están el nudo simple (2), que da lugar al nudo de trébol, el nudo de ocho (3), el nudo de la abuela (4), el nudo de rizo o cuadrado (5) o el nudo doble (7), relacionado con el nudo del cirujano
Pero continuemos con el estudio topológico de los nudos. Con el fin de resolver el problema de la clasificación de los nudos se introducen invariantes de los mismos. Los invariantes son objetos (por ejemplo, un número, un polinomio o un grupo) o propiedades (como la tricoloreabilidad) de un nudo, que tienen el mismo valor para todos los nudos equivalentes. En consecuencia, si un invariante es distinto para dos nudos, estos no pueden ser equivalentes.
Un primer ejemplo de invariante sería el “mínimo número de cruces de un nudo”. Consideremos un nudo N, se define el mínimo número de cruces c(N) del nudo N, como el menor número de cruces que puede tener un diagrama D de N, es decir, si denotamos por c(D) el número de cruces de un diagrama D, sería el mínimo valor de c(D), para todos los diagramas D del nudo N.
Si c(N) = 0, entonces N es el nudo trivial. No existen nudos para los cuales el mínimo número de cruces sea 1 o 2, cualquier diagrama que dibujemos con 1 o 2 cruces se puede transformar mediante movimientos de Reidemeister en el no-nudo. Los únicos nudos con c(N) = 3 son el nudo de trébol, y su imagen especular, mientras que el único con c(N) = 4 es el nudo de Saboya.
La primera clasificación de los nudos la realizó el matemático inglés Peter G. Tait en 1846, sin las herramientas aún de la topología, e incluía todos los nudos primos con mínimo número de cruces menor o igual que 7, que son el no-nudo y los 14 que aparecen en la imagen de abajo (obsérvese que en dicha clasificación no se está distinguiendo entre un nudo y su imagen especular).
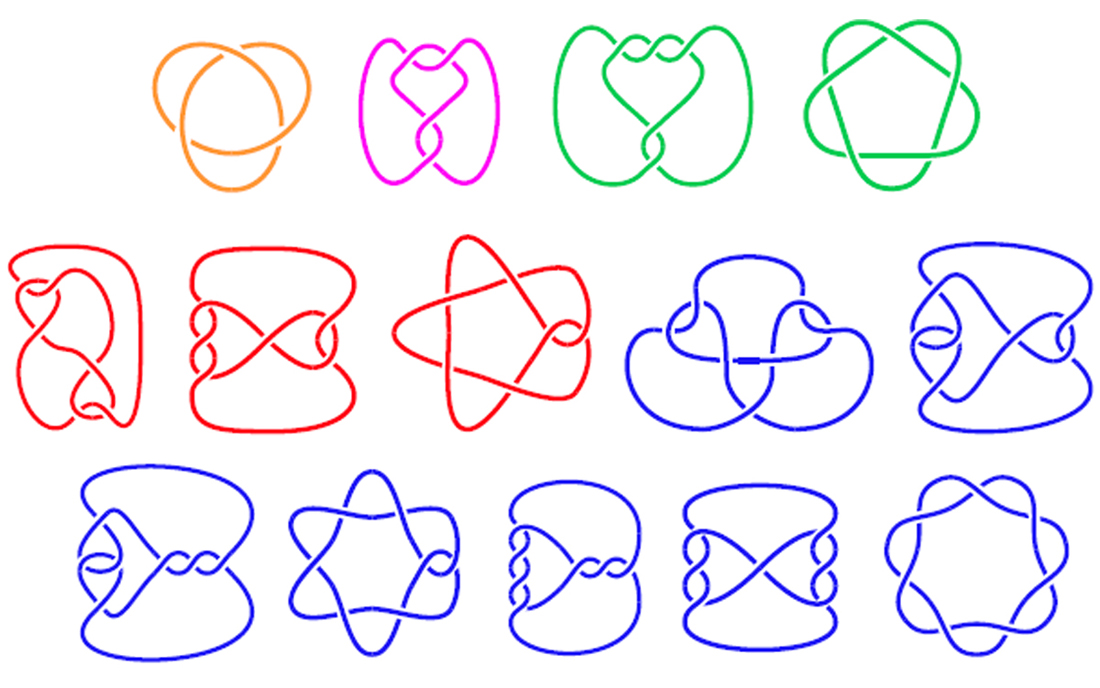
Clasificación de los nudos con mínimo número de cruces menor o igual que 7. Cada color se corresponde con los nudos con el mismo número mínimo de cruces, desde 3 hasta 7
Un invariante sencillo, que nos permitirá distinguir entre algunos nudos que no son equivalentes, es la tricoloreabilidad. Un diagrama se dice que es tricoloreable si, dado un conjunto de tres colores, se puede asignar un color a cada arco del diagrama de forma que: i) se utilizan al menos dos de los tres colores; ii) si en un cruce aparecen dos de los colores, entonces también aparece el tercero.
Se puede demostrar fácilmente que la coloreabilidad no varía con los tres tipos de movimientos de Reidemeister, por lo que, si un diagrama es tricoloreable, lo es cualquier otro equivalente. Es decir, si un diagrama es tricoloreable y otro no, entonces se corresponden con nudos no equivalentes.
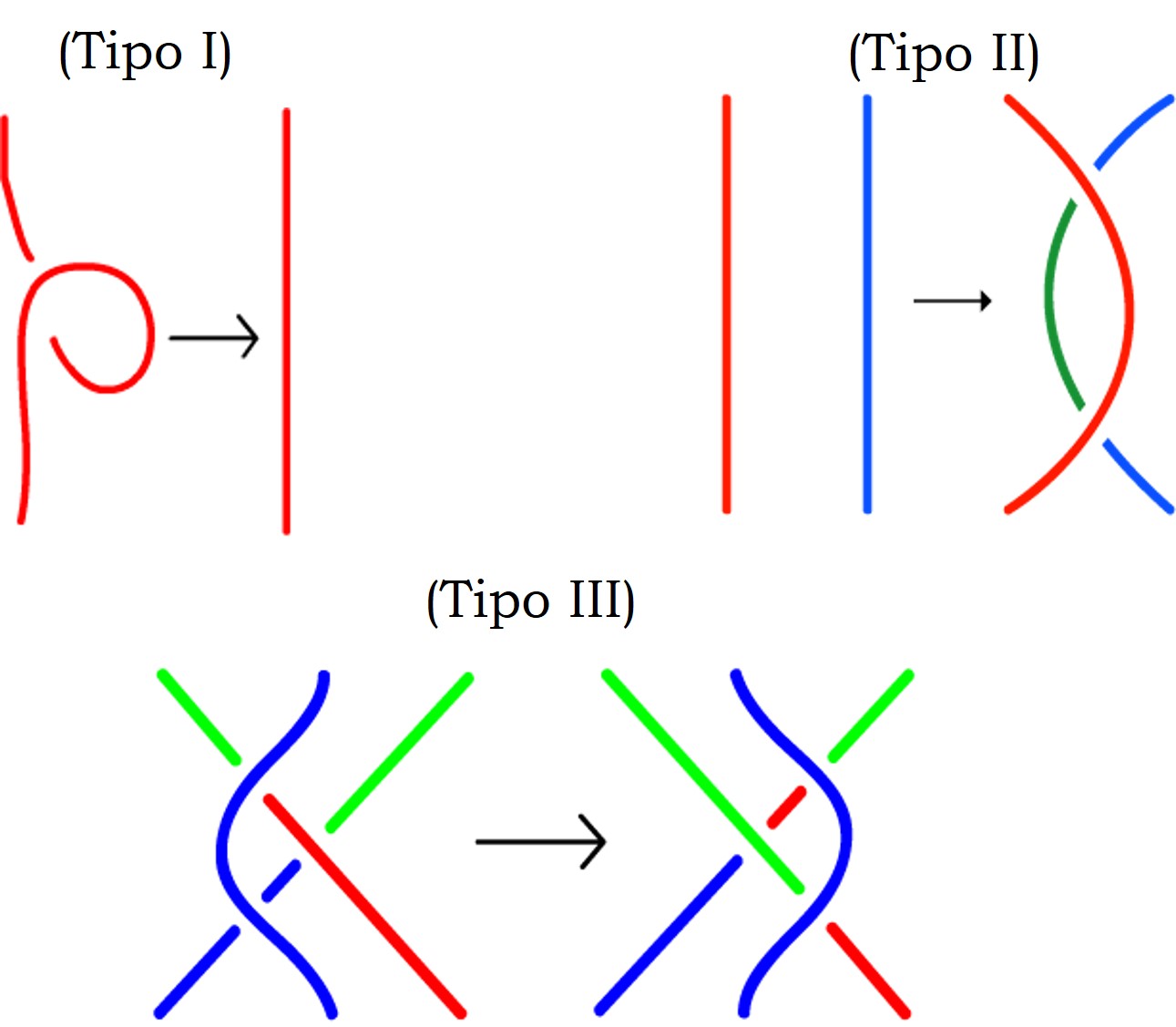
La tricoloreabilidad no varía con los tres movimientos de Reidemeister
El no-nudo es trivialmente no tricoloreable, ya que no se puede utilizar más de un color, el nudo de trébol sí es tricoloreable y el nudo de Saboya no.
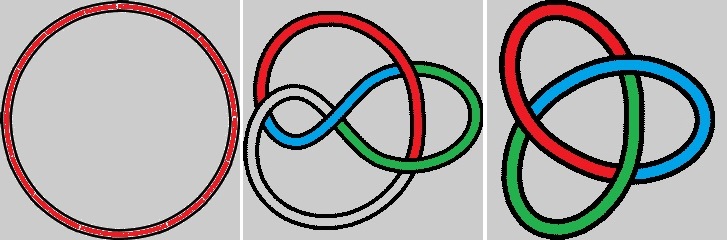
Veamos un ejemplo de cómo distinguir nudos, con el mismo número mínimo de cruces, mediante la tricoloreabilidad. Los nudos 71 y 74, que podemos ver en la clasificación anterior (el primero y cuarto de los nudos con mínimo número de cruces 7), y que tienen mínimo número de cruces, no son equivalentes, ya que 71 no es tricoloreable, mientras que 74 sí lo es.
Claramente el nudo 71 no es tricoloreable, puesto que, si pintamos uno de los segmentos de un color, por ejemplo, rojo, solo pueden ocurrir dos cosas, o todos los demás son también rojos, con lo cual no se utilizan al menos dos colores, o los colores de los demás segmentos quedan determinados y al llegar de nuevo al segmento rojo inicial habrá tres cruces cada uno con dos colores y por cada color elegido para el segmento que falta por marcar se obtienen dos cruces con solo dos colores, como se muestra en la siguiente imagen.
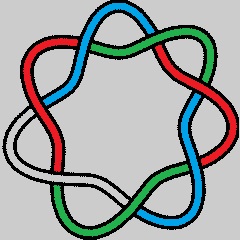
El nudo 71 no es tricoloreable
Mientras que el nudo 74, que es un nudo celta y también el nudo infinito del Budismo, es tricoloreable, como se muestra en la siguiente imagen.
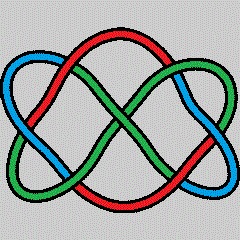
El nudo 74 es tricoloreable
Continuará en mi siguiente entrega de la sección Matemoción del Cuaderno de Cultura Científica…
…CONTINUARÁ…

Colgante con el nudo infinito del budismo
Bibliografía
1.- Museo Guggenheim-Bilbao, Anni Albers, tocar la vista, 6 de octubre de 2017 – 14 de enero de 2018.[]
2.- The Josef and Anni Albers Foundation
3.- Canal de youtube del Museo Guggenheim-Bilbao, Anni Albers, Tocar el viento.
4.- Raúl Ibáñez, La topología modifica la trayectoria de los peces, Cuaderno de Cultura Científica, 2016.
5.- María Teresa Lozano, La teoría de nudos en el siglo XX, Un Paseo por la Geometría 1998/99, Departamento de Matemáticas, UPV/EHU, 1999. Versión on-line en divulgamat
6.- Sergio Ardanza Trevijano, Excursiones matemáticas en biología, Un Paseo por la Geometría 2005/06, Departamento de Matemáticas, UPV/EHU, 2006. Versión on-line en divulgamat
7.- Martín Gardner, Huevos, nudos y otras mistificaciones matemáticas, Gedisa, 2002.
8.- Colin C. Adams, The Knot Book, An Elementary Introduction to the Mathematical Theory of Knots, AMS, 2001.
9.- Stephan C. Carlson, Topology of Surfaces, Knots, and Manifolds, John Wiley and Sons, 2001.
10.- The Knot Atlas
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo La artista Anni Albers, The Walking Dead y la teoría de nudos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La teoría de grafos y “Così Fan Tutte”
- Arthur Cayley, la teoría de grafos y los isómeros químicos
- El quipu: ¿algo más que un registro numérico?
Los tipos celulares humanos y su origen embrionario

El desarrollo embrionario comienza en los animales con la división del óvulo fecundado y las sucesivas subdivisiones posteriores. En las esponjas, tras la quinta subdivisión se forma una larva ovoide de 32 células, a partir de la cual se desarrolla el individuo adulto. En el resto de animales, tras la séptima subdivisión el embrión está formado por 128 células que se disponen en una capa y adopta forma esférica. Ese estado se denomina blástula, y en su interior hay una cavidad denominada blastocele que está llena de líquido o de vitelo.
A continuación se produce la gastrulación; algunas células migran hacia el interior y se disponen en dos capas, de manera que el embrión adopta la forma de un recipiente aproximadamente esférico que delimita una cavidad llena de líquido con una apertura al exterior. Esa configuración se denomina gástrula. Su capa externa es el ectodermo y la interna el endodermo. Los animales diblásticos -cnidarios y ctenóforos- retienen ese esquema básico a partir del cual desarrollan sus estructuras. En los más simples -los cnidarios- el ectodermo da lugar a la epidermis y el endodermo a la gastrodermis, y aunque tienen diversos tipos celulares, esas capas pueden considerarse sus únicos tejidos. En rigor no se puede decir que tengan órganos. En los embriones del resto de animales se desarrolla una tercera capa a partir del endodermo que se dispone entre las otras dos: el mesodermo. Cada una de esas tres capas da lugar a un conjunto de tipos celulares. Se presenta a continuación un breve repaso de los grandes grupos de tipos celulares en la especie humana en función de su origen embrionario.
A partir del endodermo surgen las células secretoras epiteliales de las glándulas exocrinas, que son las que vierten sus productos al exterior o a algunos órganos del sistema digestivo. Son veintisiete tipos celulares. Entre ellas se encuentran las células de las glándulas salivares, glándulas lacrimales, glándulas sudoríparas, próstata, glándulas de Bartholí, y también de glándulas del estómago, como las que producen pepsinógeno o ácido clorhídrico. Origen endodérmico tienen también los treinta y seis tipos celulares que producen hormonas (endocrinas). A este grupo pertenecen, entre otras, las de la pituitaria anterior, un buen número de células propias de los tractos respiratorio e intestinal, de las glándulas tiroides, paratiroides y adrenal, o de los islotes de Langerhans del páncreas.
Del ectodermo derivan principalmente células del tegumento y del sistema nervioso. Hay quince tipos celulares del sistema tegumentario; la mayoría de ellas son células epiteliales queratinizantes. Las del sistema nervioso son mucho más numerosas. Están, por un lado, las transductoras -convierten información sensorial en potenciales eléctricos de membrana-; son dieciséis, aunque si se consideran los cuatro tipos de células fotorreceptoras, habría que contar diecinueve. Por otro lado, tenemos las células del sistema nervioso autónomo, colinérgicas, adrenérgicas y peptidérgicas, con varios tipos celulares dentro de cada categoría. Otros doce tipos corresponden a células que dan soporte a sistemas receptores o a neuronas del sistema periférico. Y por supuesto, a este gran grupo pertenecen las neuronas y células gliales del sistema nervioso central; en esta categoría hay una gran variedad de células de difícil clasificación, pero su número podría rondar los veinticinco. Y para terminar con este grupo, habría que considerar los dos tipos celulares del cristalino.
Finalmente, están las células que derivan del mesodermo. De ese origen son los tres tipos celulares que almacenan grasas (los dos adipocitos y el lipocito del hígado). También lo son los que desempeñan funciones de barrera en el riñón (siete) y en otros órganos (doce). Hay veintiún tipos cuya función es producir matrices de material extracelular. También derivan del mesodermo las células contráctiles (más de una docena) y las de la sangre y del sistema inmunitario (más de veinte). Y para terminar hay ocho tipos celulares de origen mesodérmico que son germinales o que proporcionan soporte y nutrientes a las células germinales.
A la hora de valorar esta información ha de tenerse en cuenta que no todos los especialistas dan por buenas ciertas distinciones entre unos tipos celulares y otros, y que en algunos casos, las categorías no están del todo claras o se encuentran en revisión permanente. Las células nerviosas, por ejemplo, tienen especial dificultad.
A modo de resumen, se puede decir que hay más de sesenta tipos celulares de procedencia endodérmica, más de setenta de procedencia ectodérmica y más de ochenta de procedencia mesodérmica. En conjunto, los seres humanos tenemos más de doscientos veinte tipos celulares. Es muy posible que esa cifra sea muy similar en el resto de primates y, hasta donde sabemos, ningún otro grupo animal hay tal diversidad celular. En otras palabras, en ningún otro grupo hay tal diversificación de funciones o, utilizando una expresión más propia de otras disciplinas, tanta división del trabajo. Hay autores que consideran la diversidad de tipos celulares como un buen indicador de complejidad, por lo que de acuerdo con esa idea, los seres humanos seríamos los animales más complejos. No sé si esa consideración es adecuada, pero si aceptamos que la división del trabajo proporciona una mayor eficacia, quizás si podamos decir que somos la especia con mayor eficacia biológica.
Fuente: List of distinct cell types in the adult human body
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Los tipos celulares humanos y su origen embrionario se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Historia mínima de la complejidad animal
- A mayor tamaño, mayor complejidad
- Sistemas nerviosos: el sistema periférico de vertebrados
El principio de relatividad (y 4): la versión de Einstein

Montaje experimental para la comprobación del principio de relatividad de Einstein en un hotel.
Al formular su propia teoría de la invariancia [1], Einstein lo que va a hacer es ampliar la invariancia de Galileo afirmando que el principio de relatividad debe aplicar a todas las leyes de la física, como las leyes que rigen la luz y otros efectos del electromagnetismo, no solo a la mecánica. Einstein usó este principio como uno de los dos postulados de su teoría, de la cual luego derivó las consecuencias por deducción.
El principio de relatividad de Einstein podría expresarse de la siguiente manera:
Todas las leyes de la física son exactamente las mismas [2] para cada observador en cada marco de referencia que está en reposo o moviéndose con una velocidad relativa uniforme. Esto significa que no hay ningún experimento que se pueda realizar dentro de un marco de referencia que revele si éste está en reposo o moviéndose a una velocidad uniforme.
Como vemos esto no es más que el principio de relatividad de Galileo en el que se ha sustituido “las leyes de la mecánica” por “todas las leyes de la física”.
Como decir repetidamente “marcos de referencia que están en reposo o en velocidad uniforme en relación con otro marco de referencia” es bastante prolijo, los físicos le dan un nombre a este concepto, marcos de referencia inerciales, ya que la ley de inercia de Newton se cumple en ellos. Los marcos de referencia que se aceleran respecto a otros se denominan marcos de referencia no inerciales.
Los marcos de referencia no inerciales no están incluidos en la parte de la teoría de la invariancia que estamos tratando; debido a esta limitación a esta parte de la teoría se la conoce popularmente como teoría de la relatividad especial. Está restringida pues a marcos de referencia inerciales, aquellos que están en reposo o se mueven con una velocidad uniforme relativa entre sí.
Si nos fijamos, según el principio de relatividad en la versión de Einstein, las leyes del movimiento de Newton y todas las otras leyes de la física siguen siendo las mismas para los fenómenos que ocurren en cualquier marco de referencia inercial. Este principio no dice en absoluto que “todo es relativo”. Por el contrario, demanda que busquemos las relaciones que no cambian cuando pasamos nuestra atención de un marco de referencia en movimiento a otro. Las mediciones físicas, pero no las leyes físicas [2], dependen del marco de referencia del observador.
El principio de relatividad es, como decíamos antes, uno de los dos postulados a partir de los cuales Einstein derivó las consecuencias de la teoría de la invariancia. El otro postulado se refiere a la velocidad de la luz, y es especialmente importante cuando se comparan las observaciones entre dos marcos de referencia inerciales en movimiento relativo, ya que dependemos principalmente de la luz para hacer observaciones. Trataremos de él en nuestra próxima entrega de la serie.
Notas:
[1] Popularmente conocida como teoría de la relatividad.
[2] Por eso Einstein se refería a su teoría como teoría de la invariancia, porque las leyes no varían.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo El principio de relatividad (y 4): la versión de Einstein se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El principio de relatividad (2): la versión de Galileo
- El principio de relatividad (3): la invariancia de Galileo
- El principio de relatividad (1): movimiento relativo
La reacción de las madres al llanto de los bebés es universal

Los bebés humanos no se diferencian demasiado de los bebés de otras especie de mamíferos al señalar estados de malestar mediante vocalizaciones que expresan disgusto. Esas situaciones pueden ser la separación de la cría de la madre, el hambre o el malestar físico por algún golpe o enfermedad. Los bebés lloran, pero otras crías de corta edad emiten sonidos equivalentes. De la misma forma, las madres de las especies de mamíferos suelen responder a esos llantos o vocalizaciones recogiendo a la cría, estableciendo alguna forma de contacto físico o comunicándose con ella; a veces también defendiéndola de posibles depredadores o alimentándola. Y en ocasiones son las madres de otros bebés u otras cuidadoras las que reaccionan, mostrando incluso fuertes respuestas emocionales. Esto se ha observado, además de en humanos, en marmotas, focas, gatos, murciélagos, y otras especies.
Dada la gran dependencia de las crías humanas de la atención y cuidado de los adultos, y la larga historia de tal dependencia, no es de extrañar que algunos mecanismos de la respuesta de estos a las crías sean automáticos y se hallen, de alguna forma, impresos en sus sistemas nerviosos. Así, algunas reacciones del sistema nervioso autónomo y del sistema nervioso central de los padres a las caras de los bebés difieren de las respuestas a las caras de los adultos. Pero igualmente podría ocurrir que haya respuestas que varíen en función de factores culturales.
Una investigación reciente ha aportado elementos de interés para valorar en qué medida las respuestas de las madres humanas al llanto de sus bebés son universales o varían de unas culturas a otras. El resultado más sobresaliente de esa investigación es que las madres primíparas (primerizas) responden al llanto de sus criaturas de forma similar, con independencia de sus orígenes culturales1. Todas ellas cogen al bebé en sus brazos y le hablan, pero no tratan de distraerlo, de mostrarles cariño de forma explícita, ni les dan de mamar en esas circunstancias, como hacen las de otras especies de mamíferos. Tanto las madres primerizas al oír llorar a sus criaturas, como otras más experimentadas al oír a otros bebés, muestran patrones comunes de actividad encefálica: se activan el área motora suplementaria -área de la corteza cerebral implicada en la programación, generación y control de acciones motoras y secuencias de habla-, así como las regiones temporales superiores relacionadas con el procesamiento de estímulos sonoros. La activación de esas áreas parece producirse, además, antes de que las madres tengan plena consciencia de que van a responder al llanto, lo que constituye una indicación de la importancia de tal comportamiento en términos, lógicamente, de la supervivencia de la cría.
En mujeres que no son madres, sin embargo, no se producen esas respuestas de la actividad encefálica al llanto de los bebés. Al oírlos, las madres presentan respuestas más pronunciadas que las mujeres que no lo son en zonas encefálicas implicadas en el procesamiento de emociones, lo que, además de su significado funcional, da cuenta de una considerable plasticidad en el encéfalo materno, ya que los cambios en las respuestas pueden producirse en periodos muy breves de tiempo, de tan solo tres meses incluso.
Este estudio pone de manifiesto el carácter universal de la respuesta de las madres al llanto de sus criaturas y de otros bebés. Y sus resultados son acordes con otros trabajos en los que se ha mostrado el amplio surtido de comportamientos maternos que favorecen la supervivencia de la progenie. El llanto es una poderosa herramienta, además de señalar la condición física de los más pequeños (un llanto poderoso es señal de buena condición) es la alarma que se dispara cuando las cosas no van del todo bien. Que la madre responda a la alarma como su mensaje merece no solo favorece la supervivencia de la criatura; si además, responde de forma diferente al llanto que a otro tipo de llamadas que no indican riesgo inminente, el bebé aprende a confiar en la seguridad que le proporciona el vínculo, con lo que ello implica a los efectos de adquirir el comportamiento prosocial tan importante para el resto de su vida en el grupo.
Fuente: Marc H. Bornstein et al (2017): Neurobiology of culturally common maternal responses to infant cry. PNAS
1 Este aspecto concreto de la investigación que ha servido de referencia se estudió en madres de los siguientes países: Argentina, Bélgica, Brasil, Camerún, Francia, Kenia, Israel, Italia, Japón, Korea del Sur, y los Estados Unidos. Los trabajos de actividad encefálica (FMRi) se limitaron a madres de China, Italia y Estados Unidos.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo La reacción de las madres al llanto de los bebés es universal se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Cuando los bebés comienzan a combinar gesto y habla
- Digitalización universal de la computación cuántica analógica en un chip superconductor
- El altruismo en las mujeres se ve recompensado
El pintor que engañó a los nazis, pero no a la química.

Amsterdam tras la liberación (1945)
Amsterdam, junio de 1945
La ciudad había sido liberada y, pese a que las cicatrices que había dejado la guerra tardarían en cerrarse, se respiraba optimismo y alegría en la ciudad. Sin embargo, Han no paraba de dar vueltas en un catre mugriento. La falta de morfina le impedía dormir y la acusación que pesaba sobre su persona no ayudaba en absoluto. A duras penas se levantó y profirió un grito más frío que los barrotes que le confinaban en aquella celda:
-
¡Estúpidos! ¡Idiotas! ¡Eso no es un Vermeer! ¡Esa obra la pinté yo!
Había sido condenado por un crimen que no había cometido. Era inocente. Más o menos.
La Haya, 1928
Desde que en 1913 abandonase los estudios de arquitectura y se dedicase a la pintura, Han van Meegeren se había abierto un hueco en el panorama artístico holandés. No le faltaba talento e incluso había ganado algún que otro premio. Réplicas de su obra, El cervatillo, realizada para la princesa Juliana, colgaban de las paredes de una multitud de casas (Imagen 1). Por si fuera poco, era un reconocido retratista. Pero, tras su segunda exposición en solitario, su carrera sufriría un gran revés. Una crítica supuso su epitafio como pintor: “Posee todas las virtudes, excepto la originalidad”. El estilo de van Meegeren, heredado de los grandes maestros del XVII, no encajaba en el siglo de las nuevas vanguardias. El orgullo y el desprecio por el arte moderno no le permitieron encajar ese golpe. Si sus obras no podían ser admiradas en su época, no le quedaba otro remedio: las haría viajar en el tiempo.

Imagen 1. El cervatillo, de Han van Meegeren (1921). Fuente
{kind=link}
Riviera francesa, 1932
La venganza es un plato que se sirve frío. Pero, además, hay que saber cocinarlo. Han había decidido esconderse en las sombras y elaborar un minucioso plan para ridiculizar al lobby de la crítica artística. Se mudó con su familia a una pequeña localidad de la Costa Azul y se dispuso a pintar una gran obra maestra al estilo de Vermeer. Y no se limitaría a realizar una burda copia, pintaría un original que pudiese haber hecho el famoso pintor. ¿Y por qué elegir a dicho artista? Por una parte, porque había dejado escasas obras para la posteridad y una nueva causaría un tremendo impacto. Por otra, y quizás la más importante, porque cuadros como La callejuela o La joven de la perla le otorgaban, según algunos, el título de mejor pintor de su siglo. Estas cosas hay que hacerlas a lo grande.
{kind=link}
{kind=link}

Imagen 2. Cristo en casa de Marta y María (160×142 cm), de Vermeer (1654-56). Fuente
#/media/File:Johannes_(Jan)_Vermeer_-_Christ_in_the_House_of_Martha_and_Mary_-_Google_Art_Project.jpg){kind=link}
Pero para pintar como el genio de Delft hacía falta algo más que sed de venganza y un aplastante dominio de la técnica. Había que mimar los detalles hasta el extremo. Van Meegeren hizo acopio de los pigmentos que usaba el flamenco (bermellón, blanco de plomo, lapislázuli, etc.) e incluso fabricó sus propios pinceles siguiendo la costumbre de la época. Por otra parte, recopiló auténticas obras del siglo XVII. Las obras por sí mismas no le importaban lo más mínimo, pero necesitaba lienzos que hubiesen sufrido el desgaste de 300 años. Con precisión de cirujano eliminó la pintura sobre el lino y así consiguió el soporte ideal para sus cuadros. Durante los siguientes años se dedicó a perfeccionar su técnica hasta que estuvo seguro de que nadie le descubriría. Una vez listo, sólo faltaba seleccionar el tema para su obra y qué mejor que recurrir a otro gran maestro del que Vermeer había recibido influencias: Caravaggio. La cena de Emaús sería el tema elegido.

Imagen 3. Cena de Emaús (140×197 cm) de Caravaggio (1596-1602). Fuente
#/media/File:1602-3_Caravaggio,Supper_at_Emmaus_National_Gallery,_London.jpg){kind=link}
Seguro que van Meegeren no podía estar más satisfecho al dar su última pincelada. Pero todavía quedaba un tremendo obstáculo. La pintura al óleo se va secando y agrietando con los años. Con aquel cuadro todavía húmedo no engañaría a ningún experto. Pero, como decíamos, todo estaba cuidado hasta el extremo. El holandés había mezclado los pigmentos con baquelita, un polímero que se endurece con el calor. Sólo quedaba meter el lienzo en el horno. Tras sacarlo, le dio una capa de barniz y lo enrolló de modo que surgiesen craqueladuras en las marcas que habían dejado las antiguas obras sobre los soportes reusados. Y como quiera que los cuadros acumulan suciedad a lo largo de los años (y no digamos de los siglos), ensució la superficie para deslucir su reciente creación. Lo había conseguido: había pintado un Vermeer.
Mónaco, Septiembre de 1937
El corazón del doctor Abraham Bredius nunca había latido tan rápido. Un tratante le había hecho llegar un cuadro para examinar (Imagen 4). No cabía duda. Era una obra maestra de Vermeer o, según sus propias palabras, era “la gran obra maestra” de Vermeer. Y él lo haría público. Una medalla más en su gloriosa carrera.

Imagen 4. La cena de Emaús (115-127 cm), de Han van Meegeren (1936-37). Fuente
{kind=link}
A Hans van Meegeren solo le faltaba dar el último estoque. Según sus planes, había llegado el momento de humillar a la crítica y a esos supuestos expertos en arte encabezados por Bredius. Pero algo le hizo cambiar de opinión. Se sospecha que la fortuna que había logrado con la venta del cuadro tuvo algo que ver (más de cuatro millones y medio de euros al cambio actual). Con ese dinero compró una mansión en Niza y siguió trabajando con la técnica que tanto había tardado en depurar.
Berlín, agosto de 1943
Las fuerzas del Eje han perdido el Norte de África, pronto caerá Italia. Quizás por eso Hermann Göring decide poner a salvo su incomparable colección de arte. En ella destaca una obra de Vermeer: Cristo entre los adúlteros (Imagen 5).

Imagen 5. Cristo entre los adulteros (96×88 cm), de Han van Meegeren (1943). Fuente
Mina de sal de Altausse (Austria), mayo de 1945
La Segunda Gran Guerra llega a su fin y los aliados siguen ganando terreno. Al entrar en la mina de sal de Altausse encuentran cientos de cajas almacenadas con un total de más de 6000 obras de arte (Imagen 6). El valor de aquellas piezas es incalculable. Hay una que hará especial ilusión al recién liberado pueblo holandés, una que lleva la firma insigne de Vermeer.

Imagen 6. Obras de arte encontradas en posesión de los nazis en las minas de sal de Altausse (1945). Fuente
{kind=link}
Las investigaciones de las autoridades holandesas no se hacen esperar y el comerciante nazi que había vendido la obra a Göring pronto confiesa el origen de aquella pieza. Todos los focos apuntan hacia un pintor holandés que había desaparecido del panorama artístico: Han van Meegeren. Había expoliado patrimonio de su propio país, había negociado con los invasores. Aquello era alta traición y se pagaba con la vida.
Amsterdam, finales de 1945
Han van Meegeren se jugaba la cabeza con cada pincelada. Había conseguido esquivar la condena, pero solo a cambio de demostrar que era capaz de falsificar un Vermeer. Durante seis semanas tuvo lugar uno de los juicios más peculiares de la historia. El pintor no solo exigió su material, sino también tabaco, alcohol y morfina, alegando que le eran completamente necesarias para desatar su creatividad. Volvió a elegir un cuadro en el que Cristo era el gran protagonista: Jesús entre los doctores. Pese a que su técnica había empeorado, consiguió salvar el cuello. En aquella corte se pintó el último Vermeer (Imagen 7).

Imagen 7. Han van Meegeren pintando su última obra enfrente de un panel de expertos (1945). Fuente
Amsterdam, finales de 1947
Quien es capaz de crear un Vermeer puede crear cualquier historia. Van Meegeren esgrimió que sus obras solo tenían la finalidad de engañar a los nazis para salvar el patrimonio patrio. Había pasado de traidor a héroe. Una encuesta realizada ese mismo año le situaba como la persona más popular de su país, solo tras el primer ministro y por encima del propio principie, para cuya mujer había pintado aquel cervatillo cuando todavía era un pintor honesto.
En cualquier caso, el falsificador se enfrentaba ahora a cargos de fraude. En este juicio no sería necesario que cogiese de nuevo el pincel. Su modus operandi quedaría al descubierto gracias a pruebas más fiables: entraba en acción la evidencia científica. Y lo hacía de la mano de Paul Coremans, doctor en Química Analítica y responsable científico de Museos Reales de Bellas Artes de Bélgica. Gracias a meticulosos análisis químicos se confirmó la presencia de baquelita (polímero comercializado a partir de 1910), tal y como van Meegeren había confesado. Además, se hallaron rastros de Albertol, una resina sintetizada en 1910 que habían encontrado en el taller del falsificador, y azul cobalto, pigmento descubierto en 1802 y que, obviamente, Vermeer nunca pudo usar (Imagen 8). La suciedad escondida entre las craqueladuras, que tanto habían ayudado a engañar a los expertos, resultó no ser natural, sino tinta india con la que van Meegeren había dado un toque añejo a sus pinturas.
Frente al tribunal y la multitud que seguía el juicio, Coreman fue mostrando las evidencias una a una. El propio van Meegeren quedó impresionado – Un trabajo excelente, señoría- le confesó al juez. Sin duda, aquel 29 de octubre marcó un antes y un después en cuanto a la importancia de los estudios científicos en obras artísticas.

Imagen 8. Pruebas presentadas contra van Meegeren en la acusación de fraude. Fuente
{kind=link}
Dos semanas después Van Meegeren fue condenado a un año a prisión, aunque jamás cumpliría dicha condena. El hombre que engañó a Göring falleció el 30 de diciembre. No sin antes haber visto consumada su venganza.
Han van Meegeren fue uno de los mejores falsificadores de todos los tiempos, el mejor si hacemos caso a la opinión del propio Coreman. Posiblemente su engaño no se hubiese descubierto hasta mucho después de no haberse visto envuelto en esta rocambolesca historia. Algo que nos lleva a pensar cuántos falsificadores habrá de los que no conozcamos ni el nombre. ¿No son esos realmente los mejores? Aquellos cuyas obras descansan en las paredes de museos y colecciones privadas sin que nadie se percate, a la espera de que algún estudio científico desvele su verdadero origen. Para reflexionar sobre este hecho acabemos con una sentencia que dejó durante su juicio el protagonista de nuestro relato:
“Ayer esta pintura valía millones y expertos y amantes del arte hubiesen venido de cualquier parte del mundo para admirarla. Hoy no vale nada, y nadie cruzaría la calle ni para verla gratis. Pero la pintura no ha cambiado. ¿Qué es lo que ha cambiado?”
Epilogo
Tras la muerte de van Meegeren hubo quien se negó a creer su confesión y llegó a denunciar a Coreman por devaluar las obras de arte que seguían considerando auténticos Vermeers. En 1968, la revista Science publicaba un artículo en el que el estudio de radioisótopos de polonio y radio demostraba que obras como La cena de Emaús habían sido pintadas en el siglo XX (sirve este artículo también para hacer arqueología científica y ver que diferentes eran las publicaciones de aquella época). Desde entonces los métodos científicos han ido avanzando y se han realizado nuevos análisis (presencia de impurezas, análisis cromatográficos, etc.) que siguen descubriendo fallos en las falsificaciones de van Meegeren, dejando en evidencia que hoy sería casi imposible engañar a todo el mundo como él hizo.
Para saber más
R. C. Willams “The Forensic Historian: Using Science to Reexamine the Past” M.E. Sharpe (2013).
J. S. Held (1951) “Reviewed Works: Van Meegeren’s Faked Vermeers and de Hooghs: A Scientific Examination by P. B. Coremans, A. Hardy, C. M. Hutt; Back to the Truth: Vermeer–Van Meegeren, Two Genuine Vermeers by Jean Decoen, E. J. Labarre” College Art Journal, 10 (4) 432-436. DOI: 10.2307/772736
Essential Vermeer: Han van Meegeren’s Fake Vermeers
Essential Vermeer: Vermeer: Erroneous Attributions and Forgeries
B. Keisch (1968) “Dating Works of Art through Their Natural Radioactivity: Improvements and Applications” Science 160 (3826) 413-415 DOI: 10.1126/science.160.3826.413
Sobre el autor: Oskar González es profesor en la facultad de Ciencia y Tecnología y en la facultad de Bellas Artes de la UPV/EHU.
El artículo El pintor que engañó a los nazis, pero no a la química. se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- #Naukas14 La química del arte…pero bien
- Los cimientos de la química neumática al estilo van Helmont (y 3)
- Biringuccio, la química práctica y rentable del XVI
Naukas Bilbao 2017- Daniel Torregrosa: ¡Estamos rodeados!
En #Naukas17 nadie tuvo que hacer cola desde el día anterior para poder conseguir asiento. Ni nadie se quedó fuera… 2017 fue el año de la mudanza al gran Auditorium del Palacio Euskalduna, con más de 2000 plazas. Los días 15 y 16 de septiembre la gente lo llenó para un maratón de ciencia y humor.

Daniel Torregrosa nos advierte, por si no lo supiésemos, de que estamos rodeados de químicos. Y pone algunos ejemplos. Imposible permanecer impasible ante semejantes barbaridades.
Daniel Torregrosa: ¡Estamos rodeados!Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Naukas Bilbao 2017- Daniel Torregrosa: ¡Estamos rodeados! se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Naukas Bilbao 2017, en directo
- Naukas Pro 2017: Amaia Zurutuza y el grafeno
- Naukas Pro 2017: Carlos Briones y el origen de la vida