

Polímeros biocompatibles para integrar dispositivos electrónicos en nuestro cuerpo

“En el campo de la bioelectrónica existe la necesidad de crear una nueva generación de materiales con propiedades mecánicas blandas, conductividad iónica y electrónica, y compatible con los tejidos biológicos”, indica Isabel del Agua López autora del estudio. El polímero conductor más exitoso en aplicaciones bioelectrónicas hoy en día es el PEDOT (poli 3,4-etilendioxitiofeno), comúnmente dopado con PSS (Poli(3,4-etilendioxitiofeno)-poli(estireno sulfonato)) dada su gran conductividad tanto electrónica como iónica, su biocompatibilidad, así como la estabilidad, etc.
Actualmente, “el PEDOT se comercializa dopado con PSS, pero uno de los inconvenientes es que así no es biofuncional. Por este motivo, para mejorar su biocompatibilidad este estudio se ha centrado en la fabricación de nuevos materiales de PEDOT estabilizado con polisacáridos como la goma xantana y la goma guar en lugar de con PSS, con el fin de que el material se integre mejor en nuestros tejidos”, explica del Agua López.

Partiendo de las combinaciones PEDOT:polisacárido que han sido realizadas en este trabajo por primera vez, se han creado dos nuevos materiales. Por un lado, los geles iónicos de PEDOT, que son únicos ya que nunca antes se había fabricado un gel iónico que a su vez contuviese PEDOT. “Este material presenta propiedades únicas que surgen de la combinación de materiales del que está hecho. Presenta conductividad electrónica dada por el PEDOT, conductividad iónica por el líquido iónico y la elasticidad impartida por el polisacárido goma guar”, explica la investigadora de la UPV/EHU. En general, “este material supera a los hidrogeles de PEDOT que ya existen, ya que no se seca, es más estable y no pierde ni sus propiedades mecánicas ni su conductividad”, añade. En la actualidad se están investigando sus propiedades y aplicaciones en bioelectrónica entre las que destaca su uso como electrodos cutáneos para electrofisiología. Sobre la piel, estos materiales transmiten la actividad eléctrica de nuestro cuerpo a los electrodos para su registro. Así se consigue registrar, por ejemplo, la actividad de nuestro corazón (electrocardiografía) o la de nuestros músculos (electromiografía).

Por otro lado, “el segundo material que hemos fabricado —señala del Agua López— a partir de la combinación de PEDOT:polisacárido son las estructuras tridimensionales porosas denominadas scaffolds que sirven de soporte para el crecimiento tridimensional de células y formación de tejidos”. Gracias al contenido del polisacárido y a sus poros interconectados, las células presentan una especial afinidad por estos andamios. “Se ha demostrado que tanto la porosidad como las propiedades mecánicas de estos materiales se pueden modificar muy fácilmente dependiendo de la aplicación para la que se los quiere usar. Variando el contenido de PEDOT y de polisacárido los poros pueden tener mayor o menor diámetro y el andamio en su conjunto ser más blando o más duro”, indica. “El desarrollo de scaffolds basados en PEDOT pretende no solo facilitar el crecimiento celular sino también controlarlo”, añade Isabel del Agua.
A la vista de los resultados obtenidos, “las propiedades únicas de estos materiales poliméricos pueden llevar al campo de la bioelectrónica hacia nuevas aplicaciones, ya que estos materiales consiguen integrar dispositivos electrónicos con nuestro cuerpo e incluso a mejorar las aplicaciones actuales”, subraya la autora del trabajo.
Referencias:
Mantione, D. , del Agua, I. , Schaafsma, W. , Diez‐Garcia, J. , Castro, B. , Sardon, H. and Mecerreyes, D. (2016) Poly(3,4‐ethylenedioxythiophene):GlycosAminoGlycan Aqueous Dispersions: Toward Electrically Conductive Bioactive Materials for Neural Interfaces. Macromol. Biosci. doi:10.1002/mabi.201600059
Isabel del Agua, Sara Marina, Charalampos Pitsalidis, Daniele Mantione, Magali Ferro, Donata Iandolo, Ana Sanchez-Sanchez, George G. Malliaras, Róisín M. Owens, and David Mecerreyes (2018) Conducting Polymer Scaffolds Based on Poly(3,4-ethylenedioxythiophene) and Xanthan Gum for Live-Cell Monitoring ACS Omega doi: 10.1021/acsomega.8b00458
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Polímeros biocompatibles para integrar dispositivos electrónicos en nuestro cuerpo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Sin moda no hay futuro

Soy periodista especializada en moda. Me licencié en periodismo, cursé un máster en moda y posteriormente me doctoré. Empecé a publicar mis artículos en conocidas revistas de moda mientras hacía mi tesis doctoral. Para obtener el doctorado era imprescindible tener al menos un artículo publicado en alguna de las revistas de más impacto del momento, o al menos, varios artículos en revistas medianamente buenas y reconocidas dentro del sector.
Por aquel entonces, mientras hacía el doctorado, yo disfrutaba de una beca estatal. Era una beca insuficiente, apenas me permitía hacer frente al alquiler, así que en ocasiones tuve que pedir ayuda a mi familia y compaginarlo con trabajos que poco tenían que ver con la moda. Todo muy precario. El gobierno nos había dado financiación a un grupo de periodistas para llevar a cabo un proyecto de investigación en moda. Con ese dinero hacíamos toda nuestra labor investigadora y cubríamos los gastos que generaba, desde la asistencia a la Fashion Week de Madrid, Milán o París, cosa que era todo un logro curricular, a todos los materiales que necesitásemos para llevar con éxito la investigación. Finalmente conseguí mi ansiado doctorado.
Yo tenía muy claro que quería seguir trabajando como periodista de moda. Desgraciadamente es un mundo muy competitivo y que destaca por la precariedad laboral, especialmente para jóvenes y para mujeres, y yo era ambas cosas. Pero mi sueño era seguir en el mundo de la moda. La moda es súper importante, todo el mundo lo sabe.
Conseguí seguir investigando en moda. Estuve trabajando en universidades públicas, en centros de investigación, incluso hice varias estancias en el extranjero. Puse todo mi empeño en ello y tuve que sortear obstáculos muy complicados durante años, sobre todo largos periodos de incertidumbre, poca estabilidad laboral, y un bajo nivel de ingresos. Todo lo hice por la moda.
La concesión de becas gubernamentales y financiación depende en gran medida de la calidad de las revistas de moda para las que escriba y de la cantidad de veces que mis artículos sean citados por otros compañeros de profesión en sus respectivos artículos. Cuantas más veces publique en revistas como Vogue, Harper’s Bazaar, Elle o InStyle, más opciones tengo de seguir en esto de la moda. Y cuantas más veces se citen esos artículos, más prestigio tendré dentro del mundo de la moda y, por tanto, más probabilidades de seguir viviendo de esto y de obtener financiación.
Por eso, en cuanto escribo un artículo sobre moda que creo que puede ser suficientemente bueno para alguna de estas revistas, lo envío. Estas revistas son empresas privadas. Se encargan de reenviar mi artículo a otros periodistas especializados en moda que revisan la calidad de mi trabajo y evalúan si, efectivamente, se trata de un artículo que merece ser publicado. Pueden ocurrir tres cosas, que acepten el artículo tal cual, que lo rechacen, o que lo acepten con correcciones. Es decir, los revisores trabajan como editores. Como la moda es súper importante, estos editores no cobran a las revistas por hacer su trabajo de revisión de artículos. Revisar artículos gratis es algo que todos hacen por el buen funcionamiento de la moda.
Si la revista acepta el artículo, fenomenal. Si no, pues pruebas con otras revistas menos conocidas, a ver quién lo quiere. También puedes pagarles para que lo publiquen. De lo que se trata es de publicar.
Las revistas tampoco nos pagan por nuestros artículos. Investigamos sobre moda y todo lo que sale de ahí se lo damos a las revistas de forma gratuita. De hecho, muchas revistas incluso nos cobran por publicar. Lo hacen porque pueden, porque mi sueldo depende de lo que yo haya publicado. Ningún organismo público financiaría mis investigaciones en moda si luego no se publican en las revistas. Así que hay revistas que llegan a pedir varios miles de euros a cambio de publicar tu trabajo. Se destina el dinero público no solo a la moda en sí, si no a publicar, y a veces esto representa un porcentaje muy alto de los fondos del proyecto.
En los años 90 estas revistas al menos hacían el trabajo de maquetación y diseño del artículo. Ahora no hacen ni eso. Somos los propios periodistas de moda los que tenemos que adaptarnos a un manual de estilo y entregar el artículo tal cual como aparecerá en la revista, incluyendo fotografías e infografías. Ahora muchas de ellas ni siquiera hacen distribución en papel. Eso sí, la suscripción a estas revistas, aunque solo existan online, sí te la cobran y es muy cara, pero claro, para cualquier periodista especializado en moda como yo es fundamental estar al tanto de todas las tendencias y de todo lo que se cuece en el mundo de la moda. Así que, o bien se paga individualmente por cada artículo que quiera leer, o bien la institución en la que trabajo paga la suscripción para que todos tengamos acceso a ella. Es decir, para acceder a la revista que haya publicado mi artículo, también tengo que pagar. Y cualquier otra persona que quiera comprarse la revista, obviamente también tendrá que pagarla de su bolsillo.
Estas revistas tienen unos ingresos anuales superiores a 22 mil millones de euros y un margen de beneficios cercano al 40%, muy superior al de Apple, Google o Amazon. No es de extrañar, porque es un negocio redondo.
En el caso de España se negocia una licencia nacional y por ejemplo, simplemente para que las universidades y los centros de investigación puedan estar suscritos a la Vogue, el coste para nuestras arcas públicas asciende a 24 millones de euros al año.
Los gobiernos son clientes cautivos de estas revistas. Y si quieres ser un país realmente puntero en el mundo de la moda, tienes que estar suscrito y pagar el acceso a ellas con fondos públicos. Sin embargo, no todos los gobiernos pueden pagarlo. Como en el caso de Perú, que no ha renovado la suscripción a la Vogue desde el año pasado. Por ese motivo surgieron repositorios piratas de artículos y es común que algunas personas compartan sus claves de acceso a las revistas online. La suscripción a la Vogue es cada año más cara, igual que la de InStyle o Harper’s Bazaar, y no todas las instituciones pueden costear la suscripción a todas ellas.
Así es como funciona la moda. Y la moda hay que hacerla.

Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo Sin moda no hay futuro se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:‘Imago mundi’, finalmente 9 retratos más del mundo
Con esta entrada termina la serie Imago Mundi de la sección Matemoción del Cuaderno de Cultura Científica, que hemos dedicado a mostrar diferentes retratos del mundo, realizados con diferentes proyecciones cartográficas (matemáticas). En la primera entrega, ‘Imago mundi’, 7 retratos del mundo, las 7 proyecciones cartográficas utilizadas fueron: la proyección cilíndrica conforme de Mercator, la proyección pseudo-cilíndrica isoareal de Mollweide, la proyección pseudo-cilíndrica isoareal de Eckert IV, la proyección isoareal interrumpida homolosena de Goode, la proyección convencional de Van der Grinten, la proyección central, que preserva los caminos más cortos, y la proyección estereográfica, que es conforme.
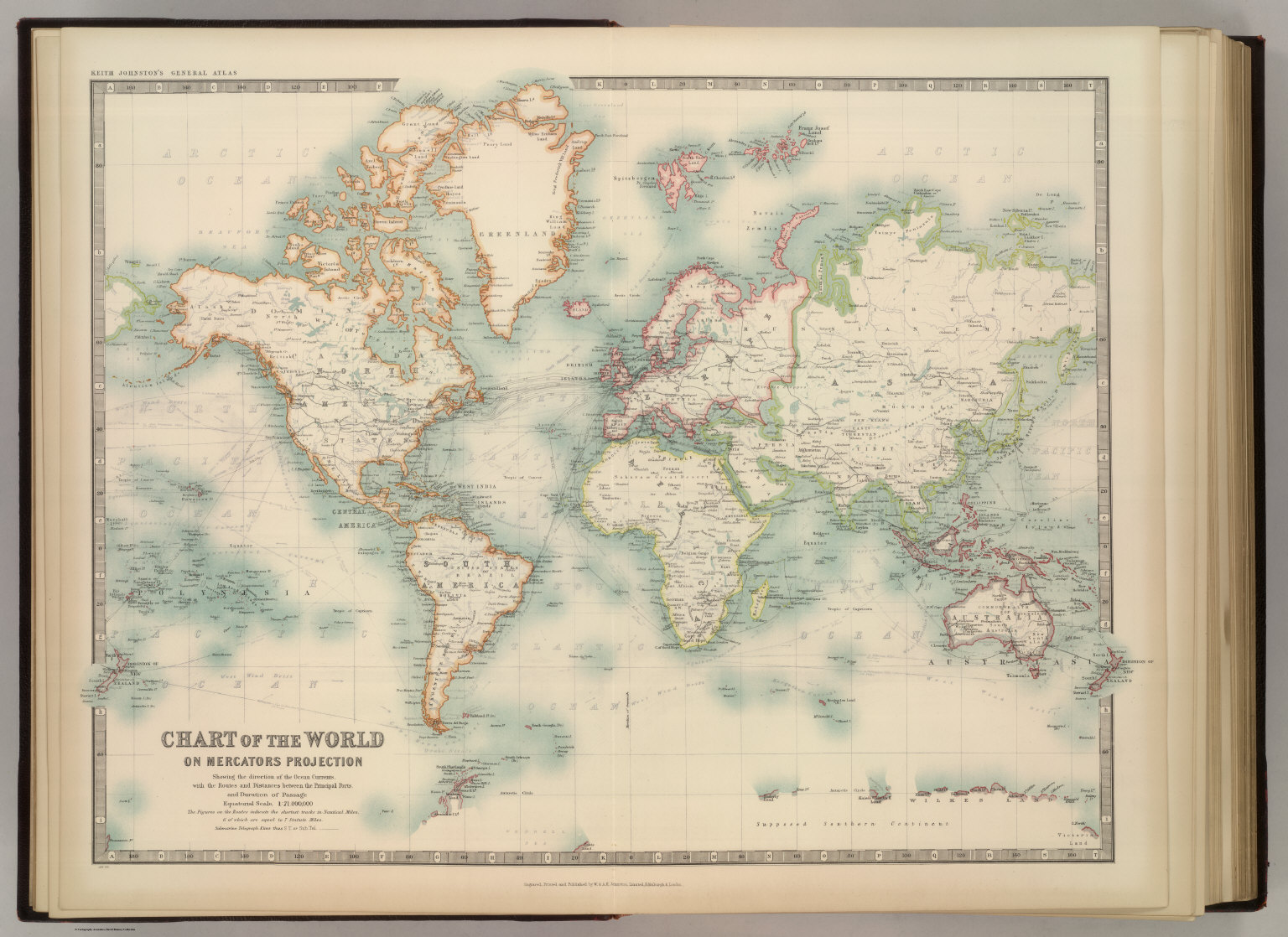 Mapa de mundo realizado con la proyección de Mercator, mostrando las corrientes oceánicas, así como las rutas y distancias entre los puertos más importantes, perteneciente a la publicación “The Royal Atlas Of Modern Geography Exhibiting”, W.& A.K. Johnston, 1912. Imagen de [1]Mientras que, en la segunda entrega, ‘Imago mundi’ 2, otros 6 retratos del mundo las proyecciones eran: la proyección rectangular o carta plana, la proyección cilíndrica de Miller, la proyección de Gall-Peters, con toda la familia de proyecciones cilíndricas isoareales a la que pertenece esta, la proyección de Robinson, la proyección de Winkel tripel y la proyección acimutal equidistante.
Mapa de mundo realizado con la proyección de Mercator, mostrando las corrientes oceánicas, así como las rutas y distancias entre los puertos más importantes, perteneciente a la publicación “The Royal Atlas Of Modern Geography Exhibiting”, W.& A.K. Johnston, 1912. Imagen de [1]Mientras que, en la segunda entrega, ‘Imago mundi’ 2, otros 6 retratos del mundo las proyecciones eran: la proyección rectangular o carta plana, la proyección cilíndrica de Miller, la proyección de Gall-Peters, con toda la familia de proyecciones cilíndricas isoareales a la que pertenece esta, la proyección de Robinson, la proyección de Winkel tripel y la proyección acimutal equidistante.
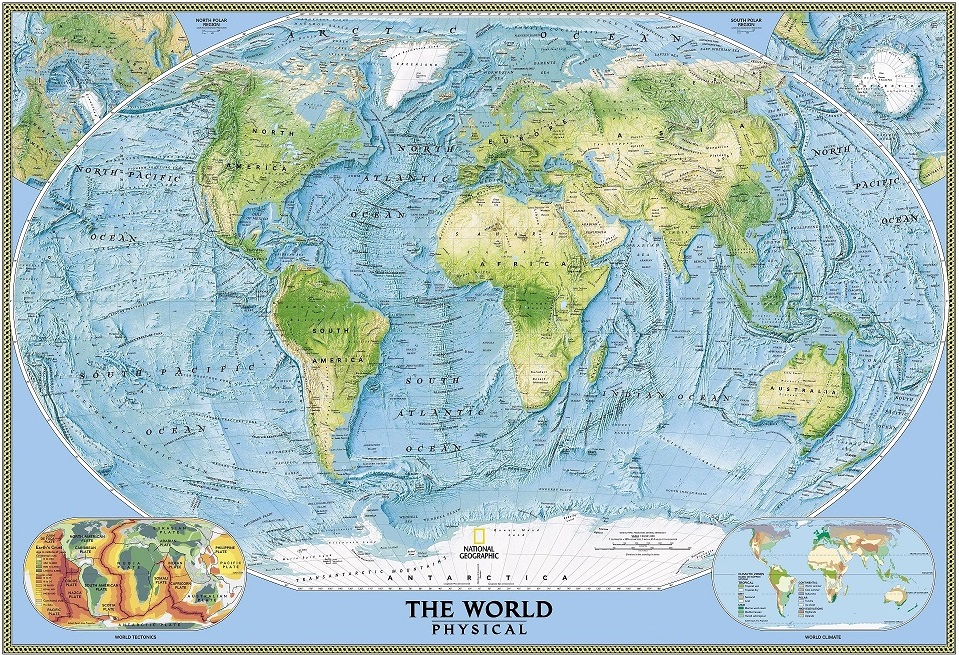 Mapa físico del mundo de National Geographic, realizado con la proyección de Winkel tripel, en 2005, revisado en 2007
Mapa físico del mundo de National Geographic, realizado con la proyección de Winkel tripel, en 2005, revisado en 2007Pero vayamos directamente a los retratos de esta tercera, y última, entrega de la serie.
Retrato 1: La proyección en perspectiva general
Si preguntáramos a la gente por la forma correcta de representar la superficie terrestre en un plano, muchas personas nos dirían que es realizando un retrato, o fotografía, desde un punto cualquiera del espacio. Esta es la conocida como proyección en perspectiva general.
La proyección en perspectiva general es una proyección geométrica azimuthal, que consiste en proyectar la superficie de la Tierra sobre un plano desde un punto de proyección mediante las rectas o “rayos” de proyección, es decir, como si estuviesemos mirando desde ese punto. Dependiendo de la posición del plano de proyección hablamos de perspectiva vertical o inclinada. La perspectiva es vertical si el plano es perpendicular a la recta que une el punto de proyección con el centro de la superficie terrestre, en otro caso, es inclinada.
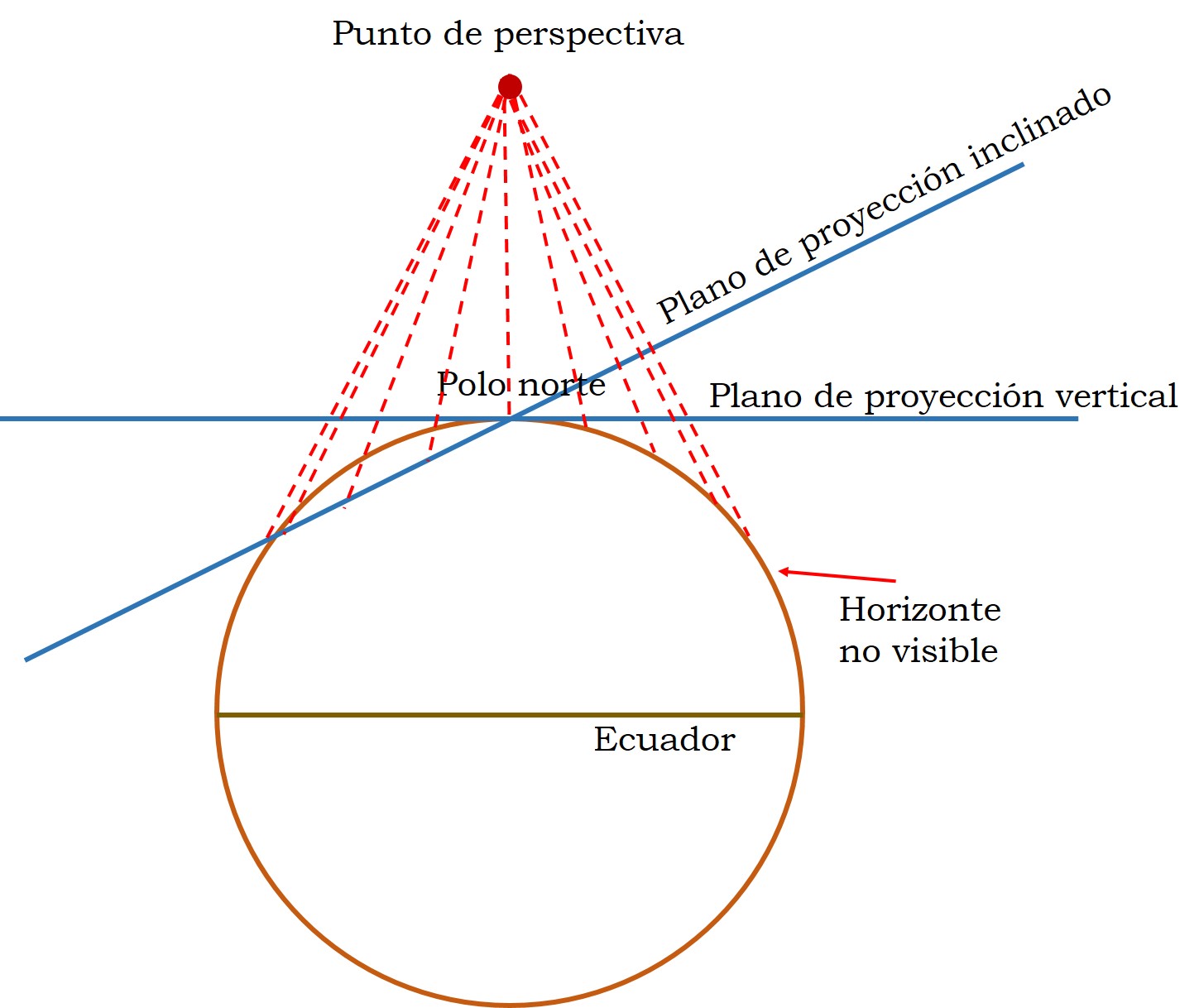 Esquema de la proyección en perspectiva general, verical o inclinada, desde un punto que está en la vertical del polo norte
Esquema de la proyección en perspectiva general, verical o inclinada, desde un punto que está en la vertical del polo norte
Dependiendo de lo lejos que esté el punto de proyección la imagen será más amplia o más reducida.
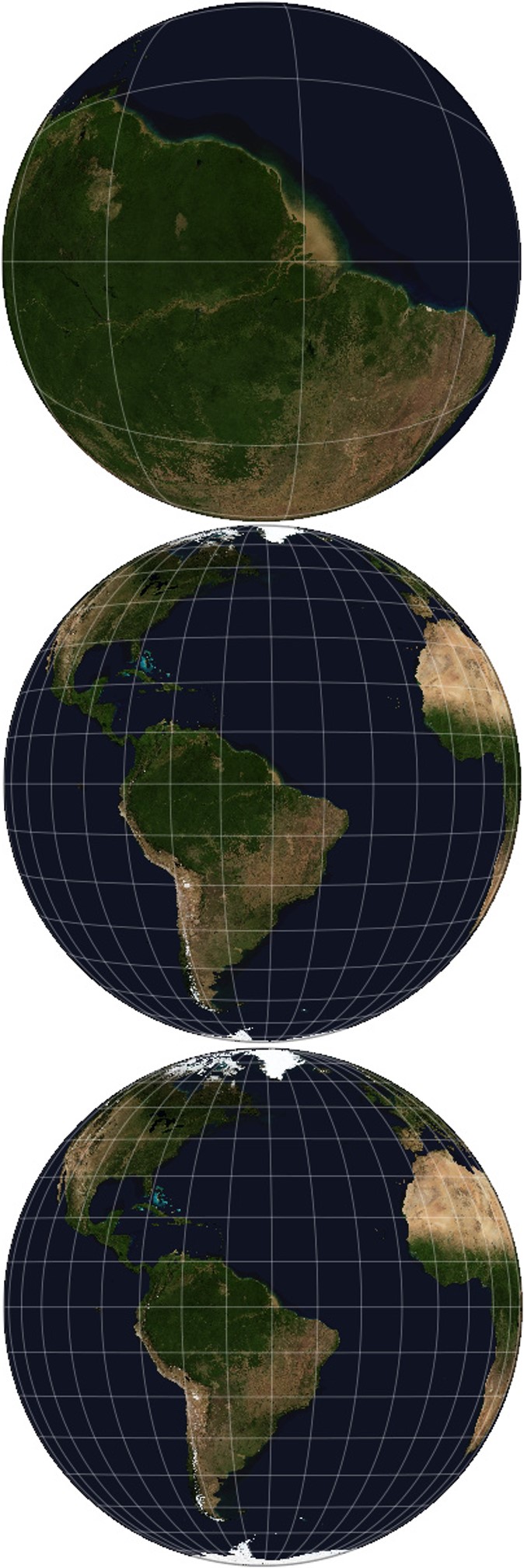 Mapas realizados con la proyección en perspectiva vertical, con imágenes reales del proyecto “The Blue Marble New Generation” de la NASA, con el centro de proyección sobre el Ecuador, cerca de la desembocadura del río Amazonas, y con el punto de proyección a 590 km (la distancia a la que está la órbita del telescopio Hubble, aunque este no mira hacia la Tierra), a 35.786 km (altura a la que suelen estar los satélites) y a 378.000 km (más o menos la órbita de la Luna). Imagen de [6]
Mapas realizados con la proyección en perspectiva vertical, con imágenes reales del proyecto “The Blue Marble New Generation” de la NASA, con el centro de proyección sobre el Ecuador, cerca de la desembocadura del río Amazonas, y con el punto de proyección a 590 km (la distancia a la que está la órbita del telescopio Hubble, aunque este no mira hacia la Tierra), a 35.786 km (altura a la que suelen estar los satélites) y a 378.000 km (más o menos la órbita de la Luna). Imagen de [6]
Pero estamos hablando de proyecciones matemáticas, y no de fotografía, por lo que podemos proyectar desde cualquier punto, incluso que esté en el interior del globo terrestre, y con el plano de proyección situado en cualquier posición, por ejemplo, en el lado opuesto, al punto de perspectiva, de la Tierra (lo que se llaman mapas en perspectiva vertical lejanos). Las proyecciones gnomónica, estereográfica y ortográfica (que veremos en el siguiente retrato) son casos particulares de la familia de proyecciones en perspectiva. Los siguientes diagramas nos muestran las diferentes opciones.
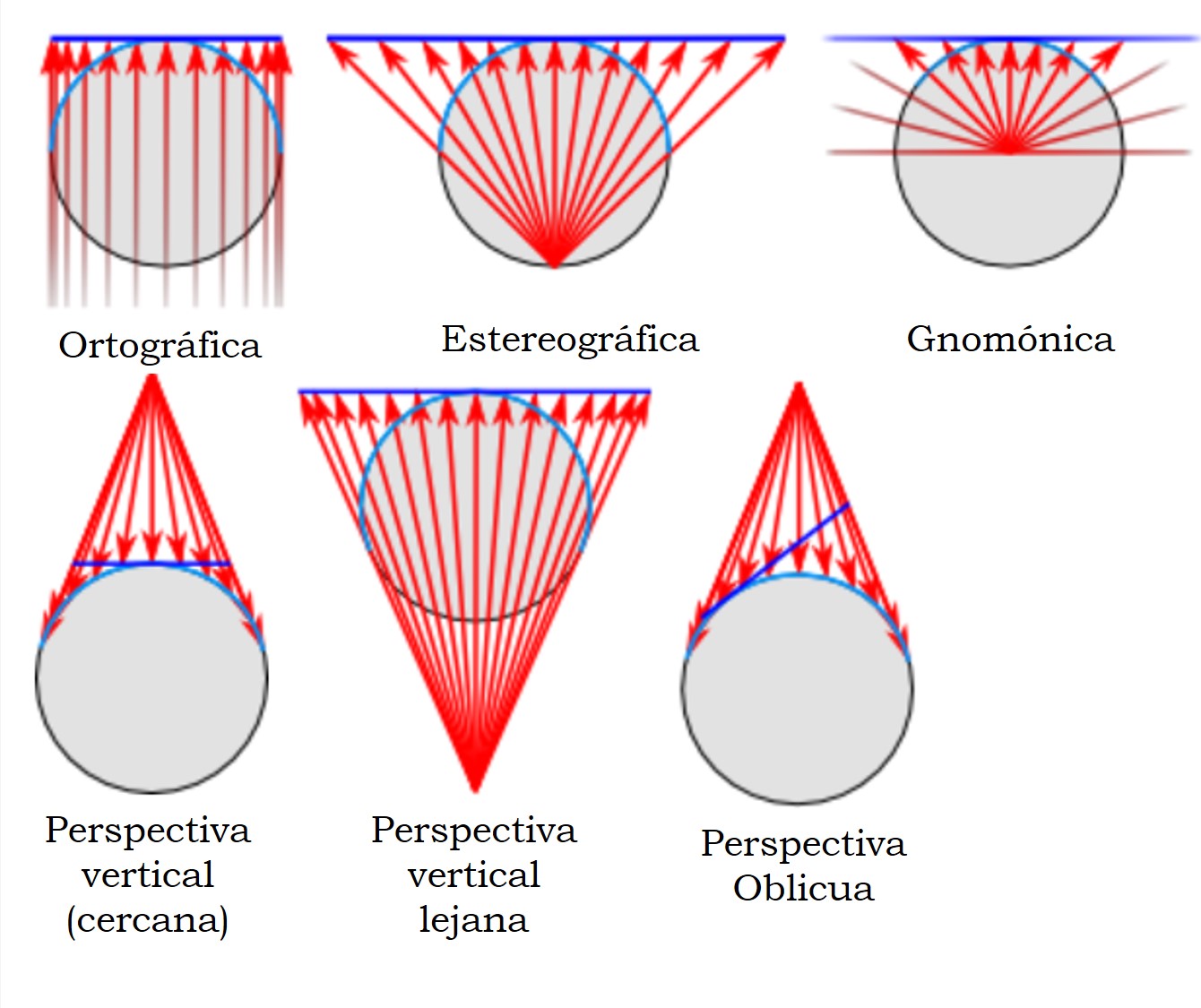 Diagramas de las diferentes proyecciones pertenecientes a la familia de proyecciones en perspectiva, dependiendo de la situación del punto de proyección y del plano sobre el que se proyecta. Imagen de [6]Para esta proyección, el meridiano y paralelo centrales se transforman en rectas, mientras que los demás meridianos y paralelos se transformarán en rectas, arcos de circunferencia o elipses, incluso en parábolas e hiperbolas, dependiendo del aspecto de la proyección (polar, ecuatorial u oblicua). No se preservan las propiedades métricas y existe una menor distorsión cerca del centro de proyección y una deformación exagerada en los bordes. Esta proyección, en su caso general, no fue prácticamente utilizada más que para representar la Tierra vista desde el espacio.
Diagramas de las diferentes proyecciones pertenecientes a la familia de proyecciones en perspectiva, dependiendo de la situación del punto de proyección y del plano sobre el que se proyecta. Imagen de [6]Para esta proyección, el meridiano y paralelo centrales se transforman en rectas, mientras que los demás meridianos y paralelos se transformarán en rectas, arcos de circunferencia o elipses, incluso en parábolas e hiperbolas, dependiendo del aspecto de la proyección (polar, ecuatorial u oblicua). No se preservan las propiedades métricas y existe una menor distorsión cerca del centro de proyección y una deformación exagerada en los bordes. Esta proyección, en su caso general, no fue prácticamente utilizada más que para representar la Tierra vista desde el espacio.
Mientras que las imágenes en perspectiva vertical general (con el plano cercano) nos muestran solo una parte de uno de los hemisferios, mediante el uso de un plano “lejano”, en la parte opuesta, de la superficie terrestre, al punto de proyección, se pueden obtener mapas que cubran más que un hemisferio.
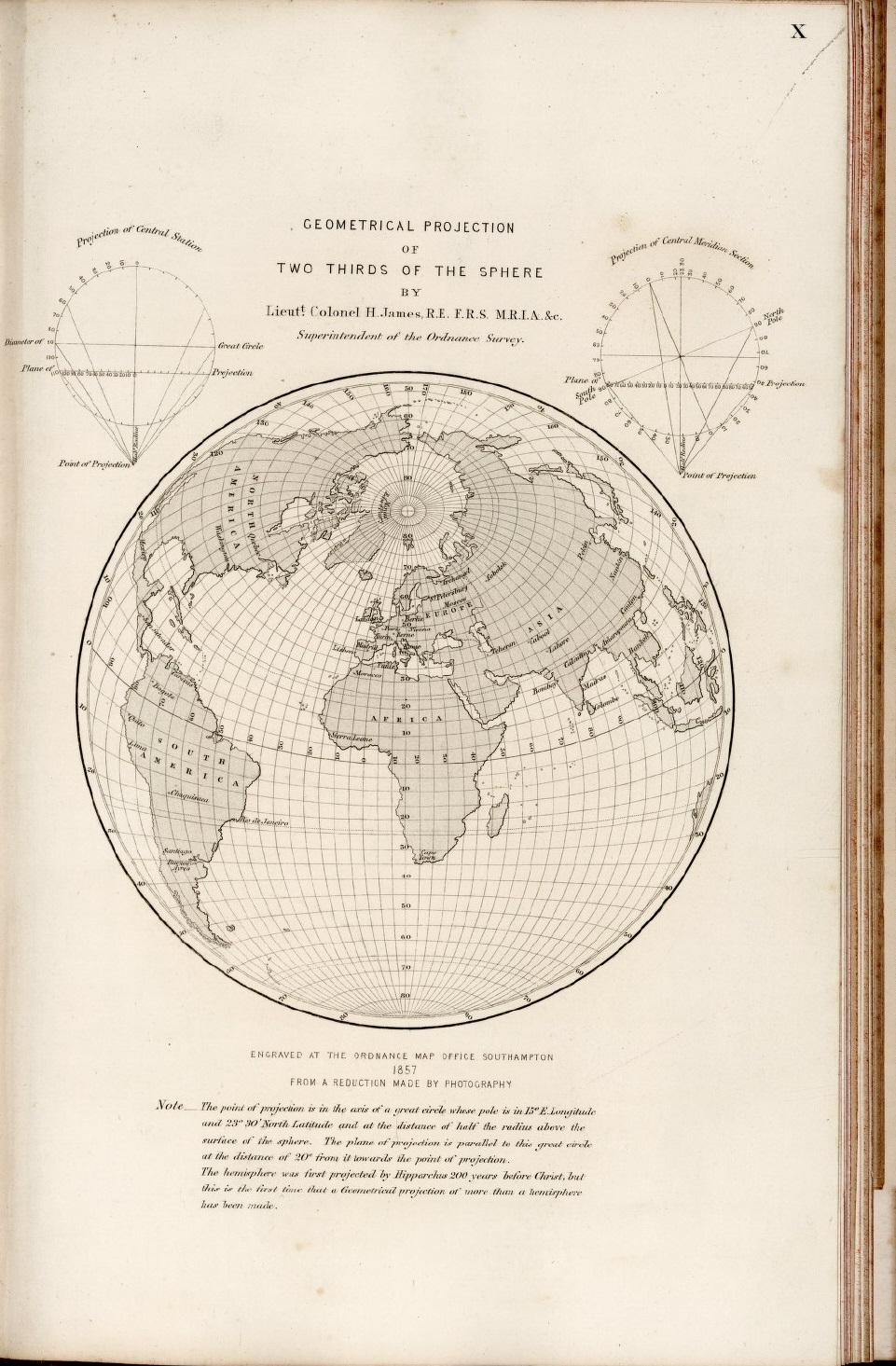 Mapa de dos tercios de la superficie terrestre, realizado en 1857 por el coronel Henry James, con la proyección en perspectiva vertical lejana, con una distancia de 1,5 veces el radio de la Tierra, desde el centro y en dirección opuesta al plano de proyección. Imagen de [1]
Mapa de dos tercios de la superficie terrestre, realizado en 1857 por el coronel Henry James, con la proyección en perspectiva vertical lejana, con una distancia de 1,5 veces el radio de la Tierra, desde el centro y en dirección opuesta al plano de proyección. Imagen de [1]
Por este motivo, la proyección en perspectiva vertical lejana fue utilizada por varios autores. El matemático francés Phillipe de La Hire (1640-1719) en 1701 con una distancia del punto de proyección de 1,7 veces el radio de la Tierra, desde el centro y en dirección opuesta al plano de proyección, el coronel británico Henry James (1803-1877), quien fuera director general de la agencia de mapas de Gran Bretaña, con una distancia de 1,5 veces el radio terrestre en 1857, el geodesta británico Alexander R. Clarke (1828-1914), junto con Henry James, a una distancia de 1,368 veces, en 1862, o solo, en su famosa “proyección crepúsculo”, con el plano a una distancia de 1,4 veces el radio de la Tierra, en 1879.
 Reproducción de Carlos A. Furuti [6] de los mapas de Phillipe de La Hire (1701), Henry James (1857), Alexander R. Clarke (1862), junto con Henry James, o solo, en su famosa “proyección crepúsculo” (1879), realizados con proyecciones en perspectiva vertical lejana
Reproducción de Carlos A. Furuti [6] de los mapas de Phillipe de La Hire (1701), Henry James (1857), Alexander R. Clarke (1862), junto con Henry James, o solo, en su famosa “proyección crepúsculo” (1879), realizados con proyecciones en perspectiva vertical lejana
Retrato 2: La proyección ortográfica
La proyección en perspectiva es un caso particular de la anterior familia, si consideramos que el punto de proyección está lejos, en el infinito, luego los rayos de proyección van paralelos entre sí y perpendiculares al plano de proyección.
 Mapa del mundo, de la zona del Atlático, realizado con la proyección ortográfica, publicado por Richard E. Harrison como suplemento de la revista Fortune, en junio de 1942, el primero de una serie de tres mapas ortográficos. Imagen de [1]
Mapa del mundo, de la zona del Atlático, realizado con la proyección ortográfica, publicado por Richard E. Harrison como suplemento de la revista Fortune, en junio de 1942, el primero de una serie de tres mapas ortográficos. Imagen de [1]
Esta proyección ya era conocida desde la antigüedad. Seguramente la era conocida por los egipcios y el matemático y astrónomo Hiparco de Nicea (aprox. 190-120 a.n.e.) la utilizó para sus cálculos de astronomía. En la antigüedad se conocía con el nombre de “analema”, que sería reemplazado por “ortográfica” en 1613, por el matemático francés Francois d’Aguillon (1567-1617). Aunque fue utilizada por primera vez para mapas del mundo en el siglo XVI, por el cartógrafo austriaco Johannes Stabius (1450-1522) y el artista renacentista alemán Alberto Durero (1471-1528).
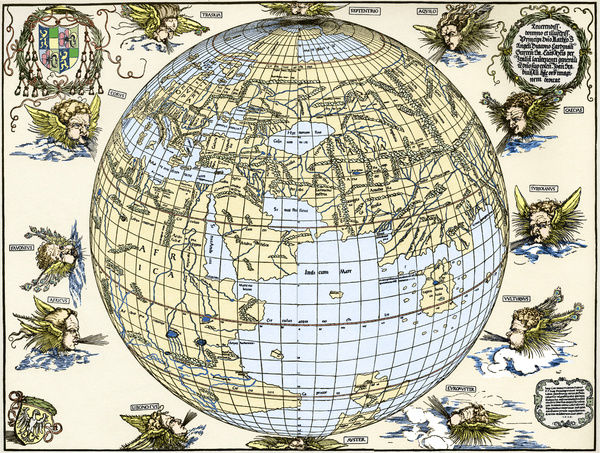 Grabado coloreado de Alberto Durero de un mapa de Johannes Stabius, de 1515. Imagen de Media Storehouse
Grabado coloreado de Alberto Durero de un mapa de Johannes Stabius, de 1515. Imagen de Media Storehouse
Esta proyección se suele utilizar por su aspecto similar al aspecto que tiene el planeta visto desde el espacio. No es una proyección que se haya utilizado en muchos atlas, pero sí en algunos, cuando se quiere mostrar la imagen de la Tierra desde el espacio exterior, como en The Global Atlas, A New View of the World from Space, publicado por Frank Debenham en 1958, en varios de los atlas de Rand McNally o por la US Geological Survey, USGS. Y volvió a utilizarse cuando empezó la carrera espacial.
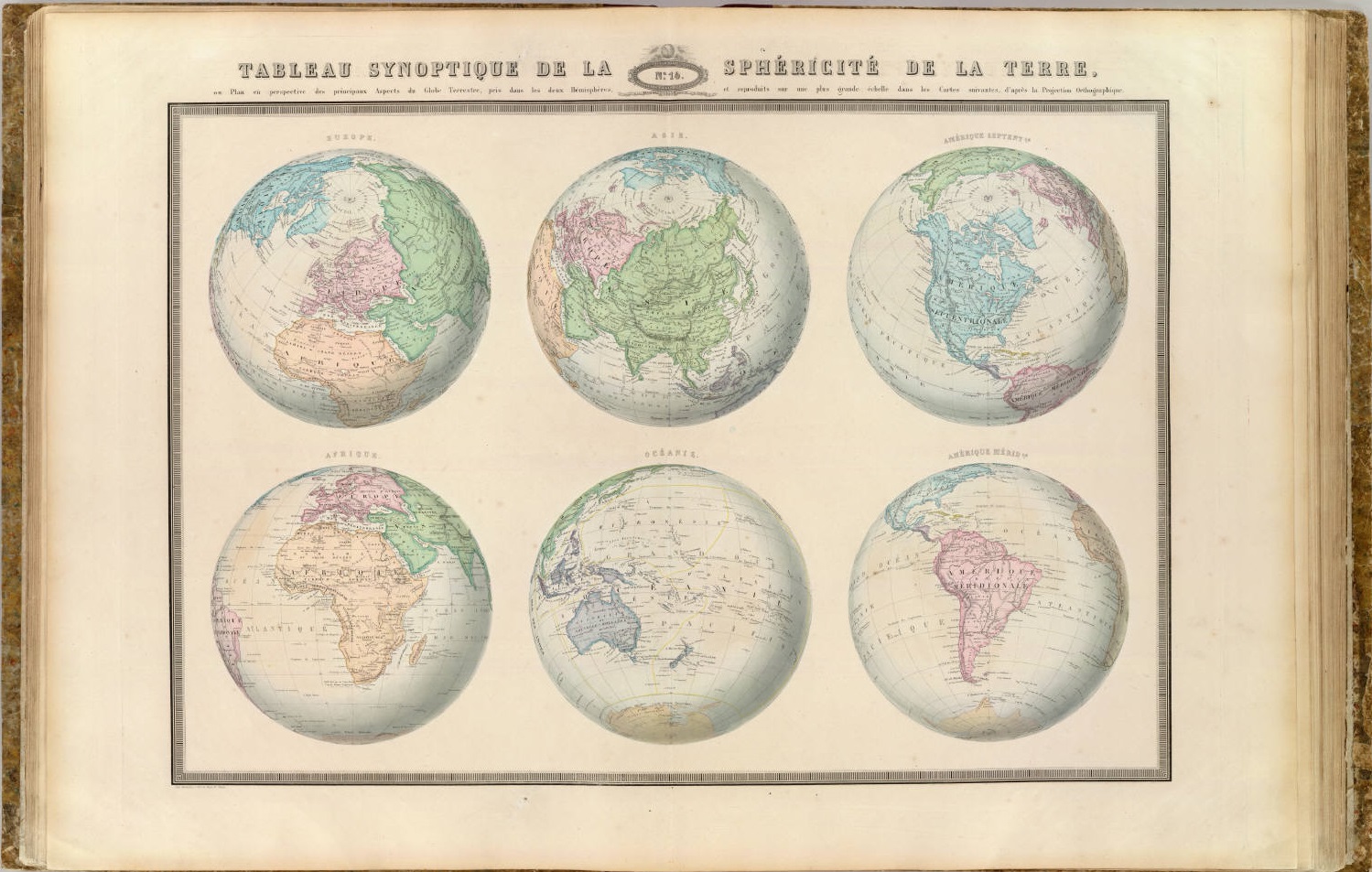 “Tabla sinóptica de la esfericidad de la Tierra”, con seis mapas hemisféricos, realizados con la proyección ortogonal, de la Tierra: Europa, Asia, Norteamérica, África, Oceanía y América del Sur, perteneciente a la publicación de M.F.A. Garnier, Atlas spheroidal et universel de geographie dresse a l’aide des documents officiels, recemment publies en France et a l’etranger (1862). Imagen de [1]
“Tabla sinóptica de la esfericidad de la Tierra”, con seis mapas hemisféricos, realizados con la proyección ortogonal, de la Tierra: Europa, Asia, Norteamérica, África, Oceanía y América del Sur, perteneciente a la publicación de M.F.A. Garnier, Atlas spheroidal et universel de geographie dresse a l’aide des documents officiels, recemment publies en France et a l’etranger (1862). Imagen de [1]
Retrato 3: La proyección cónica conforme de Lambert
Tanto en las dos primeras entregas de esta serie de retratos del mundo, Imagi Mundi, como en los dos primeros retratos de esta tercera entrega, solamente hemos presentado proyecciones cilíndricas y acimutales, o generalizaciones de estas. Ahora vamos a presentar algunas proyecciones cónicas, es decir, cuya superficie auxiliar de proyección es el cono. Es decir, en el caso de las proyecciones geométricas, se proyecta primero la esfera terrestre básica sobre un cono, tangente (la intersección es una circunferencia, que será un paralelo en el caso normal, esto es, si el eje del cono coincide con el de la esfera terrestre básica) o secante (con dos circunferencias de intersección, que serán paralelos en el caso normal), a la esfera y luego este se despliega, cortando por una de sus rectas generadoras, en un plano.
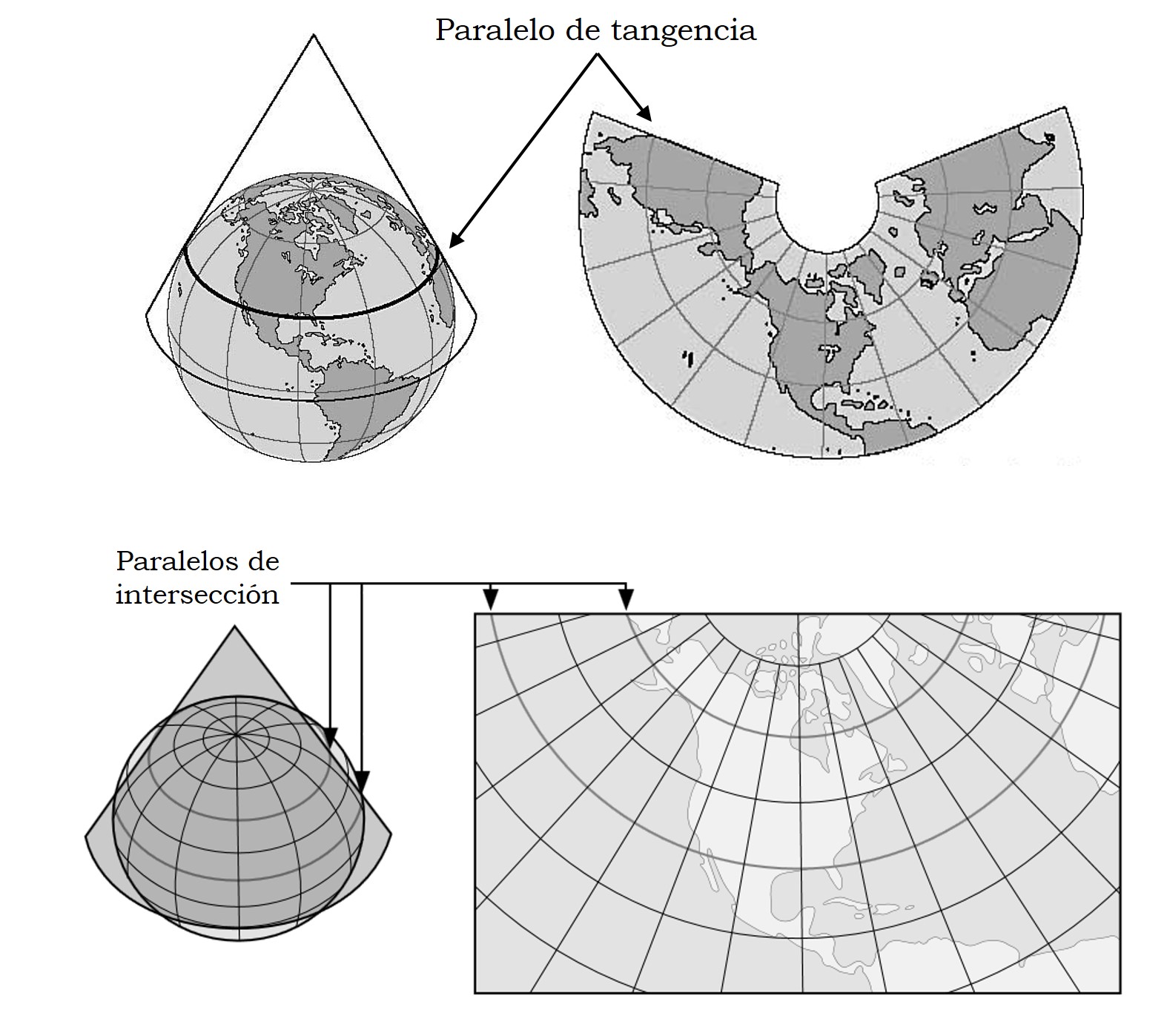 Esquemas de las proyecciones cónicas en el caso normal (el eje del cono y la esfera es el mismo), tangentes (con un paralelo de tangencia) y secantes (con dos paralelos de intersección)
Esquemas de las proyecciones cónicas en el caso normal (el eje del cono y la esfera es el mismo), tangentes (con un paralelo de tangencia) y secantes (con dos paralelos de intersección)La proyección cónica conforme de Lambert es una de las siete proyecciones presentadas por el matemático alemán, aunque de origen francés, Johann H. Lambert (1728-1777) en su trabajo Notas y comentarios sobre la composición de mapas terrestres y celestes (1772). Lambert utilizó las herramientas matemáticas en su poder (cálculo, geometría, álgebra y trigonometría) para construir una familia de proyecciones conformes intermedias entre la proyección estereográfica (que es acimutal) y la proyección de Mercator (que es cilíndrica), para los casos tangentes (con un paralelo de tangencia) y secantes (con dos paralelos de intersección).
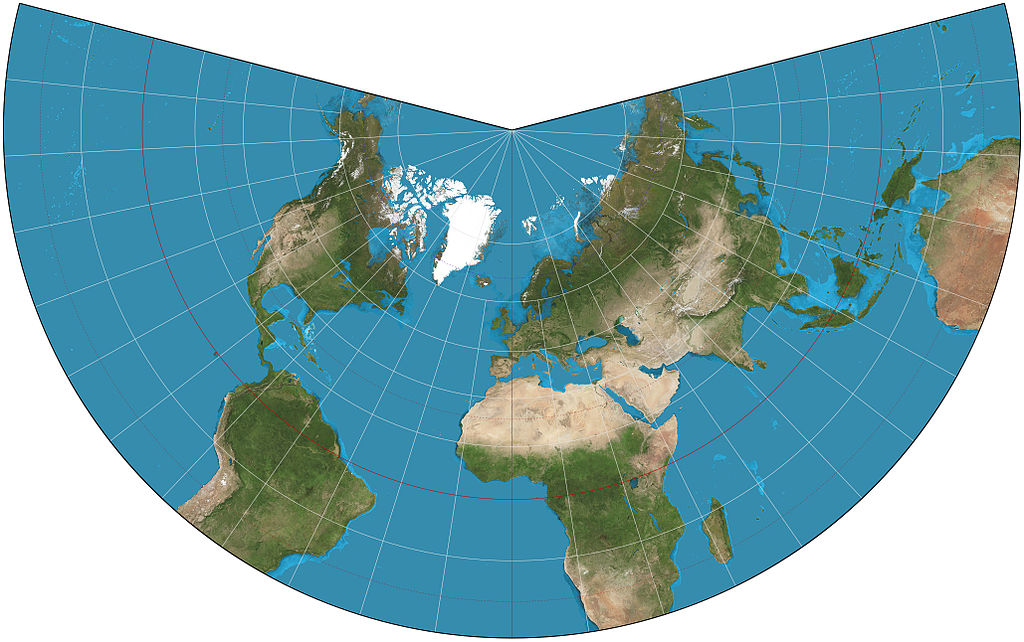 Mapa del mundo realizado con la proyección cónica conforme de Lambert, cuyos paralelos de tangencia a 20º N y 50º N, con imágenes del proyecto “Blue Marble” de la NASA. Imagen de Wikimedia Commons
Mapa del mundo realizado con la proyección cónica conforme de Lambert, cuyos paralelos de tangencia a 20º N y 50º N, con imágenes del proyecto “Blue Marble” de la NASA. Imagen de Wikimedia Commons
Como hemos comentado, esta proyección es conforme, preserva los ángulos, los rumbos, y para regiones pequeñas también las formas. La deformación es pequeña cerca de los paralelos de tangencia o intersección, y mayor al alejarse de ellos. Por este motivo, la proyección es muy útil para mapas de territorios en la dirección este-oeste, que se desarrollen alrededor del paralelo de tangencia o entre los dos paralelos de intersección, no estando estos muy alejados.
Hasta que fue utilizada por Francia durante la primera guerra mundial, esta proyección había permanecido olvidada. Después se ha convertido en una de las proyecciones más utilizadas para mapas de “escala grande” (esto es, es factor de proporcionalidad de la escala es pequeño), es decir, mapas de territorios pequeños. La utiliza la USGS de Estados Unidos, así como muchas otras agencias internacionales, para mapas topográficos. La Comisión Europea la recomienda para mapas conformes de Europa al completo de escalas mayores o iguales a 1:500.000 (como 1:100.000 o 1:25.000), y es común en países como Francia, Estados Unidos, Canada o México. También se emplea mucho para cartas náuticas.
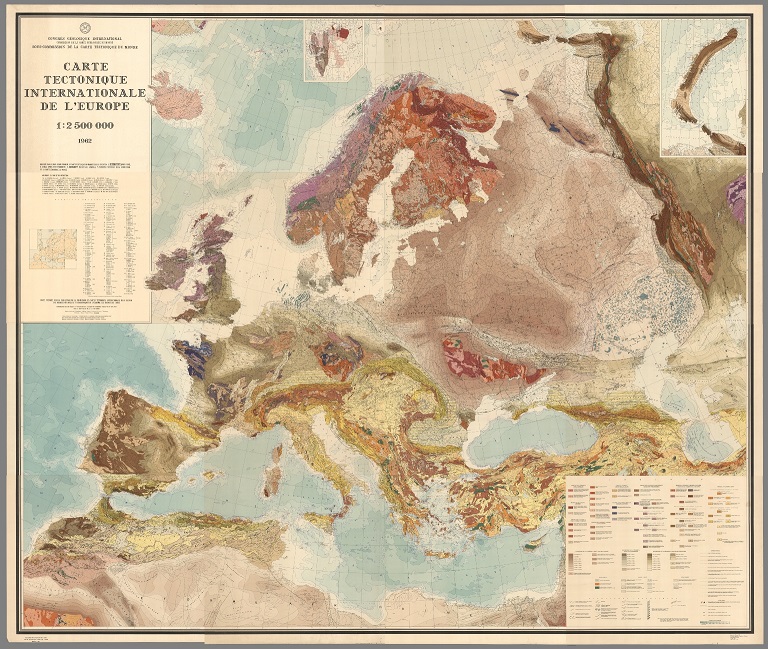 “Carta tectónica internacional de Europa”, realizada con la proyección cónica conforme de Lambert, por el Congreso Internacional de Geología, Academia de Ciencias de la URSS, 1962. Imagen de [1]
“Carta tectónica internacional de Europa”, realizada con la proyección cónica conforme de Lambert, por el Congreso Internacional de Geología, Academia de Ciencias de la URSS, 1962. Imagen de [1]
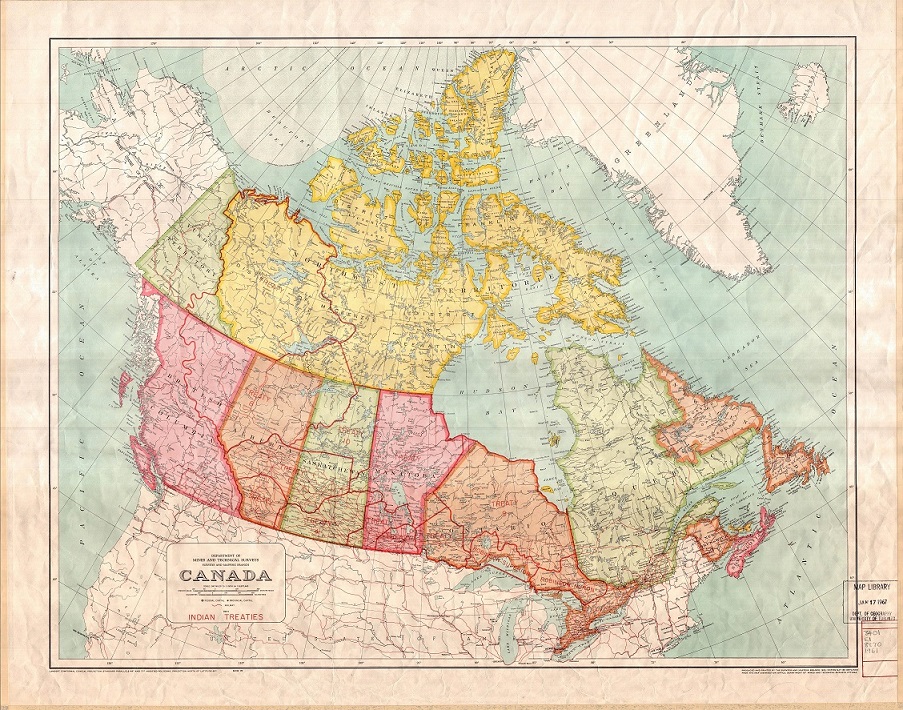 “Mapa de tratados indios de Canada”, realizado con la proyección cónica conforme de Lambert, del “Department of Mines and Technical Surveys” de Canada, 1961. Imagen de University of Toronto Libraries
“Mapa de tratados indios de Canada”, realizado con la proyección cónica conforme de Lambert, del “Department of Mines and Technical Surveys” de Canada, 1961. Imagen de University of Toronto Libraries
Retrato 4: La proyección cónica isoareal de Albers
En su monografía de 1772, Johann Lambert también propuso una proyección cónica isoareal, que sería generalizada por el cartógrafo alemán Heinrich C. Albers (1773-1833) en 1805, también con uno o dos paralelos de intersección, que son aquellos en los que la escala es real (luego son llamados paralelos estándar). Como en el caso de la proyección cónica conforme de Lambert, los paralelos son arcos de circunferencias concéntricas y los meridianos son radios –rectas- de esas circunferencias igualmente espaciados, que cortan perpendicularmente a los paralelos. Los polos son arcos de circunferencia, el interior y el exterior, mientras que en la cónica conforme de Lambert era un punto (el norte o el sur, dependiendo de la versión), y el infinito.
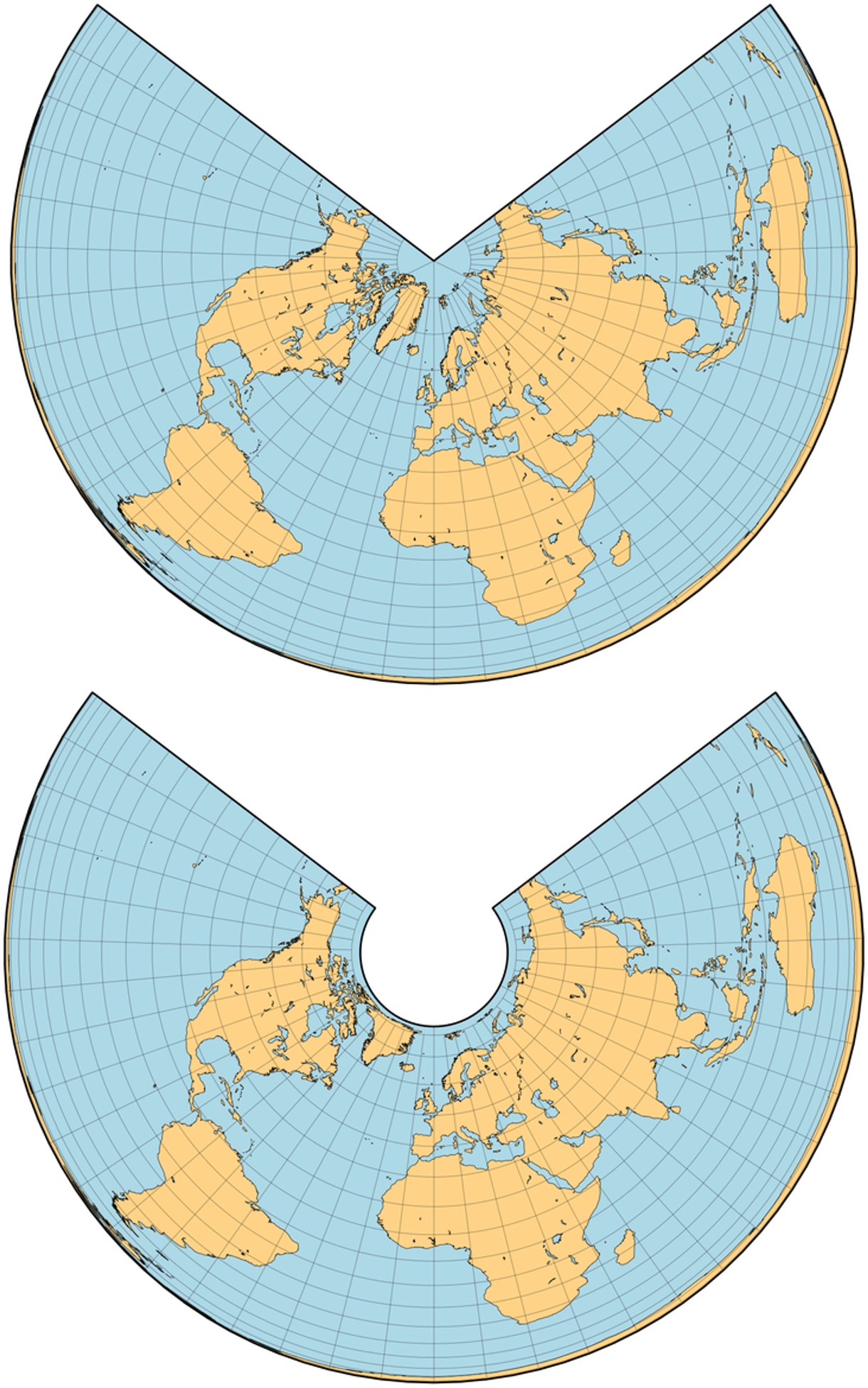 Mapas del mundo realizados con las proyecciones cónica isoareales de Lambert (con paralelos estándar a 90ºN y 24º 28’ 11’’N) y Albers (con paralelo estándar a 45ºN). Imagen de [6]
Mapas del mundo realizados con las proyecciones cónica isoareales de Lambert (con paralelos estándar a 90ºN y 24º 28’ 11’’N) y Albers (con paralelo estándar a 45ºN). Imagen de [6]
De nuevo, la deformación es pequeña cerca de los paralelos de tangencia o intersección, y mayor al alejarse de ellos, por lo que también es útil para mapas este-oeste. En particular, es una proyección, con deos paralelos estándar, muy utilizada para los mapas de Estados Unidos.
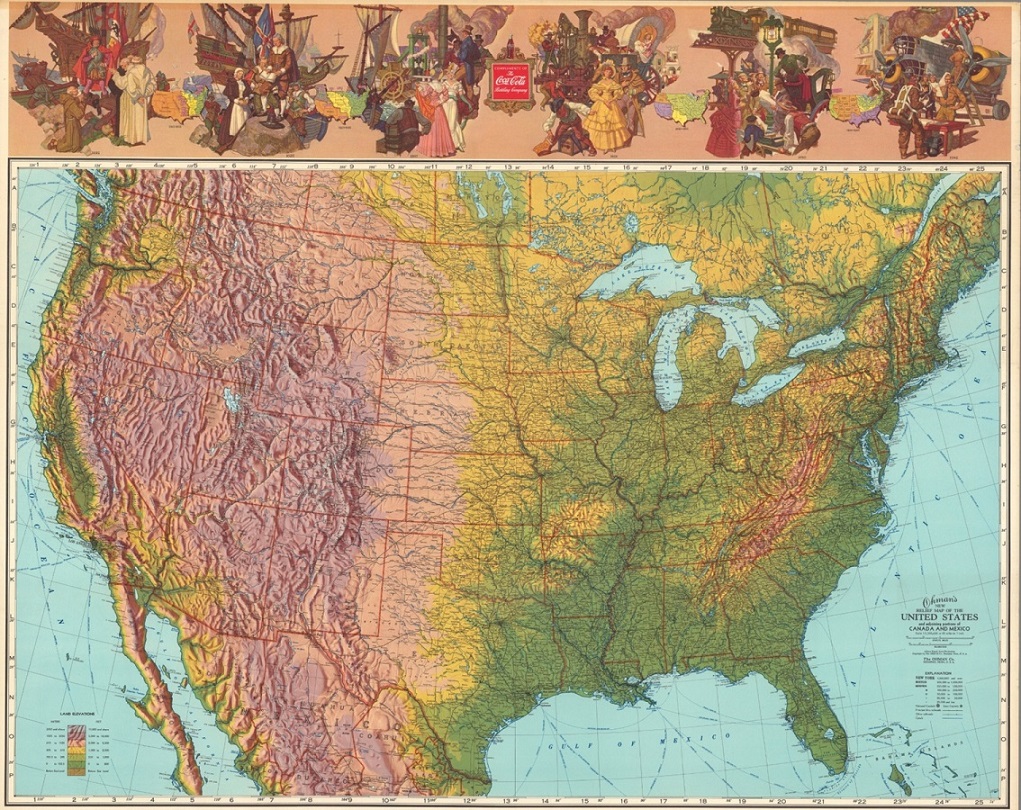 Mapa en relieve de Estados Unidos, realizado con la proyección cónica isoareal de Albers, publicado por la Ohman Company en 1942. Imagen de [1]
Mapa en relieve de Estados Unidos, realizado con la proyección cónica isoareal de Albers, publicado por la Ohman Company en 1942. Imagen de [1]
Retrato 5: La proyección de Bonne
En las proyecciones cónicas, ya sean geometricas puras o su generalización matemática, los meridianos (en la versión normal) se representan como radios (rectas), igualmente espaciados, de los arcos de circunferencias concéntricas que representan a los paralelos, mientras que en la generalización de estas proyecciones, las llamadas pseudo-cónicas, los meridianos siguen siendo arcos de circunferencia, mientras que los paralelos ya no son rectas.
Un ejemplo de proyección pseudo-cónica es la proyección de Bonne, que realmente es toda una familia de proyecciones pseudo-cónicas isoareales, en función de cual sea el paralelo estándar o central (correspondiente al paralelo de intersección con el cono).
 Mapamundis realizados con la proyección de Bonne, para los paralelos estándar de 45ºN, en el primero, y 15ºS, en el segundo
Mapamundis realizados con la proyección de Bonne, para los paralelos estándar de 45ºN, en el primero, y 15ºS, en el segundo
El autor de esta familia de proyecciones fue el cartógrafo e ingeniero francés Rigobert Bonne (1727-1795). Aunque la proyección de Bonne ya había sido utilizada con anterioridad. Por ejemplo, en el mapa Universalis Cosmographia del cartógrafo alemán Martin Waldseemüller (1470-1520) de 1507 que modifica la segunda proyección de Ptolomeo o en su generalización en el mapa del mundo de Petrus Apianus de 1520, así como en el mapa del mundo del cartógrafo italiano Bernardo Sylvanus de 1511.
 Mapa “Universalis Cosmographia” de Martin Waldseemüller (1507), en el que aparece, por primera vez en un mapa, la palabra “América”
Mapa “Universalis Cosmographia” de Martin Waldseemüller (1507), en el que aparece, por primera vez en un mapa, la palabra “América” Planisferio de Sylvanus (1511)
Planisferio de Sylvanus (1511)Los casos extremos son la proyección de Werner (o Stabius-Werner), cuando el paralelo estandar es 90ºN, que tiene forma de corazón y la proyección sinusoidal o de Sanson-Flamsteed, cuando el paralelo es 0º.
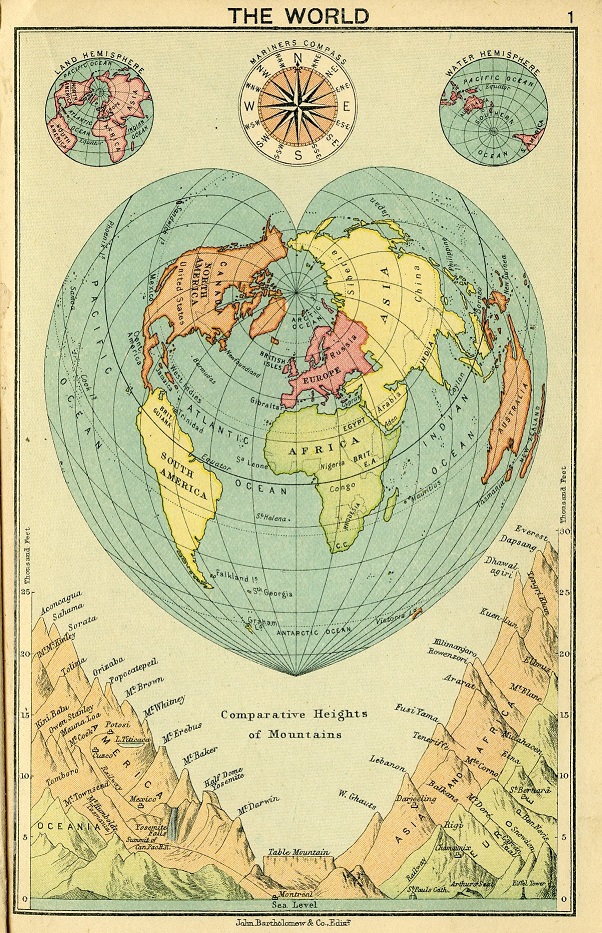 Mapa del mundo, realizado con la proyección de (Stabius-) Werner, perteneciente al “Atlas del mundo” (1913), de John Bartholomew. Imagen de University of Toronto Libraries
Mapa del mundo, realizado con la proyección de (Stabius-) Werner, perteneciente al “Atlas del mundo” (1913), de John Bartholomew. Imagen de University of Toronto Libraries
La proyección sinusoidal tiene este nombre ya que los meridianos son sinusoides, curvas de la función seno, mientras que los paralelos son rectas estándar, es decir, la escala es correcta a lo largo de los paralelos. Por este motivo, el mapa diseñado con la proyección sinusoidal se va encogiendo según los paralelos van acercándose a los polos, que son dos puntos. Para que la compresión no sea tan fuerte en los polos, se suele utilizar una versión cortada, o interrumpida.
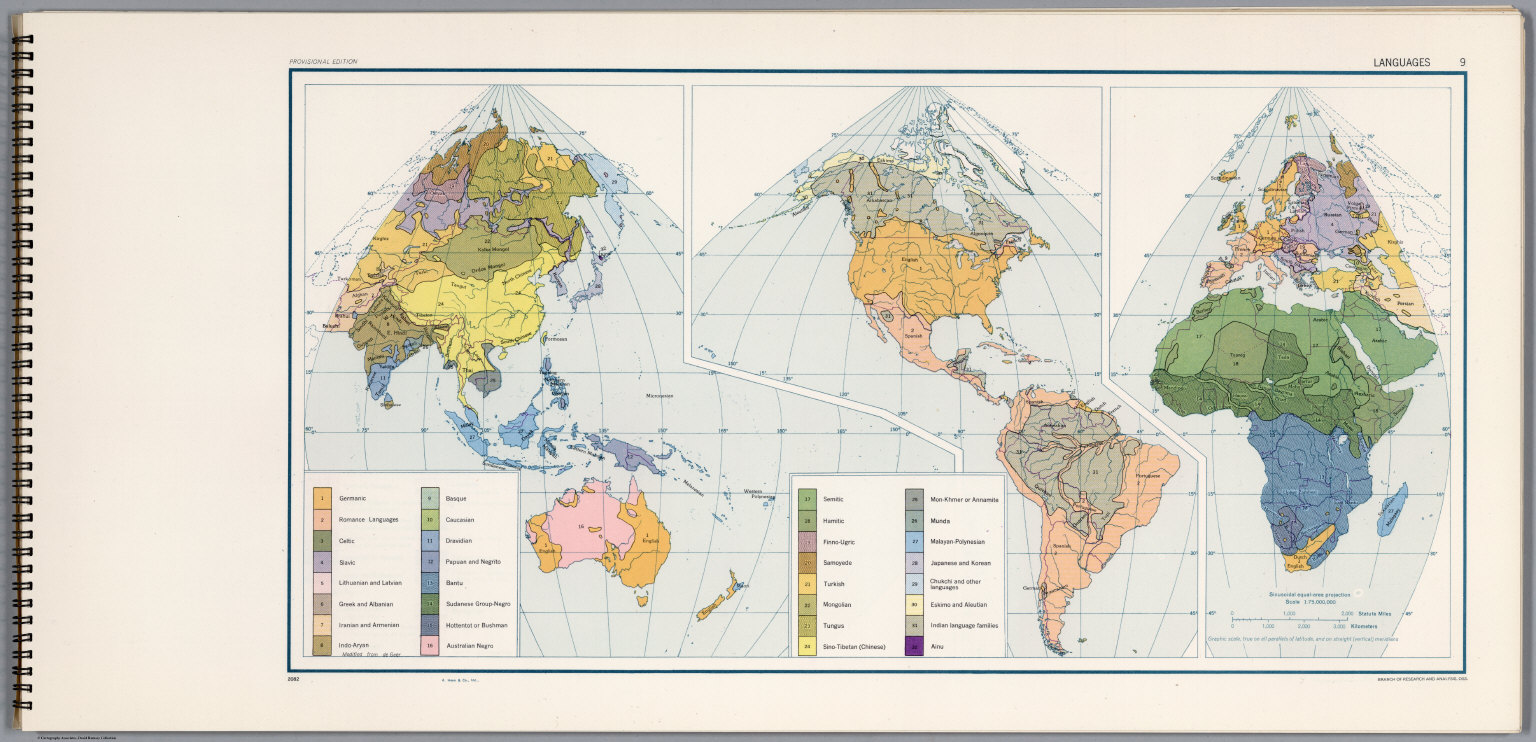 Mapa con las lenguas del mundo, realizado con la proyección sinusoidal interrumpida, perteneciente al “Atlas del mundo para el estudio de la Geografía en el Programa de Entrenamiento Especial del Ejército”, United States Army Service Forces, 1943. Aparecen el euskera (zona del País Vasco y Navarra) y el catalán (aunque solo señalado en las Islas Baleares). Imagen de [1]
Mapa con las lenguas del mundo, realizado con la proyección sinusoidal interrumpida, perteneciente al “Atlas del mundo para el estudio de la Geografía en el Programa de Entrenamiento Especial del Ejército”, United States Army Service Forces, 1943. Aparecen el euskera (zona del País Vasco y Navarra) y el catalán (aunque solo señalado en las Islas Baleares). Imagen de [1]
Retrato 7: La proyección armadillo
Como ya hemos comentado, existen tres familias principales de proyecciones, en función de si la superficie auxiliar de proyección no existe (acimulates), es un cilindro (cilíndricas) o es un cono (cónicas). También se podrían tomar otras superficies auxiliares intermedias no necesariamente desarrollables, aunque no suele ser lo habitual, como en la proyección armadillo, desarrollada en 1943 por el cartógrafo estadounidense, de origen húngaro, Erwin J. Raisz (1893-1968), que consiste en proyectar la superficie terrestre básica sobre un toro (recordemos que en las matemáticas un “toro” es la superficie que tiene la forma de un flotador) y luego proyectar ortogonalmente, según una cierta dirección, en un plano.
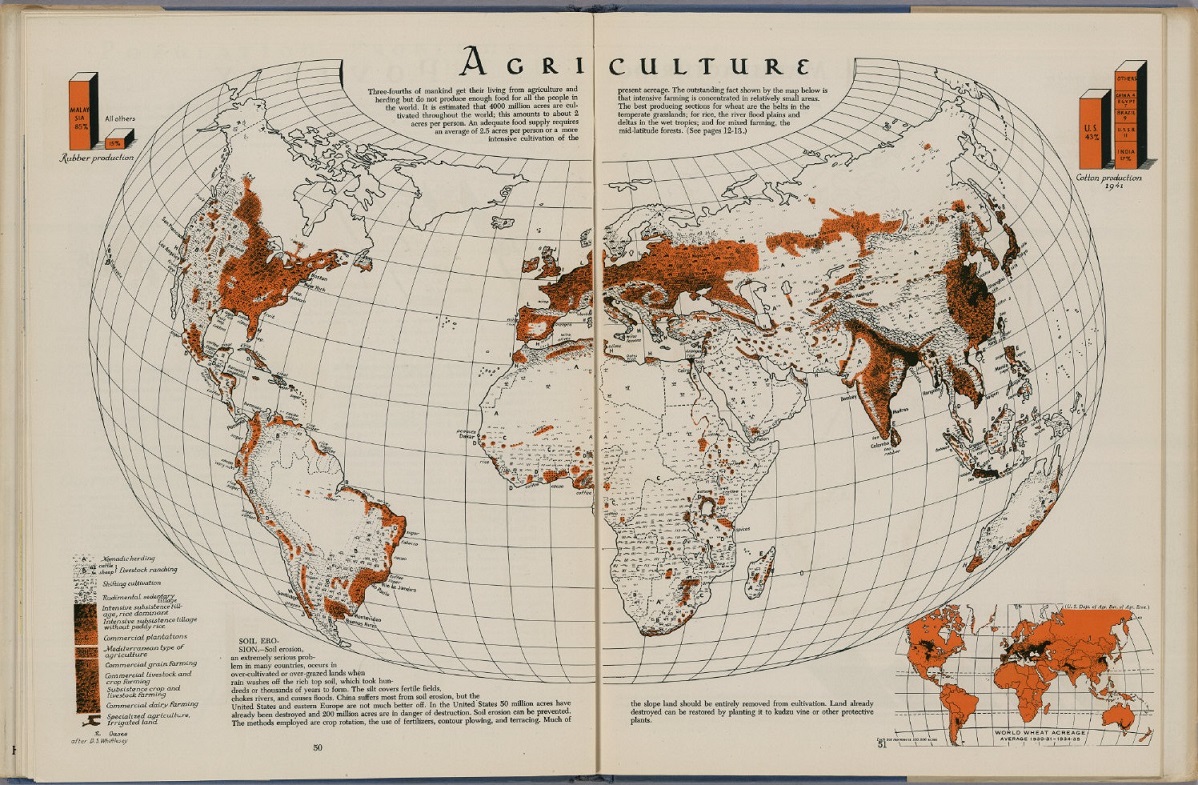 Mapa del mundo sobre agricultura, realizado con la proyección armadillo, perteneciente al “Atlas de geografía global” (1944), de Edwin Raisz. Imagen de [1]
Mapa del mundo sobre agricultura, realizado con la proyección armadillo, perteneciente al “Atlas de geografía global” (1944), de Edwin Raisz. Imagen de [1]
Retrato 8: La proyección globular de Nicolosi
Las proyecciones globulares son aquellas que pretenden representar la imagen esférica del globo terrestre, y contrariamente a las proyecciones acimutales, no son proyecciones geométricas, es decir, no están definidas a través de “rayos”, como ocurre en proyecciones acimutales como la gnomónica o la estereográfica, y en proyecciones cilíndricas como la proyección cilíndrica isoareal de Lambert. No preservan ni áreas, ni ángulos. Se limitan a un hemisferio, por lo que se necesitan dos mapas para cubrir toda la superficie terrestre.
Son proyecciones muy antiguas. Una de las proyecciones globulares más antiguas fue descrita por el filósofo inglés Roger Bacon (1214-1294) hacia 1265. La proyección globular conocida como de “Nicolosi”, que es una modificación de una proyección globular, la llamada primera, del jesuita, geógrafo y matemático francés Georges Fournier (1595-1652), fue realizada por el geógrafo italiano Giovanni Battista Nicolosi (1610-1670), aunque seguramente fue creada por el matemático persa Al-Biruni (973-1048).
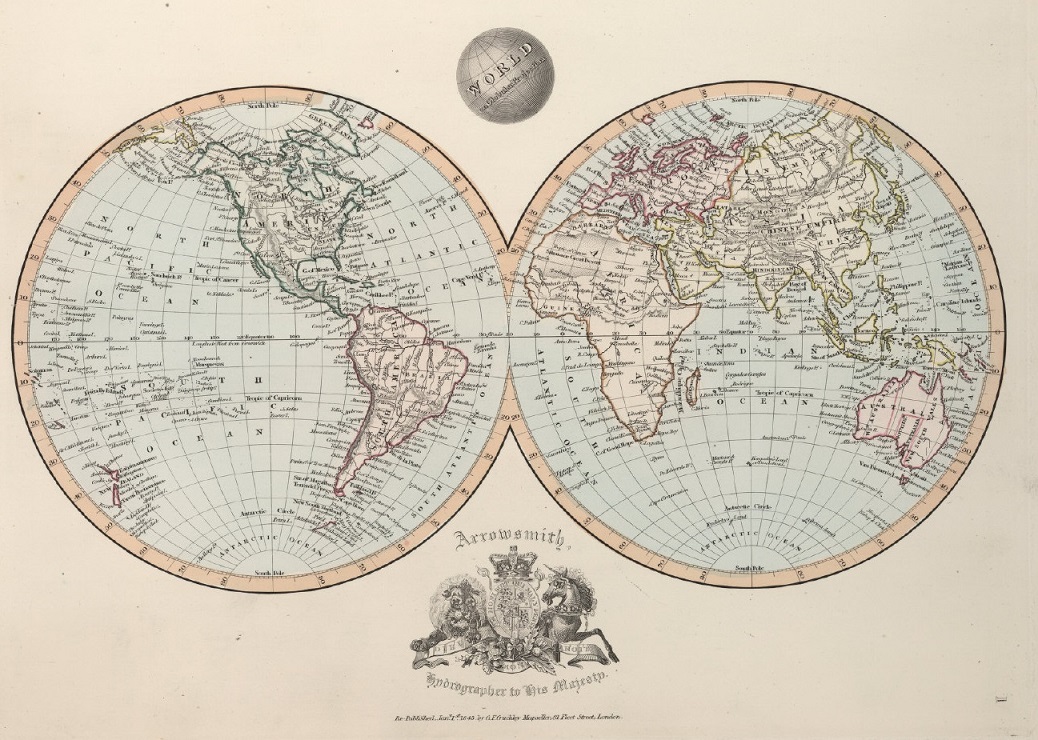 “El mundo en la proyección globular” (de Nicolosi), de la publicación Outlines of the World (1845), de Aaron Jr. Arrowsmith. Imagen de [1]
“El mundo en la proyección globular” (de Nicolosi), de la publicación Outlines of the World (1845), de Aaron Jr. Arrowsmith. Imagen de [1]
En el mapamundi diseñado con la proyección globular de Nicolosi los meridianos y paralelos son circulares. De las proyecciones globulares, esta es la que produce menos distorsión en las formas. En la mayoría de los mapas modernos en los cuales se menciona que han sido diseñados con la proyección globular, se están refiriendo a la proyección globular de Nisolosi.
Retrato 9: La proyección regional de Bartholomew
En 1958 el cartógrafo escocés John C. Bartholomew (1923-2008) combinó la proyección cónica equidistante (esta una proyección cónica sencilla, donde los meridianos son rectas estándar, es decir, la escala es correcta a lo largo de los meridianos, igualmente espaciadas y los paralelos son arcos de circunferencia, igualmente espaciados, además, los dos paralelos de intersección con el cono son también curvas estándar), para latitudes por encima del Trópico de Cáncer (22,5ºN), y la proyección de Bonne interrumpida para el resto de la superficie terrestre.
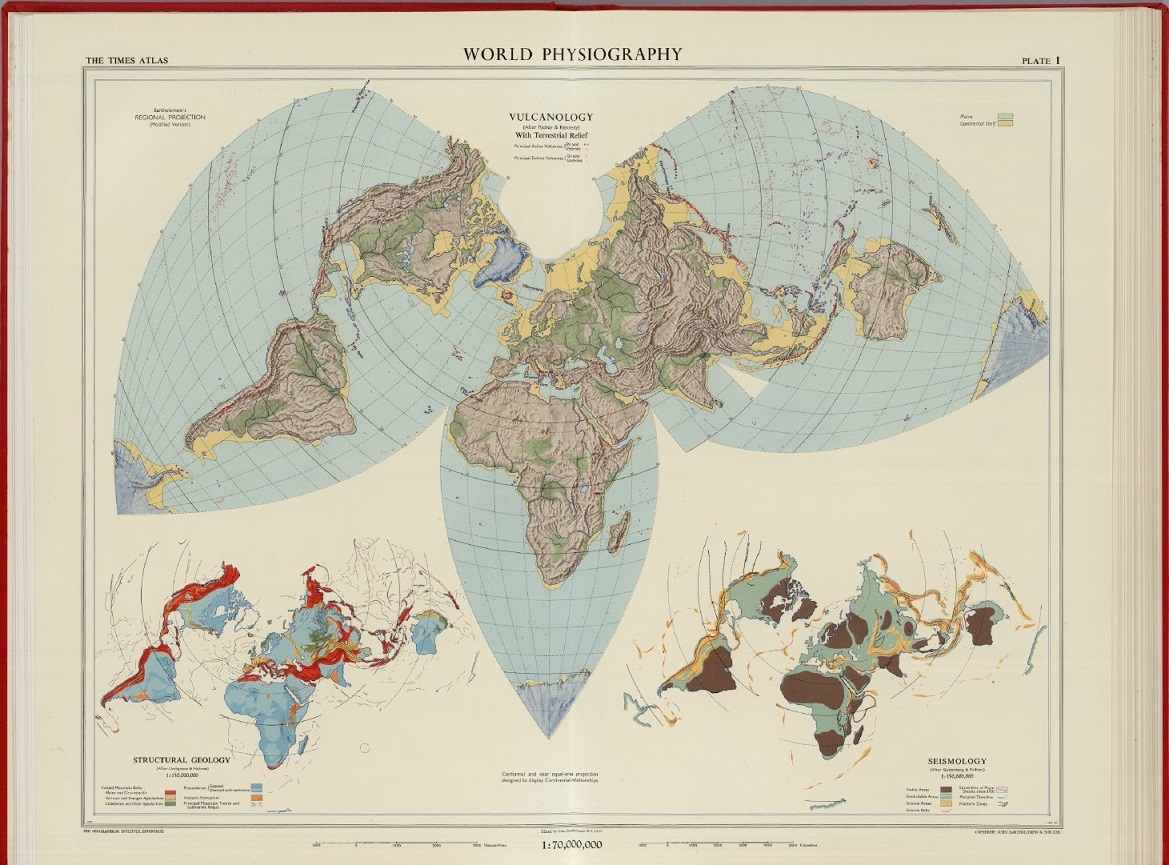 Mapa “Fisiografía del mundo”, realizado con la proyección regional de Bartholomew, perteneciente a la publicación “The Times Atlas of the World” (1958), de John C. Bartholomew (editor), Houghton Mifflin. Imagen de [1]
Mapa “Fisiografía del mundo”, realizado con la proyección regional de Bartholomew, perteneciente a la publicación “The Times Atlas of the World” (1958), de John C. Bartholomew (editor), Houghton Mifflin. Imagen de [1]
Existen muchas más projecciones cartográficas, pero parafraseando al matemático británico Andrew Wiles, “creo que lo dejaré aquí”.
 “Going Global”, de la serie “American History” (2004), de la artista estadounidense Joyce Kozloff, cuya obra artística está basada en la cartografía. Esta obra contiene un mapamundo realizado con la proyección homolosena de Goode. Imagen de [8]
“Going Global”, de la serie “American History” (2004), de la artista estadounidense Joyce Kozloff, cuya obra artística está basada en la cartografía. Esta obra contiene un mapamundo realizado con la proyección homolosena de Goode. Imagen de [8]
Bibliografía
1.- David Rumsey Map Collection
2.- National Geographic, Maps
3.- Raúl Ibáñez, El sueño del mapa perfecto; cartografía y matemáticas, RBA, 2010.
4.- Raúl Ibáñez, Muerte de un cartógrafo, Un paseo por la Geometría, UPV/EHU, 2002. Versión online en la sección textos-on-line de divulgamat
5.- J. P. Snyder, Flattening the Earth, Two Thousand Years of Map Projections, The University of Chicago Press, 1993.
6.- Carlos Furuti, Map projections
7.- J. P. Snyder, Map projections, A Working Manual, USGS Professional Paper 1395, 1987.
8.- Página web de la artista Joyce Kozloff
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo ‘Imago mundi’, finalmente 9 retratos más del mundo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Cristalografía (13): Fiat Pasteur

Cuando el joven doctor Louis Pasteur, a la sazón profesor del instituto de secundaria de Dijon, se enfrentó a su primer proyecto de investigación en solitario pensó que lo primero que necesitaba era una profunda preparación en cristalografía práctica. Decidió que lo mejor que podía hacer era estudiar sistemáticamente las formas cristalinas, repetir todas las mediciones y comparar sus resultados con los publicados. Uno de los estudios cristalográficos que decidió repetir fue el de 1841 de Frédéric Hervé de la Provostaye.
Pasteur fue muy meticuloso en la repetición de los experimentos. Esta meticulosidad tuvo su premio en el descubrimiento de algo que aparentemente había escapado tanto al ojo de Mitscherlich como al del propio de la Provostaye: aparecían caras hemiédricas en los cristales de tartrato de sodio y amonio. Sin embargo los cristales del racemato también tenían caras hemiédricas; la muestra bruta estaba formada en realidad por una mezcla de caras hemiédricas izquierdas y derechas.
Pasteur, en vez de anotar el dato y seguir con otra cosa, decidió investigar un poco. Con ayuda de una lupa y unas pinzas separó los cristales diestros y los zurdos, y preparó disoluciones con ellos. Para su sorpresa la disolución de zurdos era levorrotatoria y la de los diestros dextrorrotatoria. Si disolvía cantidades iguales de zurdos y diestros la disolución resultante era ¡ópticamente inactiva!
A continuación Pasteur decidió que tenía que comprobar la composición química de los cristales zurdos y diestros. Para ello obtuvo los ácidos libres a partir de las sales: el diestro era idéntico en todo al tartárico, el zurdo era en todo el tartárico pero con actividad óptica inversa.
Con todos estos datos el investigador de 25 años llegó a las siguientes conclusiones:
a) El ácido racémico no es un compuesto puro, sino una mezcla de iguales cantidades de ácido tartárico zurdo y diestro, que se diferencian tan sólo en su actividad óptica. La rotación óptica de los dos compuestos se cancela y, por lo tanto, la mezcla es inactiva.
b) La actividad óptica de los compuestos orgánicos, sus disoluciones, y los líquidos es el resultado de la falta de simetría (Pasteur usaba la palabra disimetría) de las moléculas.
c) La actividad óptica de los cristales cuyas disoluciones (o fundidos) son ópticamente inactivos como, por ejemplo, el cuarzo o el clorato de sodio, se debe al empaquetamiento disimétrico de moléculas simétricas.
d) Al igual que sus cristales, las moléculas diestra y zurda del ácido tartárico eran imágenes especulares (enantiómeros).

Pasteur era muy consciente de la trascendencia de su descubrimiento y de su insignificancia dentro de la comunidad científica francesa. Por ello la forma en que decidiese comunicar sus resultados era de la mayor importancia. Así que, en vez de intentar publicar directamente, escribió a la única persona capaz de entender su trabajo y con influencia suficiente para conseguir una publicación con repercusión: Jean-Baptiste Biot, a la sazón con 74 años, a punto de dejar su cátedra en la Facultad de Ciencias de París y miembro de más de 20 academias científicas europeas y americanas.
Biot reconoció la importancia del descubrimiento inmediatamente y se mostró dispuesto a comunicarlo a la Academia de Ciencias de París a la primera oportunidad. Pero, y en esto Biot demostró ser un científico cabal, no antes de que se reprodujese el experimento en su laboratorio, ensayo al que invitó a asistir a Pasteur.
Biot proporcionó a Pasteur muestras de ácido racémico, preparada por él mismo y en la que había comprobado la inactividad óptica, hidróxido sódico y amoniaco y le pidió que preparase, a partir de ellas, en su presencia, la sal doble de sodio y amonio. Una vez preparada, Pasteur abandonó el edificio y la disolución se dejó evaporar en el laboratorio de Biot en el Collège de France. Cuando se habían separado algo más de 30 g de cristales, Biot convocó de nuevo a Pasteur para que separase los cristales en su presencia. Biot en persona preparó las disoluciones para comprobar la actividad óptica de los mismos. En cuanto colocó en el polarímetro la disolución que debía ser levógira y acercó su ojo al visor, Biot exclamó tomando la mano de Pasteur:
¡Mi querido hijo, he amado tanto durante toda mi vida esta ciencia que siento mi corazón latir de júbilo!
La comunicación a la Academia se produjo ese mismo año de 1848. En los años siguientes, ya profesor universitario en Estrasburgo, Pasteur continuó con sus estudios de la asimetría molecular y cristalina de muchos compuestos, incluyendo los aspartatos y malatos ópticamente activos y los inactivos que se comprobaba que eran “mezclas racémicas”.
En 1853, mismo año en el que se le haría caballero de la Orden Nacional de la Legión de Honor, Pasteur consiguió preparar el tercer isómero del ácido tartárico, ópticamente inactivo, hoy llamado meso-tartárico.
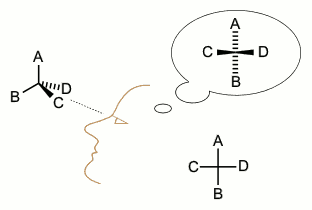
El descubrimiento de Pasteur de la quiralidad molecular (este nombre, ideado por Lord Kelvin en los años ochenta del XIX se acabaría imponiendo frente a las disimetrías de Pasteur) añadió la tercera dimensión a la química y fue el comienzo de la estereoquímica. En las décadas siguientes el concepto de molécula creció de una fórmula (1D), a un grafo (2D) y, finalmente, a finales del XIX, a un objeto 3D.
El modelo tetraédrico para los enlaces del carbono de van’t Hoff y le Bel (1874), el modelo octaédrico de coordinación de Werner (1893) y el trabajo monumental de Emil Fischer sobre la estereoquímica de los azúcares y las proyecciones moleculares (años noventa del XIX) toman como punto de partida el trabajo cristalográfico de Pasteur.
Referencias generales sobre historia de la cristalografía:
[1] Wikipedia (enlazada en el texto)
[3] Molčanov K. & Stilinović V. (2013). Chemical Crystallography before X-ray Diffraction., Angewandte Chemie (International ed. in English), PMID: 24065378
[4] Lalena J.N. (2006). From quartz to quasicrystals: probing nature’s geometric patterns in crystalline substances, Crystallography Reviews, 12 (2) 125-180. DOI:10.1080/08893110600838528
[5] Kubbinga H. (2012). Crystallography from Haüy to Laue: controversies on the molecular and atomistic nature of solids, Zeitschrift für Kristallographie, 227 (1) 1-26. DOI: 10.1524/zkri.2012.1459
[6] Schwarzenbach D. (2012). The success story of crystallography, Zeitschrift für Kristallographie, 227 (1) 52-62. DOI: 10.1524/zkri.2012.1453
Este texto es una revisión del publicado en Experientia docet el 6 de febrero de 2014
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Cristalografía (13): Fiat Pasteur se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Redes y arpones para cazar basura zombie en el espacio

El 4 de octubre de 1957, Sputnik 1 se convertía en el primer satélite artificial puesto en órbita de la historia. Desde entonces, son cientos los dispositivos que han seguido sus pasos. Tantos que a día de hoy, la órbita terrestre es un espacio atestado de cacharros espaciales en diverso grado de descacharramiento y la basura espacial se ha convertido en un problema que amenaza las actuales operaciones y misiones satelitales.
El pasado 2 de julio, un satélite destinado a medición y seguimiento del hielo de los polos, llamado CrioSat-2, operado por la Agencia Espacial Europea, orbitaba como de costumbre a unos 700 metros de altura de la superficie terrestre cuando los ingenieros al mando detectaron un trozo de chatarra espacial flotando en su dirección. Siguiendo la trayectoria de ambos objetos, comprobaron que las probabilidades de un impacto no hacían más que aumentar, así que una semana después decidieron poner en marcha su sistema de propulsión y colocar el CrioSat en otra trayectoria. 50 minutos después de completar la maniobra, la chatarra atravesaba su anterior posición a una velocidad aproximada de 4 kms por segundo.
Este tipo de maniobras para evitar accidentes se ha ido volviendo más y más común a medida que aumentaban los satélites, sondas y pedazos de ambos que pueblan nuestra órbita. En 2017, empresas, gobiernos y ejércitos, así como proyectos amateur, lanzaron al espacio 400 satélites, cuatro veces más que la media anual entre 2000 y 2010. Los números pueden incrementarse aun más si empresas como Boeing o SpaceX siguen adelante con planes ya anunciados para colocar ristras de satélites de comunicaciones que igualarán en cantidad a todos los enviados durante toda la historia de la exploración espacial.
Basura zombie, riesgo de colisión
No solo estamos llenando el espacio de basura igual que estamos haciendo con la Tierra. El problema más urgente es que esto puede convertirse en un peligro. En 2009 un satélite comercial estadounidense chocó con un satélite ruso de comunicaciones ya fuera de uso, creando miles de nuevos trocitos de basura con la que otros satélites pueden ahora chocar, y cada movimiento para evitarlos consume combustible que en teoría debe ser utilizado para la misión principal de cada satélite en cuestión. Es como un laborioso videojuego en el que cada vez es más difícil no chocar con algo mientras la fuente de energía, limitada desde el principio, se va agotando.
Basura espacial, un viaje hasta la Tierra. Fuente: ESA
El enemigo, además, tiene algo de zombi. En torno al 95% de los objetos en órbita son satélites inactivos o piezas rotas de los mismos, según Nature. Eso dificulta saber qué características tienen exactamente, algo que sería muy útil a la hora de evaluar riesgos y de navegar en torno a ellos para evitarlos. En esos casos, las agencias espaciales y los ejércitos utilizan los telescopios disponibles para recoger información durante un determinado periodo de tiempo antes de una posible colisión: si se mantiene estable o se mueve sin control, de qué materiales está hecho, si está afilado o es plano… Cuanto más sepan sobre esa chatarra zombi, mejor.
Así que diversos equipos de científicos están probando distintos enfoques para encontrar el modo de solventar el problema. Algunos han optado por hacer un detallado registro de todos los objetos que pululan por la órbita terrestre, en total unos 20.000, detallando su tamaño y forma de manera que los ingenieros de estos proyectos sepan cómo manejar sus satélites alrededor de cada uno en caso de topárselos. Otros están intentando situar todos esos objetos en su respectiva posición para trazar un mapa de la basura espacial. Otros quieren determinar órbitas y trayectorias seguras para los nuevos satélites.
Redes y arpones para pescar chatarra espacial
Algunos están buscando métodos para reducir la cantidad de chatarra que flota en la órbita terrestre, y uno de esos proyectos se ha planteado pescarla como si fuesen cachalotes y viviésemos en el siglo XIX: a base de redes y arpones. El proyecto se llama RemoveDEBRIS, ha sido desarrollado por la Universidad de Surrey, en Reino Unido, y va a realizar 4 experimentos en los que va a poner a prueba algunos conceptos y posibilidades que podrían ayudar a reducir la cantidad de escombros que pululan en la órbita más baja de la Tierra con un coste moderado.
RemoveDEBRIS, vídeo de la misión. Fuente: Universidad de Surrey.
Con un presupuesto de 15 millones de euros, esos experimentos se realizarán en un periodo de pocos meses. La nave será lanzada hacia la Estación Espacial Internacional en abril y colocada en posición en junio. El 16 o 17 de septiembre de 2019 pondrá en marcha la primera prueba, en la que utilizará una red: lanzará un satélite en forma de cubo, un cube sat, del tamaño aproximado de una caja de zapatos de la que luego saldrá un globo que se hinchará hasta alcanzar un diámetro aproximado de 1 metro. RemoveDEBRIS tratará luego de atraparlo lanzando una red con unos pesos para mantenerlo dentro.
El segundo experimento tendrá lugar a finales de octubre, y en este lanzará otro cubo y utilizará un sistema de rayos láser para escanearlo y aprender de él todo lo posible, además de encontrar la forma de navegar a su alrededor.
En el tercero, calculado para principios de febrero de 2020, RemoveDEBRIS extenderá un brazo robótico de un metro y medio, colocará un plato como objetivo y lanzará contra él un arpón para dejarlo enganchado.
El cuarto y último se espera que se realice en marzo. Para su última prueba, el satélite desplegará un mástil y una vela, que servirá como sistema de impulso para hacer descender al objeto hasta una altura menor, donde finalmente se desintegrará por la fricción contra la atmósfera.
Referencias
Satellite studying Earth’s diminishing ice swerves to avoid collision – Rocket Science Blog, ESA.
Kaputnik chaos could kill Hubble – Nature
The quest to conquer Earth’s space junk problem – Nature
Stand back, Aquaman: Harpoon-throwing satellite takes aim at space junk – Nature
RemoveDEBRIS – University of Surrey
Sobre la autora: Rocío Pérez Benavente (@galatea128) es periodista
El artículo Redes y arpones para cazar basura zombie en el espacio se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Javier Fernández Panadero: “La ciencia no te sirve en la vida cotidiana porque no la conoces”
La ciencia es difícil, a veces, muy difícil. Pero si te dicen que su conocimiento te puede salvar de morir por asfixia en un incendio o convertirte en la persona más habilidosa de la tierra cuando en realidad eres un patoso es posible que tu perspectiva cambie de forma sustancial.
Eso es justamente lo que se ha propuesto el físico Javier Fernández Panadero en su charla “Ha llegado el cacharrista”, desarrollada en la octava edición del evento de divulgación científica Naukas Bilbao, celebrado del 13 al 15 de septiembre en el Palacio Euskalduna de Bilbao.
 Imagen: El físico Javier Fernández Panadero durante su charla en Naukas Bilbao 2018. (Fotografía: Iñigo Sierra)
Imagen: El físico Javier Fernández Panadero durante su charla en Naukas Bilbao 2018. (Fotografía: Iñigo Sierra)La intervención de Fernández Panadero ha permitido comprobar como la combinación del conocimiento científico con la mirada de un ingeniero puede ser la solución a una situación de emergencia.
“La ciencia no me vale para nada porque yo no compro logaritmos de patatas, dicen algunos, pero en realidad la ciencia no te sirve en la vida cotidiana porque no la conoces”, ha asegurado Fernández, que ha convertido su intervención en la demostración empírica de que una persona corriente sumada a unos conocimientos científicos puede ser MacGyver.
Fernández, que es profesor de tecnología en secundaria y un apasionado de la divulgación científica, ha transformado un sujetador en una mascarilla contra humo y polvo que te puede salvar la vida si tienes la mala suerte de verte envuelto en un derrumbamiento o un incendio y ha demostrado que el papel de aluminio puede ser la solución cuando necesitas una pila grande y solo tienes baterías chiquitinas.
Estos experimentos, extraídos de su libro “Como Einstein por su casa”, tienen un mismo hilo conductor: “utilizar los experimentos no solo para ilustrar conceptos científicos, sino para encontrar soluciones a situaciones caseras”.
A través de sus exhibiciones, Fernández Panadero ha dejado claro que solo alguien que conoce bien las propiedades de la seda dental sabe que se trata de una herramienta perfecta para cortar un bizcocho con la precisión de un cirujano “y no desmenuzarlo como sucedería con un cuchillo romo”.
“A veces se confunde la ciencia básica, la que sirve para generar conocimiento, con el planteamiento de un ingeniero que busca su aplicación. Aunque uno no sea hábil si incorpora protocolos se convierte en alguien hábil”, razona.
Desde luego con “cacharrerismo” la física y la ciencia saben mucho mejor.
Sobre la autora: Marta Berard, es periodista en la agencia de comunicación GUK y colaboradora de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Javier Fernández Panadero: “La ciencia no te sirve en la vida cotidiana porque no la conoces” se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Moscas, pan de molde, plastilina y…¡Eureka!
La matemática Clara Grima explica qué son los escutoides en la primera jornada de Naukas Bilbao 2018.
Esta vez no ha sido en una bañera, como en el caso de Arquímedes, sino entre moscas de la fruta, figuras de plastilina y rebanadas de pan de molde, porque estas han sido las herramientas escogidas por la profesora de la Universidad de Sevilla Clara Grima para explicar ante una audiencia ávida de conocimiento científico qué son los escutoides y por qué su su descripción geométrica es tan relevante para la biología, la medicina y las matemáticas.
 Imagen: La matemática Clara Grima durante su charla en Naukas Bilbao 2018. (Fotografía: Iñigo Sierra)
Imagen: La matemática Clara Grima durante su charla en Naukas Bilbao 2018. (Fotografía: Iñigo Sierra)Todo ha sucedido en la primera jornada del evento de divulgación científica Naukas Bilbao, que este año ha celebrado su octava edición en el Palacio Euskalduna de Bilbao, un escenario en el que Grima ha conseguido unir en una misma charla moscas, diagramas matemáticos y biología celular.
“Hemos descrito la forma geométrica de las células epiteliales. Se creía que eran prismas que encajaban como piezas de lego, pero si eso fuera así en las superficies de forma curva saltarían”, ha asegurado Grima. Esas nuevas figuras, cuya geometría no había sido descrita hasta que el grupo de investigadores, liderados por el profesor del Departamento de Biología Celular de la Universidad de Sevilla Luisma Escudero, se puso manos a la obra, son los escutoides.
Pero para comprender su relevancia es clave definir el concepto de epitelio: se trata de un tejido grueso que recubre las superficies de los organismos vivos y que puede ser comparado a “una rebanada de pan de molde”.
Escudero, Grima y el resto del equipo, formado por biólogos, matemáticos y físicos, han conseguido describir cómo es la figura geométrica tridimensional que adoptan las células epiteliales para crear los órganos y generar vida. Y lo han hecho a través de la observación de la saliva de las moscas de la fruta y mediante el uso de una estructura matemática conocida como diagramas de Voronoi.
“La forma de las células epiteliales son los escutoides, que son como unos prismas retorcidos que se abrazan. Luisma los ha representado con la plastilina de su hija Margarita”, ha precisado Clara.
 Imagen: Escutoides. (Fuente: Naukas.com)
Imagen: Escutoides. (Fuente: Naukas.com)La nueva figura descrita explica que las células de los tejidos epiteliales se puedan plegar, adoptar distintas curvaturas y crear órganos que funcionen correctamente. Este hallazgo, que ha sido publicado en la prestigiosa revista científica Nature Communications, cobra relevancia porque contribuye al desarrollo de las ciencias de la salud y puede ayudar en el diseño de tejidos biónicos mediante tecnologías digitales.
Pero además, el descubrimiento permitirá establecer el dibujo de un epitelio sano y disponer de ese modelo resultará útil para compararlo con tejidos reales y detectar anomalías en el crecimiento de las células, lo que llevaría a disponer de nuevas herramientas para el diagnóstico de enfermedades.
“La propia geometría de la naturaleza es la que te dice que las cosas no van bien”, ha añadido Grima con entusiasmo.
Y así, entre moscas, rebanadas de pan y diagramas de Voronoi es como se han descubierto los escutoides. Los responsables de la investigación atribuyen el nombre a la similitud que la nueva figura descubierta tiene con el tórax del escarabajo, denominado scudum, pero Clara ha confesado: “la verdad, verdadera es que viene de (Luisma) Escudero, porque él fue el primero en reclamar que la teoría comúnmente aceptada no encajaba”. Eso y que la plastilina era de su hija.
Sobre la autora: Marta Berard, es periodista en la agencia de comunicación GUK y colaboradora de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Moscas, pan de molde, plastilina y…¡Eureka! se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Los ecosistemas acuáticos de África y el cambio climático
 Río Congo. Foto: Berto Saltori / Flickr Creative Commons
Río Congo. Foto: Berto Saltori / Flickr Creative CommonsEl cambio climático es ya una de las principales causas de la alteración y el deterioro de los ecosistemas y la biodiversidad. El Quinto Informe de Evaluación del Grupo Intergubernamental de Expertos sobre el Cambio Climático de las Naciones Unidas afirma que los ecosistemas africanos ya están viéndose afectados de manera importante por el cambio climático y que se espera que los impactos futuros sean aún más considerables. En este contexto, resulta necesario entender cómo la gestión y mejora de los servicios ecosistémicos, entendidos como la multitud de beneficios que la naturaleza aporta a la sociedad, puede fomentar la capacidad de una sociedad para adaptarse al cambio climático.
Las investigadoras Laetitia Pettinoti del Basque Centre for Climate Change (BC3), Amaia de Ayala de la UPV/EHU y BC3 y Elena Ojea de la Universidad de Vigo han realizado un estudio sobre la importancia que tienen los beneficios de los ecosistemas acuáticos en África para la adaptación al cambio climático.
Los servicios ecosistémicos acuáticos son aquellos que provienen o dependen del agua, ya sea salada o dulce. ‘Nuestro estudio se ha centrado en los ecosistemas de cuencas hidrográficas como los humedales, bosques ribereños, manglares, llanuras de inundación y ríos. Estos ecosistemas proporcionan distintos servicios como provisión de alimento, materias primas, agua y medicamentos, mantenimiento de la calidad del suelo y hábitats, control de inundaciones y promoción del ocio y la cultura’ explica Amaia de Ayala.
África, muy vulnerable al cambio climáticoEl estudio se centra en África por tres razones principales: los flujos de los ríos son esenciales para proveer servicios ecosistémicos necesarios para millones de medios de vida en el continente, África presenta una alta vulnerabilidad al cambio climático lo que conlleva la necesidad de una solución política, y la investigación sobre la relación entre los servicios de los ecosistemas y el cambio climático es escasa. “De esta manera los resultados obtenidos en nuestra investigación proporcionan orientación en el diseño de políticas de adaptación al cambio climático en el continente africano” señala Amaia de Ayala.
Las investigadoras han revisado hasta 36 estudios de valoración de la últimas tres décadas llevados a cabo en África y han creado una base de datos de 178 valores monetarios de servicios ecosistémicos acuáticos. Esto les ha permitido llevar a cabo por primera vez un meta-análisis para África.
El estudio concluye que los países más vulnerables al cambio climático presentan una mayor degradación de su biodiversidad y ecosistemas. Produciéndose, además, un círculo vicioso ya que a mayor degradación de sus ecosistemas, más vulnerables son a los efectos del cambio climático. El PIB per cápita está positivamente relacionado con el valor de los servicios ecosistémicos, mientras que el porcentaje de pobreza rural tiene un efecto negativo sobre ellos.
‘Por tanto, dado que los países menos vulnerables poseen por un lado, una brecha de adaptación menor y, por otro lado, valores de servicios ecosistémicos acuáticos mayores, este estudio sugiere que la adaptación basada en ecosistemas puede ser una medida clave para la adaptación al cambio climático en África’ concluye Amaia de Ayala.
La adaptación basada en los ecosistemas engloba el uso de la biodiversidad y los beneficios de los ecosistemas como parte de una estrategia general de adaptación para ayudar a las personas a adaptarse a los impactos adversos del cambio climático. Dicho de otra forma, utiliza la “infraestructura verde” y los beneficios que aportan los ecosistemas para fomentar la resiliencia de las sociedades humanas al cambio climático. De hecho, 25 países africanos ya han incorporado en sus Programas Nacionales de Acción para la Adaptación al cambio climático la adaptación basada en ecosistemas.
Referencia:
Laetitia Pettinotti, Amaia de Ayala and Elena Ojea (2018) Benefits From Water Related Ecosystem Services in Africa and Climate Change Ecological Economics DOI: 10.1016/j.ecolecon.2018.03.021
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Los ecosistemas acuáticos de África y el cambio climático se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:La ciencia y la guerra

El conflicto bélico es uno de los múltiples ámbitos en los wue se han aplicado los conocimientos de la ciencia, desde tiempo inmemorial. Si el primer uso de la nueva tecnología de la piedra afilada fue destazar animales muertos seguro que el segundo fue abrirle la cabeza al congénere de la tribu de al lado. O viveversa. Y esto es porque, como demuestra la primatología, la guerra estaba con nosotros antes que el saber.
Nuestros parientes chimpancés son capaces de organizarse en bandos, combatir, matar e incluso de llevar adelante campañas de exterminio sin necesidad de lanzas, espadas o fusiles. Basta el fuerte sentido intragrupal y una causa, a veces no muy sólida, para iniciar el conflicto. Y nada de combates rituales o simulacros de batallas: se va a la masacre. Para lo cual no hace falta trigonometría, sino fuerza y mala leche.
No, la ciencia no provoca las guerras, aunque pueda hacerlas más ‘eficientes’ en destrucción y muerte o poner en marcha mecanismos políticos que la hagan inevitable. Quienes luchan contra el conocimiento para evitar las guerras se equivocan, porque ni siquiera la decisión de usar tecnología para matar se toda desde criterios científicos. Y existen alentadores ejemplos de técnicas concretas que se han limitado gracias a la presión de los científicos y el resto de la sociedad por los horrores que provocan. Las armas químicas o nucleares se han usado, aunque poco, por sus efectos: este es el camino.
Prohibir el desarrollo de nuevas áreas de la ciencia para evitar su uso bélico no sólo evita que aparezcan malos desarrollos, sino también buenos. Nunca hay modo de saber cuál será el destino de un nuevo conocimiento. Pero es que además es una forma de automutilación intelectual: lo que no se descubre no se conoce jamás. Es cierto que alunos rincones del universo albergan horrores, y es prudente acercarse y tratalos con precaución. Pero el sistema más seguro es ejercer la vuluntad y decidir no utilizar aquello que sea excesivo para nuestra compasión. Nunca la prohibición y la ausencia voluntaria de saber.
Sobre el autor: José Cervera (@Retiario) es periodista especializado en ciencia y tecnología y da clases de periodismo digital.
El artículo La ciencia y la guerra se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Un mapa del discernimiento
Creo que entre los muchos mapas de los que ha hablado Raúl Ibáñez en este cuaderno, se le ha olvidado al menos uno: el mapa del discernimiento.
 “Une carte du sens” –Un mapa del discernimiento– extraído de [1]. En la página 180 de [2] puede verse una versión en inglés.
“Une carte du sens” –Un mapa del discernimiento– extraído de [1]. En la página 180 de [2] puede verse una versión en inglés.
Pero empecemos por el principio. Prédire n’est pas expliquer –Predecir no es explicar (Editions Eshel, 1991)– es el título de una serie de entrevistas que el matemático René Thom (1923-2002) mantuvo con Emile Noël. En este texto, Thom explicaba la génesis de su teoría de las catástrofes y exponía sus posiciones filosóficas sobre la ciencia.
En una parte de este escrito, el Medalla Fields describía una comida que compartió con el psiquiatra Jacques Lacan (1901-1981). Durante ese almuerzo, el psicoanalista invitó a Thom a hablar sobre su percepción de las matemáticas, sobre la evolución de sus ideas y sobre su relación con el concepto de matema. Al final de la comida, René Thom lanzó este pensamiento: “La verdad no está limitada por la falsedad, sino por insignificancia”.
El matemático realizó posteriormente un dibujo intentando aclarar y matizar esta afirmación, el que aparece en la imagen que inicia este escrito.
Debajo se reproduce la traducción del texto que aparece en [1] en el que René Thom explica los lugares de este especial mapa:
En la base se encuentra un océano, el Mar de la Insignificancia. En el continente, la Verdad se sitúa a un lado, la Falsedad en el otro. Están separadas por un río, el Río del Discernimiento. De hecho, lo que separa la verdad de la falsedad es la facultad de discernimiento. Es una noción que se debe a Aristóteles: la capacidad para la contradicción. Es lo que nos separa de los animales: cuando ellos reciben una información, la aceptan instantáneamente y desencadena la obediencia a este mensaje. Los seres humanos, sin embargo, tienen la capacidad de retractarse y cuestionar su veracidad.
Siguiendo la orilla de este río, que desemboca en el Mar de la Insignificancia, se viaja a lo largo de una costa que es ligeramente cóncava: en un extremo se encuentra la Ciénaga de la Ambigüedad y en el otro extremo se halla el Pantano del Perogrullo. Al frente del delta del río, se ve la Fortaleza de la Tautología: Ese es el baluarte de los lógicos. Se sube una muralla hacia un pequeño templo, una especie de Partenón: estas son las Matemáticas.
A la derecha, se encuentran las Ciencias Exactas: en las montañas que rodean la bahía se sitúa la Astronomía, con un observatorio que corona su templo; en el extremo derecho se hallan las máquinas gigantes de la Física, los anillos del acelerador en el CERN; los animales en sus jaulas señalan los laboratorios de Biología. Fuera de todo esto emerge un arroyo que se alimenta en el Torrente de la Ciencia Experimental y que desemboca en el Mar de la Insignificancia.
A la izquierda hay un camino ancho que sube hacia el noroeste, llega hasta la Ciudad de las Artes y las Ciencias Humanas. Continuando a lo largo de ella, se llega a las laderas del Mito. Hemos ingresado en el reino de la Antropología. Arriba, en la parte superior, se encuentra la Altiplano del Absurdo. La columna vertebral significa la pérdida de la capacidad de discernir contrarios, algo así como un exceso de comprensión universal que hace que la vida sea imposible.
Según comenta el propio Thom en [1], Une carte du sens –este mapa del discernimiento– imita la Carte du Tendre, el mapa de un país imaginario llamado Tendre que aparece en la novela Clélie, histoire romaine de la escritora Madeleine de Scudéry (1607-1701). Este mapa es una ‘representación topográfica y alegórica de la conducta y de la práctica amorosa’…
 “Carte du Tendre” de François Chauveau. Wikimedia Commons.
“Carte du Tendre” de François Chauveau. Wikimedia Commons.Referencias
[1] The Map of Discernment, Futility Closet, 22 julio 2018
[2]Roy Lisker, René Thom. Interviews with Emile Noël, traducción de Prédire N’est Pas Expliquer, 2010
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Un mapa del discernimiento se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Cristalografía (12): In vino veritas

Según la mitología griega fue el mismísimo dios Dionisios el que descendió del Monte Olimpo para enseñar a los hombres a fabricar vino. Según la arqueología moderna ese descenso, de haber existido, habría tenido lugar en Asia Menor (en lo que hoy es el este de Turquía) hace unos 7.000 años. Junto con el arte del vino, Dioniso donó otro regalo que pasó mucho tiempo sin ser reconocido como tal, el tártaro, que se encuentra en el fondo de, entonces, las ánforas y, hoy, las barricas de vino.
Tanto Lucrecio como Plinio el viejo estaban familiarizados con el tártaro. Lo que hoy sabemos que es tartrato ácido de potasio (formalmente hidrógeno tartrato de potasio) era descrito como de sabor agrio y que ardía con una llama de color púrpura, además de proporcionar recetas para una docena de remedios que lo contenían.
Se estudió con más detalle en la Edad Media. El alquimista persa Abū Mūsa Ŷābir ibn Hayyan al-Āzdī (conocido en Europa como Geber) fue el primero en dejar constancia por escrito, alrededor del año 800, de que el tártaro es una sal y aisló el ácido tartárico (y otra buena cantidad de compuestos orgánicos, pero esa es otra historia) aunque no con demasiada pureza. Hubo que esperar a 1769 para obtener el ácido tartárico químicamente puro, cosa que logró Carl Wilhelm Scheele (a la par que otra buena cantidad de compuestos orgánicos). El compuesto se empleaba en la fabricación de cosméticos y remedios medicinales, como la sal de la Rochelle o el tártaro emético, por lo que muchas bodegas se convirtieron de facto en fábricas de ácido tartárico.

Alrededor de 1818, Paul Kestner, un productor de tártaro de Thann (Francia) se dio cuenta de que, además de ácido tartárico se producía en sus barriles una pequeña cantidad de cristales de lo que parecía otra sustancia. Al principio pensó que podría ser ácido oxálico; sin embargo, al poco tiempo se dio cuenta de que era algo nuevo y empezó a producirlo en cantidades mayores a base de hervir disoluciones saturadas de ácido tartárico. En 1826, convencido completamente de que era algo desconocido para la ciencia, se decidió a llevar una muestra a Gay-Lussac, quien, después de repetidos experimentos, llegó a la conclusión de que su fórmula era C4H6O6, la misma del ácido tartárico. Llamó a este nuevo compuesto ácido racémico (del latín racemus, esto es, racimo de uvas).
Las diferencias químicas entre los ácidos tartárico y racémico (y entre sus sales , tartratos y racematos) eran pequeñas, pero suficientes como para tener intrigados a los químicos. Este fue uno de los casos de isomería conocidos en la época; además muchas de las sales de los dos ácidos eran isomorfas.

Un aspecto importante en lo trascendencia que llegaron a tener estos ácidos en el desarrollo de la ciencia fue su bajo coste y la facilidad de obtención en una época, principios del XIX, en la que la industria química estaba en su infancia y los productos químicamente puros eran una rareza. Además racematos y tartratos eran muy fáciles de preparar y conseguir cristales de tamaño apreciable no era nada complicado. Por lo tanto, era el sistema perfecto en el que estudiar dos conceptos nuevos pero que no se terminaban de entender, y que había indicios de que podían estar relacionados: isomería e isomorfismo.
En los años posteriores a 1830 Biot midió la actividad óptica del ácido tartárico y sus sales (dextrógiros todos ellos); el racémico y las suyas eran ópticamente inactivas. Berzelius, empeñado en encontrar una explicación al fenómeno, instó a Mitscherlich, ya una autoridad en la química cristalina, a que estudiase la simetría de tartratos y racematos.
Mitscherlich confirmó los hallazgos de Biot, el tartárico y sus sales eran todos dextrógiros y sus cristales hemiédricos; el racémico y las suyas inactivos ópticamente y sus cristales holoédricos. Había dos sales que no cumplían estas reglas generales: el tartrato de sodio y amonio y el racemato de sodio y amonio que formaban cristales idénticos pero de actividad óptica de signo opuesto. Mitscherlich estaba tan confundido por este hecho al que no era capaz de encontrar una explicación que no publicó sus resultados en más de una década. Sólo lo haría en 1844, después de que en 1841 Frédéric Hervé de la Provostaye publicase un estudio similar.
El misterio sería resuelto en 1848 por un joven y desconocido profesor de Dijon, recién doctorado, Louis Pasteur.
Referencias generales sobre historia de la cristalografía:
[1] Wikipedia (enlazada en el texto)
[3] Molčanov K. & Stilinović V. (2013). Chemical Crystallography before X-ray Diffraction., Angewandte Chemie (International ed. in English), PMID: 24065378
[4] Lalena J.N. (2006). From quartz to quasicrystals: probing nature’s geometric patterns in crystalline substances, Crystallography Reviews, 12 (2) 125-180. DOI:10.1080/08893110600838528
[5] Kubbinga H. (2012). Crystallography from Haüy to Laue: controversies on the molecular and atomistic nature of solids, Zeitschrift für Kristallographie, 227 (1) 1-26. DOI: 10.1524/zkri.2012.1459
[6] Schwarzenbach D. (2012). The success story of crystallography, Zeitschrift für Kristallographie, 227 (1) 52-62. DOI: 10.1524/zkri.2012.1453
Este texto es una revisión del publicado en Experientia docet el 30 de enero de 2014
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Cristalografía (12): In vino veritas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:La regulación de la diuresis en mamíferos
Al contrario que otros vertebrados, los mamíferos (salvo algunas especies, como los dromedarios) no ajustan la producción de orina modificando la tasa de filtración glomerular (GFR). De hecho mantienen esta relativamente constante y modifican la fracción de la orina primaria que es reabsorbida antes de su evacuación al exterior para regular el volumen y la concentración osmótica de los fluidos corporales.
Un porcentaje relativamente alto de la orina primaria –entre un 60% y 80% del volumen- es reabsorbido desde el túbulo contorneado proximal, para lo cual se reabsorben activamente porcentajes similares de NaCl. Además de la sal y el agua, glucosa, aminoácidos y bicarbonato son también reabsorbidos en ese segmento, estos prácticamente en su totalidad.
La reabsorción de Na+ se produce gracias a la actividad de una ATPasa de Na+-K+ de la membrana basolateral del epitelio (la que separa el líquido intersticial del interior celular). Ese transporte genera un gradiente electroquímico en la membrana apical (la que separa el interior celular de la luz del túbulo) que favorece la entrada de sodio desde el fluido tubular. La reabsorción de agua se produce a través de aquaporinas estructurales, que se hallan siempre presentes en esas células (su presencia apenas depende de factores externos).
Tras pasar por el túbulo proximal, la orina penetra en el asa de Henle. Lo hace con una concentración osmótica de unos 300 mOsm, pero tras su recorrido por ese segmento, puede alcanzar el túbulo distal con una concentración inferior a la anterior (puede llegar a ser de 100 mOsm). Como vimos, esa diferencia es debida al transporte activo de NaCl que tiene lugar en la rama ascendente, que lo retira de la orina, disminuyendo en ella su concentración, a la vez que aumenta la del líquido intersticial.
Tras el asa de Henle la orina accede al túbulo contorneado distal. El epitelio de ese segmento transporta NaCl activamente de la luz del túbulo al especio intersticial. Y aunque no es impermeable, es poco permeable al agua.
Lo que ocurre a continuación en el tubo colector depende de cuáles son las necesidades hídricas del organismo. Si necesita retener agua, el organismo se encuentra en estado de antidiuresis y el riñón producirá un volumen de orina muy limitado. Eso es consecuencia de una intensa reabsorción de agua en el tubo colector, reabsorción que se produce gracias a la presencia en la membrana apical de las células de la pared del tubo de numerosas moléculas de una forma de aquaporina (AQP-2) específica de ese epitelio. Recordemos que debido al transporte activo de NaCl que tiene lugar en la rama ascendente del asa de Henle y al equilibrio iónico y osmótico que se establece entre su rama descendente y el fluido intersticial de la médula renal, la concentración osmótica de ese fluido en el interior medular es muy alta. Por ello, la presencia de numerosos poros en las membranas apicales de las células de la pared del tubo colector permiten que el agua pase con gran facilidad de un fluido que se encuentra originariamente a una concentración osmótica muy baja (la orina que llega del túbulo distal) a otro con la concentración osmótica muy alta (el fluido intersticial medular). Y eso ocurre hasta que ambas concentraciones osmóticas se igualan, para lo que debe pasar un volumen muy importante de agua. Además, a lo largo del tubo colector se sigue reabsorbiendo activamente NaCl, lo que favorece aún más este proceso. Como consecuencia de esa reabsorción, la orina final puede llegar a representar tan solo un 1% del volumen de plasma filtrado en el glomérulo y alcanzar una concentración osmótica de 1200 mOsm, que es cuatro veces más alta que la del plasma. Pero en mamíferos con grandes restricciones hídricas esa concentración puede llegar a multiplicarse por diez o más. Producen mínimas cantidades de orina y evitan así perder agua por esa vía.

Ese estado de antidiuresis a que me he referido en el párrafo anterior es el que se produce cuando hay una alta concentración sanguínea de la hormona antidiurética (ADH), que en mamíferos es la arginina vasopresina (AVP). Es ella la responsable de la presencia en las células de la pared del ducto de numerosas unidades de aquaporinas AQP-21. Por ello, cuando las condiciones cambian y no hay necesidad de ahorrar agua o, incluso, conviene eliminarla, deja de secretarse ADH desde la neurohipófisis, baja su concentración sanguínea y, como consecuencia de ello, las aquaporinas son retiradas de la membrana apical de las células del epitelio del tubo colector. Disminuye así su permeabilidad al agua (llega a hacerse virtualmente impermeable) y deja de reabsorberse agua desde el interior del tubo hacia los espacios intersticiales. El volumen de orina es muy alto y su concentración osmótica, muy baja. De hecho, en seres humanos esa concentración puede ser tan baja como 50 mOsm, o sea, seis veces más baja que la plasmática, y el volumen de orina producido elevarse hasta representar un 15% del plasma filtrado en el glomérulo. Merece la pena reparar en el hecho de que una concentración osmótica de la orina tan baja no es solo el resultado de la supresión de la reabsorción de agua desde el tubo colector, sino que es necesario que se produzca una importante reabsorción de NaCl que no vaya acompañada de la correspondiente reabsorción de agua.
La ADH no es la única hormona implicada en la regulación de la función renal en mamíferos. La aldosterona y el péptido natriurético auricular cumplen también un importante papel. Antes de exponer brevemente en qué consiste, conviene advertir que tanto la aldosterona como, en general, las hormonas natriuréticas, o hormonas de similares naturaleza y efectos, se hallan en muchos otros grupos, además de mamíferos, pero su papel se entiende mejor en este contexto.
La aldosterona promueve la recuperación de Na+ desde la orina primaria y también la secreción de K+. Por ello, su efecto global más obvio es regular el contenido de esos iones en los fluidos corporales. Sin embargo, de forma indirecta también cumple un papel determinante en la regulación del volumen de los fluidos extracelulares, plasma sanguíneo incluido. La razón es que la concentración osmótica y de sales, como sabemos, se halla estrechamente controlada en los mamíferos y, en general, en el resto de los vertebrados. Por ello, el volumen de agua extracelular es muy dependiente de la cantidad de NaCl que hay en esos fluidos (no así en los intracelulares, cuyo catión principal es el K+), ya que Na+ y Cl– son los principales iones extracelulares. Así pues, si una hormona, como la aldosterona, promueve la reabsorción de Na+, también promueve la de Cl– y, por supuesto, la de agua. En otras palabras: cuanto más Na+ se reabsorbe en el riñón, también se reabsorbe más agua, por lo que su efecto neto es antidiurético.
La aldosterona es una hormona esteroidea, un mineralocorticoide producido por la corteza adrenal. Su secreción está controlada por otro sistema hormonal, el sistema renina-angiotensina que, a su vez, se encuentra parcialmente controlado por receptores de presión sanguínea y de volumen sanguíneo. Cuando la presión de la sangre baja y en virtud de varios mecanismos que actúan simultáneamente, las células yuxtaglomerulares (células especializadas del endotelio de la arteriola aferente) liberan renina. La acción (enzimática) de la renina sobre una molécula precursora de origen hepático (el angiotensinógeno) acaba dando lugar a que se produzca una sustancia denominada angiotensina II. Esta ejerce varios efectos: estimula la constricción (estrechamiento) de arteriolas sistémicas; promueve la sed; estimula la secreción de ADH y estimula la secreción de aldosterona. Todas las actuaciones provocadas por la angiotensina II causan la recuperación de agua y el reestablecimiento de la presión sanguínea y el volumen de líquidos extracelulares adecuados. Cuando la acción de la renina ha surtido sus efectos, ciertas sustancias paracrinas producidas por las células de la macula densa2 provocan que las células yuxtaglomerulares dejen de liberar renina.
La aldosterona actúa penetrando en sus células diana (a los efectos de lo que nos interesa aquí se trata de las células del epitelio del túbulo distal), llega al núcleo e inicia la transcripción de ADN para producir nuevas ATPasas de Na+-K+ y de canales de Na+ y de K+ para su inserción en la membrana celular. De esta forma se eleva la reabsorción tubular de Na+ y como consecuencia, la recuperación de agua y la restauración del volumen sanguíneo. Este mecanismo actúa, de hecho, en respuesta a situaciones –como las hemorragias- en las que se produce una importante pérdida de líquido sin que ello vaya asociado a una elevación de la concentración osmótica sanguínea.
Hay gran diversidad de péptidos natriuréticos en el dominio animal, y el mejor conocido es el péptido natriurético auricular (ANP, por sus siglas en inglés) de los mamíferos. El ANP se produce en determinadas zonas del encéfalo y en el corazón (de ahí su nombre “auricular”) y sus efectos son en gran parte opuestos a los de la aldosterona. Inhibe, de hecho, la liberación de aldosterona y promueve directamente la secreción de Na+, elevando la producción de orina y la concentración de Na+ en esta. La secreción de ANP es estimulada por el aumento del volumen de líquidos extracelulares, lo que es detectado a partir del estiramiento de las paredes de la aurícula en el corazón.
En definitiva, la función renal está sometida a un complejo sistema de regulación principalmente endocrino. Aquí hemos visto los tres sistemas principales, cada uno con sus especificidades. Gracias a ese sistema de efectos múltiples, los mamíferos, y demás vertebrados, son capaces de mantener estrechamente controlados tanto el volumen de los líquidos corporales, como sus concentraciones osmóticas e iónicas.
Notas:
1El mecanismo es muy similar al que vimos para la mayor parte de vertebrados, aunque en los otros grupos de vertebrados la ADH actúa en el túbulo distal y la molécula de efectos antidiuréticos en los demás vertebrados era algo diferente: arginina vasotocina (AVT).
2Grupo de células especializadas que se disponen en el punto en que el túbulo distal y la arteriola aferente se encuentran en posición adyacente.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo La regulación de la diuresis en mamíferos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La regulación osmótica e iónica en los teleósteos marinos
- La función del asa de Henle en el riñón de mamíferos
- La regulación osmótica de los animales de agua dulce
Una vida eterna
Sabíamos que en unas cuantas especies animales los individuos viven más y se encuentran en mejor estado de salud si se les reduce la ingesta de alimento. Pero no acabábamos de saber si esa misma forma de prolongar la vida sería aplicable a los seres humanos. Seguimos sin saberlo, pero una investigación cuyos resultados se publicaron hace unas semanas en la revista Cell Metabolism parece aportar algunas claves del mecanismo que permitiría que la (así llamada) restricción calórica pudiese alargar la vida de quienes la experimentan.

Fuente: Redman et al. (2018) / Cell Metabolism
En la investigación mencionada se limitó la ingestión de alimento a treinta y cuatro personas de ambos sexos, y a otras diecinueve que mantuvieron sus hábitos alimenticios se les monitorizó para que sirvieran de control. Todos los participantes en el estudio eran adultos, ninguno era obeso y, por supuesto, eran voluntarios. Redujeron su ingesta en un 15%, pero se aseguraron una toma adecuada de los nutrientes esenciales.
Dos años después de iniciado el experimento habían perdido 9 kg de peso, mientras que los controles habían ganado 2 kg. Junto con la pérdida de peso, los individuos sometidos voluntariamente a la restricción calórica experimentaron también una importante reducción del gasto metabólico: cada día gastaron entre 80 y 120 kcal menos que las que cabía esperar a partir de la pérdida de peso. O sea, a lo largo de ese periodo de tiempo, la actividad metabólica de los que redujeron la ingesta se adaptó, reduciéndose a niveles inferiores a los característicos de la situación anterior al experimento. Esa adaptación metabólica vino acompañada por una bajada en la actividad de las hormonas tiroideas, que son las principales encargadas de regular el metabolismo. Y también se redujo el denominado “estrés oxidativo”, que es una condición fisiológica perjudicial para las células -y por lo tanto para los órganos y el conjunto del organismo- que se produce como consecuencia de un desequilibrio entre la producción de sustancias oxidantes muy dañinas y la capacidad de los sistemas biológicos para neutralizar esas sustancias o reparar el daño que causan.
Estos resultados refuerzan dos hipótesis sobre las causas del envejecimiento que cuentan con amplia aceptación, la de la velocidad vital (rate of living) y la del daño oxidativo; como veremos, además, ambas son perfectamente compatibles. De acuerdo con la hipótesis de la velocidad vital, que se formuló inicialmente hace cerca de un siglo, la longevidad es inversamente proporcional a la tasa metabólica de un individuo; o sea, cuanto mayor es esa tasa y, por ende, la actividad biológica que refleja, menor es la duración de la vida. Y según la segunda hipótesis, sería el daño que causa el estrés oxidativo al ADN, las proteínas y otras macromoléculas, el responsable del acortamiento de la vida, pues el envejecimiento sería consecuencia de la acumulación de daños. Así pues, bien podría ocurrir que la relación negativa entre actividad metabólica y longevidad viniese mediada por el efecto dañino de las sustancias oxidantes sobre las estructuras biológicas.
En definitiva, el organismo humano se adapta a la privación de alimento reduciendo la velocidad a la que transcurren los procesos vitales. Comer menos conlleva una vida fisiológica más lenta y, en cierto modo, más eficiente. Además, otros estudios han encontrado que un metabolismo basal alto se asocia con un peor estado de salud y mayor riesgo de mortalidad temprana. Por lo tanto, aunque es cierto que este estudio no permite extraer conclusiones firmes y que los datos disponibles no son concluyentes, lo más probable es que comer menos alargue la vida. Eso sí, de lo que podemos estar seguros es de que nos la haría parecer eterna.
Fuente: Leanne M. Redman, Steven R. Smith, Jeffrey H. Burton, Corby K. Martin, Dora Il’yasova & Eric Ravussin (2018): Metabolic Slowing and Reduced Oxidative Damage with Sustained Caloric Restriction Support the Rate of Living and Oxidative Damage Theories of Aging Cell Metabolism 27 (4): 805-815
—————————————————————–
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
————————
Una versión anterior de este artículo fue publicada en el diario Deia el 6 de mayo de 2018.
El artículo Una vida eterna se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Andar puede salvarte la vida
- La historia de la vida
- En la ría palpita la vida, por José Ignacio Saiz Salinas
Nuevas tecnologías para el estudio del cerebro: Desde Cajal a nuestros días

Uno de los objetivos fundamentales de la neurociencia es comprender los mecanismos biológicos responsables de la actividad mental humana. En particular, el estudio de la corteza cerebral constituye el gran reto de la ciencia en los próximos siglos, pues representa el fundamento de nuestra humanidad.
La ciencia ha avanzado de un modo espectacular en las últimas décadas, permitiendo desentrañar algunos de los misterios que encierra el cerebro. Sin embargo, aún no tenemos respuesta a algunas de las principales preguntas de la neurociencia, como por ejemplo: ¿Qué nos hace a las personas humanas? ¿Qué tiene de especial la neocorteza humana? ¿Cómo se altera el cerebro y por qué se produce la esquizofrenia, el Alzheimer o la depresión?
El neurobiólogo y profesor de investigación en el Instituto Cajal (CSIC), Javier de Felipe Orquieta responde a estas cuestiones en la conferencia: “Nuevas tecnologías para el estudio del cerebro: Desde Cajal a nuestros días“. En esta charla Javier de Felipe muestra las distintas líneas de investigación que llevan a cabo proyectos como Blue Brain, Cajal Blue Brain, Human Brain Project o Brain Activity Map para el conocimiento del funcionamiento del cerebro.
La conferencia tuvo lugar el pasado 23 de abril en el Bizkaia Aretoa de Bilbao y forma parte del ciclo de conferencias Achucarro Forum que organiza el centro vasco de neurociencia del mismo nombre para la sensibilización social sobre la investigación de cerebro y sus enfermedades.
'Nuevas tecnologías para el estudio del cerebro:desde Cajal a nuestros día'Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Nuevas tecnologías para el estudio del cerebro: Desde Cajal a nuestros días se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- “La aplicación de las nuevas tecnologías en agricultura” por Pere Puigdomènec
- #Naukas14 Regenerar el cerebro
- Estudio de eficacia escolar en el País Vasco
La energía de las olas ha aumentado un 40 % en el último siglo.
Los convertidores de energía olamotriz son diseñados para generar la máxima energía posible en su ubicación, y toman como referencia un año típico del lugar. Investigadores de diferentes centros de la UPV/EHU han estudiado, junto con el Centro de Investigación de Energía Marina irlandés, la evolución de la energía marina en Irlanda durante el último siglo. Los resultados revelan un incremento de hasta un 40%, lo cual afecta directamente al rendimiento de los convertidores.

Foto: Pete Conroy / Stab Magazine
Los convertidores de energía olamotriz o undimotriz están específicamente diseñados para tener un rendimiento máximo en la ubicación que vayan a tener, es decir, para generar la mayor cantidad de electricidad posible del movimiento de las olas de su entorno. El diseño y adaptación se hace basándose en datos históricos, en la altura y periodo que presentaron las olas en el pasado. “Sin embargo, el espacio de tiempo que se tiene en cuenta suele ser bastante reducido, y, además, se considera el año típico de ese periodo. Así, los convertidores se ajustan en función del comportamiento que deberían tener en ese año típico”, explica Alain Ulazia, profesor de la Escuela de Ingeniería de la UPV/EHU en Eibar .
Teniendo en cuenta los cambios que se están produciendo como consecuencia del cambio climático en cuanto a la temperatura y otros parámetros meteorológicos, Ulazia y otros dos investigadores de la UPV/EHU, de los departamentos de IN y Mecánica de Fluidos y Física Aplicada II, así como de la Estación Marina de Plentzia, en colaboración con el Centro de Investigación de Energía Marina de Irlanda abordaron una investigación de mayor plazo. “Llevamos a cabo en Irlanda un estudio que anteriormente habíamos realizado en el Golfo de Bizkaia, dado que Irlanda es particularmente energética en cuanto a la energía de las olas, y quisimos analizar esa energía como recurso. Calculamos, mediante simulación, qué respuesta o comportamiento habría tenido un convertidor ante el nivel de energía registrado en el último siglo, dividido en periodos de 20 años, dado que los convertidores tienen una vida útil de 20 años de media”, detalla.
Para esta labor, han tenido como fuente de información dos bases de datos del Centro Europeo de Predicción a Plazo Medio (ECMWF): ERA-Interim y ERA20. Ambas son reanálisis, es decir, bases de datos surtidas con multitud de observaciones y mediciones. Son redes espaciales, que proporcionan largas series temporales en cada uno de los ojos de la red, es decir, para cada ubicación. La más conocida es la ERA-Interim, ya que reúne infinidad de datos, incluso provenientes de satélites, pero su limitación es que “solo cuenta con datos de los últimos 40 años —aclara Ulazia—. La ERA20, por su parte, se nutre de muchos menos datos, y es más irregular desde la perspectiva tanto temporal como espacial, pero aporta datos de todo el s. XX”.
En la investigación, calibraron una base de datos contra la otra, valiéndose del periodo de solapamiento que tienen. Y posteriormente las validaron contra las mediciones tomadas en las boyas del Atlántico. Tal como declara Ulazia, “hemos concluido que los datos son aceptables, que se pueden dar por buenos, por lo que hemos podido simular los niveles de energía en los que deberían haber trabajado los convertidores”.

El convertidor olamotriz Oyster, utilizado para el estudio. Foto: Alain Ulazia – UPV/EHU.
Tomando como referencia los 20 años de vida útil media de los convertidores de energía olamotriz, dividieron el siglo pasado en cinco periodos, y adaptaron los conversores para el nivel de energía correspondiente a cada uno de esos periodos. “Encontramos que, del primer periodo de tiempo al último, el nivel de energía marina se ha visto incrementado más de un 40 %, y el incremento mayor se ha dado en los último 20 años (18 %) —subraya el investigador—. No hemos entrado a analizar qué es lo que ha provocado ese aumento, pero la hipótesis principal sería el cambio climático”.
El hecho de que haya grandes oscilaciones en la energía de las olas tiene consecuencias directas en el rendimiento de los convertidores; en la investigación han podido ver, por ejemplo, que “los convertidores no han aprovechado toda la energía que tenían a su alcance, y, además, los eventos extremos, tales como episodios de olas de más de siete metros o fenómenos como El Niño, han sido más frecuentes conforme avanzaba el siglo. Como consecuencia, los convertidores han tenido que entrar más a menudo en modo de supervivencia, y dejar de producir energía mientras duraban estos eventos marinos”, comenta.
La información obtenida debería valer, según Ulazia, para optimizar el diseño de los convertidores: “Como estos dispositivos se optimizan en función de la altitud y el periodo de las olas, habría que adaptar su diseño para que tengan un rendimiento máximo en condiciones que cada vez son más energéticas”.
Referencia:
Markel Peñalba, Alain Ulazia, Gabriel Ibarra-Berastegui, John Ringwood, Jon Sáenz (2018) Wave energy resource variation off the west coast of Ireland and its impact on realistic wave energy converters’ power absorption Applied Energy doi: 10.1016/j.apenergy.2018.04.121
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo La energía de las olas ha aumentado un 40 % en el último siglo. se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- ¿Son eficientes las plantas de energía marina?
- Las barreras a los edificios de consumo de energía casi nulo en el sur de Europa
- Se intuye la conservación de la energía (1)
Los desodorantes con aluminio no causan cáncer

Los cosméticos son seguros. El aluminio de los desodorantes no causa cáncer ni ninguna otra enfermedad. De no ser así, de encontrar alguna evidencia que ponga en duda su seguridad, las autoridades sanitarias actuarían de inmediato prohibiendo su uso y retirándolos del mercado. Así es cómo se zanja cualquier debate sobre la seguridad de los cosméticos. Sin embargo, los rumores persisten a pesar del sentido común. Hay quien prefiere creer en endemoniadas conspiraciones de la industria y en la corrupción sistemática de las autoridades.
Para salir de toda duda, en este artículo abordaremos el origen del mito, la evidencia científica que existe al respecto y para qué llevan aluminio los desodorantes. Desde luego, estos cosméticos no llevan aluminio para enfermar a la población, sino para lo obvio: ser eficaces contra el sudor.
-
El origen del mito
En el artículo publicado en el Journal of the National Cancer Institute titulado «¿Los rumores pueden causar cáncer?» se explica que el rumor de que el aluminio de los desodorantes producía cáncer de mama se extendió hace más de 18 años vía email. Es difícil saber dónde y a quién se le ocurrió relacionar el cáncer de mama con el uso de desodorantes. No había ningún indicio ni sospecha sobre aquello, por lo que se elaboró una explicación que, aunque estaba fuera de toda lógica, parecía creíble. En esos correos se explicaba que «las sales de aluminio presentes en los antitranspirantes, al taponar los conductos de las glándulas sudoríparas, impedían la expulsión de las toxinas y provocaban su concentración en los ganglios linfáticos de las axilas, donde causaban cambios celulares que conducían al cáncer. (…) Los “compuestos químicos” de los desodorantes se absorbían a través de la piel e interferían con las hormonas y propiciaban el crecimiento celular de los cánceres de mama». Las proclamas se apoyaban en el hecho de que la mayoría de los tumores mamarios brotan en la región más próxima a la axila.
La explicación suena factible. Tanto es así que el rumor sigue persistiendo 18 años después. Es una de las consultas que recibo con más asiduidad.
-
La evidencia científica
La investigación científica tampoco se quedó al margen del rumor y, desde entonces, ya se han publicado varios estudios en los que se ha tratado de relacionar sin éxito el aluminio con el cáncer de mama. Ninguno de ellos ha sido concluyente, es decir, no existen evidencias científicas que relacionen el uso de desodorantes con aluminio y el cáncer de mama.
Los más relevantes quizá sean este estudio de 2002 y este otro de 2006. En 2014 se publicó esta amplia revisión sistemática, cuya conclusión fue que no hay pruebas que relacionen un aumento del cáncer de mama con el uso de cosméticos antitranspirantes.
Ni siquiera el aluminio que contienen los antitranspirantes tiene una gran capacidad de ser absorbido por la piel. Según este estudio, tan solo el 0,012% del aluminio cosmético atraviesa la dermis. Con lo cual el aluminio que llega a nuestro organismo habrá tenido que acceder por otra vía, principalmente a través de la alimentación. El estudio concluye que el aluminio cosmético «no contribuye significativamente a la carga corporal de aluminio».
Rebuscar entre engorrosas publicaciones científicas es muy trabajoso. Por eso es aconsejable acudir a la información divulgativa que comparten organismos oficiales como la Asociación Española Contra el Cáncer, la FDA, la OMS o el Instituto Nacional del Cáncer de EEUU. Todos estos organismos están de acuerdo en lo mismo: no hay relación entre el aluminio y un mayor riesgo de padecer cáncer de mama.
Hay estudios que culminan diciendo que, aunque no se haya encontrado relación, es un asunto que debe seguir investigándose. Esto es una obviedad, sin embargo se ha convertido en uno de los argumentos que esgrimen los rumorosos. Réplicas del tipo «Ningún estudio ha demostrado que los desodorantes no causen cáncer» son absurdas y confusas. Es igual de absurdo que decir «Ningún estudio ha demostrado que bailar no cause cáncer». No se puede demostrar que algo no causa cáncer. Solo podemos probar si algo sí lo causa.
-
¿Por qué huele el sudor?
El sudor procedente de las glándulas ecrinas, que abundan especialmente en la cara, el pecho y las palmas de las manos, casi no produce ningún olor porque su composición es básicamente agua y sales minerales. Su función es termorreguladora. En cambio, las glándulas apocrinas localizadas mayoritariamente en axilas, ingles y pubis emanan un sudor más viscoso, compuesto por agua, lípidos, ésteres y polisacáridos.
Los fluidos que emanan ambas glándulas no huelen. Sin embargo, las bacterias que tenemos en la piel de forma natural se alimentan de los compuestos presentes en estos fluidos y los degradan produciendo ácidos grasos de cadena corta, compuestos sulfurados y nitrogenados que sí tienen olor. La concentración se sustancias susceptibles de ser degradadas por bacterias las encontramos en los fluidos de las glándulas apocrinas, por eso el mal olor del sudor se suele concentrar en las axilas y el pubis. Además estas zonas suelen estar poco aireadas y a veces envueltas en vello, lo que propicia el ambiente húmedo y oscuro que conviene a las bacterias.
El sudor apocrino se segrega a partir de la pubertad, por eso los niños tienen un olor diferente y leve en comparación con los adolescentes. A medida que envejecemos nuestras glándulas apocrinas se ralentizan, por lo que las personas mayores suelen tener menos olor corporal.

-
¿Por qué ponemos aluminio en los desodorantes?
De forma general denominamos «desodorante» tanto a los cosméticos que contienen antitranspirantes como a los que solo contienen desodorantes. No obstante, son cosas distintas:
Los desodorantes son sustancias que enmascaran el olor (como perfumes o aceites esenciales) o son agentes antimicrobianos (como alcoholes, ésteres o citratos) que inhiben a las bacterias y les impiden degradar el sudor, con lo que el mal olor no termina de aparecer.
Los antitranspirantes son sustancias que bloquean las secreciones de las glándulas sudoríparas, es decir, atacan a la fuente primaria que origina el sudor. Los antitranspirantes más utilizados en cosmética son las sales de aluminio. Habitualmente las sales utilizadas son el clorhidrato de aluminio en los aerosoles y roll-on, y el tetraclorohidroxiglicinato de aluminio y zirconio o el sesquiclorhidrato de aluminio en las barras y geles.
Cuando la sal de aluminio se combina con el agua, el aluminio se separa como ión aluminio (Al3+), que es muy soluble y capaz de penetrar en la piel bloqueando las glándulas sudoríparas. Así se reduce la cantidad de sudor emitido durante horas e incluso días. El tamaño de partícula de estas sales también influye en su eficacia, así como el uso de otras sustancias que sirven de vehículo para garantizar la correcta absorción del producto, como los alcoholes cetílicos.
Otra sal de aluminio de uso frecuente es el comercialmente denominado mineral de alumbre. No se trata de un mineral que encontremos fácilmente en la naturaleza, sino que es otra sal sintética de aluminio: es un sulfato doble de aluminio y potasio. Hay otras fórmulas menos habituales con sales de titanio, sales de zinc e incluso copolímeros, pero los más empleados y más eficaces son las sales de aluminio.
Los «desodorantes» tienen formulaciones que combinan sustancias antitranspirantes, sustancias desodorantes, emulsionantes, emolientes y antioxidantes. Algunos también cuentan con sustancias adsorbentes y absorbentes como talco, perlita, zeolitas, arcillas, óxidos metálicos, etc que reducen la humedad.
Los desodorantes sin aluminio se basan en formulaciones cuyos principales principios activos son los agentes antibacterianos, perfumes, aceites esenciales e inhibidores enzimáticos. Algunos cuentan con sustancias parcialmente antitranspirantes, como el gluconato de zinc, fenolsulfonato de zinc, o el sulfato de 8-hidroxiquinoleína, cuya eficacia es muy limitada.
-
Conclusión
Hace más de 18 años que se extendió el rumor de que los desodorantes con aluminio estaban relacionados con el cáncer de mama. La explicación que se daba, aunque no hubiese ninguna evidencia científica que la apoyase, tenía apariencia de verdad. Tanto es así que el miedo al aluminio empleado en estos cosméticos sigue ahí hoy en día.
Todos los estudios científicos publicados sobre si el aluminio es un potencial cancerígeno han llegado a la conclusión de que no existe tal relación o de que no son concluyentes, es decir, no se ha encontrado ninguna prueba que relacione el uso de desodorantes con una mayor incidencia de cáncer de mama. Todos los organismos oficiales están de acuerdo con esto, así que no hay nada que temer. Los desodorantes con aluminio son seguros. Y no solo eso, son los desodorantes más efectivos del mercado.
Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo Los desodorantes con aluminio no causan cáncer se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La batalla contra el cáncer: la importancia de la alimentación
- #Naukas14 Mitos del cáncer
- Método para evaluar la activación de proteínas marcadoras en cáncer
‘Imago mundi’ 2, otros 6 retratos del mundo
Mi anterior entrada de la sección Matemoción del Cuaderno de Cultura Científica, titulada Imago mundi, 7 retratos del mundo, estaba dedicada a mostrar diferentes retratos del mundo, en concreto, 7 mapas diferentes del planeta Tierra. Bueno, en realidad, mostrábamos 7 formas diferentes de realizar mapamundis, a través de 7 proyecciones cartográficas (matemáticas) diferentes: la proyección cilíndrica conforme de Mercator, la proyección pseudo-cilíndrica isoareal de Mollweide, la proyección pseudo-cilíndrica isoareal de Eckert IV, la proyección isoareal interrumpida homolosena de Goode, la proyección convencional de Van der Grinten, la proyección central, que preserva los caminos más cortos, y la proyección estereográfica, que es conforme.

“Mapa de la Tierra n. 5 con la proyección de Mercator”, perteneciente a la publicación “Sohr-Berghaus Hand-Atlas uber alle Theile der Erde” –Atlas de mano de Sohr-Bergaus de todas las partes de la Tierra-, Carl Flemming, 1888. Imagen de [4]
A la hora de realizar un mapa, la proyección cartográfica es la herramienta matemática que nos permite transformar la superficie terrestre, de forma esférica (geoide), en una superficie plana, aunque en el diseño del mapamundi intervienen muchos otros elementos, científicos, técnicos, artísticos, socio-políticos, etc. Por ejemplo, el mapa anterior, realizado con la proyección cilíndrica conforme de Mercator, está centrado en el meridiano de Greenwich, sin embargo, el siguiente mapa que mostramos está realizado con la misma proyección cartográfica, pero está centrado en el océano Pacífico, dejando Asia y Oceanía a la izquierda de la línea central y a América a la derecha.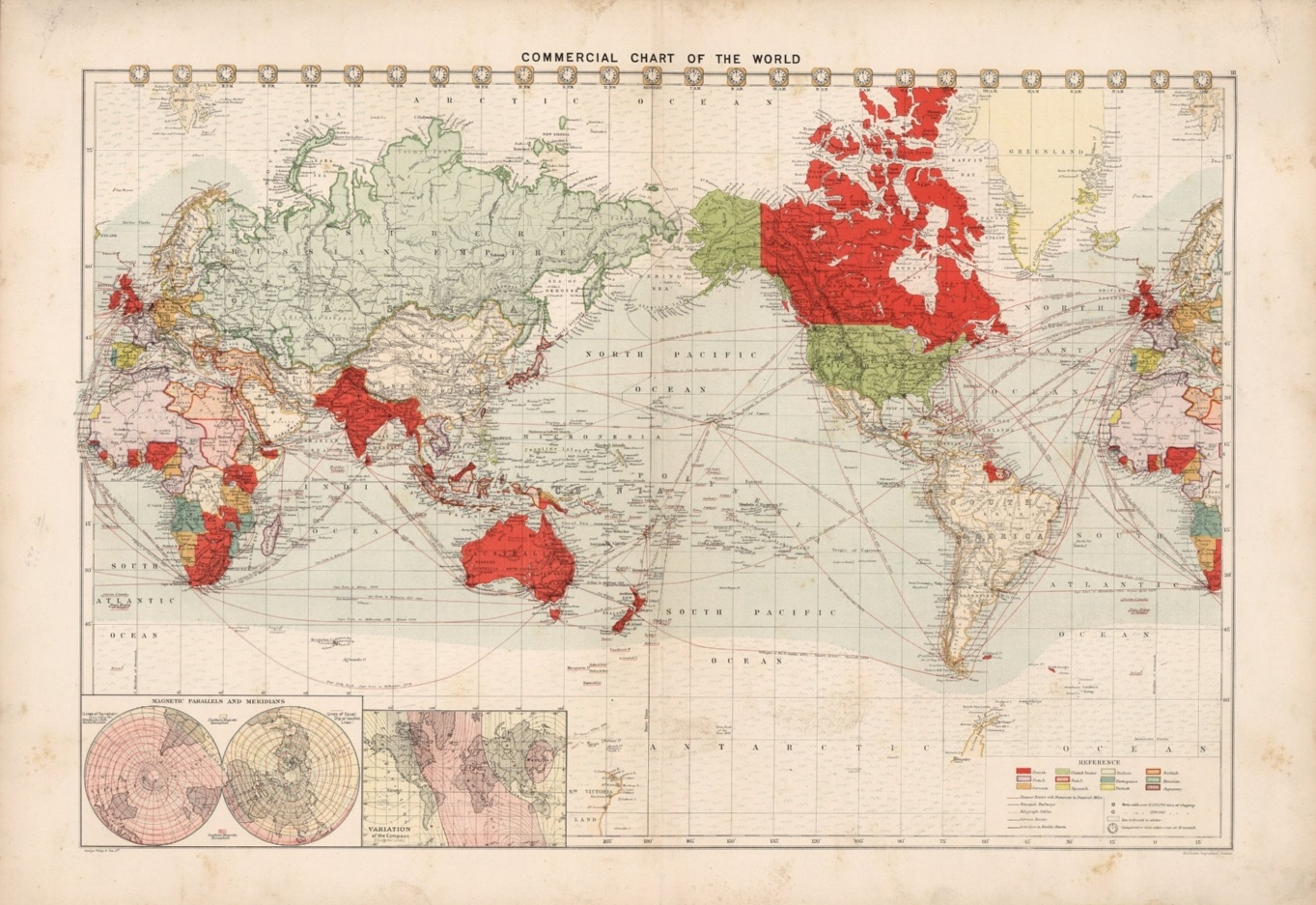
“Mapa comercial del mundo”, realizado con la proyección de Mercator, perteneciente a la publicación “Philips’ Mercantile Marine Atlas”, George Phillips and Sons, The London Geographical Institute, 1905. Imagen de [4]
Por otra parte, el primero de los “mapas con el sur arriba” modernos fue el diseñado en 1979 por el australiano Stuart McArthur, cansado de las continuas bromas sobre “down under” (que podemos traducir como “abajo del todo”), que era una forma coloquial de referirse a Australia y Nueva Zelanda. Es el mapa conocido como Mapa Correctivo Universal de McArthur, y aunque su gran aportación es situar el sur arriba, también está realizado con la proyección de Mercator. Por lo tanto, aunque solemos hablar del mapa de Mercator, esto es ambiguo y más bien deberíamos de hablar de mapas realizados con la proyección de Mercator.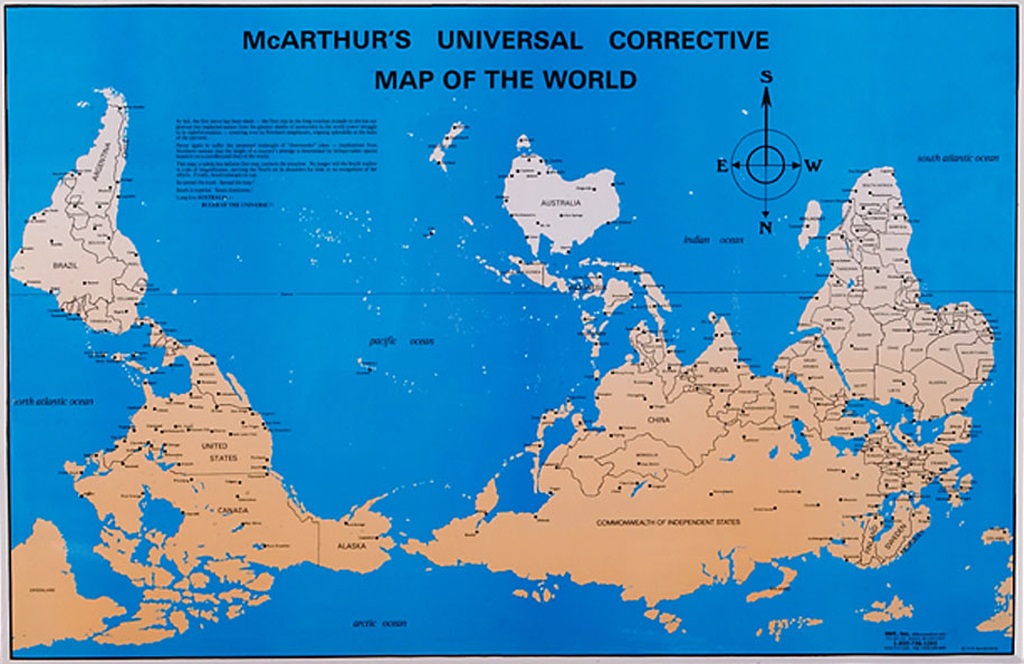
“Mapa Correctivo Universal de McArthur” (1979). Imagen de [4]
Pero, continuemos mostrando diferentes retratos del mundo, realizados con nuevas proyecciones.Retrato 1: la proyección rectangular o carta plana
La proyección rectangular, también llamada equirectangular o carta plana, es la proyección cartográfica más sencilla, desde el punto de vista matemático, puesto que son la latitud y la longitud directamente las coordenadas cartesianas del plano. En esta proyección los meridianos y paralelos están igualmente espaciados, de manera que forman una red cuadrada.
Mapa de la imagen de la Tierra visible obtenida por el Earth Observatory de la NASA, realizado con la proyección equirectangular, en el que se muestra la red cuadrada de meridianos y paralelos. Imagen de la NASA
Esta proyección suele atribuirse al sabio griego Eratóstenes de Cirene (276-194 a.n.e.), aunque el astrónomo y matemático romano Claudio Ptolomeo (aprox. 90-170) cita al geógrafo fenicio Marino de Tiro (aprox. 60-130) como su inventor hacia el año 100. A partir de entonces fue ampliamente utilizada, en particular, para la navegación, debido a la sencillez de construcción. Suele utilizarse mucho para mapamundis sencillos. La USGS y otras agencias suelen utilizarlo para mapas índice, es decir, aquellos en los que se situan esquemáticamente los diferentes mapas incluidos en una serie o atlas, y en los que se indica la página o referencia de localización.

Mapa de los cráteres de la Tierra del Earth Impact Database, en noviembre de 2017, realizado con la proyección equirectangular
Se ha convertido en standard para programas informáticos para procesar mapas globales, por la correspondencia entre pixeles y su situación geográfica, como Celestia.
Retrato 2: la proyección cilíndrica de Miller
Esta proyección cartográfica fue diseñada por el cartógrafo escocés-americano Osborn Maitland Miller (1897-1979) en 1942, con el objetivo de crear un mapa que mantuviese la imagen del conocido mapa de Mercator, de sus familiares formas, pero sin tanta distorsión hacia los polos. En la proyección equirectangular, los paralelos están igualmente espaciados, mientras que en la proyección de Mercator, se van separando cada vez más, según vamos acercándonos a los polos, cerca de los cuales la separación es muy grande, y también la distorsión. Lo que hizo Miller fue comprimir la proyección de Mercator, en la dirección norte-sur, juntando más los paralelos, y por lo tanto, con menos distorsión en los polos.
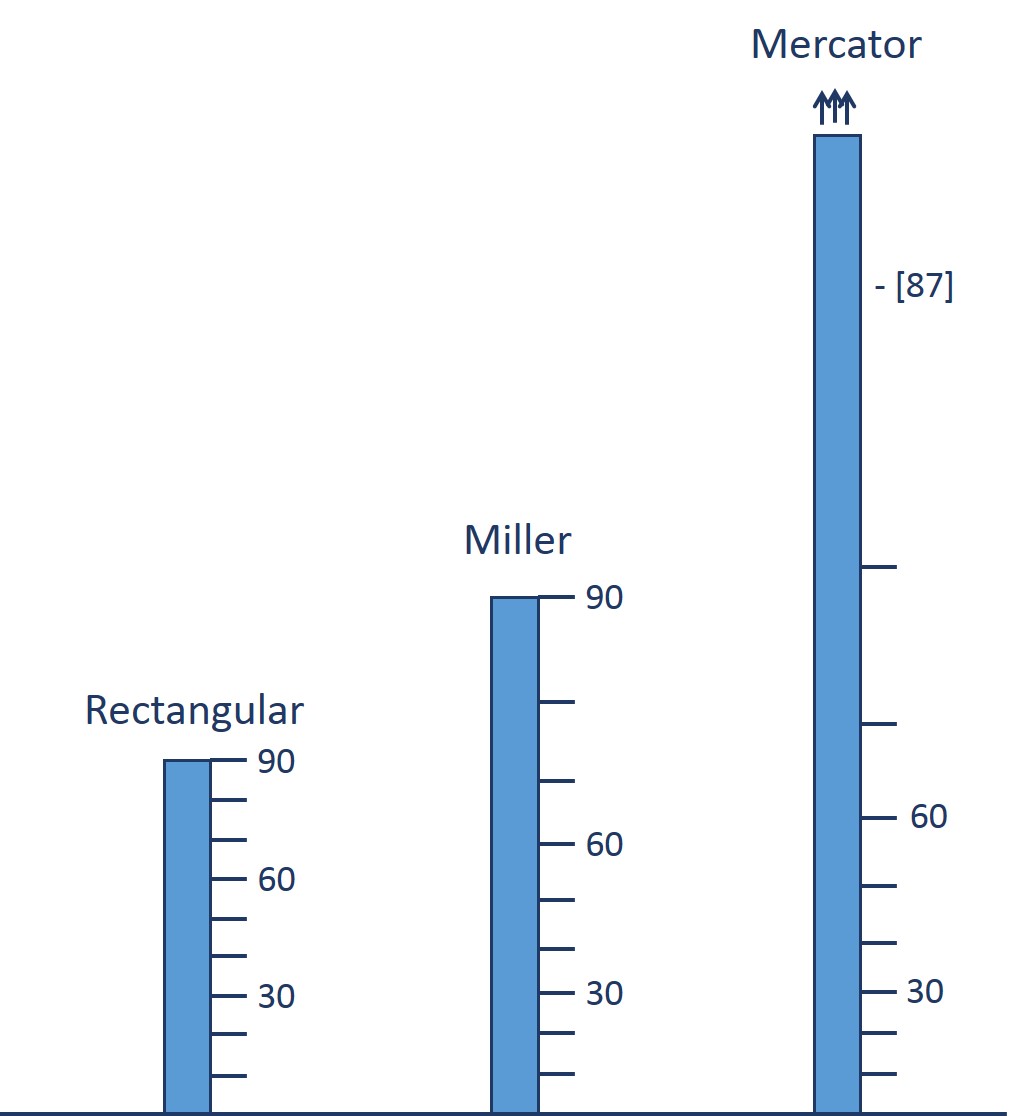
Esquema de la separación de los paralelos, marcados cada 10º en la dirección norte desde el ecuador, de las proyecciones cilíndricas rectangular, de Miller y de Mercator. La proyección de Mercator cerca de los polos se distorsiona mucho, con una gran separación entre los paralelos, como se observa en la imagen
“Rutas de Navegación n. 24”, de la publicación “Atlas of World Maps for the Study of Geography in the Army Specialized Training Program. Army Services Forces Manual”, United States Army Service Forces, 1943. Imagen de [4]
Esta proyección cilíndrica no preserva ninguna propiedad métrica, ni ángulos, ni áreas, ni geodésicas (los caminos más cortos). Esta es una proyección bastante utilizada. El mapa del mundo Esso (imagen de abajo) fue la primera vez, 1942, en la que se utilizó esta proyección, despues el gobierno de EE.UU. empezó utilizarla, en 1943, en el Servicio de Mapas del Ejercito (mapa de arriba) y en la U.S. Geological Survey, y siguió utilizándose para mapas en atlas comerciales.
Mapa del mundo de la empresa petrolera estadounidense ESSO, “Your Esso Reporter World News Map” (1958), realizado con la proyección cilíndrica de Miller. Imagen de [4]
La escala que aparece en el anterior mapa es 1:45.000.000, es decir, cada centrímetro en el mapa se corresponde con 45.000.000 centímetros, 450 kilometros, en la esfera terrestre. Aunque, como ya comentamos en la anterior entrada, no existen mapas correctos de la superficie terrestre, luego la escala de los mapas es mentira, solo es un valor aproximado.Retrato 3: la proyección de Gall-Peters
El conocido como mapa de Peters es una de las historias de polémica y manipulación relacionadas con la cartografía.
Mapa de Peters
Pero primero expliquemos en qué consiste la proyección de Gall-Peters, para la mayoría conocida solo como la proyección de Peters, y la familia de proyecciones cilíndricas a la que pertenece.
La familia de proyecciones cilíndricas (recordemos que eso significa que la esfera terrestre básica, es decir, el globo terrestre reducido primero a la escala que va a tener el mapa, se proyecta sobre un cilindro) isoareales (que preserva las áreas, salvo el factor de escala) a las que pertenece esta proyección tiene como punto de partida la proyección de Arquímedes o proyección cilíndrica isoareal de Lambert. Se proyecta la esfera terrestre básica, desde el eje de la misma, sobre el cilindro tagente a la esfera en el ecuador (como se muestra en la imagen), y después se despliega el cilindro, cortando por una de sus rectas generadoras, para obtener el mapa plano.
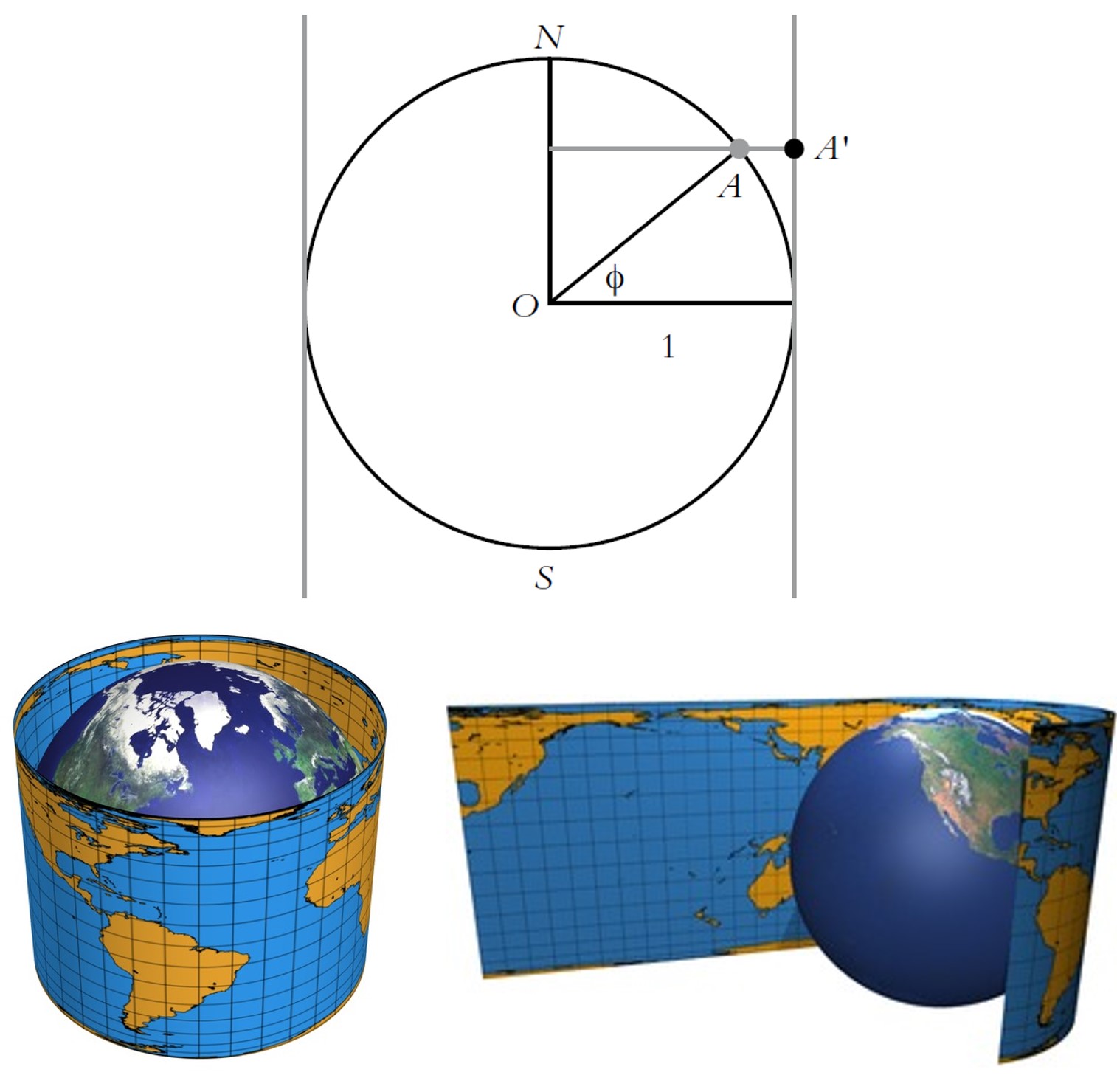
Proyección de Arquímedes o cilíndrica isoareal de Lambert. Imagen de [6]
El mapa que se obtiene mediante dicha proyección es el mapa cilíndrico isoareal de Lambert, diseñado en 1772 por el matemático alemán Johann Heinrich Lambert (1728-1777), quien también demostró la irracionalidad del número π.
Mapa de la imagen de la Tierra, realizado con la proyección cilindrica isoareal de Lambert, con imágenes del Earth Observatory “Blue Marble” de la NASA. Imagen de Wikimedia Commons
Se puede motificar esta proyección tomando, en lugar del cilindro tangente a la esfera terrestre básica, un cilindro secante a la misma (como en la imagen siguiente), es decir, que la interseca en un par de paralelos, equidistantes del ecuador.
Proyección cilíndrica, desde el eje de la esfera terrestre básica, sobre un cilindro secante. Imagen de [6]
Dependiendo de los paralelos en los que se intersecan la esfera terrestre básica y el cilindro se obtienen diferentes proyecciones cilíndricas isoareales. El clérigo escocés James Gall (1808-1895) diseñó, en 1855, el mapa para el paralelo de 45º, es decir, los paralelos 45º N y 45º S, aunque en 1967 la presentaría historiador alemán Arno Peters (1917-2002) como una proyección original suya. En 1910 el geógrafo alemán Walter Behrmann (1882-1955) diseñó el mapa para el paralelo de 30º, el arquitecto y cartógrafo aficionado Trystan Edwards (1884-1973) diseñó dos mapas para los paralelos 37,2º y 52º en 1953, o en el conocido mapa de Hobo-Dyer se utilizó, en 2002, el paralelo 37,3º para diseñar un mapa que se haría famoso por ser utilizado en un “mapa con el sur arriba”, y existen más.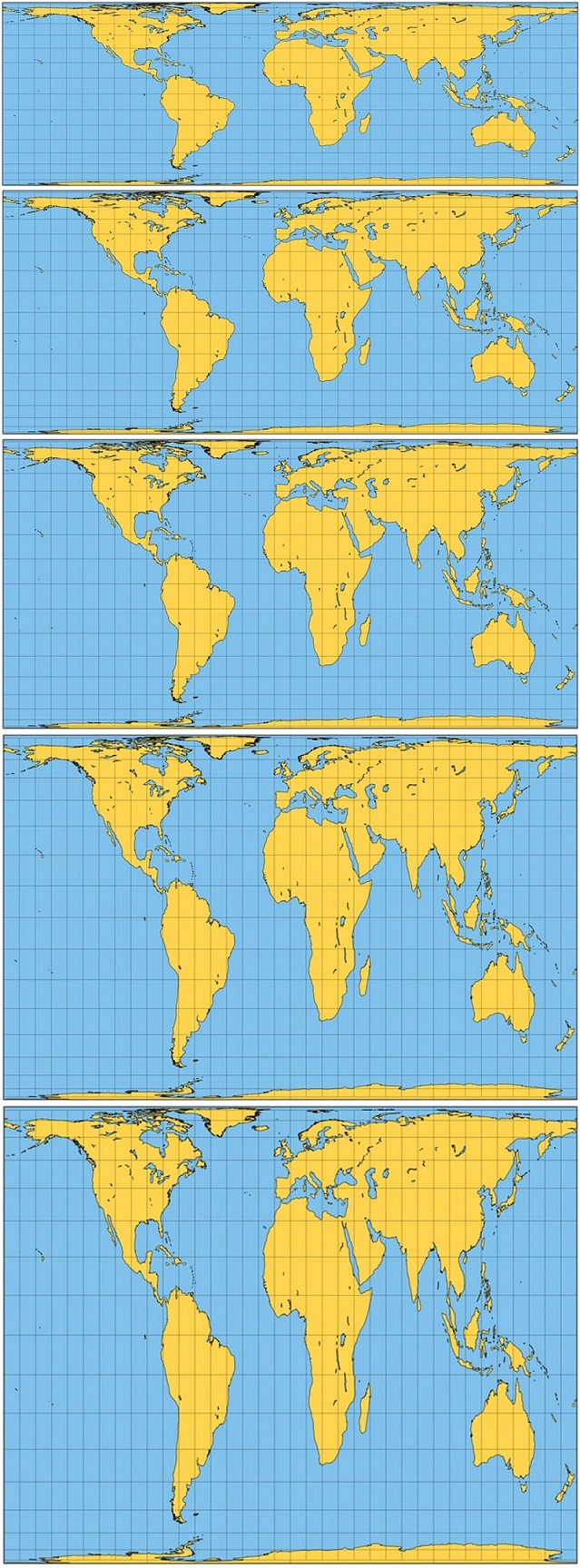
Mapas diseñados con las proyecciones cilindricas isoareales con paralelos de intersección a 0º (Lambert), 30º (Behrmann), 37,2º (Trystan Edwards), 45º (Gall-Peters) y 52º (Trystan Edwards)
El historiador alemán Arno Peters presentó al mundo de la cartografía la proyección que lleva su nombre en 1967, en un congreso en la Academia de Ciencias de Hungría, pero el mundo científico no le hizo mucho caso, puesto que esa era una proyección ya conocida, había sido creada un siglo antes por el reverendo Gall. Sin embargo, en 1973 Arno Peters convocó a la prensa en Bonn y les presentó “su” mapamundi como la única alternativa posible, tanto desde el punto de vista de la justicia social como cartográfico, al mapa “racista” e inadecuado de Mercator. El argumento principal era que la proyección de Mercator distorsiona el área de las diferentes partes del mundo, mostrando las naciones del llamado “tercer mundo” (África, y centro y sur de América) pequeñas en comparación con las del llamado “primer mundo” (Norteamérica, Europa y Rusia). Tras su ataque al mapa de Mercator, mostró “su” mapamundi como la única alternativa posible.
Se originó un debate en el que, sin criterios científicos, los medios de comunicación y algunas organizaciones con preocupaciones humanitarias y religiosas defendieron y avalaron el mapa de Peters. Se pudieron escuchar expresiones como “la proyección de Mercator sobrevalora al hombre blanco y distorsiona la imagen del mundo para ventaja de los colonialistas” (Peters) o “el mapa de Peters corrige los errores del de Mercator […] es más riguroso desde el punto de vista científico”.
Arno Peters se aprovechó de la buena fe de las personas y de su solidaridad, así como de su desconocimiento de las mínimas nociones de la ciencia de la cartografía, para que reconocieran y apoyaran “su” mapa como el “único mapa solidario”, y lo que es peor, desde el punto de vista matemático y cartográfico, como “el único mapa correcto”.
Como sabemos, no existe ningún mapa correcto, ni el de Mercator, ni el de Peters, ni ningún otro. Cada proyección tiene sus propias propiedades positivas y negativas. La proyección de Mercator preserva los ángulos, los rumbos, y en su mapa las rectas representan los caminos de rumbo constante, tan útiles para la navegación (véase esta proyección en la entrada Imago mundi, 7 retratos del mundo), pero no preserva áreas, ni formas, ni caminos más cortos, y obviamente tampoco distancias. Por su parte, la proyección de Gall-Peters es efectivamente isoareal, preserva las áreas, pero no preserva ni ángulos, ni caminos más cortos, ni distancias y distorsiona bastante las formas (África y América del Sur están estiradas y Rusia, Canadá y Groenlandia comprimidas). Por otra parte, existen cientos de proyecciones, con los correspondientes mapas diseñados a partir de ellas, distintas, y muchas de ellas preservan las áreas, no solo la proyección de Gall-Peters, como toda la familia de proyecciones cilíndricas isoareales a la que pertenece o las proyecciones de Mollweide, Eckert IV o homolosena de Goode, que aparecen en la entrada Imago mundi, 7 retratos del mundo, y muchas más.
Retrato 4: la proyección de Robinson
Como ya comentamos en la entrada anterior de esta serie Imago mundi, el mapamundi de Mercator produce una fuerte distorsión cerca de los polos, en particular, en las áreas, lo que la hace inadecuada para mapas generales del mundo, mapas para la divulgación científica, la educación y los medios de comunicación. A pesar de ello, este mapamundi se sobre utilizó durante mucho tiempo. Sin embargo, a lo largo del siglo XX se fueron diseñando muchos mapas del mundo con otras proyecciones cartográficas más adecuadas e incluso se inventaban nuevas proyecciones con el objetivo de diseñar mapamundis generales más convenientes. En la entrada anterior mostramos algunos de esos ejemplos. Las siguientes proyecciones, de Robinson y de Winkel Tripel, son otros dos ejemplos.
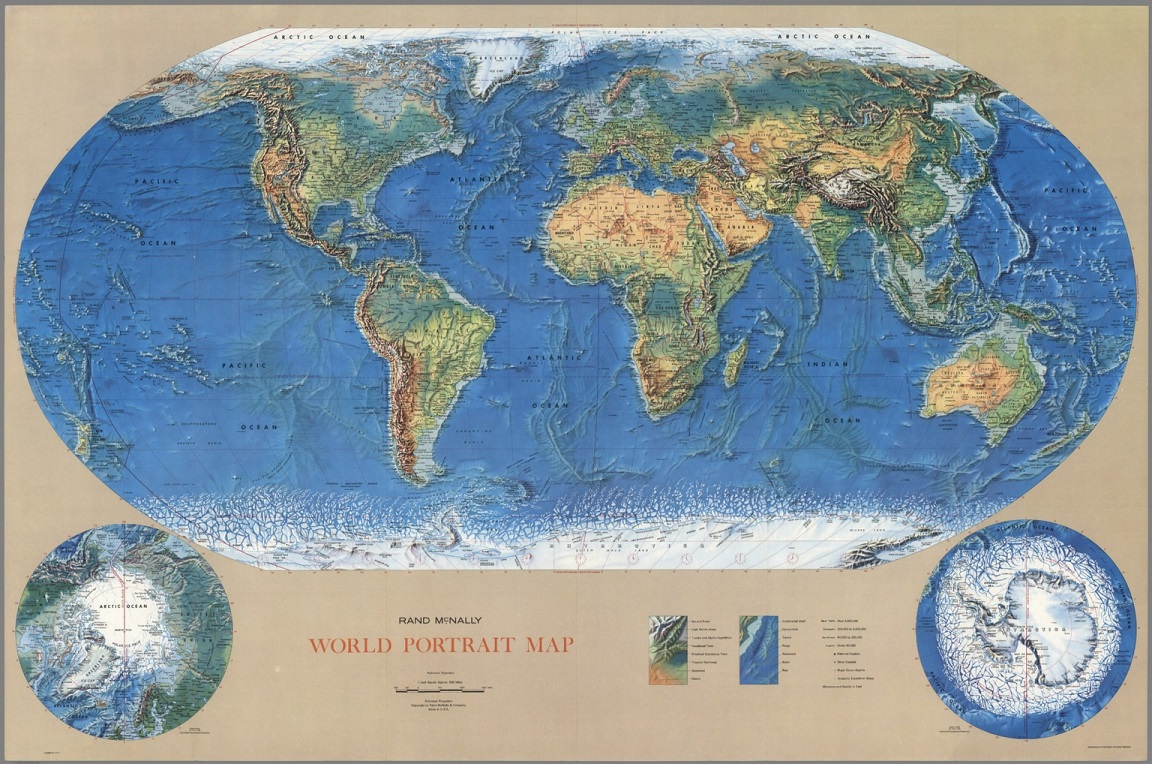
Mapa del mundo de Rand McNally, realizado con la proyección de Robinson, publicado por la compañía Rand McNally en 1975
Rand McNally es una compañía norteamericana decicada a la tecnología y a la edición, famosa por sus publicaciones de atlas del mundo. La compañía estaba descontenta con las proyecciones cartográficas utilizadas para los mapas que representaban a todo el planeta, por lo que en 1961, solicitó al geógrafo y cartógrafo estadounidense Arthur H. Robinson (1915-2004), una proyección adecuada para el diseño del mapamundi, para lo que le pusieron una serie de condiciones, como que no fuera un mapa interrumpido, con la mínima deformación general posible, que no distorsionase mucho las áreas de los grandes continentes, con una red sencilla de meridianos y paralelos, y que fuese un mapa fácil de utilizar para cualquier edad. En 1974 el cartógrafo estadounidense publicó la nueva proyección psedo-cilíndrica que hoy se conoce como proyección de Robinson.
Mapa del mundo diseñado con la proyección de Robinson por “Global Mapping”, que recibió el premio al mejor mapa impreso de la Bristish Cartographic Society – BGS en 2013
La National Geographic Society empezó a utilizar la proyección de Robinson para sus mapas del mundo entero en 1988, reeemplazando la proyección de Van der Gritten que había sido utilizada desde 1922, y fue reemplazada en 1998 por la proyección de Winkel tripel. Y fue utilizada también por muchas otras agencias.
Retrato 5: la proyección de Winkel tripel
Como acabamos de mencionar la National Geographic Society, que es un referente internacional, empezó a utilizar en 1998 la proyección de Winkel tripel para sus mapas generales del mundo.
Esta proyección es una de las tres creadas por el cartógrafo alemán Oswald Winkel (1874-1953) en 1921, como una media aritmética de otras dos proyecciones ya conocidas. En el caso de la proyección de Winkel tripel de la proyección rectangular (véase más arriba) y la proyeccion de Aitoff, una proyección creada a partir de la proyección azimutal equidistante (véase más abajo) propuesta por el cartógrafo y revolucionario ruso David A. Aitoff (1854-1933) en 1889.
Mapa físico político del mundo del IGN – Instituto Geológico Nacional de Argentina, realizado con la proyección de Aitoff. Edición de 2011. Tiene dos versiones, con el norte o el sur arriba
El nombre de “tripel” alude a la propiedad de la proyección de minimizar la distorsión de las tres propiedades métricas: área, ángulos y distancias.
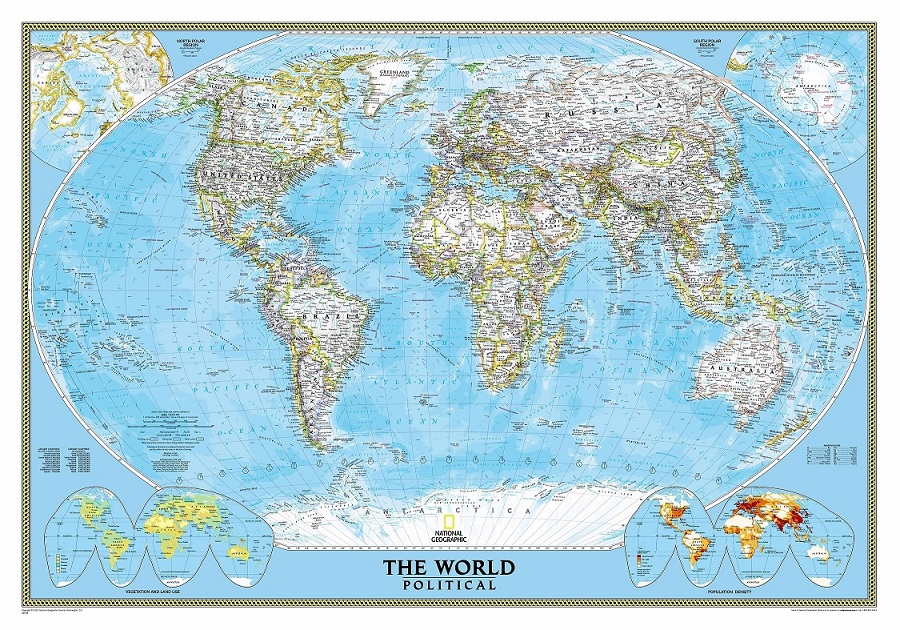
Mapa mural del mundo de “National Geographic”, realizado con la proyección de Winkel tripel, y que contiene, en pequeño, dos mapamundis realizados con la proyección homolosena de Goode. Edición de 2012
Después de que la National Geographic Society adoptase la proyección de Winkel tripel para sus mapas del mundo, muchas agencias, compañías y entidades educativas la utilizaron también para sus mapamundis. Aunque ya antes había sido utilizada también. Fue utilizada por primera vez para el Times Atlas of the World, editado por John Bartholomew & Sons, en 1955.
Mapa del mundo sobre la vegetación, realizado con la proyección de Winkel tripel, perteneciente al “Times Atlas of the World”, editado por John Bartholomew & Sons, edición de 1959. Imagen de [4]
Retrato 6: la proyección acimutal equidistanteAl igual que las proyecciones gnomónica y estereográfica que presentamos en la anterior entrada, Imago mundi, 7 retratos del mundo, esta es una proyección acimutal, es decir, que se proyecta directamente sobre la esfera, sin pasar por una superficie auxiliar como el cilindro o el cono, aunque esta proyección, a diferencia de las otras, no es geométrica, no se deriva de una proyección a través de “rayos”. También es una proyección clásica, que ya debían utilizar los egipcios para los mapas celestes y que fue descrita por primera vez por el matemático iraní Al-Buruni (973-1050). La primera vez que se utilizó para elaborar mapas terrestres fue en el siglo XVI.
Mapa polar del mundo de Rand McNally, realizado con la proyección acimutal equidistante centrada en el polo norte. Edición de 1943. Imagen de [4]
Al igual que otras proyecciones acimutales, satisface que las geodésicas, los círculos máximos de la esfera, que pasan por el punto central de referencia se transforman en rectas del plano que pasan por el centro del mapa. La propiedad particular de esta proyección es que la escala es constante a lo largo de dichas rectas, es decir, se preservan las distancias desde el centro del mapa.
Puede utilizarse para representar la totalidad de la superficie terrestre en un mapa plano, aunque la distorsión es muy fuerte al superar el semicírculo que está a la mitad de la distancia del centro. En la versión polar del mapa, que es la que aparece en la imagen anterior o en el mapa de la Organización de Naciones Unidas, los meridianos son las rectas radiales que emanan del centro, el polo, y los paralelos son circunferencias concéntricas igualmente espaciadas.

Bandera de la ONU, Organización de Naciones Unidas, con el mapa del mundo realizado con la proyección acimutal equidistante centrada en el polo norte
Es una proyección ampliamente utilizada, en muchas ocasiones para representar las zonas polares como acompañante de los mapamundis diseñados con otras proyecciones, pero también para mapas de un solo hemisferio. Se suele llamar también “mapa egocéntrico” ya que posee un punto central, que se convierte en el mapa del mundo, y desde el que se preservan las distancias.
“Mapa del mundo de la Era de la Navegación Aérea”, realizado con la proyección acimutal equidistante centrada en Washington, EE. UU., perteneciente a la publicación “Hammond’s New World Atlas”, 1948. Imagen de [4]
Aunque estamos hablando en estas entradas de mapas del mundo, las proyecciones se utilizan para mapas de regiones más pequeñas, así esta proyección se utiliza para mapas centrados en un lugar concreto desde donde se quiere conocer los puntos que están a unas ciertas distancias, que como esta proyección preserva las distancias desde el centro se representan como circunferencias.
Mapa acimutal equidistante centrado en Kabul, Afganistán, en el que se muestran las circunferencias de los lugares que están a una misma distancia. Imagen de la Library of Congress
No hemos tenido tiempo de hablar de algunas proyecciones cónicas, de las proyecciones acimutales ortográfica y de perspectiva, de la proyección de armadillo, o de algunas proyecciones singulares, a las cuales dedicaremos la tercera y última entrega de esta serie del Cuaderno de Cultura Científica, Imago Mundi.
Para terminar, la instalación World Map (2013) del artista sudafricano, aunque afincado en Londres, Clinton de Menezes, que desgraciadamente fue asesinado en la nochevieja de 2013 en su país natal.

Instalación “World Map” (2013), de Clinton de Menezes. Imagen del blog de Clinton de Menezes

Detalles de la instalación “World Map” (2013), de Clinton de Menezes. Imágenes de My Modern Met
Bibliografía
1.- Raúl Ibáñez, El sueño del mapa perfecto; cartografía y matemáticas, RBA, 2010.
2.- Raúl Ibáñez, Muerte de un cartógrafo, Un paseo por la Geometría, UPV/EHU, 2002. Versión online en la sección textos-on-line de divulgamat
3.- Timothy G. Feeman, Portraits of the Earth; A Mathematician looks at Maps, AMS, 2002.
4.- David Rumsey Map Collection
5.- J. P. Snyder, Flattening the Earth, Two Thousand Years of Map Projections, The University of Chicago Press, 1993.
6.- Carlos Furuti, Map projections
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo ‘Imago mundi’ 2, otros 6 retratos del mundo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- ‘Imago mundi’, 7 retratos del mundo
- El teorema de los cuatro colores (2): el error de Kempe y la clave de la prueba
- La geometría de la obsesión
Cristalografía (11): Asimetrías y juegos de luz

A última hora de una tarde de 1808 un veterano de la Expedición a Egipto se entretenía paseando por los jardines de Luxemburgo, que desde 1791 eran, como el palacio del mismo nombre, “propiedad nacional”. Llevaba en el bolsillo un cristal de espato de Islandia con el que se entretenía de vez en cuando observando objetos a su través. En un momento dado, ocurrió algo curioso: mientras observaba la luz reflejada en los cristales del palacio se dio cuenta de que, en vez de ver dos imágenes igualmente brillantes, aparecía una mucho más brillante que la otra. Como después diría Pasteur, la suerte favorece a la mente preparada; Étienne-Louis Malus dedujo que el efecto tenía que estar relacionado con el hecho de que la luz fuese reflejada. La luz, concluyó, se polarizaba al reflejarse.

Malus publicó su descubrimiento en 1809. En 1810 publicaría la teoría de la doble refracción de la luz en los cristales e ingresaría en la Académie des Sciences de París. Poco después inventaría los primeros filtros polarizadores y polariscopios. Ambos se basaban en la reflexión de un haz de luz no polarizada en un ángulo determinado, hoy llamado ángulo de Brewster.
Hacer experimentos con luz polarizada se convirtió en la moda científica del momento y, como era de esperar, empezaron a hacerse nuevos descubrimientos muy pronto. Así, por ejemplo, los de un jovencísimo astrónomo del Observatorio de París y miembro de la Academia y del consejo de la École Polytechnique desde los 23 años, François-Jean-Dominique Arago (científico y hombre excepcional con amplios intereses políticos, llegó a ser de facto, durante mes y medio, jefe del estado francés). Arago fue el primero en observar el cambio de color cuando un haz de luz polarizada pasaba a través de un cristal de cuarzo (1811).

Compañero de aventuras y correrías del joven Arago, Jean-Baptiste Biot observó la rotación óptica (hoy diríamos actividad óptica) de los cristales de cuarzo (1812) y de algunas sustancias orgánicas: el aceite de trementina, los extractos cítricos, el extracto de laurel, las disoluciones de alcanfor, el azúcar (1815). Biot observó además que los compuestos orgánicos retenían su actividad óptica independientemente de su estado de agregación, esto es, el azúcar es dextrorrotatoria (gira el plano de polarización a la derecha desde el punto de vista del observador) tanto esté en forma cristalina como en disolución. El cuarzo fundido, sin embargo, es ópticamente inactivo. Biot llegó a la conclusión de que la rotación óptica de los compuestos orgánicos es una propiedad molecular, mientras que la rotación óptica del cuarzo es una propiedad del cristal, el resultado de cómo se empaquetan las “moléculas”.
Pero Biot fue más allá. Afirmó que la causa de la actividad óptica era la asimetría . Por tanto, las moléculas orgánicas serían asimétricas, mientras que los cristales de cuarzo serían ordenamientos asimétricos de moléculas simétricas. En lenguaje actual las moléculas asimétricas en el sentido de Biot se denominan quirales, y las simétricas, aquirales. Por otra parte hoy sabemos que no existen moléculas de cuarzo (SiO2) ni en los cristales ni en el fundido, por lo que algo que no existe no puede ser quiral.
Pocos años más tarde John William Herschel describió la existencia de caras hemiédricas en los cristales de cuarzo, es decir, cristales en los que sólo aparecen la mitad de las caras para la máxima simetría (holoedría) que permite el sistema cristalino. Herschel descubrió que existen dos tipos de cristales hemiédricos, los que sólo tienen caras hemiédricas zurdas y los que sólo tienen caras hemiédricas diestras, y que son imagen especulares unos de otros (en la imagen cristales hemiédricos de tartrato de sodio y amonio).
Herschel dio también el siguiente paso al correlacionar la rotación óptica con la hemiedría: los cristales zurdos eran levorrotatorios (giraban el plano de la luz polarizada a la izquierda) y los diestros, dextrógiros. Esto supuso la primera confirmación independiente de la relación estructura-actividad propuesta por Biot.
En 1828 William Nicol inventaba el prisma de su nombre, un dispositivo que consistía en un monocristal de espato de Islandia cortado diagonalmente y vuelto a unir con una capa intermedia de bálsamo del Canadá, un adhesivo transparente, que hacía uso de sus propiedades birrefringentes. El prisma de Nicol es un polarizador compacto y robusto que, desde 1830, contribuyó sobremanera al uso rutinario de la polarimetría en la investigación óptica y cristalográfica.
Podríamos incluso afirmar que el prisma de Nicol simboliza el nacimiento de una nueva rama del conocimiento, la óptica cristalina, cuyos pioneros fueron Arago, Biot y David Brewster en la primera mitad del siglo XIX. La observación de cristales con luz polarizada ofreció el primer vistazo a la estructura interna de los cristales, y fue el único método capaz de hacer esto hasta la aparición de la difracción de rayos X, ya comenzado el siglo XX.
Referencias generales sobre historia de la cristalografía:
[1] Wikipedia (enlazada en el texto)
[3] Molčanov K. & Stilinović V. (2013). Chemical Crystallography before X-ray Diffraction., Angewandte Chemie (International ed. in English), PMID: 24065378
[4] Lalena J.N. (2006). From quartz to quasicrystals: probing nature’s geometric patterns in crystalline substances, Crystallography Reviews, 12 (2) 125-180. DOI:10.1080/08893110600838528
[5] Kubbinga H. (2012). Crystallography from Haüy to Laue: controversies on the molecular and atomistic nature of solids, Zeitschrift für Kristallographie, 227 (1) 1-26. DOI: 10.1524/zkri.2012.1459
[6] Schwarzenbach D. (2012). The success story of crystallography, Zeitschrift für Kristallographie, 227 (1) 52-62. DOI: 10.1524/zkri.2012.1453
Este texto es una revisión del publicado en Experientia docet el 23 de enero de 2014
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Cristalografía (11): Asimetrías y juegos de luz se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Cristalografía (3): Goniómetros y óxidos dulces
- Cristalografía (1): Protociencia, del “Homo erectus” a Linneo
- Cristalografía (4): Átomos y balas de cañón.
Una última oportunidad para Opportunity

El rover Opportunity, gemelo del Spirit, diseñados para ejercer de geólogos robóticos sobre la superficie de Marte. Foto: NASA
De todos los robots o rovers activos que la NASA tiene recorriendo la superficie de Marte a día de hoy, Curiosity es la estrella. Nos manda selfies y tuitea y tiene un innegable parecido con Wall-E, el adorable robot protagonista de la película de Pixar que se afanaba en limpiar una Tierra que el ser humano había abandonado ya por exceso de contaminación y porquería.
Pero eso es un poco injusto porque si hay uno de esos cacharros que merezca toda nuestra admiración, ese es Opportunity, ya que ha superado de larguísimo las expectativas que su equipo de ingenieros tenía sobre su resistencia, utilizad y perseverancia. Ahora, Opportunity no pasa por su mejor momento. Lleva apagado y en silencio desde junio, cuando una intensa tormenta de arena marciana le obligó a entrar en hibernación. Desde entonces sus baterías se han ido descargando. La NASA ha decidido esperar a que la tormenta afloje y entonces darle al robot un plazo de 45 días para que se recargue y vuelva a enviar señales de vida. Si eso no ocurre, Opportunity se dará por perdido, aunque se seguirá escuchando periódicamente en su dirección hasta finales del mes de enero a la espera de nuevas señales.

Los paneles solares que alimentan a Opportunity. Foto: NASA
Si este termina siendo el final de Opportunity, nadie podrá decir que el robot no ha sido un superviviente. Retrocedamos un poco, hasta el 25 de enero de 2004, el día que el rover puso sus ruedas en Marte. Tres semanas antes, el 3 de enero, su gemelo, el Spirit, había hecho lo mismo en otra zona del planeta. La duración estimada de su misión era de 90 días marcianos (cada uno dura 40 minutos más que un día en la Tierra) porque los ingenieros suponían que el polvo de Marte los enterraría rápidamente, pero Spirit siguió funcionando y enviando datos durante 7 años, y Opportunity iba de camino a cumplir 15 años en activo.
La tormenta de arena que amenaza al rover
Pero la tormenta que le cayó encima este mes de junio ha sido de las más severas, y eso supone 2 problemas para el robot: por un lado, la propia arena que puede dañar sus componentes, y por otro, que impide que pase la luz del Sol de la que se alimentan sus baterías. Los científicos no pueden calcular con exactitud cuándo aminorará lo suficiente como para que la luz atraviese las nubes de polvo y vuelva a recargar de energía a Opportunity.
Y hay un tercer problema: cuando afloje la tormenta, todo ese polvo tiene que posarse en algún sitio, y lo hará sobre el robot. Su el polvo se posa sobre sus paneles solares, impedirá que estos reciban la luz del Sol igual que cuando estaba en el aire, y los ingenieros desde la Tierra no tienen modo de solucionar el problema.

Dos imágenes de la superficie de Marte, tomadas por Curiosity, que muestran los efectos de la tormenta de arena del pasado mes de Junio. Foto: NASA
Hay, aseguran un rayo de esperanza, un fenómeno que los científicos observaron por primera vez cuando los robots llegaron a Marte y que fue parcialmente responsable de que no sucumbieran a los 90 días al polvoriento destino que todos les auguraban: los ciclos periódicos de vientos que recorren la superficie marciana con suficiente fuerza como para arrastrar con ellos el polvo y así quitárselo de encima a los robots.
El equipo de la NASA calcula que estos vientos tendrán lugar desde noviembre hasta enero, y eso podría encajar con el margen de tiempo que le han dado a Opportunity para que se ponga en contacto de nuevo con la Tierra, pero solo si la tormenta se despeja en las próximas semanas, cosa que no hay forma de predecir con seguridad. Por eso algunos científicos que han trabajado en las misiones de Opportunity y Spirit consideran que los plazos anunciados por la agencia espacial no le dan al robot la oportunidad que merece, y que habría que esperar a que se despeje la tormenta para establecer la duración de los siguientes periodos de escucha.
Son robots, pero son más que eso
El caso del Spirit fue diferente, allí no cupo mucha esperanza. En abril de 2009 se quedó atascado en una posición que le hizo perder toda su energía en el invierno marciano que llegó poco después. En julio de 2010 la NASA comenzó una intensa operación de recuperación, enviando señales durante meses e intentando escuchar una respuesta.
Tras recibir apenas un susurro como respuesta, en mayo de 2011, la NASA declaraba perdido a Spirit. En aquel momento la decisión fue dura, pero existía el consuelo de haber hecho todo lo posible por recuperarlo y de que aun quedaba en pie la mitad de la misión gracias al perseverante Opportunity. El trabajo continuaría y seguirían recibiendo información.

Es difícil no sentir simpatía por Opportunity si pensamos en Spirit esforzándose por ser un buen rover para que le recojan y le traigan de vuelta a casa, en esta tira cómica de xkcd. Fuente: xkcd.com
Esto ya no es así. Si Opportunity deja de funcionar, se acabó la misión. Por eso muchos de los científicos que participan en ella están haciendo lo que está en su mano para salvar al robot, entre otras cosas, promoviendo una campaña en Twitter con la etiqueta #SaveOppy. Sin embargo, parece haber discrepancias entre los directivos de la NASA que están tomando las decisiones y los científicos de la misión, que cuentan en este artículo de Space.com que nadie les avisó del anuncio que hizo la NASA el día 30 de agosto en el que anunciaba los planes para Opportunity y que consideran que no se le está dando una oportunidad justa establecer los plazos sin esperar a que pase la tormenta.
Aquí chocan los intereses científicos con los administrativos. Cuando Spirit desapareció y el equipo pasó meses tratando de recuperarlo, lo hacían como parte de una misión que en cualquier caso seguiría adelante con Opportunity como protagonista. Pero ahora, la recuperación de Opportunity marcará la diferencia entre que la misión siga adelante o no, y si termina siendo que no, es una oportunidad para dedicar todos esos esfuerzos a otra cosa. “No voy a mantener a todo el personal en esto durante 6 u 8 meses si las probabilidades de éxito son bajas”, ha dicho John Callas, gestor del proyecto Opportunity en el JET Propulsion Laboratory de la NASA.
Así que el tiempo juega en contra el Opportunity, que vive unos meses cruciales en los que tiene que calmarse la tormenta con el tiempo suficiente para que los vientos marcianos limpien de polvo sus placas solares y así pueda enviar a la Tierra la señal que demuestre que 15 años no son nada para él, que ya ha superado con creces todas las expectativas.
Referencias:
Martian Skyes Clearing Over Opportunity Rover – Jet Propulsion Laboratory, NASA
Opportunity – Wikipedia
NASA Just Gave the Opportunity Rover a Survival Deadline on Mars—Here’s What That Means – Space.com
Mars Dust Storm: June 2018 – NASA
Un homenaje a Spirit – NASA
Sobre la autora: Rocío Pérez Benavente (@galatea128) es periodista
El artículo Una última oportunidad para Opportunity se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Las ventajas (para ti y para los demás) de ser egoísta de vez en cuando
- Asteroides, ¿de la amenza a la oportunidad?
- La verdadera composición última del universo (I): Más allá del modelo estándar
Meteoros. LLuvias. Poemas
Una estrella fugaz
para una mujer
que no sabe qué pedir.
Suzuki Masajo
Tres versos, 17 sílabas en total y un microcosmos de significado capturado en una imagen: esto es un haiku de una transgresora poeta japonesa del siglo XX. El tema es curioso [daría para mucho, siendo mujer su autora y fisgando algo de su fascinante vida personal]. Nos remite a algo verosímilmente posible si en agosto nos encontramos bajo la lluvia de Perseidas o en diciembre bajo las Gemínidas: olvidar qué deseo pedir. Entre otras cosas, porque las estrellas fugaces no están ahí para cumplir deseos de primates ni de organismos eucariotas en general, y siento que muera un unicornio cada vez que alguien lee esto. A ver si lo compenso: no cabe duda de que pedir un deseo cuando se ve una estrella fugaz es un buen ejercicio, hasta sorprendente, para descubrirnos a nosotros mismos qué deseamos. Y una vez llevamos dos o tres formulados, igual nos apetece saber más sobre cómo se originan esas «estrellas», por qué aparecen en la misma época del año, de dónde vienen, adónde van…

Perseida y Pléyades [M45]. Foto de Óscar Blanco en A Veiga. Agosto 2018
«Necesitamos imaginación en ciencia, no todo es matemáticas y lógica, también belleza y poesía». Parecen palabras contemporáneas, el eslógan de un festival de sciencepoetry; son de Maria Mitchell, la primera astrónoma oficial de EEUU, directora del Observatorio del Vassar College [Nueva York] y formadora y defensora de mujeres en ciencia. Nació hace justo 200 años, se codeó amistosamente con John Herschel, Mary Sommerville o Alexander von Humboldt e incluso se le autorizó entrar en el Observatorio del Vaticano, aunque sólo hasta que se pusiese el sol… [un mírame y no me toques para un observatorio estelar, pero allá que fue].
Años antes, en 1847, Maria había avistado un cometa no periódico –bautizado en su honor como el cometa Miss Mitchell – desde su Nantucket natal y obtuvo por ello la medalla de oro prometida por un rey con afición a la astronomía, Federico VI de Dinamarca.
Por muy presentes que sigan las palabras y el carácter de su descubridora, el cometa Miss Mitchell no es de los que vuelven. Algunos de los cometas que sí nos visitan con regularidad precisamente provocan lluvias de estrellas, en las que a veces pedir un deseo es lo de menos. Muchos cometas son escultores involuntarios de meteoros y meteoritos.
No son lo mismo, claro. Todos conforman un ovillo de polvo y roca, pero el cometa, de órbita más elongada, se parece más a una bola sucia de nieve y hielo que, al calor del Sol, desprende una estela de polvo y gas ionizado muy vistosa, verdiazul; una coma en latín [κόμη en griego], una cabellera. Y de coma, tenemos cometa. Una bola de hielo desmelenada. Partículas y pequeñas rocas desprendidas de esa cola de polvo seguirán en su órbita y se cruzarán con la nuestra. Las llamamos «lluvia de estrellas», si bien la mayoría son esquirlas del tamaño de un grano de arena que entran en incandescencia al roce con nuestra atmósfera. Esos son los meteoros y se desplazan en «tubos meteóricos»: un hula hop de polvo y detritos.
La condición que convierte un meteoro en meteorito y le otorga su sufijo es el hecho de llegar a tocar nuestro planeta. Un meteoro pasa por el cielo como un ave de paso dejando una firma luminosa –de ahí lo de estrella fugaz, aunque no tenga nada de estrella – y puede convertirse en meteorito si no se desintegra y se hunde en algún lugar de nuestra Tierra, tal vez un océano, bosque o desierto. A la espera de que alguien dé con él y lo destripe.
[Sí, también puede caer sobre nuestras cabezas, pero esa probabilidad es 1 entre 1.600.000; mucho menor que la probabilidad de que nos caiga un rayo, nos ataque un tiburón o ganemos la Lotería. Podemos seguir mirando al cielo sin mayores aprensiones].
Lo que conocemos como lluvia de estrellas, en inglés meteor shower [ducha de meteoros], es un fenómeno frecuente y periódico protagonizado por meteoros. En griego μετέωρος significa «suspendido del cielo» y en principio podía aludir a la lluvia, la nieve, el arco iris, las auroras boreales…De ahí que todos esos fenómenos dispares en origen entren en el campo de estudio de la meteorología. Todos se manifiestan una vez pasado el lienzo transparente de nuestra atmósfera.
En la llanura de Tesalia, al norte de Grecia, los monasterios de Meteora nos recuerdan la raíz de esa palabra: las montañas sobre las que se erigen suscitaron la ilusión óptica de colgar o flotar en el cielo, son inmensos pilares de roca del terciario erosionados por un gran río.
Pero retomemos el hilo de los meteoros y su relación con los cometas [y algún que otro asteroide]. Como hemos apuntado, las conocidas como lluvias de estrellas suelen ser periódicas dado que su origen se encuentra en aquellos restos de roca desprendidos de un cometa en su período orbital en torno a nuestro Sol –que, como vemos, es menos nuestro de lo que pensábamos-. Hay muchas lluvias a lo largo del año, desde las Cuadrántidas de comienzos de enero hasta las fabulosas Gemínidas de diciembre, las que cuentan con mayor tasa horaria zenital o THZ, es decir, número máximo de meteoros por hora; sin olvidar las Líridas de abril, las Oriónidas, las Boótidas o las Leónidas, entre otras.
Todas ellas se originan en los restos de polvo dejados atrás por las colas de un cometa; ese enjambre de escombros cruza el plano orbital de nuestro planeta, aunque el cometa se halle ya pasado Saturno. El entrañable Halley [1P/Halley es su título oficial], que volverá a visitarnos hacia julio del 2061, es responsable de dos lluvias de estrellas al año, las Eta Aquáridas en mayo y las Oriónidas en octubre, coincidiendo con dos puntos de corte con su órbita. Las Perseidas son, por su parte, polvareda del cometa Swift–Tuttle [de nombre técnico 109P/Swift–Tuttle]. Y las espectaculares Gemínidas de nuestro invierno boreal serían migajas de otro tipo de roca, un asteroide: (3200) Phaethon, nombre que alude a otro mito, Faetón, el hijo caído por guiar con torpeza la cuadriga del astro rey.
Este variado menú de lluvias tiene algo común: todas ellas suenan igual. Riman, de hecho. Si regresamos al griego, el sufijo –idas significa «descendencia». Perseidas serían hijas de Perseo, Dracónidas de Draco y Gemínidas de Géminis. Una filiación metafórica, desde luego. De hecho, como todo lo relativo a las constelaciones, depende sólo del punto de vista humano desde su posición en la Tierra, es decir, se trata de ilusiones ópticas y de perspectiva que comparte nuestra especie. Todos los meteoros parecen surgir de una región del cielo donde reina una constelación, de las 88 totales reconocidas por la Unión Astronómica Internacional, de la cual toman su nombre como «hijos de». Esa región se denomina radiante, ya que los meteoros en apariencia irradian de ahí. Podemos verlos rayar otro punto del firmamento; en ese caso, trazamos su línea imaginaria y desembocamos en la constelación matriz. Si no es así, se trataría de un esporádico: un meteoro que no forma parte de la lluvia de estrellas, pero al que queremos igual.
Para una observación de Perseidas la constelación en el punto de mira como referencia es Perseo, el héroe que montaba a Pegaso, siempre cerca de Casiopea y Andrómeda, sus colegas de mito. Para las Leónidas, Leo, constelación fácil de ver al hallarse en la franja imaginaria del zodíaco, la línea de los eclipses, la eclíptica [quizás la línea más importante para la observación astronómica: una extensión de la recta imaginaria que uniría Tierra y Sol y la proyecta en el fondo de estrellas]. Y el radiante de las Camelopardálidas? Y el de las Cuadrántidas? Ahí os lo dejo.

Esto es un cometa, y qué cometa: el Hale-Bopp, de 1997, visible en el cielo durante varios meses y más brillante que Sirio. Créditos de la imagen: A. Dimai and D. Ghirardo, (Col Druscie Obs.), AAC
***
«¡Ou ti! roxa estrela
que din que comigo
naciche, poideras
por sempre apagarte,
xa que non pudeche
por sempre alumarme…!»
[«¡O tú! roja estrella
que dicen que conmigo
naciste, bien podrías
por siempre apagarte,
ya que no has podido
por siempre alumbrarme…!»]
Rosalía de Castro
No sabemos a qué estrella se refiere Rosalía y si se trata de una licencia o responde a un dato biográfico rastreable hacia febrero de 1837: acaso la monstruosa Antares, el astro rojo principal de la constelación de Escorpio [Kalb Al Acrab, el corazón del alacrán, en árabe]; o el propio planeta Marte, con fulgor anaranajado y que podría interpretarse como estrella por ojos no expertos. La voz poética en este fragmento de Follas Novas no parece muy conforme con su estrella, o su destino. Pero no queda claro qué «estrella roja» es la acusada.
Si nos remontamos 4 años antes del nacimiento de la poeta gallega, en noviembre de 1833 sí hubo una espectacular lluvia de meteoros que Denison Olmsted, astrónomo de Yale, observó alertado por sus vecinos. Se fijó que todos los meteoros, más de 72.000 por hora [una THZ bárbara], parecían surgir de un mismo punto, al que bautizó radiante.
Aquella lluvia es la que hoy conocemos como Leónidas y se trataba en realidad de una tormenta de estrellas fugaces [una concentración significativamente mayor], que en el caso de las Leónidas sucede cada 33 años; más o menos el período orbital de su cometa, el Tempel-Tuttle.

Tormenta de estrellas fugaces de 1833 vista sobre las cataratas del Niágara, grabado. Portada de “Astronomy in Canada”
Este registro marcó un antes y un después en la astronomía, no sólo estadounidense: una nueva visión de esos chaparrones puntuales de bolas de fuego, ahora con los ojos de la ciencia, estaba en marcha. Otro acontecimiento llegaría poco después, hacia 1860, y ahí encontramos dos posibles testimonios artísticos: un cuadro de Frederic Church, «The Meteor of 1860», y uno de los fluviales poemas de Walt Whitman, «Año de Meteoros». Poema bastante elusivo, como un cometa, que figura en el índice original de Redobles de tambor [Drum taps, 1865], por lo visto luego añadido al mítico Hojas de Hierba [si bien la edición y traducción de Jorge Luis Borges no lo recoge].
Existe una curiosa ramificación de la ciencia de los astros: algo que, exista o no crimen, se ha llamado «astronomía forense»; quizá una denominación más acertada sería astronomía detectivesca o indagación astronómica. Mantiene a sus adeptos ante obras de arte, literatura o arquitectura en busca de indicios sobre fenómenos relativos a objetos celestiales. Una especie de registro informal siempre desde la óptica artística. Desde la Universidad del Estado de Texas, el astrónomo forense Donald Olson ha investigado la relación entre el óleo de Church y el poema de Whitman; sostiene que ambos fueron testigos del mismo evento, el primero desde Catskill, Nueva York y el segundo desde la ciudad de Nueva York: el paso de un bólido fragmentado en dos, y con escintilaciones, durante más de 30 segundos, evento que no pasó por alto en diarios y revistas de otros lugares del globo.
Whitman nos legó uno de sus fantásticos poemas donde lo poético no menoscaba lo divulgativo del fenómeno, pero hoy ya podemos precisar: se trató de un superbólido [un meteoro de más masa, sonido apreciable y muy brillante, de magnitud superior a la de Venus, que es -4] y no un cometa. Y sí, se dividió en varias partes, como podemos contemplar en el cuadro y leer en los versos de Whitman.

Frederic Church, Meteoro de 1860

Fragmento final de “Año de Meteoros”
No olvido cantar el prodigio, el barco que remotó las aguas de mi bahía
esbelto y majestuoso, 600 pies de eslora, el Great Eastern remontó las aguas de mi bahía
su deslizarse veloz, rodeado de una miríada de pequeñas barcas, no olvido cantarlo; ni al cometa que desde el norte llegó sin anunciarse, y encendió el cielo
ni a su extraña procesión de enormes meteoros, deslumbrantes sobre nuestras cabezas
(durante un instante, largo instante, hizo navegar sus bólidos de ultraterrena luz sobre nuestras cabezas
y luego se alejó, engullido por la noche, y desapareció).
De tales cosas, e incierto como ellas, canto. De centelleos como el suyo
urdo y hago centellear estos cantos.
Tus cantos, oh, año moteado de bueno y malo,
año de presagios, año de la juventud que amo
año de cometas y meteoros fugaces y extraños, ¡eh, tú!
Aquí tienes a uno tan fugaz y tan extraño
que te revolotea a toda prisa, pronto a caer, a desaparecer
¿y qué es sino este libro?
¿Y qué soy yo sino uno de tus meteoros?
Walt Whitman. Traducción de Estíbaliz Espinosa
No será la primera ni la última vez que un «yo lírico» se identifique con un fenómeno celeste. El yo poético de Whitman «contiene multitudes», y nos recuerda una época en la que se miraba a un cielo con una curiosidad genuina y menos luces LED.
Para futuros astrónomos forenses, buenas noticias: el arte de nuestra especie está cuajado de referencias a meteoros y cometas, considerados tanto presagios benignos [Giotto di Bondone pintó un cometa, seguramente el Halley, en La adoración de los Magos de 1305, como una suerte de estrella de Belén; por eso la sonda que más se acercó al Halley en 1986 se llamó Giotto] como augurios nefastos [muchos de los cometas exquisitamente reproducidos en el Libro de Seda de Mawangdui, en China, hacia el siglo II a. de C, donde se les llama «estrellas escoba», seguramente por su forma]. Y ahí tenemos la maravillosa escena 32 del tapiz de Bayeux, se cuenta que bordado por Matilde, esposa de Guillermo I el Conquistador, y sus damas –nos inclinamos más bien por la idea de fue obra de artesanos ingleses hacia 1080–. Isti mirant stella: «estos miran asombrados la estrella», dice la escena. En ella, un cometa de hilos dorados deslumbra a los sajones: estos lo interpretan a lo gafe y los normandos como un impulso a su conquista. Ya sabemos quién ganó.

Escena 32 del Tapiz de Bayeux, Museo del Tapiz, Bayeux, Francia
Hay testimonios de posibles cometas en el arte rupestre: a Toca do Cosmos en Brasil, Valcamonica en el norte de Italia, petroglifos de Nuevo México, entre otros todavía objeto de investigación, dada la ambigüedad con que pueden interpretarse. Lo que sí es pura leyenda renacentista es la famosa excomunión del Halley por parte del Papa Calixto III, de los Borgia de toda la vida, en lo que sería un astuto y algo chiflado ardid para quitarse de encima el mal fario en la guerra contra los turcos. Sí hubo una bula papal que ordenaba la cruzada contra los turcos, pero sin mencionar al cometa. Esta leyenda la reprodujo, entre otros, el astrónomo francés Pierre-Simon Laplace.
Y por último un cometa pintado tenuemente, pero con un mensaje potente: el del lienzo del escocés William Dyce, Pegwell Bay, Kent: Una recolección del 5 de octubre de 1858 [1860], que muestra familiares suyos recogiendo fósiles bajo la débil estela del cometa Donati en el cielo. El óleo data de poco después de la publicación de El origen de las especies, de Charles Darwin, en 1859, re-situando al ser humano en un nuevo paisaje terrestre y cósmico: el paisaje de la ciencia.

William Dyce, “Pegwell Bay, Kent: Una recolección del 5 de octubre de 1858” (1860)
***
haiku en Guillermo
Choven Xemínidas.
Meteoros falan de ti
sen saber de ti.
[Llueven Gemínidas.
Meteoros hablan de ti
sin saber de ti.]
de Curiosidade, Aira, 2017. Estíbaliz Espinosa.
La ciencia actual distingue entre meteoro, meteorito e incluso meteoroide: un asteroide de no más de 50 m. de diámetro que vaga por el espacio. Pero recordemos el mantra: sólo será meteorito si toca tierra. La mayoría de los que aterrizan en nuestros paisajes son condritas, meteoritos no diferenciados [que no han sufrido fusión tras haberse formado por acreción, es decir, que permanecen casi igual a hace unos 4.500 millones de años] desprendidos de un asteroide, y contienen tesoros informativos sobre el origen del sistema solar o compuestos orgánicos. Alrededor de un 4’5% de las condritas caídas contienen carbono pero, ojo, eso no las convierte en portadoras de vida, por mucho que venda la idea de que la vida vino del espacio. Los diamantes y las minas de lápiz son carbono también. Y la panspermia –la teoría de que la vida viaja en asteroides y se va sembrando por ahí, ya que panspermia significaría algo así como «semillas por todas partes»- no goza de consenso en la actualidad.
No obstante, algunas certezas no dejan de plegarse en una mueca burlona. Por ejemplo, la distinción entre asteroide y cometa se ha revisado en los últimos meses gracias al objeto ‘Oumuamua [en hawaiano primer mensajero que llega de lejos], que ha traído en jaque a l*s astrónomo*s. Se sabe que es el primer objeto errante interestelar que detectamos, dato fascinante de por sí. De forma extraña [como un puro], una especie de boomerang lanzado por nadie y perdido a 26 Km/s, superando la velocidad de escape del Sol, vagabundo desde la constelación de Lira, con aspecto de asteroide pero comportamiento de cometa. La explicación de su carencia de coma se debe quizás a una baja emisión tanto de gas como de polvo. Según Jessica Agarwal, astrónoma del Instituto Max Planck para la Investigación del Sistema Solar, en Gotinga, en comparación con los cometas típicos su tasa de desgasificación es pequeña. Pero existe. Tal vez le ha dado un impulso inesperado, suficiente para acelerarlo pero insuficiente para volver visible una estela por sublimación. Lo hemos detectado un instante, a finales de 2017, y no lo veremos más. Como el cometa de Miss Mitchell, no es de los que vuelve. Pero puede haber más como él. Y lo curioso es que ya lo habíamosimaginado. El divulgador Borja Tosar recordó en una charla la asombrosa similitud de ‘Oumuamua con el asteroide también cilíndrico y de rápida rotación de Cita con Rama, de Arthur C. Clarke, un clásico de la ciencia-ficción. Casualidad, desde luego. Pero los sapiens estamos programados para buscar patrones y coincidencias y la imaginación brutal de la naturaleza supone un desafío para la nuestra; cuando una fantasía humana se anticipa [y Clarke creció en la época anterior a la astronáutica] y la naturaleza parece copiarla, y no al revés, nos reconciliamos un poco más con nuestra especie.
Entretanto, ‘Oumuamua y otros fenómenos ni siquiera fabulados podrán revelarnos más preguntas: cometas y asteroides son joyas preservadas en frío que han escapado de la evolución planetaria y seguido otros excéntricos y apasionantes caminos. A veces tras ellos caerá una lluvia de meteoros, pero igual ya no nos importa no pedir deseo alguno: verlos y conocer su origen ya es alucinante de por sí.
Meteoros y cometas aúnan belleza y violencia, como en general casi todo lo [poco] que sabemos del universo. E indiferencia. No se saben hermosos, objetos de deseo o de destrucción ni, por mucho que los bauticemos mensajeros, parecen enviados por ninguna inteligencia concreta con un propósito.
Quizá a los dinosaurios no avianos les habría aliviado llegar a estas mismas conclusiones hace 66 millones de años, aunque tampoco les habría servido de mucho frente al asteroide que acabó con –casi– todos ellos.
¿Acabarán también con los que se hacen llamar sapiens? El cine ya nos ha puesto en ese brete en incontables guiones. Y desde la poesía alguien mostró curiosidad por saber si, por ejemplo, sería un meteoro el que acabó con aquella legendaria isla de la Atlántida y su civilización que, casi en superposición cuántica, existió y al mismo tiempo no.Tan lejos y tan cerca de la nuestra y de nuestras certezas. No sin retranca, así lo captura este fragmento del poema Atlántida, de la Nobel polaca Wislawa Szymborska:
Incapaces de servir
en serio como moraleja.
Cayó un meteoro.
No era un meteoro.
Un volcán hizo erupción.
No era un volcán.
Alguien gritó algo.
Nadie nada.
En esta más o menos Atlántida.

Fotografía de Óscar Blanco. Meteoros sobre laguna de A Veiga
Bibliografía
Rao, J., «The Leonids: the Lion King of Meteor showers», in Journal of the International Meteor Association, vol. 23, no. 4, p. 120-135, 1995
International Dark Sky Asociation, «7 Pieces of Art inspired by the Night Sky»
Agrupación Astronómica Coruñesa Ío, «7 obras de arte inspiradas polo ceo nocturno»
Altschuler, D. R y Ballesteros, F. J., Las mujeres de la luna, Next Door Publishers, Pamplona, 2016
Blog Vega 0.0, «Observando meteoros: la tasa horaria zenital»
Solar System Exploration, NasaScience, «In Depth: Perseids»,
Phillip McCouat, «Comets in art», en Journal of Art in Society
Borja Tosar, Postal Planetaria, charla en el Planetario de la Casa de las Ciencias de A Coruña, 2017
Zoe Macintosh, Space.com, «Walt Whitman Meteor Mystery Solved by Astronomer Sleuths»
Antonio Martínez Ron, Fogonazos, «Trabajos de astronomía forense»
European Space Agency, Giotto, «ESA remembers the night of the comet»
Investigación y ciencia, ‘Oumuamua es un cometa, no un asteroide‘
Trigo-Rodríguez J.M. y Martínez-Jiménez M. «Las condritas y sus componentes primigenios» , Revista Enseñanza de las Ciencias de la Tierra-AEPECT nº 21-3, Asociación Española para la Enseñanza de las Ciencias de la Tierra, Madrid, pp. 263-272.
Sobre la autora: Estíbaliz Espinosa es escritora y cantante lírica. Pertenece a la Agrupación Astronómica Coruñesa Ío
El artículo Meteoros. LLuvias. Poemas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas: