

La obesidad infantil podría iniciarse antes de la concepción
 Foto: Hush Naidoo / Unsplash
Foto: Hush Naidoo / UnsplashUn grupo de investigadores de la Universidad del País Vasco, el Hospital de Cruces, la clínica IVI Bilbao y Biocruces Bizkaia ha descubierto que los ovocitos —óvulos inmaduros— de las mujeres obesas y de las mujeres con sobrepeso tienen menores concentraciones de ácidos grasos omega-3.
En un estudio de la composición lipídica de 922 óvulos de fertilización in vitro de 205 mujeres de complexión normal, con sobrepeso y con obesidad, dirigido por el catedrático de la Facultad de Medicina y Enfermería de la UPV/EHU Roberto Matorras Weinig, se ha encontrado que los ovocitos tanto de las mujeres obesas como con sobrepeso tienen una composición lipídica muy diferente.
Los ácidos grasos omega-3 son esenciales en la dieta humana, es decir, deben ser ingeridos porque el organismo no los sintetiza. Su ingesta es en general escasa en la dieta occidental. Por otra parte, señala el Dr. Matorras, “los ácidos grasos omega-3 compiten metabólicamente con los omega-6, cuya ingesta en general es demasiado alta en la dieta occidental. Así, elevadas ingestas de omega-6 contribuyen a que haya bajos niveles de omega-3. Presumiblemente este sea el mecanismo de sus bajos niveles en los óvulos”.
La obesidad es un conocido problema de salud pública con numerosas repercusiones en diferentes órganos. “Una de sus implicaciones en el embarazo es el nacimiento de niños macrosómicos (de peso elevado), y con posterior riesgo de obesidad infantil y adulta. Hasta la fecha esto era atribuido al efecto de la obesidad materna durante el embarazo, así como a las dietas inadecuadas en la vida infantil. Pero con estos hallazgos se plantea la posibilidad de que los problemas de estos niños puedan iniciarse incluso antes de su concepción, debido a una peor composición lipídica de los óvulos que los han generado”, indica Matorras.
El investigador añade que “las pacientes obesas tienen peores resultados en fertilización in vitro, los cuales han sido atribuidos a numerosos motivos. Con este descubrimiento se pone de manifiesto otra posible causa de estos resultados inferiores”.
Referencia:
Roberto Matorras, Antonia Exposito, Marcos Ferrando, Rosario Mendoza, Zaloa Larreategui, Lucía Laínz, Larraitz Aranburu, Fernando Andrade, Luis Aldámiz-Echevarria, Maria Begoña Ruiz-Larrea, Jose Ignacio Ruiz-Sanz (2020) Oocytes of women who are obese or overweight have lower levels of n-3 polyunsaturated fatty acids compared with oocytes of women with normal weight Fertility and Sterility doi: 10.1016/j.fertnstert.2019.08.059
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo La obesidad infantil podría iniciarse antes de la concepción se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La ausencia de un supresor tumoral podría producir esterilidad en ratones.
- El pteroestilbeno como posible tratamiento de la obesidad
- Resveratrol y pteroestilbeno en el control epigenético de la acumulación de grasa corporal
El misterio de los caballos salvajes de Chernóbil
Germán Orizaola
 Manada de caballos de Przewalski en la Zona de Exclusión de Chernóbil (Ucrania). Septiembre 2016. Foto: Luke Massey
Manada de caballos de Przewalski en la Zona de Exclusión de Chernóbil (Ucrania). Septiembre 2016. Foto: Luke MasseySe cumplen 34 años del accidente en la central nuclear de Chernóbil (Ucrania). Este accidente, el mayor de la historia en una instalación nuclear, llevó a la creación de una Zona de Exclusión de 4 700 km² entre Ucrania y Bielorrusia. Un total de 350 000 personas fueron evacuadas de ese área.
Las predicciones iniciales señalaban que, debido a la contaminación radiactiva, la zona iba a ser inhabitable durante más de 20 000 años. Se pensaba que Chernóbil se convertiría en un desierto para la vida.
Tres décadas más tarde numerosos estudios han señalado que en Chernóbil vive una diversa y abundante comunidad animal. Un gran número de especies amenazadas a nivel nacional y europeo tienen hoy su refugio en la Zona de Exclusión de Chernóbil.
Un ejemplo claro de cuál es la situación de la fauna en Chernóbil es el de los caballos de Przewalski.
¿El último caballo salvaje?
La existencia de caballos salvajes en las estepas de Asia se conocía en occidente desde el siglo XV. Pero no fue hasta 1881 cuando la especie se describió formalmente para la ciencia a partir de un cráneo y una piel recolectados por el coronel ruso Nikolái Przewalski. Así fue como los caballos conocidos como takhi (“sagrados”) en Mongolia pasaron a llamarse caballos de Przewalski (Equus ferus przewalski).
 Caballo de Przewalski, Zona de Exclusión de Chernobyl (Ucrania). Septiembre 2015. Foto: Nick Beresford
Caballo de Przewalski, Zona de Exclusión de Chernobyl (Ucrania). Septiembre 2015. Foto: Nick BeresfordDurante mucho tiempo se consideraron como el único caballo salvaje del mundo. Sin embargo, estudios recientes han indicado que son formas asilvestradas descendientes de los primeros caballos domesticados por el pueblo Botai en el norte de Kazajistán hace 5 500 años.
En tiempos del coronel Przewalski estos caballos salvajes ya eran escasos en las estepas de Mongolia y China. El sobrepastoreo y la caza para su consumo por las poblaciones humanas provocaron su declive final. El último ejemplar salvaje fue observado en el desierto del Gobi en 1969.
La población en cautividad tampoco pasó por una situación muy positiva. En los años 50 solo 12 individuos sobrevivían en zoos europeos. No obstante, a partir de ellos se comenzó un programa de cría en cautividad que ha conseguido rescatar a la especie de la extinción.
Hoy la población llega a los 2 000 individuos. Varios centenares viven en libertad en las estepas de Asia y distintas zonas de Europa. Entre ellas, para sorpresa de muchos, en Chernóbil.
 Grupo de caballos de Przewalski en la Zona de Exclusión de Chernóbil (Ucrania). Septiembre 2016. Foto: Luke Massey
Grupo de caballos de Przewalski en la Zona de Exclusión de Chernóbil (Ucrania). Septiembre 2016. Foto: Luke MasseyLos caballos de Chernóbil
En el momento del accidente en la central nuclear no existían caballos de Przewalski en Chernóbil. No fue hasta 1998 cuando los primeros 31 individuos llegaron a la Zona de Exclusión. Eran 10 machos y 18 hembras procedentes de la reserva natural de Askania Nova, en el sur de Ucrania, y 3 machos de un zoo local.
Tras una alta mortalidad asociada al traslado y suelta, la elevada tasa de nacimientos hizo que la población llegase a 65 individuos en solo cinco años. La intensa caza furtiva entre 2004 y 2006 diezmó a la población. Solo 50 individuos sobrevivían en 2007.
 Macho de caballo de Przewalski fotografiado por cámaras de fototrampeo en el bosque rojo, Zona de Exclusión de Chernóbil (Ucrania). Abril 2017.
Macho de caballo de Przewalski fotografiado por cámaras de fototrampeo en el bosque rojo, Zona de Exclusión de Chernóbil (Ucrania). Abril 2017.Foto: RED FIRE Project / UK Centre for Ecology and Hydrology
Las intensas medidas de protección han hecho que solo 20 años después de su llegada a Chernóbil su número se haya multiplicado por cinco. El censo más actual, realizado por científicos locales en 2018, reveló que en la parte ucraniana de la Zona de Exclusión viven unos 150 animales. Los caballos se agrupan en entre 10 y 12 manadas familiares, además de dos grupos de machos y algunos individuos solitarios. En 2018 al menos 22 potros nacieron en la Zona de Exclusión. Algunos se han movido más al norte y se han asentado ya en Bielorrusia.
 Dos caballos de Przewalski fotografiados por cámaras de fototrampeo dentro de un pinar de la Zona de Exclusión de Chernóbil (Ucrania). Enero 2015.
Dos caballos de Przewalski fotografiados por cámaras de fototrampeo dentro de un pinar de la Zona de Exclusión de Chernóbil (Ucrania). Enero 2015.Foto: TREE Project / UK Centre for Ecology and Hydrology
Las cámaras de fototrampeo instaladas por toda la Zona de Exclusión han demostrado que, a pesar de ser una especie asociada a las estepas, en Chernóbil estos caballos usan el bosque con gran frecuencia. Esto incluye el famoso “bosque rojo”, una de las zonas más radiactivas del planeta.
Los recientes incendios en Chernóbil han afectado severamente a algunas de las localidades usadas por los caballos en la Zona de Exclusión. Será necesario ahora evaluar el efecto que estos fuegos tendrán sobre la conservación de la especie en la zona.
Las lecciones de los caballos de Chernóbil
La introducción de los caballos de Przewalski en Chernóbil ha sido un éxito. De este éxito se pueden extraer varias lecciones.
El caso de los caballos de Przewalski refleja una vez más que, en ausencia de humanos, Chernóbil se ha convertido en un refugio para la fauna salvaje. Esto nos debería llevar a reflexionar sobre el impacto de la presencia humana sobre los ecosistemas naturales. Sin actividad humana alrededor, incluso con contaminación radiactiva, la gran fauna prospera.
Otras zonas afectadas por contaminación radiactiva como la derivada del accidente en la central de Fukushima (Japón) y de las pruebas de bombas atómicas en los atolones del Pacífico, mantienen igualmente una alta diversidad de fauna. Quizás debamos reconsiderar nuestra visión sobre el impacto a medio y largo de plazo de la radiactividad sobre el medio ambiente.
En todo caso, necesitamos entender mejor los mecanismos que permiten a la fauna vivir en zonas con contaminación radiactiva. Son muchas las preguntas que quedan por responder. ¿Están los organismos vivos de Chernóbil expuestos a menos radiación de la prevista?, ¿causa esta exposición menos daño?, ¿tienen los organismos mecanismos de reparación del daño celular causado por la radiación más eficaces de lo esperado?
Para responder a estas preguntas necesitamos más ciencia. En septiembre, esperamos empezar a trabajar con los caballos de Przewalski en Chernóbil, intentando desvelar los misterios que hacen que esta especie y muchas otras prosperen en la Zona de Exclusión.
Sobre el autor: Germán Orizaola es investigador del Programa Ramón y Cajal en la Universidad de Oviedo
Este artículo fue publicado originalmente en The Conversation. Artículo original.
El artículo El misterio de los caballos salvajes de Chernóbil se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Los supermicrobios amenazan con ser más letales que el cáncer
- Epigenética, desigualdad y cambio climático
- La oreja de oso, una joya del Pirineo que guarda el secreto de la resurrección
Los números que proporcionan alegría
La imaginación de las personas es increíble. En anteriores entradas del Cuaderno de Cultura Científica, como Los números enamorados o ¿Pueden los números enamorarse de su propia imagen?, hemos visto curiosas e interesantes familias de números naturales, sin embargo, la imaginación matemática no deja de crear, o descubrir si uno cree en el platonismo matemático, fascinantes grupos de números. En esta entrada os hablaré de los números llamados harshad o de Niven.
 Symmetry, acrílico sobre lienzo, 60 x 60 cm, del artista suizo Eugen Jost. Obra perteneciente a la exposición Everything is number
Symmetry, acrílico sobre lienzo, 60 x 60 cm, del artista suizo Eugen Jost. Obra perteneciente a la exposición Everything is numberUn número natural se dice que es un número harshad, o también, de Niven, si es divisible por la suma de sus dígitos. Por ejemplo, el número 18 es harshad porque es divisible por 1 + 8 = 9, como también lo es el número de la bestia, el 666 (véanse las entradas 666, el número de la bestia (1) y (2)), divisible por 6 + 6 + 6 = 18, o el número de Hardy-Ramanujan 1729 (véase la entrada Las matemáticas del taxi ), divisible por 1 + 7 + 2 + 9 = 19. Sin embargo, el 25 no es un número de Niven ya que no es divisible por 2 + 5 = 7, ni tampoco lo son todos los números primos con más de un dígito.
El concepto de número harshad fue introducido por el matemático recreativo indio Dattatreya Ramchandra Kaprekar (1905-1986), a quien le debemos algunos descubrimientos de teoría de números como la constante de Kaprekar, los números de Kaprekar, los autonúmeros o los números harshad, en su artículo Multidigital numbers, publicado en la revista Scripta Mathematica en 1955. El nombre harshad viene de la unión de las dos palabras del sánscrito “harsa”, que significa alegría o felicidad, y “da”, que significa “dar”, por lo que sería algo así como “que da, o proporciona, alegría”.
El concepto fue introducido de nuevo por el matemático canadiense-estadounidense Ivan M. Niven (1915-1999), que fue presidente de la Mathematical Association of America, en una charla que impartió en un congreso de teoría de números en 1977. Por este motivo, se les conoce también como números de Niven.
 Fotografías de los matemáticos D. R. Krapekar (abajo), de Wikimedia Commons, e Ivan M. Niven (arriba), tomada por Konrad Jacobs y perteneciente a la colección de fofografías de Oberwolfach.
Fotografías de los matemáticos D. R. Krapekar (abajo), de Wikimedia Commons, e Ivan M. Niven (arriba), tomada por Konrad Jacobs y perteneciente a la colección de fofografías de Oberwolfach.Una de las ventajas de una familia como esta es que es sencillo calcular por uno mismo, a mano o con calculadora, los primeros números de la misma, por ejemplo, los menores que 1.000, que se muestran más abajo, o hasta la cantidad que cada cual decida. Los números harshad se corresponden con la sucesión A005349 de la Enciclopedia online de sucesiones de números enteros, del matemático británico-estadounidense N. J. A. Sloane. Los menores de 1.000 son:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 18, 20, 21, 24, 27, 30, 36, 40, 42, 45, 48, 50, 54, 60, 63, 70, 72, 80, 81, 84, 90, 100, 102, 108, 110, 111, 112, 114, 117, 120, 126, 132, 133, 135, 140, 144, 150, 152, 153, 156, 162, 171, 180, 190, 192, 195, 198, 200, 201, 204, 207, 209, 210, 216, 220, 222, 224, 225, 228, 230, 234, 240, 243, 247, 252, 261, 264, 266, 270, 280, 285, 288, 300, 306, 308, 312, 315, 320, 322, 324, 330, 333, 336, 342, 351, 360, 364, 370, 372, 375, 378, 392, 396, 399, 400, 402, 405, 407, 408, 410, 414, 420, 423, 432, 440, 441, 444, 448, 450, 460, 465, 468, 476, 480, 481, 486, 500, 504, 506, 510, 511, 512, 513, 516, 518, 522, 531, 540, 550, 552, 555, 558, 576, 588, 592, 594, 600, 603, 605, 612, 621, 624, 629, 630, 640, 644, 645, 648, 660, 666, 684, 690, 700, 702, 704, 711, 715, 720, 730, 732, 735, 736, 738, 756, 770, 774, 777, 780, 782, 792, 800, 801, 803, 804, 810, 820, 825, 828, 832, 840, 846, 864, 870, 874, 880, 882, 888, 900, 902, 910, 912, 915, 918, 935, 936, 954, 960, 966, 972, 990, 999, 1.000.
Como podemos observar hay muchos números de Niven entre los mil primeros números, en concreto, 213. Sin embargo, como demostraron en 1985 los matemáticos estadounidenses Robert E. Kennedy y Curtis N. Cooper la densidad de estos números es cero, es decir, que cuanto más grandes sean los números naturales considerados menos números que proporcionan alegría habrá. En otras palabras, si N(n) es la cantidad de números de Niven menores, o iguales, que n, entonces el límite del cociente N(n) / n es cero.
Una curiosidad de estos números está relacionada con los números factoriales. Recordemos que el factorial de un número m es el número igual a la multiplicación de todos los números naturales menores, o iguales, que el mismo, es decir, m! = m x (m – 1) x (m – 2) x … x 3 x 2 x 1. Así, para los primeros números naturales sus factoriales son 1! = 1, 2! = 2, 3! = 6, 4! =24, 5! = 120, 6! = 720, 7! = 5040, y podríamos continuar. Si nos fijamos, todos esos números son de Niven, incluso si continuamos con algunos más, 40.320, 362.880, 3.628.800, 39.916.800, … descubriremos que lo siguen siendo. Por este motivo, algunas personas interesadas en el estudio de esta familia se preguntaron si todos los números factoriales serían de los que proporcionan alegría. La respuesta es negativa, ya que la suma de los dígitos del factorial del número 432, es 3.897, cuya descomposición en factores primos es 32 x 433, pero el número primo 433 no puede dividir a 432!. En consecuencia, el factorial 432! no es harshad.
 El año 2.020 es un año harshad, o un año que proporciona alegría, ya que 2.020 es divisible por 4, que es la suma de sus dígitos. La imagen ha sido compuesta con los números de una tipografía de números creada por el diseñador barcelonés DAQ
El año 2.020 es un año harshad, o un año que proporciona alegría, ya que 2.020 es divisible por 4, que es la suma de sus dígitos. La imagen ha sido compuesta con los números de una tipografía de números creada por el diseñador barcelonés DAQOtra propiedad que se ha estudiado ha sido la existencia de números harshad consecutivos, más allá de los diez primeros números. La primera pareja es, como puede verse arriba, 20 – 21, aunque hay muchas más, como 80 – 81. El primer trio de números de Niven es 110 – 111 – 112. Los cuatro primeros números consecutivos que producen alegría son 510 – 511 – 512 – 513. Mientras que para obtener cinco números consecutivos ya nos tenemos que desplazar a números más grandes, en concreto al sexteto que empieza en 131.052.
En 1982 el matemático Robert E. Kennedy demostró que no es posible construir una sucesión de 21 números harshad consecutivos, pero como probaría después con su colega Curtis Cooper, sí se pueden construir 20 números de Niven consecutivos, de hecho, existen infinitos ejemplos de tales sucesiones. Aunque la más pequeña de esas familias tiene más de 44.363.342.786 dígitos.
 La ceramista estadounidense Laura C. Hewitt crea cerámicas con números binarios, con tipografías de máquinas de escribir, como este hermoso jarrón. La imagen pertenece a su tienda de Etsy.
La ceramista estadounidense Laura C. Hewitt crea cerámicas con números binarios, con tipografías de máquinas de escribir, como este hermoso jarrón. La imagen pertenece a su tienda de Etsy.La propiedad definitoria de los números harshad está dada en función de los dígitos de la representación del número, luego no es una propiedad del número en sí mismo, sino que depende de la base de numeración en la que lo representemos.
Empecemos considerando el sistema binario, es decir, la representación de los números en base dos (véase por ejemplo el video de la serie Una de mates dedicado a los números binarios). Por ejemplo, los números 20, 21, 27 y 34 se representan en el sistema binario como:
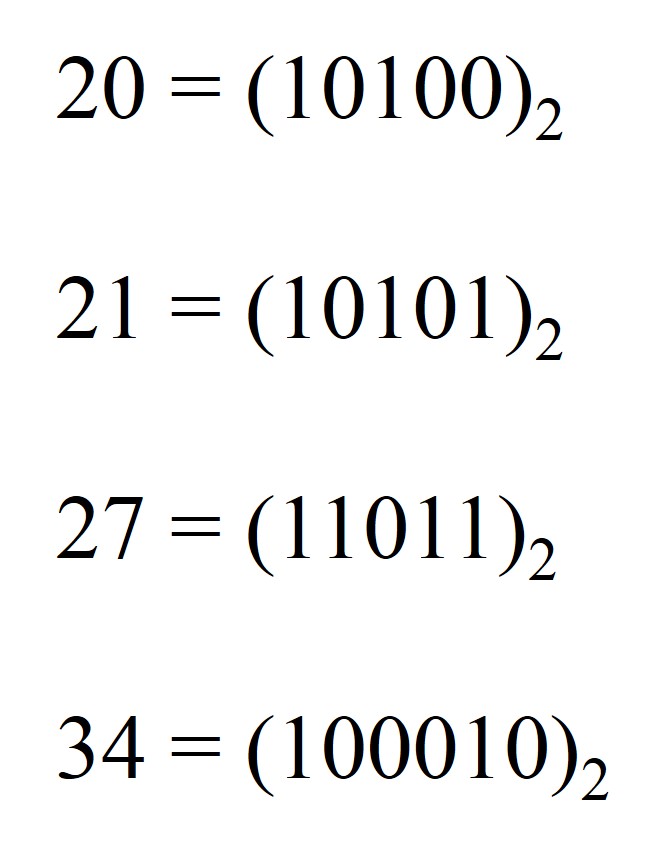
Recordemos que los unos y ceros de la representación binaria nos están diciendo qué potencias de 2 se utilizan para expresar el número como sumas de potencias de 2. Como los tres primeros números binarios anteriores tienen 5 dígitos las potencias de 2 implicadas son 16, 8, 4, 2 y 1. Además, 20 = 16 + 4 (16 sí, 8 no, 4 sí, 2 no y 1 no), 21 = 16 + 4 + 1 y 27 = 16 + 8 + 2 + 1. El último número tiene 6 dígitos, luego implica también a la potencia 32, de hecho, 34 = 32 + 2 (32 sí, 16 no, 8 no, 4 no, 2 sí y 1 no).
La suma de los dígitos binarios del número 20 es 2 (véase la imagen anterior), que divide a 20, luego el número 20 es un número 2-harshad (donde el prefijo indica en la base en la que tiene esa propiedad, luego en los casos normales, cuando no lo hemos indicado, habría sido 10-harshad). Y la suma de los dígitos binarios de 21 es 3, que divide a 21, luego también es 2-harshad. Por lo tanto, 20 y 21 son 2-harshad y 10-harshad.
Por otra parte, 27 que es 10-harshad, no es 2-harshad, ya que la suma de sus dígitos es 4, que no divide a 27. Mientras que para el 34, que no es 10-harshad, la suma de sus dígitos es 2, que divide a 34, luego sí es 2-harshad.
Al igual que hemos comentado antes para la base decimal, podríamos calcular los primeros números (hasta la cantidad que deseemos) que son harshad en la base binaria, es decir, que son 2-harshad. En general, podemos calcular los números b-harshad para cualquier base de numeración b, no solo 2 o 10.
Para un sistema de numeración en base b, los primeros b números naturales –que se corresponden con las b – 1 cifras básicas no nulas y el número de la base b, son trivialmente números b-harshad.
Los únicos números primos que pueden ser b-harshad son aquellos que son menores, o iguales, que la base. Por eso los únicos primos de Niven en la base decimal son 2, 3, 5 y 7, o el número 11 es 12-harshad.
Existen cuatro números que son b-harshad para cualquier base b, que son 1, 2, 4 y 6. Aunque el número 12 casi les acompaña, puesto que es b-harshad para todas las bases, excepto b = 8.
 Los mediadores (2016), de la artista sudafricana, afincada en Francia, Nicky Broekhuysen. Imagen de la página web del artista
Los mediadores (2016), de la artista sudafricana, afincada en Francia, Nicky Broekhuysen. Imagen de la página web del artista Detalle de Los mediadores (2016), del artista sudafricano, afincado en Francia, Nicky Broekhuysen. Imagen de la página web del artista
Detalle de Los mediadores (2016), del artista sudafricano, afincado en Francia, Nicky Broekhuysen. Imagen de la página web del artistaPero volvamos a los números harshad, o de Niven, para la base decimal, aunque lo que vamos a comentar a continuación también sería válido para cualquier base. Vamos a considerar dos familias particulares dentro de esta familia. La primera es la formada por los números harshad (o de Niven) múltiples, que son aquellos tales que, al dividirlos por la suma de sus dígitos, el resultado es otro número harshad. Por ejemplo, el número 6.804, que al dividirlo por la suma de sus dígitos, 18, el resultado 378 sigue siendo un número que proporciona felicidad. Más aún, con este número se puede seguir el proceso, hasta un total de cuatro veces (llamada multiplicidad de número de harshad múltiple 6.804), como se muestra en la imagen.
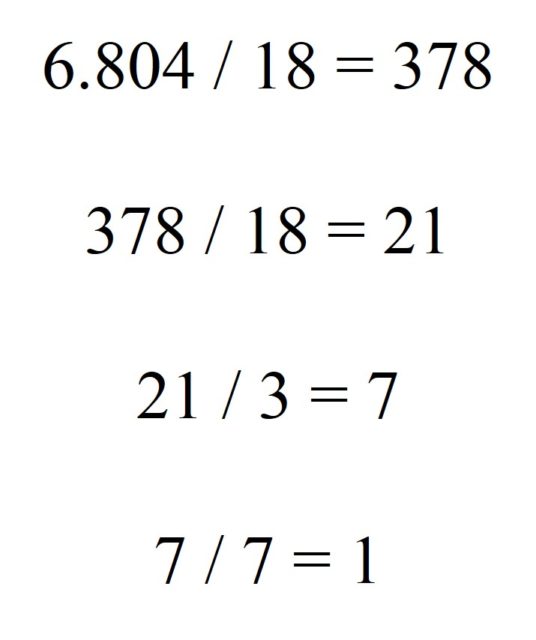
O el número 987.552, que es harshad múltiple, con multiplicidad 3, ya que en el proceso de dividir por las sumas de los dígitos se obtienen los números de Niven 27.432 y 1.524, pero el siguiente resultado 127 ya no lo es.
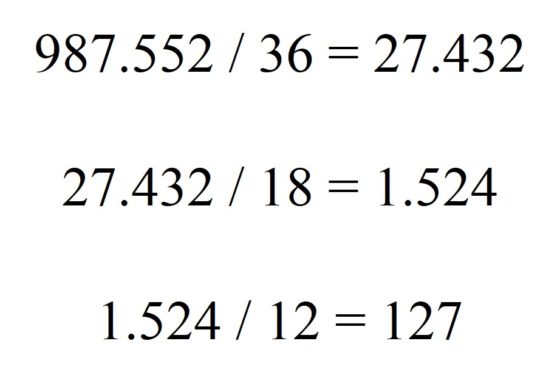
El número 2.016.502.858.579.884.466.176 harshad múltiple, con multiplicidad 12, como se muestra en la imagen, donde los divisores son las sumas de los dígitos de los números del dividendo, y los resultados se escriben en la línea siguiente.

Una subfamilia interesante dentro de los números harshad podría la fromada por aquellos números tales que al dividirlos por la suma de sus dígitos el resultado sea el producto de los mismos. O lo que es equivalente, el número se puede escribir como el producto de la suma de sus dígitos por el producto de los mismos, por eso reciben el nombre de números suma-producto. Un ejemplo es el número 135 que, al dividirlo por la suma de sus dígitos, 1 + 3 + 5 = 9, el resultado es 15, que es el producto de los mismos. A pesar del interés de esta propiedad, realmente solo existen 3 números que cumplen la misma, 1, 135 y 144.
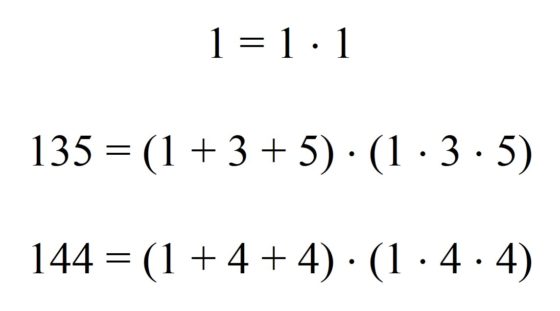
Para terminar esta entrada del Cuaderno de Cultura Científica introduciremos los números harshadmórficos, o Nivenmórficos, que son aquellos números n tales que existe un número harshad N cuya suma es el número n y además está en los últimos dígitos de N. Por ejemplo, el número 18 es harshadmórfico ya que existe el número de Niven 16.218, cuyos dígitos suman 18 y termina en 18.
El matemático Sandro Boscaro demostró que curiosamente todos los números, salvo el 11, son harshadmórficos. Siempre se puede encontrar un número de Niven que termine en ese número y sus dígitos también sumen el propio número.
Por ejemplo, si tomamos el número 12, por el resultado de Boscaro sabemos que es harshadmórfico. De hecho, la suma de los dígitos y la terminación del número de Niven 912 es 12. Lo cual vale para cualquier otro número, que no sea once. Os dejo como entretenimiento buscar los correspondientes números de Niven para los números menores que 30 (salvo 11, claro).
Bibliografía
1.- David Wells, The Penguin Dictionary of Curious and Interesting Numbers, Penguin Press, 1998.
2.- J. Sándor, B. Crstici, Handbook of Number Theory II, Kluwer Academic Publishers, 2004.
3.- Wolfram MathWorld: Harshad Number
4.- Wikipedia: Harshad number
5.- N. J. A. Sloane, The On-line Encyclopedia of Integer Sequences: A005349
6.- D. R. Kaprekar, Multidigital numbers, Scripta Math. 21, 27, 1955.
7.- R. E. Kennedy, C. N. Cooper, On the natural density of the Niven numbers,
College Math. J. 15, no. 4, p. 309-312, 1984.
8.- R. E. Kennedy, Digital sums, Niven numbers and natural density, Crux Math. 8, p. 131-135, 1982.
9.- C. N. Cooper, R. E. Kennedy, On consecutive Niven numbers, Fib. Quart.
21, p. 146-151, 1993.
10.-Boscaro, Sandro, Nivenmorphic integers, Journal of Recreational Mathematics 28 (3), p. 201–205, 1996–1997.
11.- Página web del artista Nicky Broekhuysen
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo Los números que proporcionan alegría se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El secreto de los números que no querían ser simétricos
- Números primos gemelos, parientes y sexis (2)
- Números errores de impresión
Juntando semiconductores: el diodo n-p
 Fuente: ESA
Fuente: ESALa introducción de las impurezas adecuadas permite crear semiconductores de distintos tipos, el tipo n y el tipo p [1]. ¿Qué pasaría si tomamos un semiconductor tipo p con una superficie muy limpia y homogénea [2] y juntamos esta superficie con la superficie limpia y homogénea de un semiconductor tipo n? Piénsalo un momento antes de continuar.
Los electrones en la banda de conducción del semiconductor de tipo n pueden moverse a través del límite entre los dos semiconductores y caer en los huecos [3] en la banda de valencia de energía más baja del semiconductor de tipo p. Dicho de otra forma, al establecer el contacto, lo electrones libres de uno y los huecos del otro comienzan a desaparecer. Pero a medida que los electrones desaparecen en el tipo n, las cargas positivas de las impurezas ya no están equilibradas por los electrones conductores negativos que quedan, por lo que el tipo n se carga positivamente. Lo contrario sucede en el semiconductor de tipo p. A medida que desaparecen los huecos, las impurezas terminan teniendo un electrón extra, lo que hace que el tipo p se cargue negativamente.
El resultado de todo esto es que después de muy poco tiempo se establece un campo eléctrico neto entre los semiconductores tipo n y tipo p que detiene el proceso de destrucción mutua al mantener los electrones en el tipo n separados de los huecos en el tipo p, con una «capa agotada» [4] en el medio. Se alcanza pues un estado de equilibrio.
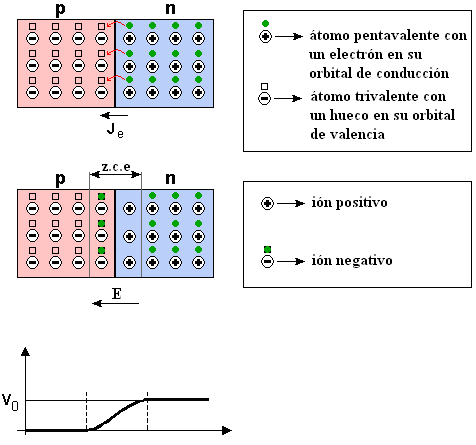 Estado de equilibrio del diodo n-p y formación de la zona agotada (z.c.e.) [4]. Fuente: Wikimedia CommonsSi ahora establecemos una diferencia de potencial, con una batería pequeña, por ejemplo, a través del dispositivo formado por el tipo p y el tipo n, que podemos llamar diodo n-p, el equilibrio se verá afectado o no dependiendo de cómo establezcamos la diferencia de potencial. Si el cable positivo se coloca en el material de tipo n y el cable negativo en el material de tipo p, la separación de los electrones y los agujeros se refuerza. No pasa corriente.
Estado de equilibrio del diodo n-p y formación de la zona agotada (z.c.e.) [4]. Fuente: Wikimedia CommonsSi ahora establecemos una diferencia de potencial, con una batería pequeña, por ejemplo, a través del dispositivo formado por el tipo p y el tipo n, que podemos llamar diodo n-p, el equilibrio se verá afectado o no dependiendo de cómo establezcamos la diferencia de potencial. Si el cable positivo se coloca en el material de tipo n y el cable negativo en el material de tipo p, la separación de los electrones y los agujeros se refuerza. No pasa corriente.
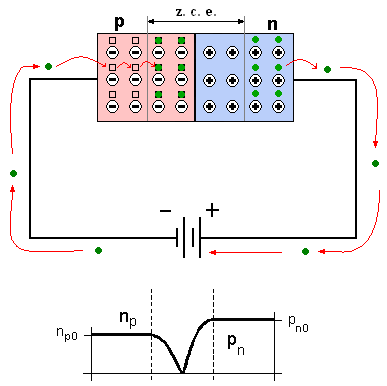 El positivo de la batería al tipo n. La zona agotada (z.c.e.) [4] se amplía. No hay corriente. Fuente: Wikimedia Commons.Pero si invertimos los cables, de modo que el cable positivo llega al tipo p y el cable negativo al tipo n, los electrones negativos en el lado de tipo n se mueven hacia la capa agotada, y lo mismo pasa con los huecos positivos en el tipo p. Si el potencial externo aplicado es mayor que el potencial creado por el campo eléctrico entre los dos semiconductores, pasará la corriente en el diodo n-p.
El positivo de la batería al tipo n. La zona agotada (z.c.e.) [4] se amplía. No hay corriente. Fuente: Wikimedia Commons.Pero si invertimos los cables, de modo que el cable positivo llega al tipo p y el cable negativo al tipo n, los electrones negativos en el lado de tipo n se mueven hacia la capa agotada, y lo mismo pasa con los huecos positivos en el tipo p. Si el potencial externo aplicado es mayor que el potencial creado por el campo eléctrico entre los dos semiconductores, pasará la corriente en el diodo n-p.
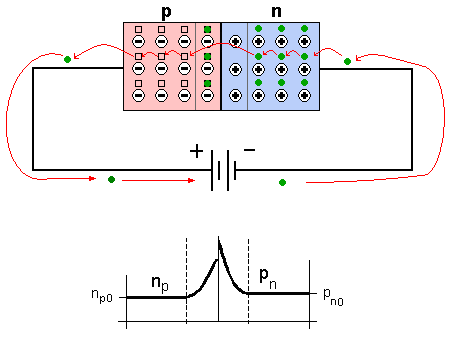 El positivo de la batería al tipo p. Fluye la corriente. La zona agotada (z.c.e.) [4] desaparece. Fuente : Wikimedia Commons¿Y esto para qué sirve? Si ahora llega un fotón desde el exterior y aporta energía de forma que un electrón del tipo n salte a la banda de conducción, la corriente aumentará. El diodo n-p por tanto se puede usar como una fotocélula aún más potente que un simple semiconductor solo. Quizás el uso más común de este tipo de fotocélula es la generación de electricidad a partir de la energía solar. Esto se puede hacer para dispositivos a pequeña escala, como los calculadores de bolsillo, o para necesidades de energía a mayor escala, como la energía para un edificio completo. Estas fotocélulas se suelen llamar células fotovoltaicas.
El positivo de la batería al tipo p. Fluye la corriente. La zona agotada (z.c.e.) [4] desaparece. Fuente : Wikimedia Commons¿Y esto para qué sirve? Si ahora llega un fotón desde el exterior y aporta energía de forma que un electrón del tipo n salte a la banda de conducción, la corriente aumentará. El diodo n-p por tanto se puede usar como una fotocélula aún más potente que un simple semiconductor solo. Quizás el uso más común de este tipo de fotocélula es la generación de electricidad a partir de la energía solar. Esto se puede hacer para dispositivos a pequeña escala, como los calculadores de bolsillo, o para necesidades de energía a mayor escala, como la energía para un edificio completo. Estas fotocélulas se suelen llamar células fotovoltaicas.
Notas:
[1] Para entender bien lo que sigue es conveniente leer antes Impurezas dopantes.
[2] Para visualizarlo puedes entender homogénea como plana, sin irregularidades, lo que permite un buen contacto.
[3] Personalmente creo que es más gráfico decir boquetes, pero mantenemos hueco por aquello de que es la palabra más habitual. Bujero tampoco me parecería mal, pero mejor no.
[4] Una capa de tierra quemada, donde los electrones y huecos se han compensado hasta que el campo eléctrico creado ha impedido que siguiese la destrucción. También se llama barrera interna de potencial o zona de carga espacial (z.c.e.).
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Juntando semiconductores: el diodo n-p se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:¿Qué esconden los sedimentos de la Ría?
 Imagen: Vista de satélite del estuario de la ría de Bilbao en 2005. (Fotografía: NASA – imagen de dominio público. Fuente: Wikimedia Commons)
Imagen: Vista de satélite del estuario de la ría de Bilbao en 2005. (Fotografía: NASA – imagen de dominio público. Fuente: Wikimedia Commons){kind=link}
La ría de Bilbao fue originalmente el estuario más grande del Cantábrico. El espesor de sus sedimentos varía enormemente desde los 10 m que encontramos en El Arenal hasta los 30 m de Las Arenas.
La mayor parte de esos materiales son gravas de origen fluvial anteriores al último cambio climático hace 12.000 años, seguidas de arenas depositadas por la entrada del mar en ascenso durante los milenios posteriores y, finalmente, fangos acumulados en los últimos 4.000 años mientras el nivel marino permanecía estable.
La naturaleza proporcionó a Bilbao 2 elementos fundamentales para su enorme desarrollo económico: el mineral de hierro como materia prima y el estuario como puerto natural, y ambos fueron explotados hasta el límite de sus posibilidades durante los últimos 700 años. Los dominios de la Ría y su valle proporcionaron además el soporte físico para asentar la aglomeración urbana e industrial de los siglos XX y XXI.
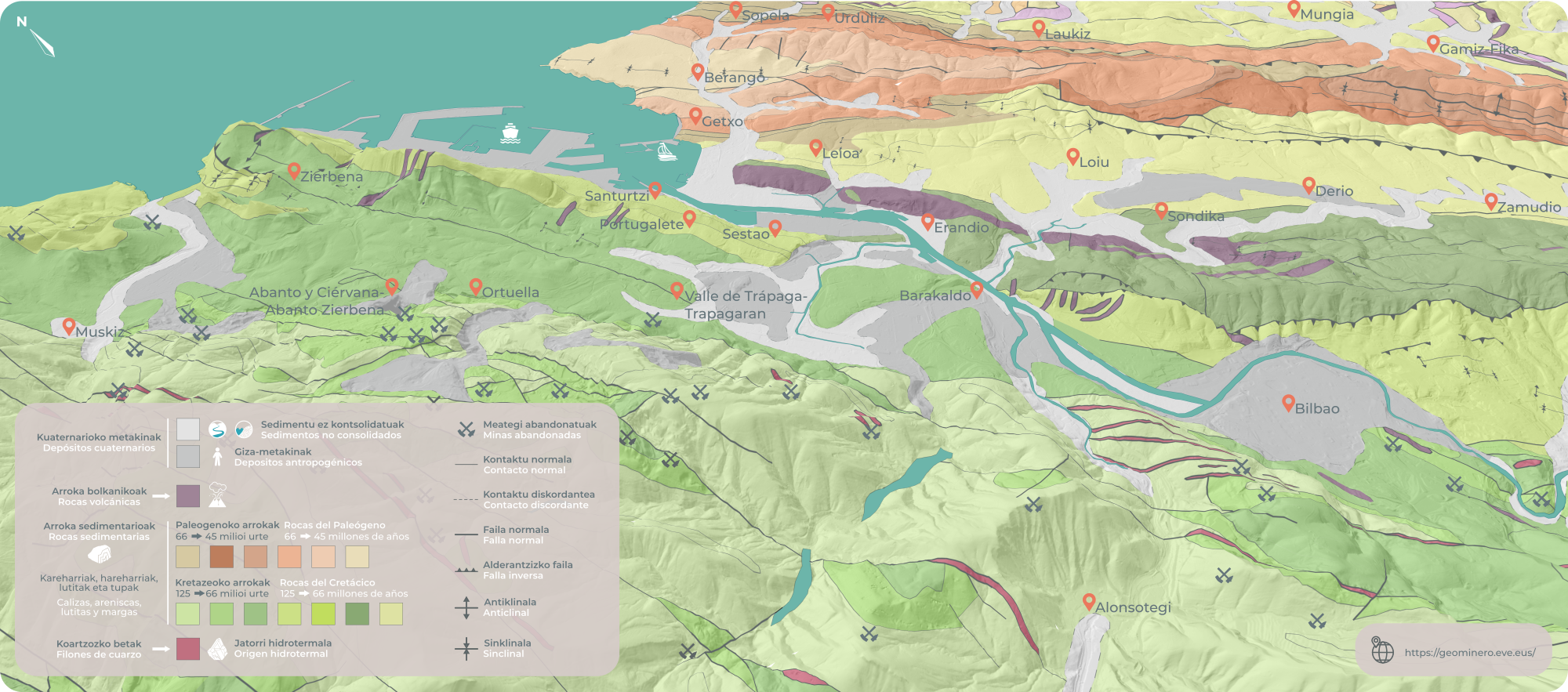 Ilustración 1: características de la geología de la ría del Nervión y sus inmediaciones. (Ilustración: NorArte Studio)
Ilustración 1: características de la geología de la ría del Nervión y sus inmediaciones. (Ilustración: NorArte Studio)La Ría es hoy una creación completamente artificial prisionera entre diques que modificaron todo su recorrido para adaptarlo a las exigencias de la navegación. A partir del siglo XIX, un paisaje nuevo de humos y fábricas, de ferrocarriles, de urbanización opresiva, de movimiento incesante impuesto por la industria pasó por encima de todo lo demás.
Desde los primeros altos hornos que se construyeron sobre sus marismas en 1854, las características naturales de la Ría fueron modificadas por el desarrollo urbano, industrial y portuario. El estuario original se redujo de tamaño ocupando sus dominios para formar un canal mareal desde la ciudad hasta el mar que fue completado en 1885.
Durante los últimos 150 años, la Ría ha recibido vertidos incontrolados de desechos mineros, industriales y domésticos que degradaron sus condiciones físico-químicas. Las concentraciones de oxígeno en sus aguas disminuyeron dramáticamente hasta provocar condiciones anóxicas. La calidad microbiológica del agua era deficiente, mientras que los sedimentos mostraban elevadas concentraciones de compuestos químicos orgánicos e inorgánicos. Como consecuencia de este desarrollo insostenible, en la década de 1970 la Ría se había convertido en una cloaca navegable que atravesaba una de las ciudades más contaminadas de Europa.
El estudio geológico de sus sedimentos proporciona una perspectiva histórica sobre la magnitud del problema, permitiendo definir tres zonas ambientales diferentes desde la superficie hacia abajo:
- Una etapa industrial sin microfauna, que contiene concentraciones extremas de metales y estéril en microfósiles desde la década de 1950.
- Una etapa industrial con microfauna, donde coexisten cantidades elevadas de metales con asociaciones de microfósiles abundantes durante el período 1850-1950.
- Una etapa pre-industrial, que muestra concentraciones naturales de metales y microfósiles, y que corresponde al estuario formado tras el cambio climático y el ascenso marino en los siguientes milenios.
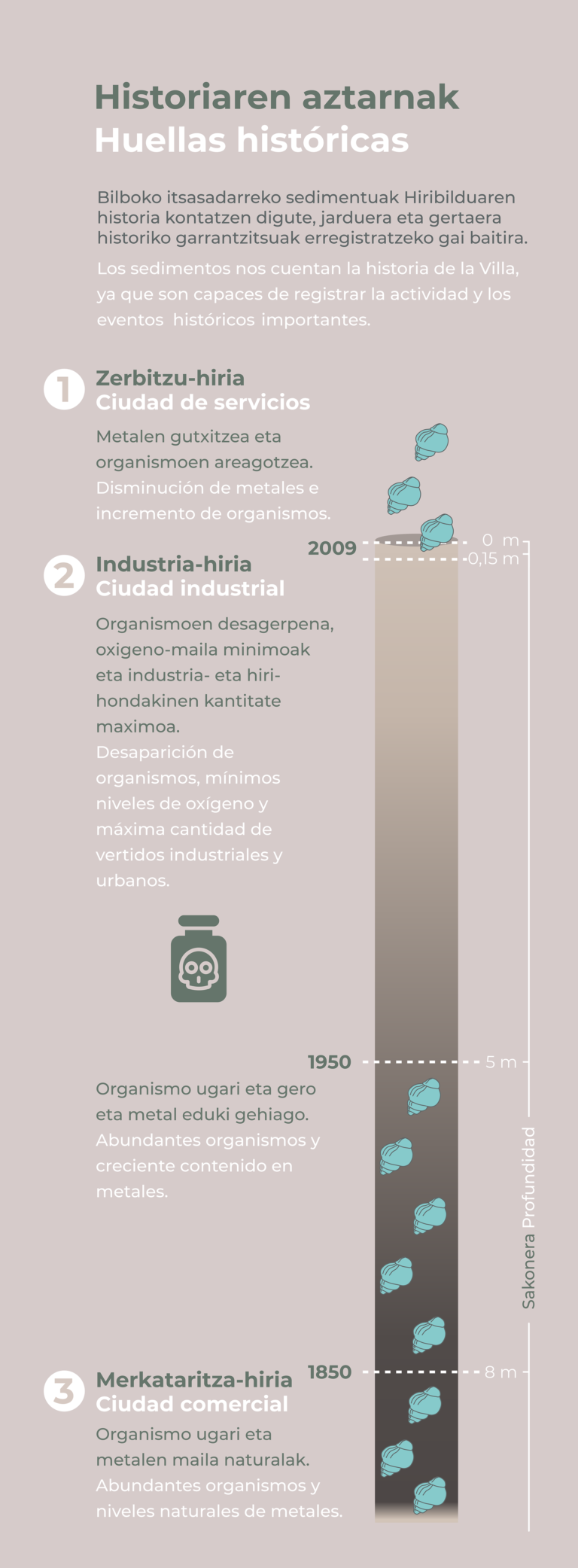 Ilustración 2: los sedimentos de la Ría dan cuenta de las distintas etapas de desarrollo de la ciudad de Bilbao. (Ilustración: NorArte Studio)
Ilustración 2: los sedimentos de la Ría dan cuenta de las distintas etapas de desarrollo de la ciudad de Bilbao. (Ilustración: NorArte Studio)Sin embargo, durante los años 1980 y 1990 se produjo una disminución significativa en el aporte de materia orgánica y contaminantes debido a la puesta en marcha de políticas de protección ambiental, el cierre de fábricas importantes y la mejora de los sistemas de tratamiento de vertidos, con un plan institucional de saneamiento integral que comenzó en 1984. Los programas de monitorización a largo plazo confirmaron mejoras considerables en las características del agua, la calidad de los sedimentos superficiales y los parámetros ambientales. Adicionalmente, se produjo una disminución general en las concentraciones de metales desde 1997 a 2003, gracias a la reducción de fuentes contaminantes y la implementación del tratamiento biológico en la planta depuradora de Galindo desde 2001.
A pesar de esta mejora, en 2003 la mayor parte de la Ría aún presentaba condiciones adversas para la biota. Desde el año 2009, en cambio, la abundancia de organismos experimentó un notable crecimiento y su colonización se trasladó desde los tramos inferiores a las zonas superiores del estuario. Para 2014, toda la Ría contenía un número moderado de especies vivas.
Por encima de la capa industrial que existía en el año 2003, actualmente encontramos densidades significativas de organismos y niveles mejorados (aunque variables) de metales. A principios del siglo XXI, los cambios socioeconómicos obligaron a la transición desde una economía industrial a una economía de servicios, y las medidas de reducción de la contaminación por aguas residuales fueron clave para su recuperación biológica. Las condiciones ambientales originales aún están lejos de alcanzarse, pero esta capa superior de sedimentos puede definirse como una nueva «zona post-industrial».
En la ría de Bilbao los procesos de mejora ambiental en curso coexisten con una herencia negativa que perdura en forma de grandes cantidades de contaminantes enterrados en sus sedimentos. Aunque algunos cambios son irreversibles (por ejemplo, la pérdida de los ecosistemas originales del estuario por su ocupación urbana e industrial), otros factores, como la calidad geoquímica de las aguas y sedimentos, y el desarrollo de comunidades biológicas, han comenzado a progresar. Un seguimiento regular de la evolución de estas nuevas capas sedimentarias que se están depositando proporcionará información útil para tomar decisiones correctas sobre su gestión ambiental y ayudará a mantener el frágil equilibrio entre su regeneración y las actividades humanas.
Sobre los autores: Alejandro Cearreta es profesor e investigador del Departamento de Estratigrafía y Paleontología de la UPV/EHU y María Jesús Irabien es profesora e investigadora del Departamento de Mineralogía y Petrología de la UPV/EHU.
El proyecto «Ibaizabal Itsasadarra zientziak eta teknologiak ikusita / La Ría del Nervión a vista de ciencia y tecnología» comenzó con una serie de infografías que presentan la Ría del Nervión y su entorno metropolitano vistos con los ojos de la ciencia y la tecnología. De ese proyecto han surgido una serie de vídeos y artículos con el objetivo no solo de conocer cosas interesantes sobre la ría de Bilbao y su entorno, sino también de ilustrar como la cultura científica permite alcanzar una comprensión más completa del entorno.
El artículo ¿Qué esconden los sedimentos de la Ría? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Geología, industrialización y transporte del mineral de hierro en el entorno de la Ría de Bilbao
- Los sedimentos fluviales, una reserva dinámica de metales contaminantes
- Ox Bel Ha, un ecosistema tropical alimentado por metano
Historias de la malaria: La guerra y la historia
«Quizás sea un duro golpe para el amor propio de nuestra especie pensar que los humildes mosquitos y los virus sin cerebro pueden condicionar nuestros asuntos internacionales. Pero pueden.”
John R. McNeill, Ecology and war in the Greater Caribbean, 1620-1914, 2010.
“Estamos en guerra con los mosquitos … De media, el número anual de muertes es de unos dos millones … se calcula que la mitad de todos los humanos que han vivido hasta ahora han muerto por los mosquitos”.
Timothy Winegard, El mosquito, 2019.
“Los hombres hacen su propia historia, pero no la hacen a su libre arbitrio, bajo circunstancias elegidas por ellos mismos, sino bajo aquellas circunstancias con que se encuentran directamente, que existen y les han sido legadas por el pasado”.
Karl Marx, El Dieciocho Brumario de Luis Bonaparte, 1852.
“Creemos que hacemos la historia, pero es la historia la que nos hace a nosotros”.
Martin Luther King.
La historia de la malaria está ligada a la historia de los países, sobre todo a sus crónicas militares. O viceversa, y es la historia de los países la que está condicionada por las enfermedades y, en este caso, por la malaria. Poco dicen los historiadores de “la obra de los invisibles”, como la llama Wilhelm von Drigalski. Esa “obra” difundió, casi más que otros poderes más conocidos, el terror, el miedo, la muerte, la devastación y la ruina. Aunque todavía se ignora mucho de cómo lo conseguían “los invisibles”, es evidente su importancia en el transcurrir de la historia de la humanidad. El plasmodio de la malaria fue, y todavía lo es en muchas zonas del planeta, un actor histórico inadvertido, sobre todo en las áreas rurales. Nuestra historia, la de la especie humana, es un juego complicado con guerras, política, viajes, comercio y enfermedades.
Además, para los occidentales, la colonización de los trópicos por los países europeos cambió su ecología. Tal como ocurrió cuando apareció la agricultura, la tala de los bosques tropicales para el desarrollo de plantaciones mejoró las condiciones ambientales para la alimentación y reproducción de mosquitos y, en consecuencia, para la extensión de la malaria. La enfermedad se convirtió en un factor importante en las luchas geopolíticas por las colonias cercanas al trópico.
En África occidental se seleccionó una adaptación genética, la anemia falciforme, con glóbulos rojos defectuosos y menos receptivos al plasmodio de la malaria. Los pueblos agricultores bantúes, con esta mutación, se extendieron por el centro, el este y el sur de África. Vivían en comunidades estables, a diferencia del movimiento continuo de los cazadores recolectores. La malaria, sobre todo con el Plasmodium falciparum, mataba regularmente a sus niños y, ocasionalmente, también a las madres. Pero los que sobrevivían adquirían una cierta inmunidad y, de adultos, podían salir adelante. Así, los pueblos bantúes comenzaron su expansión, hace unos 7000 años, y, 700 años después apareció la mutación de la anemia falciforme. Se calcula que la tasa de mortalidad cayó hasta un 55%. Y los bantúes llegaron al Índico en África oriental, y hacia el sur hasta Sudáfrica. Además, ayudaron las armas de hierro que utilizaban en la guerra. Y, también, la agricultura del ñame que, incluso, inhibe la reproducción del plasmodio de la malaria en la sangre. Los pocos pueblos que quedan y no hablan dialectos de origen bantú, ocupan entornos marginales, más duros y pobres y, además, son marginados sociales.
La Organización Mundial de la Salud (OMS) declaró que la guerra es una “emergencia compleja” que crea las condiciones ideales para mosquitos y plasmodios. La guerra, según la OMS, es incompatible con los avances en el control de la malaria.
 «Lord Byron en su lecho de muerte» de Joseph Denis Odevaere (c. 1826). Óleo sobre lienzo, 166 × 234,5 cm. Groeningemuseum, Brujas. Fuente: Wikimedia Commons
«Lord Byron en su lecho de muerte» de Joseph Denis Odevaere (c. 1826). Óleo sobre lienzo, 166 × 234,5 cm. Groeningemuseum, Brujas. Fuente: Wikimedia Commons
Hay evidencias de malaria en algunos restos óseos de hace 9000 años recuperados en Catalhuyuk, en la actual Turquía. El faraón Tutankamon murió de malaria hace unos 3500 años. La malaria atacó a los galos cuando sitiaban Roma en el siglo IV antes de nuestra era, aunque tomaron la ciudad. La enfermedad atacó a las expediciones militares contra Roma del emperador Lotario y de Federico Barbarroja en la Edad Media, en los siglos IX y XII. La expedición portuguesa que subió el río Zambeze, en el sur de África, en 1569, murió casi en su totalidad por las enfermedades. En el siglo XVIII golpeó a los ejércitos ingleses en los Países Bajos. Lord Byron murió de malaria en 1824 cuando luchaba con los griegos por su independencia del Imperio Otomano. Murieron 88 de los 108 europeos de la expedición a Gambia de 1825. Y en 1865, al terminar la Guerra de Secesión de Estados Unidos, las tropas de la Unión tuvieron 1.3 millones de casos de malaria con unas 10000 bajas. En la expedición al río Níger en 1841 enfermó el 80% de los componentes. Las campañas para la colonización, por Francia, de Argelia y Madagascar, durante el siglo XIX fueron un paseo militar y un desastre sanitario. En conclusión, el significado estratégico de la malaria es conocido desde hace cientos de años.
Y, también, la muerte por malaria de dirigentes e intelectuales. Por ejemplo, los emperadores romanos Vespasiano, Tito, Adriano y Constantino, entre el siglo I y el IV; Alarico, rey de los visigodos; los Papas Gregorio V y Sixto V, en el siglo X y el XVI; el emperador de Bizancio Alexius I; o Dante y Petrarca en los siglos XIII y XIV.
La Segunda Guerra Púnica, entre Roma y Cartago, terminó con la derrota de Aníbal en Zama en el año 202 antes de nuestra era. Su ejército estaba debilitado por la malaria contraída en las Marismas Pontinas, junto a Roma, una de sus mejores defensas, peligrosa incluso para los propios romanos, durante siglos. Por allí pasaron con sus ejército, y sufrieron o utilizaron la malaria como defensa, desde Julio César a Napoleón. Incluso, en la Segunda Guerra Mundial, cuando los aliados invadieron Italia y se acercaban a la capital contrajeron la malaria provocada por los alemanes. La malaria de las Marismas Pontinas destruyó ejércitos invasores durante siglos.
En el siglo XVIII cambió la historia de Inglaterra por la malaria. Oliver Cromwell inició la llamada Revolución Inglesa, derrotó a Carlos I, que fue ejecutado en 1649, e instauró la República. En 1653, se nombró Lord Protector de Inglaterra y acaparó el poder que había tenido el decapitado rey Carlos I. Pero, un lustro después, en 1658, Cromwell sufrió “calenturas”, o sea, fiebres causadas por la malaria. No quiso medicarse con quina, el llamado “polvo de los jesuitas”, y el único remedio conocido entonces. Era un protestante fanático, y los prejuicios antipapistas no le dejaron utilizar la quina. Cromwell murió aquel año de 1658. Desapareció la República, la corona fue a Carlos II, hijo de Carlos II, y volvió la monarquía a Inglaterra.
A finales del siglo XVIII, después de la Revolución Francesa, el ejército de Napoleón desembarcó en Alejandría y, desde Egipto, emprendió la campaña para llegar a Siria. En San Juan de Acre, cerca de la actual Haifa, en Israel, era un ejército diezmado por la malaria. Solo quedaban 8000 hombres de los más de 40000 que habían llegado a Egipto. Napoleón retrocedió hasta El Cairo.
La malaria fue un adversario no esperado en la Primera Guerra Mundial. Atacó ejércitos y civiles, y los movimientos de personas, militares o no, extendieron la enfermedad por todo el continente. Hubo enfermos en el sudeste de Inglaterra, en el centro de Italia, en el sur de los Balcanes y, en concreto, en Albania, Macedonia y Grecia. Y en Oriente Próximo, desde Egipto hasta Georgia y de Turquía a Irán. Eran áreas endémicas de la enfermedad desde Inglaterra a Irán y en el centro y el este del Mediterráneo.
Según las estadísticas militares de la época, los casos de malaria en los ejércitos aliados superaron los 600000, con casi 4000 fallecidos. Entre los alemanes y sus aliados, el número de casos superó los 500000 con más de 23000 muertes. Además, los soldados con malaria estaban debilitados y, si eran heridos en el combate, sucumbían con facilidad. En el frente occidental, la malaria no fue tan importante como en Grecia y el Oriente Próximo, con ejemplos como Macedonia donde eran 300 enfermos por cada mil, o en el ejército otomano y en los alemanes estacionados en Turquía.
 Militares estadounidenses rastrean la selva en la Guayana Holandesa en 1942. Fuente.
Militares estadounidenses rastrean la selva en la Guayana Holandesa en 1942. Fuente.En oriente, la armada francesa tuvo el 50% de sus hombres con malaria y provocó 20000 repatriaciones. En aquellos años, en 1917, y por el empuje de Lawrence de Arabia, el general Allenby y el ejército británico tomaron Jerusalén y se dirigieron al valle del Jordán para cruzar el río y llegar a Damasco. Pero el valle era cálido y húmedo, lleno de mosquitos y un hábitat perfecto para la malaria endémica. Los soldados cayeron enfermos y tuvieron que ser evacuados a Jerusalén. Murieron por miles.
Muy al norte de Palestina, en el valle del río Struna, entre Grecia y Bulgaria, se estacionó el ejército del general francés Maurice Sarrail. Estaba formado por británicos, franceses e italianos. En poco tiempo, tenía 6000 enfermos de malaria de un total de 15000 hombres. Y tuvieron que ser evacuados a Salónica. Hubo momentos en que solo tenía 2000 soldados listos para el combate. Cuando le ordenaron atacar, respondió que “mi ejército está inmovilizado en los hospitales”. Una queja parecida escribió el general McArthur en la campaña de Filipinas, durante la Segunda Guerra Mundial.
En Italia, en 1914, al comienzo de la guerra, las estadísticas sobre la malaria eran de 57 fallecidos por millón de habitantes. En 1918, al final de la guerra, la cifra era de 325 fallecidos por millón de habitantes. Para 1923, cinco años después, fueron 61 muertos por millón de habitantes, casi la cifra de antes de la guerra.
A principios del siglo XX, entre 1911 y 1927, la guerra de España en Marruecos supuso el ataque de la malaria tanto a los reclutas españoles como a la población indígena. En Melilla, casi toda la guarnición pasó, en un momento u otro, por el hospital y, para 1918, eran 2600 enfermos de más de 23000 de guarnición. En 1918, en Ceuta había casi 6000 casos de malaria en un total de 23500 militares. Cerca de Tetuán, en uno de los campamentos, hasta el 80% de los soldados estuvo afectado por la malaria cada verano. O, en otro ejemplo, un batallón con 800 soldados quedó reducido a 150, con 87 fallecidos, y tuvo que ser relevado.
En la Segunda Guerra Mundial, cerca de medio millón de soldados de Estados Unidos fueron hospitalizados con malaria. En las islas del Pacífico conquistadas por el ejército japonés, era la malaria la mejor defensa contra los aliados. En Guadalcanal, en 1942, todos los soldados de Estados Unidos tuvieron malaria. En Papua Nueva Guinea, el 70% de los soldados australianos enfermaron de malaria.
En el campo de concentración de Dachau, el profesor Claus Schilling inoculó a prisioneros con malaria. Fue ejecutado por condena del Tribunal de Nuremberg. En ese campo de Dachau se instaló el Instituto Entomológico de las Waffen-SS, creado en 1942 para estudiar la transmisión de malaria por el mosquito Anopheles, parece ser, sin confirmación escrita, para su utilización como arma biológica.
Las tropas del Vietcong llegaban a Vietnam del Sur por el llamado Camino Ho Chi Minh desde Vietnam del Norte. En 1965, de un regimiento con 1200 soldados, cuando llevaba un mes de viaje, solo 120 podían luchar. Un médico del Vietcong recordaba que “nosotros no teníamos miedo de los imperialistas americanos, solo temíamos a la malaria”.
Los artrópodos que llevan patógenos, como el plasmodio de la malaria, se ha utilizado como armas biológicas desde hace siglos. Los mongoles y las pulgas que llevan la Yersinia pestis, causa de la peste, las moscas que ensayó el Ejército Imperial del Japón para infectar Mongolia en la Segunda Guerra Mundial y, como hemos visto, las SS nazis de Alemania con sus investigaciones con mosquitos y el plasmodio de la malaria. En conclusión, malaria y guerra están unidas en la historia de nuestra especie.
Referencias:
Brabin, B.J. 2014. Malaria’s contribution to World War One – the unexpected adversary. Malaria Journal 13: 497.
Deichmann, U. 1996. Biologists under Hitler. Harvard University Press. Cambridge, Ms. 468 pp.
Gargantilla, P. 2016. Enfermedades que cambiaron la historia. La Esfera de los Libros. Madrid. 254 pp.
Jarman, N.M. & K. Ballschmiter. 2012. From coal to DDT: the history of the development of the pesticide DDT from synthetic dyes till Silent Spring. Endeavour 36: 131-142.
Kwak, M.L: 2016. Arboterrorism: Doubtful delusion or deadly danger. Journal of Bioterrorim & Biodefense DOI: 10.4172/2157-2526.100152.
Martín Sierra, F. 1998. El papel de la sanidad militar en el descubrimiento del mosquito como agente transmisor del paludismo y de la fiebre amarilla. Sanidad Militar 54: 286-296.
McNeill, J.R. 2010. Ecology and war in the Greater Caribbean, 1620-1914. Cambridge University Press. Cambrudge. 371 pp.
McNeill, W.H. 1984. Plagas y pueblos. Siglo XXI de España Eds. Madrid. 313 pp.
Molero Mesa, J. 2003. Militares, “moros” y mosquitos: el paludismo en el Protectorado Español en Marruecos (1912-1956). En “La acción médico-social contra el paludismo en la España metropolitana y colonial del siglo XX”, p. 323-380. Ed. por E. Rodríguez Ocaña et al. CSIC. Madrid.
Neghima, R. et al. 2010. Malaria, a journey in time: In search of the lost myhts and forgotten stories. American Journal of the Medical Sciences 340: 492-498.
Pagès, F. 1953. Le paludisme. P.U.F. París. 113 pp.
Peinado Lorca, M. 2019. Cómo los mosquitos ambiaron la historia de la humanidad. The Conversation 13 agosto.
Pérez Benavente, R. 2019. Una historia de mosquitos, escoceses, esclavos y nazis. Cuaderno de Cultura Científica 19 agosto.
Reinhardt, K. 2013. The Entomological Institute of the Waffen-SS: evidence for offensive biological warfare research in the Third Reich. Endeavour 37: 220-227.
Schlagenhauf, P. 2004. Malaria: prehistory to present. Infectious Disease Clinics of North America 18: 189-205.
Shah, S. 2010. The fever. How malaria has ruled humankind for 500.000 years. Picador. New York. 309 pp.
Snowden, F.M. 2006. The conquest of malaria. Italy, 1900-1962. Yale University Press. New Haven & London. 296 pp.
von Drigalski, W. 1954. Hombres contra microbios. La victoria de la humanidad sobre las grandes epidemias. Ed. Labor. Barcelona. 368 pp.
Winegard, T.C. 2019. El mosquito. La historia de la lucha de la humanidad contra su depredador más letal. Penguin Ramdon House Grupo Ed. Barcelona. 635 pp.
Sobre el autor: Eduardo Angulo es doctor en biología, profesor de biología celular de la UPV/EHU retirado y divulgador científico. Ha publicado varios libros y es autor de La biología estupenda.
El artículo Historias de la malaria: La guerra y la historia se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Historias de la malaria: Charles Louis Alphonse Laveran y el protozoo
- Historias de la malaria: Las drogas sintéticas
- Historias de la malaria: El mosquito
Catástrofe Ultravioleta #25 CUARENTENA
 Catástrofe Ultravioleta #25 CUARENTENA
Catástrofe Ultravioleta #25 CUARENTENADespués de una larga espera, vuelve Catástrofe Ultravioleta para ofrecer una tercera temporada. Lo hacemos además en Podium Podcast, la plataforma de la Cadena SER y continuamos contando con el inestimable apoyo de la Cátedra de Cultura Científica de la UPV/EHU y de la Fundación Euskampus. En este capítulo especial, grabado durante el confinamiento, hemos contado con vuestra ayuda para explicar lo que sucedió durante el parón de la actividad humana provocado por la pandemia de coronavirus y lo que visteis por la ventana.
Agradecimientos: Douglas Cardoso, Cristina Martín, Adriano y Eva Morán, Iñaki López, Céline, Miguel y Leo. Juan López Medrano , Sergio de Mayorga, Luis de Barcelona, Varyn, María de Málaga.
El artículo Catástrofe Ultravioleta #25 CUARENTENA se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Preparados para una Catástrofe Ultravioleta
- Catástrofe Ultravioleta #03 Interferencias
- Catástrofe Ultravioleta #13 LEVIATÁN
Saturno tiene el sistema de nieblas en capas más extenso observado en el Sistema Solar
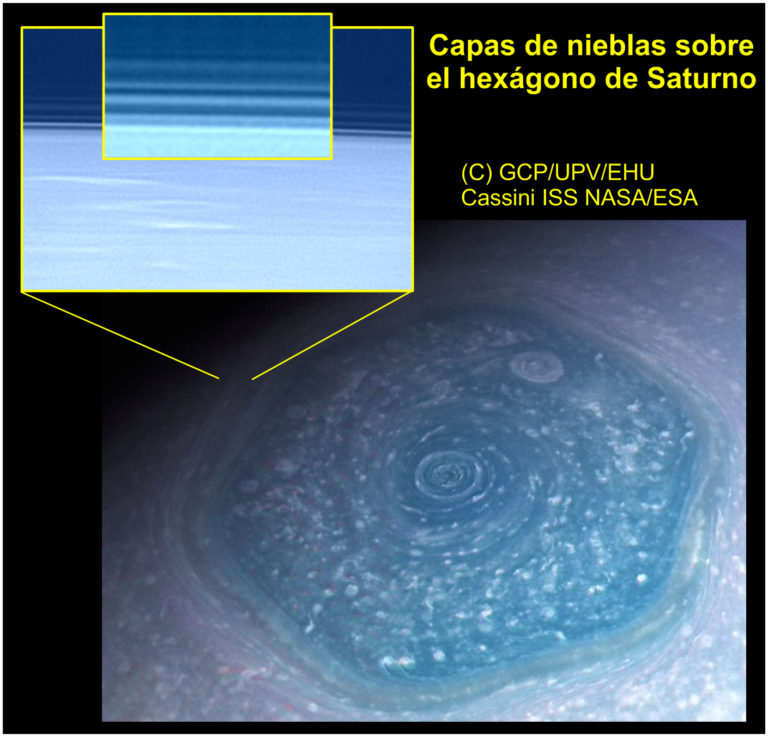
En la extensa atmósfera de hidrógeno del planeta Saturno, un mundo gigante, con unas diez veces el tamaño de la Tierra, se desarrollan fenómenos meteorológicos muy diversos cuyo estudio nos permite comprender mejor los de la atmósfera terrestre. Entre ellos destaca por su singularidad el conocido “hexágono”, una estructura ondulante que rodea a la región polar norte del planeta cuya forma parecería haber sido trazada por un geómetra.
Descubierta en 1980 por las naves espaciales Voyager 1 y 2 de la NASA, ha sido observada ininterrumpidamente desde entonces, a pesar del intenso y largo ciclo de estaciones del planeta. Por el interior de esta gigantesca onda planetaria fluye una estrecha y rápida corriente en chorro en donde los vientos alcanzan velocidades máximas de unos 400 km/hora. Mientras, curiosamente, la onda en sí misma permanece casi estática; es decir, apenas se desplaza con respecto a la rotación del planeta. Todas estas propiedades hacen que el “hexágono” sea un fenómeno altamente atractivo para los meteorólogos e investigadores de las atmósferas de los planetas.
La nave Cassini, que estuvo en órbita del planeta entre los años 2004 y 2017, tomó una inmensa cantidad de imágenes desde muy variadas distancias al planeta y ángulos de visión. En junio del año 2015, su cámara principal obtuvo imágenes del limbo del planeta a muy alta resolución, capaces de resolver detalles de 1-2 km, que capturaban las nieblas situadas sobre las nubes que trazan la onda hexagonal. Además, utilizó muchos filtros de color, desde el ultravioleta hasta el infrarrojo cercano, permitiendo así estudiar la composición de estas nieblas. Como apoyo para este estudio se usaron también imágenes del Telescopio Espacial Hubble tomadas 15 días más tarde y que muestran al hexágono no en el limbo sino visto desde arriba. “Las imágenes de Cassini nos han permitido descubrir que, como si formaran un “sandwich”, el hexágono tiene un sistema multicapa de, al menos, siete neblinas que se extienden desde la cima de sus nubes hasta más de 300 km de altura sobre ellas”, ha declarado el profesor Agustín Sánchez Lavega, quien lidera el estudio. “Otros mundos fríos como el satélite Titán de Saturno o el planeta enano Plutón tienen también capas de nieblas, pero no en tal número, ni tan regularmente espaciadas”.
Cada capa de niebla tiene entre 7 y 18 kilómetros de espesor en vertical y de acuerdo con el análisis espectral contienen partículas muy pequeñas con radios del orden de 1 micra. Su composición química es exótica para nuestros estándares terrestres, ya que, debido a las bajas temperaturas en la atmósfera de Saturno, entre 120 °C y 180 °C bajo cero, pudieran estar compuestas por cristalitos de hielo de hidrocarburos como el acetileno, propino, propano, diacetileno, o incluso butano en el caso de las nieblas más altas.
Otro de los aspectos que el equipo ha estudiado es la regularidad en la distribución vertical de las nieblas. La hipótesis que proponen es que las nieblas están organizadas por la propagación vertical de ondas de gravedad que generan oscilaciones en la densidad y temperatura de la atmósfera, fenómeno bien conocido en la Tierra y otros planetas. Los investigadores plantean que es la propia dinámica del hexágono y su intensa corriente en chorro la que puede estar detrás de la formación de estas ondas de gravedad. En la Tierra también se han observado este tipo de ondas generadas por la corriente en chorro ondulante que con velocidades de 100 km/h se dirige de Oeste a Este en las latitudes medias. El fenómeno pudiera ser semejante en ambos planetas, si bien las peculiaridades de Saturno hacen que este sea un caso único en el sistema solar. Este es un aspecto que queda pendiente para futuras investigaciones.
Referencias:
A. Sánchez-Lavega, A. García-Muñoz, T. del Río-Gaztelurrutia, S. Pérez-Hoyos, J. F. Sanz-Requena, R. Hueso, S. Guerlet & J. Peralta (2020) Multilayer hazes over Saturn’s hexagon from Cassini ISS limb images Nature Communications doi: 10.1038/s41467-020-16110-1
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Saturno tiene el sistema de nieblas en capas más extenso observado en el Sistema Solar se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- A vueltas con el hexágono de Saturno
- Planeta X, en busca del inquilino invisible del sistema solar
- Día de Darwin 2020: Evolución del Sistema Solar + Teoría evolutiva y medicina
El ferrocarril metropolitano ante la COVID-19
Iván Rivera
 Cercanías entrando en la estación de Atocha, Madrid. Foto: Iván Rivera
Cercanías entrando en la estación de Atocha, Madrid. Foto: Iván RiveraLa pandemia provocada por SARS-CoV-2, el virus informal y metonímicamente conocido como coronavirus, está suponiendo un reto complejo de afrontar para una enorme cantidad de sistemas de organización y tecnológicos cuya rentabilidad, tanto social como económica, ha dependido hasta ahora de su rendimiento medido en número de personas servidas por unidad de medida temporal o de tamaño.
Entre estos sistemas destaca por méritos propios el transporte público metropolitano. Esencial para garantizar la movilidad en los entornos urbanos, el transporte público es el gran igualador de oportunidades para amplios segmentos de la población. Por ello, la respuesta de los sistemas de transporte, y en particular los ferroviarios, frente a la crisis de la epidemia de COVID-19 ha suscitado gran atención y preocupación.
Los límites del distanciamiento
Hasta ahora, ésta ha pivotado mayoritariamente en torno a medidas destinadas a aumentar el distanciamiento social. En términos prácticos, el distanciamiento social en el transporte se traduce en separación física entre usuarios: una distancia recomendada de seguridad de más de un metro [1], lo que significa que en un recinto cerrado y suponiendo una disposición óptima hexagonal y un área personal —el área físicamente ocupada por cada individuo— de 0,28 m², la densidad máxima alcanzable está por debajo de las 0,45 personas/m². Los límites físicos del recinto —mamparos, paramentos verticales— introducirían una corrección al alza en esta estimación.
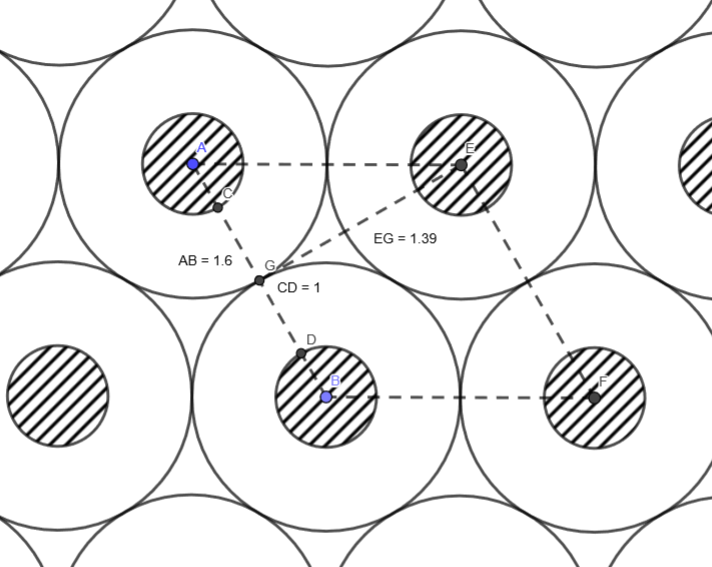 Celda unitaria del modelo de empaquetamiento óptimo para personas, considerando un espacio individual ocupado circular de radio 0,3 metros. Imagen: Iván Rivera
Celda unitaria del modelo de empaquetamiento óptimo para personas, considerando un espacio individual ocupado circular de radio 0,3 metros. Imagen: Iván RiveraLa recomendación de mantener una distancia de seguridad de un metro de distancia, emitida por la Organización Mundial de la Salud, choca con otras estimaciones superiores. El CDC (Centers for Disease Control and Prevention, Centros para el Control y la Prevención de Enfermedades) estadounidense recomienda una separación social de dos metros, lo que coincide con la recomendación del administrador de infraestructuras ferroviarias español, Adif. Recientes estudios acerca de la propagación de nubes de gotículas [2] han llegado a medir velocidades de hasta 30 metros por segundo en el estornudo, lo que establecería una cota superior para la distancia de riesgo en el rango de los 7-8 metros en la dirección frontal.
Incluso sin tener en cuenta la influencia de los estornudos en la posible propagación de patógenos, estos resultados chocan frontalmente con los cálculos de capacidad realizados por organismos reguladores como el Consorcio de Transportes de Madrid, que estima un máximo de 4 personas por metro cuadrado, o incluso con los de operadores como Metro de Madrid, que ha llegado a establecer su oferta de transporte en función de capacidades máximas de 6 personas por metro cuadrado [3].
El modelo de separación de seguridad con empaquetamiento óptimo sugiere que habría que multiplicar por nueve —en el mejor de los casos— la oferta de plazas en el momento más desfavorable, la hora punta. Aunque los sistemas ferroviarios metropolitanos han optado mayoritariamente por mantener o incluso aumentar las frecuencias de paso de los enlaces considerados estratégicos, no es posible aumentar la capacidad de transporte de una línea de metro o cercanías que esté operando cerca de su máximo de tráfico. Este viene fijado por sistemas de señalización que podrían modernizarse en algunos casos, pero nunca más allá de los máximos teóricos ofrecidos por los sistemas de bloqueo más avanzados, como CBTC o ERTMS nivel 3.
Como vemos, ampliar el espacio disponible por pasajero mediante el aumento de la capacidad de transporte es un enfoque con una potencia muy limitada para responder a las nuevas exigencias de seguridad de un mundo post-pandémico. Teniendo esto en cuenta, los gestores del transporte ferroviario han trabajado en propuestas adicionales que ha recogido la UIC (Union Internationale des Chemins de Fer, Unión Internacional de Ferrocarriles) en un documento de trabajo [4]. Estas medidas están clasificadas en tres grupos: relativas al contacto físico persona a persona, relativas al contacto objeto a persona, y de comunicación hacia los pasajeros.
Medidas propuestas por la UIC
Ya hemos visto cómo el contacto físico persona a persona es una característica definitoria de todo el transporte público, que basa su eficiencia precisamente en la compartición del espacio dedicado a la prestación del servicio. Por ello, toda medida basada en el distanciamiento social tendrá necesariamente un recorrido escaso y requerirá ser apoyada por acciones externas al propio sistema de transporte. En este sentido, la limitación de aforos en las estaciones es fundamental, pero como toda limitación de acceso, puede resultar en la denegación del servicio para una parte de los usuarios. Esto se puede paliar mediante la laminación de la hora punta, obligando a los diferentes usuarios a distribuir sus horas de entrada y salida del trabajo en un intervalo lo más amplio posible. El fomento del teletrabajo es también una medida con impacto tanto sobre el transporte público como privado que puede reducir la presión sobre los espacios compartidos.
La adopción obligatoria de mascarillas es otra de las medidas que ofrece el potencial de entorpecer los flujos de gotículas que transmiten el virus SARS-CoV-2, entre otros. Se ha observado que existe una relación entre la eficacia filtrante de la mascarilla, la frecuencia de su uso por parte de la población y el número de reproducción básico R₀ de un patógeno [5]. Esta relación hace posible que el uso de mascarillas de relativa baja eficacia, pero portadas por fracciones cercanas al total de los usuarios, resulte en una medida eficaz para permitir reducir las distancias de seguridad en espacios cerrados y, por consiguiente, aumentar los pasajeros-kilómetro transportados con un grado de seguridad epidemiológica aceptable.
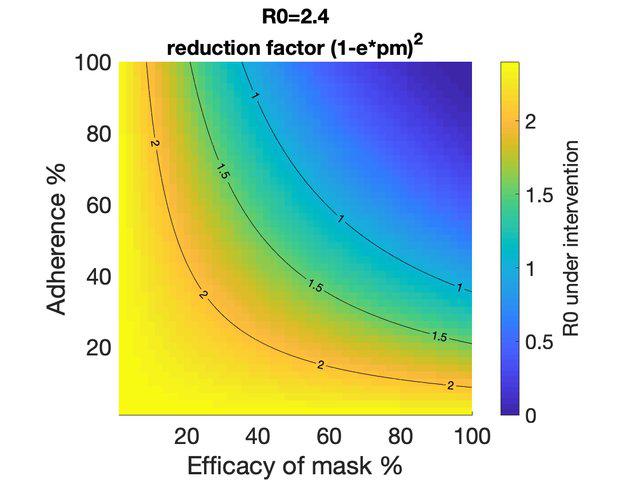 Impacto del uso de mascarillas en función de la frecuencia de su uso y su eficacia protector. El color indica el número de reproducción básico resultante (Rₒ), partiendo de un valor inicial de 2,4. Imagen tomada de [5].Otras actuaciones que pueden resultar en una mejora de la seguridad epidemiológica del transporte colectivo son la adopción de señalización específica tanto en estaciones como embarcada para recordar a los usuarios las distancias de seguridad; la disponibilidad generalizada de dispensadores automáticos de gel hidroalcohólico —si es posible, cuya operación sea sin contacto físico—; así como medidas que favorezcan la trazabilidad de los usuarios: billetes nominativos, controles masivos de temperatura mediante termografía o cuestionarios de síntomas. Este último grupo de intervenciones, sin embargo, plantea riesgos importantes en lo referente a los derechos fundamentales de privacidad de los usuarios [6]. Por ello, su implantación generalizada está llevándose a cabo en estados donde estos derechos no son reconocidos por la legislación, como China.
Impacto del uso de mascarillas en función de la frecuencia de su uso y su eficacia protector. El color indica el número de reproducción básico resultante (Rₒ), partiendo de un valor inicial de 2,4. Imagen tomada de [5].Otras actuaciones que pueden resultar en una mejora de la seguridad epidemiológica del transporte colectivo son la adopción de señalización específica tanto en estaciones como embarcada para recordar a los usuarios las distancias de seguridad; la disponibilidad generalizada de dispensadores automáticos de gel hidroalcohólico —si es posible, cuya operación sea sin contacto físico—; así como medidas que favorezcan la trazabilidad de los usuarios: billetes nominativos, controles masivos de temperatura mediante termografía o cuestionarios de síntomas. Este último grupo de intervenciones, sin embargo, plantea riesgos importantes en lo referente a los derechos fundamentales de privacidad de los usuarios [6]. Por ello, su implantación generalizada está llevándose a cabo en estados donde estos derechos no son reconocidos por la legislación, como China.
Existe, por último, la posibilidad de introducir mejoras en los sistemas de ventilación de estaciones y, sobre todo, coches de viajeros. Por ejemplo, el operador de transporte japonés Japan Rail East reporta haber incorporado nuevos protocolos de revisión más exhaustiva de los dispositivos de aire acondicionado, con limpiezas más frecuentes de los elementos filtrantes. Los ciclos de trabajo también están siendo reducidos en la medida de lo posible, renovando el aire de la cabina en intervalos menores (de 6 a 8 minutos). Por su parte, los ferrocarriles iraníes se han embarcado en un interesante proyecto para utilizar luz ultravioleta de alta frecuencia (UV-C, entre 200 y 280 nm) en componentes clave de los sistemas de ventilación. El uso de luz ultravioleta de alta frecuencia como fungicida, bactericida y viricida está avalado por la práctica en laboratorios de alta seguridad biológica [7], si bien el entorno ferroviario requerirá asegurar la ausencia de exposición de los pasajeros y los operarios a la radiación UV-C, así como dimensionar adecuadamente el sistema en función de las características del patógeno SARS-CoV-2 frente a este tratamiento.
Respecto del contacto y posible transmisión de la enfermedad entre objetos y usuarios, la UIC recomienda acortar los ciclos de limpieza y desinfección de los diferentes recintos, disponer de contenedores apropiados para desechar residuos potencialmente contaminados (como las propias mascarillas) y reducir en la medida de lo posible el contacto físico entre las manos de los pasajeros y los diferentes elementos de interacción de su entorno, como billetes —que deberán ser sustituidos por elementos sin contacto, como tarjetas o móviles con tecnología NFC— y también botones de apertura de puertas. La apertura de puertas deberá ser automática en la medida de lo posible, aunque también puede recurrirse allá donde sea una opción a su operación con partes del cuerpo distintas de la mano, como el codo, apoyándose en señalización ex profeso.
Finalmente, no debemos olvidar las medidas de comunicación. Una política abierta y clara de difusión de riesgos, reglas y consejos es fundamental para reducir la inseguridad del público respecto de sus sistemas de transporte. Para ello, todos los soportes comunicativos de los que disponen los administradores de infraestructuras del transporte y sus encomiendas de gestión deben ponerse al servicio de esta misión: megafonía, cartelería, señalética y sistemas avanzados de vídeo. Es preciso que esta comunicación pueda ser bidireccional, habilitando para ello los canales precisos en redes sociales y, presencialmente, en las mismas instalaciones a través del personal encargado del mantenimiento y seguridad, quienes deberán recibir formación específica.
Qué no hacer
La respuesta de los sistemas de transporte ferroviario a las necesidades inducidas por la pandemia de la COVID-19 tiene todavía aspectos importantes que deberán ser refinados con la práctica. No es una opción, sin embargo, prescindir del ferrocarril metropolitano como medio de transporte de alta capacidad y fomentar en su lugar el uso del automóvil privado como refugio seguro más que en casos aislados y siempre temporalmente.
Esto es así por varias razones. En primer lugar, el problema de las emisiones del transporte privado no desaparecerá mágicamente cuando la crisis de la pandemia pase. Fomentarlo acríticamente dañará los objetivos de limitación de emisiones de CO₂ y otros gases de efecto invernadero que están arrastrando las temperaturas medias del planeta en su actual curso ascendente, con las consecuencias previstas en los modelos climáticos a largo plazo y que estamos comenzando a comprobar en forma de una mayor siniestralidad debida a fenómenos atmosféricos extremos, así como la subida del nivel del mar.
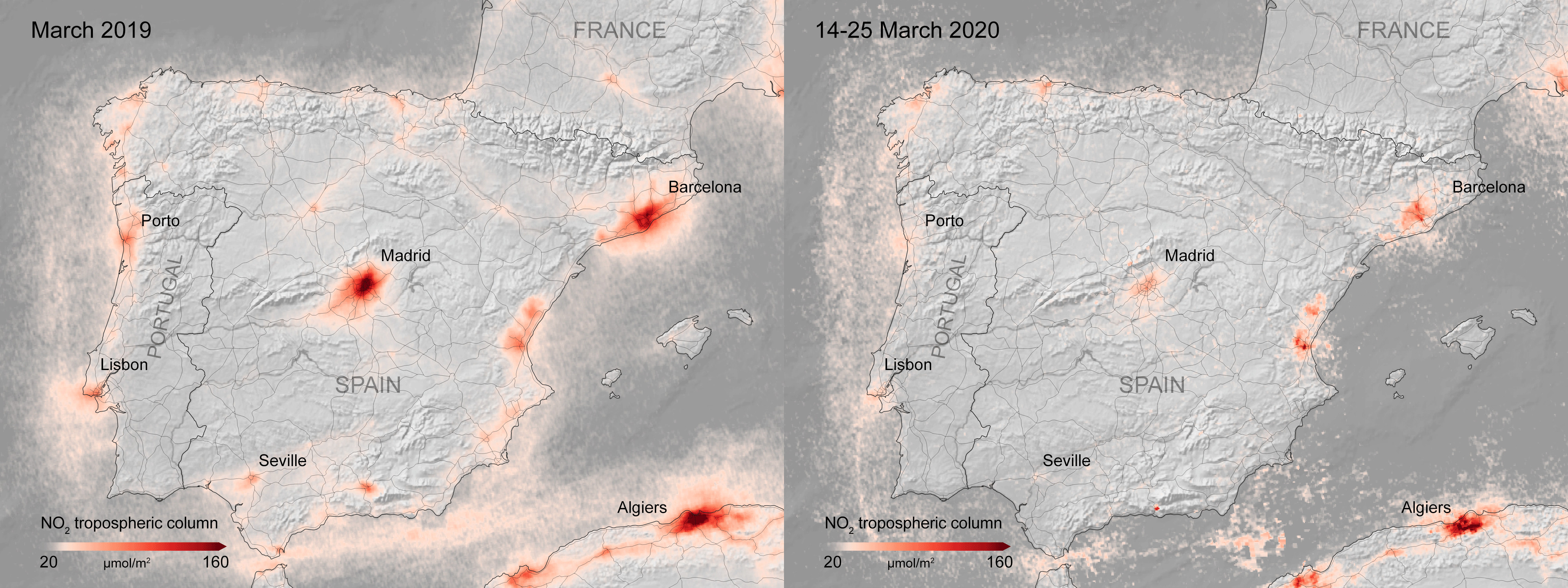 Concentraciones de la columna troposférica de NO₂ sobre la península Ibérica en marzo de 2019 y marzo de 2020. Imagen tomada de [8].En segundo lugar, la lista de contaminantes debidos al automóvil privado no finaliza con el CO₂. Los óxidos de nitrógeno y las partículas en suspensión también son relevantes para establecer la calidad del aire de los grandes núcleos urbanos. Los datos del satélite Copernicus Sentinel-5P, tratados por científicos del Real Instituto Meteorológico de los Países Bajos (KNMI) mediante filtros para eliminar la variación meteorológica intradía, muestran claramente que la disminución de la actividad industrial y del tráfico debida a las medidas de confinamiento y cierre tomadas por los diferentes gobiernos nacionales tienen un impacto inmediato sobre la atmósfera [8]. La primera fase del confinamiento en Madrid, por ejemplo, ocurrió en un contexto meteorológico de bajas temperaturas durante el que las calefacciones estuvieron mayoritariamente activas. Pese a ello, la contaminación atmosférica disminuyó considerablemente, lo que apunta a un origen mayoritario en el transporte no electrificado y en la industria. La relación de la contaminación del aire por partículas en suspensión, óxidos de nitrógeno y otros es responsable, según la literatura disponible, de un 3 % de la mortalidad anual en España, unas 10000 personas [9].
Concentraciones de la columna troposférica de NO₂ sobre la península Ibérica en marzo de 2019 y marzo de 2020. Imagen tomada de [8].En segundo lugar, la lista de contaminantes debidos al automóvil privado no finaliza con el CO₂. Los óxidos de nitrógeno y las partículas en suspensión también son relevantes para establecer la calidad del aire de los grandes núcleos urbanos. Los datos del satélite Copernicus Sentinel-5P, tratados por científicos del Real Instituto Meteorológico de los Países Bajos (KNMI) mediante filtros para eliminar la variación meteorológica intradía, muestran claramente que la disminución de la actividad industrial y del tráfico debida a las medidas de confinamiento y cierre tomadas por los diferentes gobiernos nacionales tienen un impacto inmediato sobre la atmósfera [8]. La primera fase del confinamiento en Madrid, por ejemplo, ocurrió en un contexto meteorológico de bajas temperaturas durante el que las calefacciones estuvieron mayoritariamente activas. Pese a ello, la contaminación atmosférica disminuyó considerablemente, lo que apunta a un origen mayoritario en el transporte no electrificado y en la industria. La relación de la contaminación del aire por partículas en suspensión, óxidos de nitrógeno y otros es responsable, según la literatura disponible, de un 3 % de la mortalidad anual en España, unas 10000 personas [9].
En tercer lugar, existen resultados preliminares, pendientes de confirmación, que indican que son precisamente los altos niveles de contaminación ambiental los que correlacionan con la letalidad de la COVID-19 [10]. Serán necesarios más estudios en esta dirección para confirmar, en su caso, esta posible relación, así como para determinar los mecanismos que puedan explicarla. Parece, sin embargo, que el tan justamente denostado principio de precaución podría aquí mostrarse relevante: optar por medidas que supongan aumentos indiscriminados de la contaminación ambiental, de la que ya sabemos que tiene impactos inmediatos en la salud pulmonar de los ciudadanos, no parece lo más inteligente en plena pandemia de un patógeno nuevo que también afecta al sistema respiratorio.
El ferrocarril metropolitano se enfrenta a la ardua tarea de recuperar la confianza de millones de usuarios. Este objetivo solo podrá cumplirse afianzando la seguridad epidemiológica del entorno del transporte. Para ello, deben aplicarse con rigor aquellas todas las acciones y políticas que tengan un impacto reconocido por la comunidad científica. Pero, a la vez, es necesario redoblar esfuerzos en la investigación para probar nuevas ideas y medir el efecto de otras que, de modo concebible, puedan rendir beneficios y mejoras. Solo así los operadores de transporte ferroviario podrán mantener el ferrocarril de nuestros grandes núcleos urbanos como la opción sostenible y de futuro que, incluso en el nuevo contexto epidémico, sigue siendo.
Agradecimientos
El autor quiere agradecer su ayuda en la elaboración de este texto a Conchi Lillo, profesora titular del área de Biología Celular en la Facultad de Biología de la Universidad de Salamanca e investigadora del Instituto de Neurociencias de Castilla y León (INCYL).
Referencias:
[1] Coronavirus disease (COVID-19) advice for the public, World Health Organization. Visitado el 07/05/2020 en https://www.who.int/emergencies/diseases/novel-coronavirus-2019/advice-for-public.
[2] Bourouiba, L. (2020). Turbulent Gas Clouds and Respiratory Pathogen Emissions. Jama. doi: 10.1001/jama.2020.4756. Visitado el 07/05/2020 en https://jamanetwork.com/journals/jama/fullarticle/2763852.
[3] León, P. (11/02/2019). Metro satura sus vagones para ofertar más plazas sin aumentar los trenes. El País. Visitado el 07/05/2020 en https://elpais.com/ccaa/2019/02/10/madrid/1549808836_600403.html.
[4] Management of COVID-19 — Potential measures to restore confidence in rail travel following the COVID-19 pandemic, Union Internationale des Chemins de Fer. (04/2020). Visitado el 07/05/2020 en https://uic.org/IMG/pdf/potential_measures_to_restore_confidence.pdf.
[5] Howard, J., Huang, A., Li, Z., Tufekci, Z., Zdimal, V., Westhuizen, H.-M. V. D., … Rimoin, A. W. (04/2020). Face Masks Against COVID-19: An Evidence Review. doi: 10.20944/preprints202004.0203.v1. Visitado el 07/05/2020 en https://www.researchgate.net/publication/340603522_Face_Masks_Against_COVID-19_An_Evidence_Review.
[6] Comunicado de la AEPD en relación con la toma de temperatura por parte de comercios, centros de trabajo y otros establecimientos, Agencia Española de Protección de Datos. (30/04/2020). Visitado el 07/05/2020 en https://www.aepd.es/es/prensa-y-comunicacion/notas-de-prensa/comunicado-aepd-temperatura-establecimientos.
[7] La función de las lámparas UV-C como germicida en instalaciones de HVAC, Ingeniarg SA. (02/02/2016). Visitado el 07/05/2020 en http://www.in4geniarg.com/blog/24-la-funcion-de-las-lamparas-uv-c-como-germicida-en-instalaciones-de-hvac.
[8] Coronavirus lockdown leading to drop in pollution across Europe, European Space Agency. (2020, March 27). Visitado el 07/05/2020 en https://www.esa.int/Applications/Observing_the_Earth/Copernicus/Sentinel-5P/Coronavirus_lockdown_leading_to_drop_in_pollution_across_Europe.
[9] La contaminación del aire, protagonista del Día Mundial del Medio Ambiente: muertes prematuras evitables, Instituto de Salud Carlos III. (06/06/2019). Visitado el 07/05/2020 en https://repisalud.isciii.es/bitstream/20.500.12105/7937/1/2019_06_04_LaContaminaci%c3%b3nDelAire.pdf.
[10] Travaglio, M., Yu, Y., Popovic, R., Leal, N. S., & Martins, L. M. (04/2020). Links between air pollution and COVID-19 in England. doi: 10.1101/2020.04.16.20067405. Visitado el 07/05/2020 en https://www.medrxiv.org/content/10.1101/2020.04.16.20067405v3.
Sobre el autor: Iván Rivera (@brucknerite) es ingeniero especializado en proyectos de innovación de productos y servicios para ferrocarriles.
El artículo El ferrocarril metropolitano ante la COVID-19 se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Los límites del ferrocarril
- El electromagnetismo ante la mente matemática (1)
- El electromagnetismo ante la mente matemática (y 2)
Vida de Galileo
Quien no conoce la verdad, es sólo un zoquete. Pero quién la conoce y la llama mentira, ¡es un criminal!
Vida de Galileo, Bertold Brecht
Vida de Galileo es una obra de teatro de Bertold Brecht (1898-1956) escrita entre 1938 y 1939, durante su exilio en Dinamarca. El dramaturgo escribió otras dos versiones, una entre 1945 y 1947 –adaptada a los gustos del público estadounidense–, y la última en 1955 –la llamada «versión berlinesa»–.
Esta pieza –una biografía novelada de Galileo–se centra en los últimos años de vida del investigador. Simboliza la lucha de la verdad contra el oscurantismo; defiende el racionalismo y el espíritu científico.
SINOPSIS: En su hogar en Florencia, Galileo transmite parte de sus conocimientos a Andrea, el hijo de su casera. Cuando el científico anuncia sus descubrimientos sobre el Sistema Solar, recibe la condena de la Inquisición. Galileo debe retractarse de sus ideas temiendo la tortura y la pérdida de sus privilegios. Pero, al mismo tiempo, difunde en secreto sus descubrimientos entre sus colaboradores.
 Galileo, por Justus Sustermans. Imagen: Wikimedia Commons.
Galileo, por Justus Sustermans. Imagen: Wikimedia Commons.
Recorremos brevemente la obra a través de algunas citas extraídas de la traducción de Miguel Sáenz.
La obra comienza en 1609, en el gabinete de estudio de Galileo, que comenta a Andrea sus descubrimientos:
GALILEO. Yo predigo que, antes de que hayamos muerto, se hablará de astronomía en los mercados. Hasta los hijos de las pescaderas irán a las escuelas. Porque a los hombres de nuestras ciudades, ansiosos de novedades, les gustará que una nueva astronomía empiece a moverse sobre la Tierra. Siempre se ha dicho que los astros estaban fijos en una bóveda de cristal para que no pudieran caerse. […] Y la Tierra gira alegremente alrededor del Sol, y las pescaderas, mercaderes, príncipes y cardenales, y hasta el mismo Papa, giran con ella.
Galileo presenta su telescopio en Venecia:
GALILEO. ¡Excelencia, señorías! Como profesor de matemáticas de vuestra Universidad de Padua y director de vuestro Gran Arsenal, aquí en Venecia, siempre he considerado mi deber, no sólo el cumplir con mi alta labor docente, sino también procurar beneficios excepcionales a la República de Venecia por medio de útiles inventos. […] Hoy puedo presentaros y entregaros un instrumento totalmente nuevo, mi anteojo de larga vista o telescopio, construido en vuestro Gran Arsenal, famoso en el mundo entero, de acuerdo con los más altos principios científicos y cristianos y fruto de diecisiete años de paciente investigación de este vuestro devoto servidor. […] Ésos creen haber recibido una baratija lucrativa, pero es mucho más. Ayer enfoqué el tubo hacia la Luna.
 Galileo enseñando al dux de Venecia el uso del telescopio, por Giuseppe Bertini. Imagen: Wikimedia Commons.
Galileo enseñando al dux de Venecia el uso del telescopio, por Giuseppe Bertini. Imagen: Wikimedia Commons.
Junto a su amigo Sagredo, Galileo observa la Luna:
GALILEO. ¡No hay soportes en el Cielo, no hay nada fijo en el Universo! ¡Júpiter es otro sol! […] Lo ves no lo había visto nadie. ¡Tenían razón!
SAGREDO. ¿Quiénes? ¿Los copernicanos?
GALILEO. ¡Y el otro también!i ¡El mundo entero estaba contra ellos y ellos tenían razón! […] Sí, ¡y no que todo el gigantesco Universo, con todos sus astros, gira en torno a nuestra minúscula Tierra, como piensan todos!
SAGREDO. ¡Es decir, que sólo hay astros!… ¿Y dónde está Dios? […]
GALILEO. ¿Soy teólogo acaso? Soy matemático. […] ¡Tengo fe en los hombres, lo que quiere decir que tengo fe en su razón!
En la corte de Florencia, Galileo no consigue convencer a los científicos de la utilidad de las observaciones realizadas con su telescopio:
EL FILÓSOFO. […] Señor Galilei, antes de utilizar su famoso tubo quisiéramos tener el placer de una discusión. Tema: ¿pueden existir esos planetas?
EL MATEMÁTICO. Una discusión en regla.
GALILEO. Yo había pensado que miraran simplemente por el anteojo y se convencieran. […]
EL MATEMÁTICO. Claro, claro… Naturalmente, usted sabe que, según la opinión de los antiguos, no es posible que existan estrellas que giren en torno a otro centro que no sea la Tierra, ni que no su apoyo en el Cielo. […] Se sentiría la tentación de responder que su anteojo, al mostrar lo que no puede ser, no es muy de fiar, ¿no? […] Sería mucho más provechoso, señor Galilei, que nos diera las razones que le inducen a suponer que, en las más altas esferas del Cielo inmutables, los astros pueden moverse libremente.
EL FILÓSOFO. ¡Razones, señor Galilei, razones!
GALILEO. ¿Razones? ¿Cuándo una ojeada a las propias estrellas y a mis anotaciones demuestran el fenómeno? Señor mío, la discusión me parece de mal gusto.
En 1616 el colegio romano confirma los descubrimientos de Galileo:
EL PEQUEÑO MONJE. Señor Galilei, el padre Clavius dijo antes de irse: ¡ahora tendrán que ver los teólogos cómo recomponen las esferas celestes! Usted ha vencido.
GALILEO. ¡Ha vencido! ¡No yo, sino la razón!
Pero la Inquisición rechaza sus teorías:
PRIMER SECRETARIO. El Santo Oficio ha decidido la pasada noche que la teoría de Copérnico, según la cual el Sol es el centro del Universo y está inmóvil, y la Tierra no es el centro del Universo y se mueve, es demencial, absurda y herética. Se me ha encargado que le exhorte a renunciar a esa opinión.
GALILEO. […] ¿Y los hechos? Creí entender que los astrónomos del Collegium Romanum reconocieron la exactitud de mis anotaciones. […] Pero los satélites de Júpiter, las fases de Venus…
BELLARMINO. La Santa Congregación ha tomado su decisión sin tener en cuenta esos detalles.
GALILEO. Eso significa que toda investigación científica ulterior…
 Galileo ante el Santo Oficio, por Cristiano Banti. Imagen: Wikimedia Commons.
Galileo ante el Santo Oficio, por Cristiano Banti. Imagen: Wikimedia Commons.
Galileo conversa con un monje, que explica los motivos por los que ha abandonado el estudio de la Astronomía:
EL PEQUEÑO MONJE. He conseguido penetrar en la sabiduría de ese decreto. Me ha descubierto los peligros que encierra para la Humanidad una investigación sin freno, y he decidido renunciar a la Astronomía. […] ¿Qué dirían los míos si yo les dijera que se encuentran en un pequeño conglomerado rocoso, que gira incesantemente en el espacio vacío y se mueve en torno a otro astro, uno de muchos, bastante insignificante? […]
GALILEO: ¡Cómo puede suponer nadie que la suma de los ángulos de un triángulo pueda contradecir sus necesidades! Pero si no se movilizan y aprenden a pensar, ni los más hermosos sistemas de riego les servirán para nada.
La llegada de un nuevo Papa, Urbano VIII, anima a Galileo a volver a investigar:
GALILEO. Empecemos a observar por nuestra cuenta y riesgo esas manchas solares que nos interesan. […] Mi intención no es demostrar que he tenido razón hasta ahora, sino saber si realmente la he tenido. […] Quizá sean vapores, quizá sean manchas, pero antes de suponer que son manchas, lo que nos vendría muy bien, supondremos que son colas de pez. Efectivamente, lo pondremos en duda todo, todo otra vez. […]. Y lo que hoy encontremos, lo borraremos mañana de la pizarra y sólo volveremos a anotarlo cuando lo encontremos de nuevo. […]. ¡Quitad el paño al anteojo y apuntadlo a Sol!
Molestos por los panfletos contra la Biblia difundidos por el pueblo, los inquisidores culpan a Galileo. El Papa es un hombre ilustrado, pero no tiene poder contra la Inquisición:
EL PAPA. ¡No haré que se rompan las tablas de cálculo! ¡No!
EL INQUISIDOR. […] Es la inquietud de sus propios cerebros la que aplican a la Tierra, a esta Tierra inmóvil. Y gritan: ¡Los números hablan! ¿Pero de dónde vienen esos números? Todo el mundo sabe que vienen de la duda. […] Y entonces van esos gusanos de matemáticos y apuntan sus anteojos al cielo y comunican al mundo que también allí, en el único lugar que no se os discutía, la posición es difícil.
El 22 de junio de 1633, Galileo se retracta de su teoría sobre el movimiento de la Tierra, ante la desilusión, entre otros, de Andrea:
ANDREA. Lo matarán. No terminará de escribir los “Discorsi” […] Porque no se retractará jamás. […] ¡No se atreverán! Y aunque lo hicieran, no se retractará. “Quien no conoce la verdad, es sólo un zoquete. Pero quién la conoce y la llama mentira, ¡es un criminal! […]
VOZ DEL PREGONERO. “Yo Galileo Galilei, profesor de Matemáticas y de Física en Florencia, abjuro de lo que he enseñado: que el Sol es el centro del mundo y que está inmóvil en su lugar, y que la Tierra no es el centro y no está inmóvil. Abjuro, maldigo y abomino, con corazón sincero y fe no fingida, de todos esos errores y herejías, así como de cualquier otro error y cualquier otra opinión contrarios a la Santa Iglesia”. […]
ANDREA: ¡Pobre del país que no tiene héroes! […] ¡Tonel de vino! ¡Devorador de caracoles! ¿Has salvado tu querido pellejo? […]
GALILEO. No. Pobre del país que necesita héroes.
 Portada de los Discorsi. Imagen: Wikimedia Commons.
Portada de los Discorsi. Imagen: Wikimedia Commons.
Desde 1633 hasta su muerte en 1642, Galileo vive en una casa cerca de Florencia, prisionero de la Inquisición. Recibe la visita de Andrea, que ya es un hombre de mediana edad, y se dirige a Holanda para trabajar en ciencia:
GALILEO. He terminado los “Discorsi”.
ANDREA. ¿Qué? ¿Los “Discursos sobre dos nuevas ciencias: la Mecánica y las leyes de la gravitación”? […] “Mi propósito es presentar una ciencia muy nueva sobre un tema muy viejo: el movimiento. Por medio de experimentos he descubierto algunas de sus propiedades, que son dignas de ser conocidas.” […] ¡Y nosotros que pensábamos que había desertado! ¡Mi voz fue la que más alto se alzó contra usted!
GALILEO. […] Yo sostengo que el único objetivo de la Ciencia es aliviar las fatigas de la existencia humana. Si los científicos, intimidados por los poderosos egoístas, se contentan por acumular Ciencia por la Ciencia misma, se la mutilará, y vuestras nuevas máquinas significarán sólo nuevos sufrimientos. […] Si yo hubiera resistido, los hombres dedicados a las ciencias naturales hubieran podido desarrollar algo así como el juramento de Hipócrates de los médicos: ¡la promesa de utilizar la Ciencia únicamente en beneficio de la Humanidad! […]
Andrea sale de Italia en 1937, con el manuscrito de Galileo:
EL GUARDIA. ¿Por qué deja usted Italia?
ANDREA. Soy científico.
Nota:
i Se refiere a Giordano Bruno.
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Vida de Galileo se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- 42, la respuesta definitiva a la vida, el universo y todo lo demás
- Galileo vs. Iglesia Católica redux (y VII): Balanzas
- Galileo vs. Iglesia Católica redux (V): Reconvención
Impurezas dopantes
 Es equivalente decir que las burbujas de aire suben como que el agua baja. Foto: Martin Str / Pixabay
Es equivalente decir que las burbujas de aire suben como que el agua baja. Foto: Martin Str / PixabayEl uso más importante de los semiconductores, como el silicio o el germanio, incluido su uso como transistores, surge de su comportamiento cuando, después de estar suficientemente purificados de átomos distintos del elemento básico (esto es, silicio o germanio), se introducen cantidades muy pequeñas de impurezas muy concretas.
Si bien los métodos para purificar primero y agregar pequeñas cantidades de impurezas después al germanio estuvieron disponibles tras la Segunda Guerra Mundial, la investigación sobre la purificación y la introducción controlada de impurezas para el silicio no tuvo éxito hasta finales de la década de 1950. Como el silicio es más abundante que el germanio y otros semiconductores, pronto reemplazó al germanio como el semiconductor preferido.
El germanio (elemento 32) y el silicio (elemento 14) tienen ambos cuatro electrones de valencia, que llenan la banda de valencia cuando estos metales forman un cristal. El elemento 33, el arsénico, tiene cinco electrones de valencia, al igual que el elemento 15, el fósforo. Si se agrega una cantidad muy pequeña de arsénico al germanio a medida que se forma el cristal de germanio, los átomos de arsénico sustituirán a varios átomos de germanio en la red. Lo mismo sucede cuando se agrega una pequeña cantidad de fósforo al silicio. Las pequeñas cantidades se controlan cuidadosamente en el proceso de producción y son solo alrededor del 0,0001% del total de átomos.
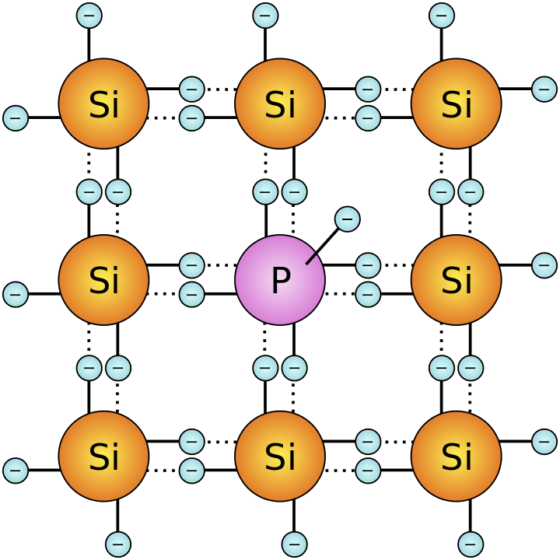 Fuente: Wikimedia Commons
Fuente: Wikimedia CommonsEste proceso se llama dopaje, y las impurezas se llaman dopantes. Cuando el dopante correspondiente se introduce en la red de germanio o silicio, cuatro de sus electrones de valencia se unen a los otros átomos en la red, dejando el quinto electrón ”suelto”. Estos electrones de valencia extra de los dopantes están tan ligeramente unidos a sus átomos que con muy poca energía de vibración saltan a la banda de conducción del semiconductor. Tanto es así que, a temperatura ambiente, todos se encuentran en la banda de conducción, lo que significa que el semiconductor dopado ahora actúa como un conductor. Dado que los electrones, que tienen carga negativa, donados por las impurezas permiten que el material conduzca, estos tipos de semiconductores se denominan semiconductores de tipo n.
Una situación similar ocurre cuando los semiconductores se dopan con impurezas de elementos que están un peldaño más abajo en la tabla periódica, es decir, cuando el silicio (14) se dopa con el elemento 13, aluminio, y el germanio (32) se dopa con el elemento 31, galio. Los dopantes tienen solo tres electrones de valencia. Eso hace que, cuando están incorporados a la red de silicio o germanio, generen un espacio en la banda de valencia, un espacio que puede aceptar un electrón de un átomo de silicio o germanio vecino. Este espacio es lo que se conoce como hueco [1]. El hueco se comporta de manera similar a una burbuja de aire en un vaso de agua con gas [2].
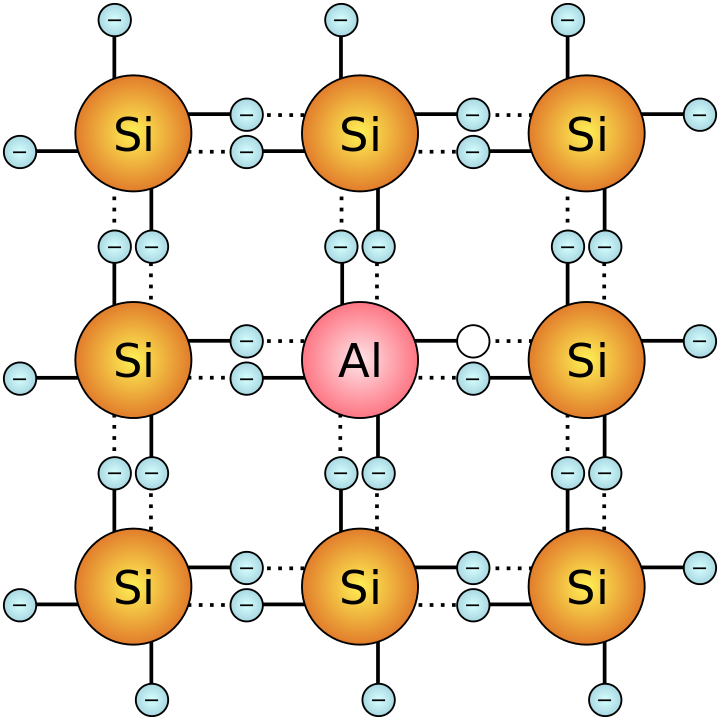 Fuente: Wikimedia Commons
Fuente: Wikimedia CommonsCuando se activa un campo eléctrico externo, los electrones de los átomos vecinos, que normalmente no tienen lugar al que moverse, ahora pueden cambiar de átomo para llenar el hueco. Pero esto deja un hueco en el átomo que han dejado, que puede ser llenado por su vecino, y así sucesivamente. Del mismo modo, el movimiento ascendente de la burbuja de aire en un vaso de agua con gas en realidad implica el flujo descendente del agua hacia el espacio ocupado por la burbuja, que es la que a simple vista parece la única en moverse. En el semiconductor, si el campo mueve los electrones a la izquierda, por ejemplo, el hueco parecerá migrar a la derecha. Al moverse hacia la derecha, se comporta como lo haría una carga positiva, aunque solo sea un espacio.
Es decir, debido al movimiento de carga negativa hacia la izquierda, el efecto físico es el mismo que si hubiese cargas positivas fluyendo hacia la derecha (en nuestro ejemplo) en la banda de valencia, por debajo de la banda de conducción, donde anteriormente no podían fluir cargas. Una vez más, la introducción muy cuidadosa de pequeñas cantidades de impurezas ha convertido el semiconductor en un conductor. Como las cargas conductoras parecen ser positivas, estos semiconductores se conocen como semiconductores de tipo p.
Estos semiconductores dopados podrían usarse como cualquier otro conductor, pero no merece la pena, ya que podemos producir conductores como los cables de cobre de manera mucho más fácil y económica. En cambio, se reconoció durante y después de la Segunda Guerra Mundial que las aplicaciones realmente útiles de este tipo de semiconductores aparecen cuando se colocan físicamente uno al lado del otro dentro de dispositivos electrónicos.
Notas:
[1] Podría llamarse hueco, boquete, bujero u oquedad, pero no, se llama hueco de electrón.
[2] O de refresco, o de cerveza, o de champán. Captas la idea. Elegimos agua porque las alternativas no son buenas para la salud en comparación.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Impurezas dopantes se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Semiconductores
- El modelo clásico de electrones libres de Drude-Lorentz
- La teoría de bandas explica la conducción eléctrica
Geología, industrialización y transporte del mineral de hierro en el entorno de la Ría de Bilbao
 Imagen 1: la ría de Bilbao entre Portugalete y Getxo. (Fotografía: LBM1948 – bajo licencia Creative Commons Attribution-Share Alike 4.0 International. Fuente: Wikimedia Commons)
Imagen 1: la ría de Bilbao entre Portugalete y Getxo. (Fotografía: LBM1948 – bajo licencia Creative Commons Attribution-Share Alike 4.0 International. Fuente: Wikimedia Commons){kind=link}
El desarrollo económico, tecnológico y social de Bizkaia, surgido en la segunda mitad del siglo XIX y que alcanzó su máximo esplendor a finales del mismo y principios del XX, tuvo lugar como consecuencia de la suma de una serie de factores:
- Unas características geológicas muy favorables. La existencia de una importante mineralización de hierro aflorante, muy próxima a una geomorfología facilitadora de la explotación y transporte de los minerales.
- La creación de unas condiciones económicas y legislativas que impulsaron la explotación y exportación de grandes cantidades de mineral.
- La existencia de una mano de obra abundante y barata, procedente del entorno local y de regiones cercanas, que si bien trabajaron a destajo y bajo condiciones, en algunos casos infrahumanas, tuvieron también la valentía y el orgullo de organizarse en movimientos asociativos de gran valor y trascendencia social. En 1910 había unas 13.000 personas trabajando en las minas.
- El desarrollo empresarial minero, que tuvo la facilidad, oportunidad y visión de crear negocios locales, pero de ámbito económico más amplio, que a su vez generaron el desarrollo de otros sectores (bancos, compañías de seguros, siderúrgicas, de ferrocarriles, astilleros, navieras, etc…).
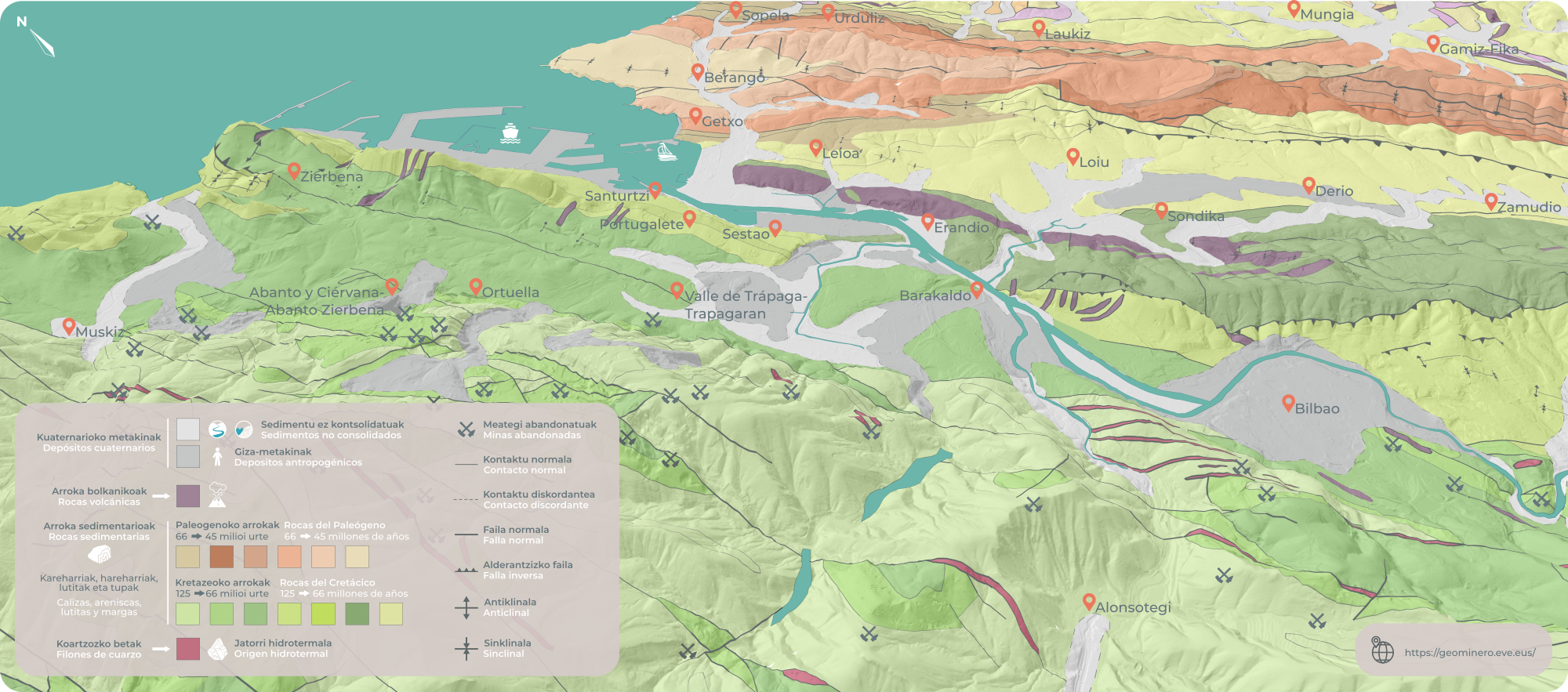 Ilustración 1: características de la geología de la ría del Nervión y sus inmediaciones. (Ilustración: NorArte Studio)
Ilustración 1: características de la geología de la ría del Nervión y sus inmediaciones. (Ilustración: NorArte Studio)Vamos a centrarnos en uno de estos factores, las características geológicas, tanto desde su vertiente de contener los yacimientos de hierro como desde la de facilitar la creación de una geomorfología adecuada para el desarrollo de los medios de transporte que sirvieron para el traslado de los minerales tanto a nivel interno como para su exportación.
El subsuelo del área que rodea la ría de Bilbao se halla compuesto mayoritariamente por rocas sedimentarias. Son el resultado de la acumulación, litificación, plegamiento y erosión de materiales detríticos y biogénicos (areniscas, lutitas, calizas, margas y margocalizas principalmente) en una cuenca sedimentaria, Cuenca Vasco-Cantábrica, que tuvo su origen en la apertura del Océano Atlántico Norte y del Golfo de Bizkaia.
Dicha cuenca ha evolucionado desde momentos con una elevada tasa de acumulación de sedimentos marinos, pasando por situaciones de erosión o de sedimentación continental, hasta terminar por recibir presiones laterales (debidas al choque y ligera rotación de las placas ibérica y euroasiática durante la Orogenia Alpina), que provocaron el plegamiento, fracturación y posterior erosión de las rocas preexistentes, hasta llegar a la situación actual.
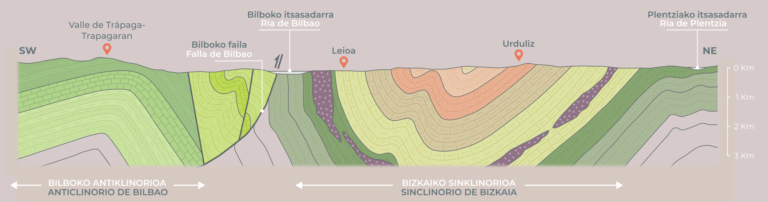 Ilustración 2: bajo el suelo del entorno de la ría de Bilbao existe una gran variedad de materiales y estructuras. Calizas, areniscas, volcánicas, lutitas y margas, así como una falla normal y otra inversa. (Ilustración: NorArte Studio)
Ilustración 2: bajo el suelo del entorno de la ría de Bilbao existe una gran variedad de materiales y estructuras. Calizas, areniscas, volcánicas, lutitas y margas, así como una falla normal y otra inversa. (Ilustración: NorArte Studio)Durante este largo proceso de evolución de la Cuenca Vasco-Cantábrica se han registrado multitud de eventos geológicos superpuestos, si bien son dos los que adquieren mayor relevancia para el tema que nos ocupa:
- La formación de los yacimientos de hierro y su enriquecimiento por oxidación.
- La creación de una geomorfología adecuada para el desarrollo del transporte fluvial.
Las mayores mineralizaciones de hierro del entorno de Bilbao se encuentran encajadas en calizas de edad Cretácico inferior (Aptiense y Albiense, entre 125 y 90 millones de años de antigüedad). Se agrupan en dos franjas más o menos paralelas que corresponden con los flancos norte y sur de una estructura anticlinal de entidad regional, el Anticlinal de Bilbao. La zona mineralizada se extiende entre las localidades de Basauri y Mioño (Cantabria).
Su génesis está sometida a diferentes interpretaciones. No todos los yacimientos pertenecen a la misma tipología, pero podrían clasificarse en dos grupos, las masivas y las filonianas.
Las masivas corresponden a reemplazamientos de las calizas. Son masas de siderita (FeCO3) albergadas en las calizas (CaCO3), con ankerita, calcita y algunos sulfuros. Los volúmenes involucrados en el reemplazamiento pueden ser muy variables. La Mina Bodovalle, en Gallarta, cerrada en 1993 tenía cubicadas 50 Mt de reservas.
 Ilustración 3: las calizas del Cretácico inferior (~125-90 millones de años), presentes en ambos flancos del Anticlinal de Bilbao, fueron enriquecidas con hierro mediante diferentes procesos de mineralización. (Ilustración: NorArte Studio)
Ilustración 3: las calizas del Cretácico inferior (~125-90 millones de años), presentes en ambos flancos del Anticlinal de Bilbao, fueron enriquecidas con hierro mediante diferentes procesos de mineralización. (Ilustración: NorArte Studio)Las filonianas son también muy abundantes. Los filones presentan orientación preferente NO-SE. Se asocian a fracturas de escala regional. Pueden presentar potencias (grosores) desde centimétricas a métricas (filones explotables). La mineralogía es similar a la que presentan las mineralizaciones masivas: siderita, cuarzo, ankerita y como minerales accesorios sulfuros.
En algún momento, cuando las calizas estaban ya sedimentadas y compactadas, o en vías de estarlo, pero no deformadas por las fases compresivas Alpinas, a favor de fracturas y planos de estratificación se introdujeron soluciones hidrotermales (calientes), salinas, clorurado-sódicas, capaces de transportar los cationes disueltos. Suministraron el hierro, produciéndose el reemplazamiento del catión Ca++ por el catión Fe++, formando siderita y ankerita. La mayor parte de los filones con mineralización representan el relleno de las propias fracturas por las que ascendieron los fluidos hidrotermales.
Durante el proceso de plegamiento, y asociado al ascenso y erosión de los sedimentos suprayacentes, las rocas mineralizadas entraron en contacto con el oxígeno ambiental generando una alteración en las zonas superficiales, lo que provocó la transformación de los minerales carbonatados (siderita principalmente), en óxidos e hidróxidos de hierro (hematites, goethita y limonita), cuyo contenido en hierro y la facilidad de su tratamiento metalúrgico es muy superior.
Durante los primeros años de explotación se produjo una doble ventaja competitiva. Por una parte los minerales más ricos en hierro (óxidos e hidróxidos) se explotaron a cielo abierto y por otra no era necesario un tratamiento previo para su incorporación a los hornos altos. En años posteriores, ya bien entrado el siglo XX, empezaron a explotarse los carbonatos, cuya extracción se producía a mayor profundidad, en muchos casos mediante minería subterránea, y además era necesario su tratamiento previo mediante hornos de calcinación para poder enriquecer su contenido en hierro y evitar problemas metalúrgicos.
El segundo de los factores decisivos para el desarrollo económico de Bizkaia, desde el punto de vista geológico, ha sido la evolución geomorfológica del subsuelo, con la creación del estuario de Bilbao, que ha actuado y sigue funcionando como puerto natural. Ya desde la Edad Media y hasta el siglo XIX, la ría actuó como eje vertebrador y comercial de los productos procedentes de Castilla, y es a mediados del siglo XIX y durante el siglo XX cuando se desarrolló la actividad económica minera y su industria asociada.
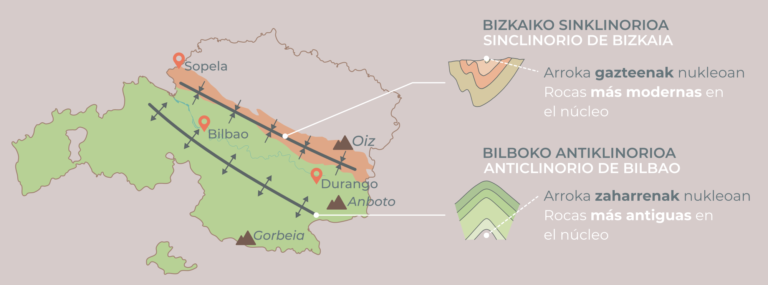 Ilustración 4: trazado de las grandes estructuras cartográficas del estuario de Bilbao, coincidentes con la dirección general del cauce fluvial. (Ilustración: NorArte Studio)
Ilustración 4: trazado de las grandes estructuras cartográficas del estuario de Bilbao, coincidentes con la dirección general del cauce fluvial. (Ilustración: NorArte Studio)Basta con observar desde una cierta distancia la morfología rectilínea y la orientación NW-SE del estuario de Bilbao para percatarse de que esta disposición no es casual. La dirección de los plegamientos principales (anticlinorio y sinclinorio) es totalmente coincidente con la dirección general del cauce fluvial. La alternancia de materiales competentes, calizas y areniscas principalmente, con sedimentos mucho más blandos, lutitas y margas, facilitó que por éstos últimos, y a favor de los accidentes estructurales principales, fallas, planos de debilidad, diaclasas, contactos estratigráficos, fluyeran las aguas que originaron el encauzamiento y redireccionaron los flujos procedentes de los cauces afluentes (Cadagua, Nervión, Ibaizabal).
Todo ello configuró un estuario que, en la zona cercana a su desembocadura, donde los ríos pierden su capacidad erosiva y el sistema se hallaba muy influenciado por los cambios mareales, se produjeron grandes acúmulos de sedimentos que originaron ecosistemas de marismas en los que los cauces fluviales pasaron de una disposición rectilínea a una meandriforme.
 Ilustración 5: ubicación de los cargaderos de mineral que existían a lo largo de la orilla de la ría de Bilbao. (Ilustración: NorArte Studio)
Ilustración 5: ubicación de los cargaderos de mineral que existían a lo largo de la orilla de la ría de Bilbao. (Ilustración: NorArte Studio)Pese a existir una magnífica red de transporte a través de los cauces fluviales, éstos tenían en muchos casos un calado insuficiente y variable en función de cada temporada o incluso eran estacionales. Fue necesario actuar para encauzar los ríos de forma artificial, asegurar su calado y permitir la construcción de cargaderos estables. Llegaron a existir decenas de cargaderos de mineral a lo largo de la margen izquierda del estuario, que representa las vías de ferrocarril que transportaban el mineral hasta los cargaderos.
Sobre el autor: Alex Franco San Sebastián es geólogo y Responsable del Área de Geología y Minería del Ente Vasco de la Energía – EVE
El proyecto «Ibaizabal Itsasadarra zientziak eta teknologiak ikusita / La Ría del Nervión a vista de ciencia y tecnología» comenzó con una serie de infografías que presentan la Ría del Nervión y su entorno metropolitano vistos con los ojos de la ciencia y la tecnología. De ese proyecto han surgido una serie de vídeos y artículos con el objetivo no solo de conocer cosas interesantes sobre la ría de Bilbao y su entorno, sino también de ilustrar como la cultura científica permite alcanzar una comprensión más completa del entorno.
El artículo Geología, industrialización y transporte del mineral de hierro en el entorno de la Ría de Bilbao se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La geología y sus superpoderes
- Naukas Bilbao está en marcha
- Geología, ver más allá de lo que pisamos
¿De qué se muere la gente en el mundo?
 Foto: Davide Ragusa / Unsplash
Foto: Davide Ragusa / UnsplashEn el mundo mueren cada año unas 56 millones (en adelante, M) de personas. La principal causa de muerte son las enfermedades cardiovasculares; por su culpa mueren casi 18 M, cerca de la tercera parte del total. Y si se agrupan en una única categoría, los cánceres son los responsables de casi 10 M de muertes. En conjunto, el 73% fallece a causa de enfermedades no contagiosas.
Los fallecimientos debidos a enfermedades infecciosas representan hoy el 19%. En ese grupo entran, sobre todo, afecciones del aparato respiratorio (2,56 M) y del digestivo (2,38 M), incluidas las diarreas (1,6 M). Hace un cuarto de siglo el porcentaje de muertes debidas a enfermedades infecciosas era del 33% y, en general, es más alto en los países pobres. La bajada del 33% al 19% es consecuencia del progreso. Cuanto más pobre es un país mayor es el porcentaje de muertes debidas a enfermedades infecciosas. Lo contrario ocurre con las no infecciosas. La otra gran categoría de muertes corresponde a las producidas por golpes o heridas, pero estas apenas varían con el tiempo y representan un 8% (9% 25 años antes).
Casi un 4% de los niños y niñas mueren antes de cumplir cinco años. En otras palabras: cada año fallecen 5,5 M. La principal causa de muerte de esas criaturas son las infecciones respiratorias (unas 800.000). De hecho, una de cada tres personas muertas por ese motivo es menor de 5 años. 650.000 bebés (menores de un mes) fallecen por patologías o complicaciones neonatales. Y las diarreas son también una causa de muerte infantil importante; aunque ha bajado mucho su número, alrededor de medio millón de niños y niñas mueren por esa razón. En conjunto estas afecciones son responsables de una gran pérdida de años de vida. También lo son los accidentes de tráfico (1,2 M de muertes, muchos de ellos de adolescentes y jóvenes), y el síndrome de inmunodeficiencia adquirida (SIDA), a causa del cual pierden la vida casi 1 M de personas (el 84% menores de 50 años). De las 800.000 personas que se quitan la vida cada año, 460.000 son menores de 50 años.
En el extremo opuesto están las distintas formas de demencia, que son responsables de 2,5 M de muertes anuales. Esa cifra ha subido mucho y seguirá subiendo conforme siga aumentando la esperanza de vida por la disminución, sobre todo, de las muertes debidas a enfermedades infecciosas. Pero precisamente por esa razón, no provoca la pérdida de muchos años de vida.
Hay tres causas de muerte que no tienen la relevancia cuantitativa de las anteriores pero que, sin embargo, reciben una gran atención mediática; son los homicidios, los atentados terroristas y las catástrofes naturales. Fallecen por homicidio unas 400.000 personas al año, y 26.000 por actos terroristas. Las catástrofes naturales solo provocan 9.600 muertes.
Cuando hablamos de causas de muerte nos referimos a las causas próximas o inmediatas, a las enfermedades que las provocan, pero como es sabido, hay hábitos o modos de vida que aumentan o disminuyen la probabilidad de contraer enfermedades que pueden resultar fatales. Cada año 8 M de personas mueren a causa del tabaco, y la obesidad es responsable de casi 5 M de muertes; en ambos casos, la mitad son menores de 70 años. Por culpa del alcohol fallecen 2,8 M (2 M son menores de 70).
Están, por último, los factores ambientales: la contaminación atmosférica provoca la muerte de 3,4 M, y la del hogar, de 1,6 M. Y es que la contaminación sí mata, la atmosférica también.
Nota: En las cifras anteriores no están incluidas las muertes debidas a Covid19. A fecha 9 de mayo, se habían producido 274.290 muertes confirmadas por esa causa, aunque la cifra real es seguramente muy superior. A modo de ejemplo, en España, los fallecimientos que constan en los registros civiles son, desde la llegada de la pandemia, del orden de un 56% más que en el mismo periodo de otros años. Es de suponer que ese exceso de muertes se debe a los efectos de Covid19, por lo que las muertes reales por esa causa representan del orden de un 30% más de las reportadas oficialmente.
Fuente: Our World in Data
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo ¿De qué se muere la gente en el mundo? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- No habrá solución sin más conocimiento
- ¿Cuánta gente ha vivido en la Tierra?
- La ecología de una enfermedad
Francisco Villatoro – Naukas Bilbao 2019: El abrazo de la plata
Tras dejar claro que es mejor integrar que derivar, esta charla «presenta el problema del año [2019]: la discrepancia a más de cinco sigmas entre la constante de Hubble calculada integrando el modelo cosmológico y extrapolando la pendiente de la escalera de distancias usando supernovas Ia y cefeidas. En la charla explico las razones que me llevan a desconfiar de la estimación astrofísica, que creo está dominada por errores sistemáticos no considerados, y preferir la estimación cosmológica, aunque esté basada en un modelo teórico.» en palabras del propio Francis Villatoro.
.
Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Francisco Villatoro – Naukas Bilbao 2019: El abrazo de la plata se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Francisco R. Villatoro – Naukas Bilbao 2018: El ángulo mágico del grafeno
- Naukas Bilbao 2017 – Francisco R. Villatoro: El espín para irreductibles
- José Ramón Alonso – Naukas Bilbao 2019: Son nuestros amos y nosotros sus esclavos
Generada en plataformas eólicas marinas, desembarcada como hidrógeno
Investigadores de la Escuela de Ingeniería de Vitoria-Gasteiz de la UPV/EHU han propuesto utilizar la energía generada en las plataformas eólicas marinas para producir hidrógeno in situ en lugar de transportarla por cable a tierra. Han demostrado que es técnicamente posible y económicamente viable. Además, han comprobado que la incorporación de ciertos elementos de muy bajo coste mejora notablemente la eficiencia de los aerogeneradores.

En las plataformas eólicas marinas, o parques eólicos offshore, la generación de energía es muy elevada, ya que se instalan aerogeneradores de gran potencia y los regímenes de viento son mucho más estables que en tierra. “Toda esta energía generada puede ser transportada a tierra mediante dos vías: la creación de una infraestructura enorme, para hacer llegar la red de potencia eléctrica hasta ella, y transportar por cable la electricidad generada, o la generación de hidrógeno allí mismo, mediante hidrólisis, utilizando la energía generada en el terreno, y el transporte de ese hidrógeno a tierra para ser utilizado como combustible. Nosotros hemos apostado por la segunda opción y el objetivo de esta investigación ha sido buscar una forma de mejorar ese proceso”, explica Ekaitz Zulueta Guerrero, investigador del Departamento de Ingeniería de Sistemas y Automática de la Escuela de Ingeniería de Vitoria-Gasteiz de la UPV/EHU.
Al poner en marcha la investigación, los investigadores, del Departamento de Ingeniería de Sistemas y Automática y del Departamento de Ingeniería Nuclear y Mecánica de Fluidos de la Escuela de Ingeniería de Vitoria-Gasteiz, buscaban reducir el coste energético del proceso de generación de hidrógeno. “Con el fin de mejorar la aerodinámica de los aerogeneradores, quisimos probar el efecto de dos componentes utilizados para controlar el flujo de la turbina. Uno es un generador de vórtices y, el otro, unas láminas (conocidas como Gurney Flaps) que se colocan en la pala, que mejoran mucho la fuerza de sustentación y, por tanto, la aerodinámica”, explica Unai Fernández-Gámiz, miembro del Departamento de Ingeniería Nuclear y Mecánica de Fluidos. Además, “son muy baratos y se colocan fácilmente en los aerogeneradores”.
En un segundo paso, quisieron ver si “es viable, tanto técnica como económicamente, la generación de hidrógeno en las propias plataformas eólicas offshore, a partir de esa energía generada, mediante hidrólisis, y así poderlo transportar a tierra para que pueda ser utilizado como combustible —añade Fernández-Gámiz—. De hecho, la generación de hidrógeno permitiría su transporte a tierra en barco y, además, la energía acumulada ofrecería una gran flexibilidad al sistema eléctrico, teniendo en cuenta que en la actualidad la producción de electricidad debe ser acorde con la demanda”.
Las pruebas se llevaron a cabo en el laboratorio nacional de energías renovables de Estados Unidos (NREL), en una turbina de 5 MW, cuyas características técnicas, geometrías y demás parámetros son públicos. “Se ha comprobado que la producción anual de energía de las turbinas es alrededor de un 2,5 % superior. No es un incremento muy elevado, pero teniendo en cuenta la gran potencia de los aerogeneradores que se instalan en el mar, se genera una gran cantidad de energía adicional”, ha explicado Zulueta. Los investigadores también han calculado la cantidad de hidrógeno que se podría producir con esta generación adicional de energía: más de 130.000 Nm3. Es decir, “la cantidad de combustible que necesitarían un millón de coches impulsados por hidrógeno para recorrer 100 kilómetros —detallan los investigadores en el artículo—. Y esto gracias a los elementos de control de flujo añadidos, que apenas implican costes adicionales”.
Una vez comprobado que técnicamente es posible y económicamente viable, el siguiente paso sería, según los investigadores, “que algún desarrollador de plataformas eólicas se pusiera en contacto con nosotros para probar, medir y adaptar en sus sistemas lo conseguido en la planta de Estados Unidos”.
Referencia:
Aitor Saenz-Aguirre, Unai Fernández-Gámiz, Ekaitz Zulueta, Iñigo Aramendia, Daniel Teso-Fz-Betoño (2020) Flow control based 5 MW wind turbine enhanced energy production for hydrogen generation cost reduction International Journal of Hydrogen Energy doi: 10.1016/j.ijhydene.2020.01.022
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Generada en plataformas eólicas marinas, desembarcada como hidrógeno se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Cómo obtener hidrógeno a partir de una placa de circuitos impresos
- Hidrógeno a partir de composites de fibra de carbono
- Un microrreactor para producir hidrógeno 100 veces más pequeño
El océano en una caracola
 Voluta musica, llamada así por los adornos de su concha similares a una partitura.
Voluta musica, llamada así por los adornos de su concha similares a una partitura.Ilustración de Charles Kiener, Louis Charles (1835). Fuente Wikimedia Commons
“Me han traído una caracola.
Dentro le canta
un mar de mapa.
Mi corazón
se llena de agua
con pececillos
de sombra y plata.
Me han traído una caracola”.
Caracola, Canciones para niños de Federico García Lorca.
En el océano hay una caracola que contiene un océano entero.
Durante generaciones, la gente creyó que al presionar una concha marina contra su oído, lo que oía era el rugido del mar. Pocos relatos de la cultura popular resultan tan evocadores y, al mismo tiempo, tan erróneos. No existe ninguna relación entre el mar y ese sonido característico, más allá de la asociación mental entre la caracola y su lugar de origen que probablemente dio lugar a este relato popular. Sin embargo, como las mejores metáforas, esta nos puede servir de excusa para explicar una historia real.
El hecho es que vivimos rodeados de olas. Son olas de aire, eso sí, pequeñas variaciones en la densidad de ese fluido en el que inadvertidamente vivimos sumergidos. Normalmente resultan inaudibles, su constante presencia hace que las ignoremos. Pero cuando acercamos una caracola a nuestro oído, estas olas empiezan a rebotar contra sus paredes rígidas y algunas de sus frecuencias llegan a nuestro tímpano amplificadas. El cambio de color nos hace reparar en un sonido que hasta entonces había pasado desapercibido. La caracola nos revela la rugosidad de nuestro ambiente, los terremotos del mundo mosquito, el rugido de las polillas salvajes.
Cualquier cavidad resonante produce el mismo efecto, en realidad. Si uno se coloca un vaso o una tetera en la oreja (cualquier tipo de envase rígido en realidad), se oye el mismo sonido. Sin embargo, sugerir que se oye el mar dentro de un bote de garbanzos probablemente resulta mucho menos evocador, así que ese relato no trascendió. En cambio, en un entorno totalmente silencioso, el mismo experimento quedaría sin ningún efecto. No oiríamos nada porque no habría nada que amplificar.
El parecido entre el sonido de la caracola y el del mar, se debe a que ambos son sonidos amplios, con un gran ancho de banda, una especie de ruido blanco indefinido. En ellos conviven todo tipo de frecuencias, graves y agudas, más o menos en igual proporción. Sin embargo, dentro de la caracola no todas las frecuencias están igualmente representadas. Cuando el sonido atraviesa su cavidad resonante, esta refuerza solo algunas frecuencias: aquellas que coinciden con sus propios modos normales de vibración, que vienen dados por sus dimensiones, su forma y, sobre todo, por su longitud. Puede que una caracola no parezca a priori un objeto muy alargado, pero se puede pensar en ella como una especie de tubo cónico y enrollado, cerrado por uno de sus extremos. En ese sentido, sus modos de vibración son equiparables a los de una cuerda, un tubo, o a los de cualquier otro instrumento de viento. La caracola tiene una frecuencia fundamental característica y otras más agudas, correspondientes a su serie armónica. El resultado de todas ellas combinadas es un tono musical. Gracias a su forma alargada y enrollada, la caracola está afinada en una determinada nota. Por eso, distintas caracolas dan lugar a océanos sonoros ligeramente distintos según su tamaño (océano en do, océano en la bemol…).
 Grabado atribuido a Giorgio Ghisi (1520–1582). Fuente: MET Museum
Grabado atribuido a Giorgio Ghisi (1520–1582). Fuente: MET MuseumEsta peculiaridad convirtió a las caracolas en uno de los instrumentos musicales más antiguos y también en uno de los más universales. Probablemente, el primer instrumento de viento metal de la historia: basta hacer vibrar labios contra su punta un poco rota, como haciendo una pedorreta, para producir un sonido sorprendentemente poderoso, brillante, rotundo. Desde hace miles de años, las caracolas se han utilizado en culturas de todo el mundo como un tipo de trompeta, un símbolo de poder y un instrumento vinculado a los dioses. El ejemplo que nos pilla más cerca quizás es el de Tritón, que utilizaba el sonido de una concha para controlar las olas y el viento. Ese mismo viento que agita y hace llegar a nuestros oídos el sonido del mar.
Sobre la autora: Almudena M. Castro es pianista, licenciada en bellas artes, graduada en física y divulgadora científica
El artículo El océano en una caracola se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Los enigmas que nos cantan desde el fondo del océano
- El sonido del viento (2)
- ¿Por qué suena triste el modo menor?
Cancelaciones anómalas
No hace mucho tiempo escribí una entrada para esta sección del Cuaderno de Cultura Científica titulada Números errores de impresión en la cual estuvimos hablando de ciertos números que, aunque se produzca un cierto error tipográfico, siguen manteniendo su valor. Recordemos un ejemplo. Supongamos que queremos escribir en un artículo o una entrada de un blog el número “2 elevado a 5 multiplicado por 9 elevado a 2”, es decir, 25 92, pero se produce un error tipográfico y no quedan reflejadas las potencias, es decir, se queda escrito 2592. En general, esto produciría un error, ya que el valor de la expresión matemática no coincidiría con el valor del número, sin embargo, en este caso el resultado de 25 92 es, si realizamos las operaciones, 2592, luego sorprendentemente se mantiene inalterado. A estos números se les llama números errores de impresión.
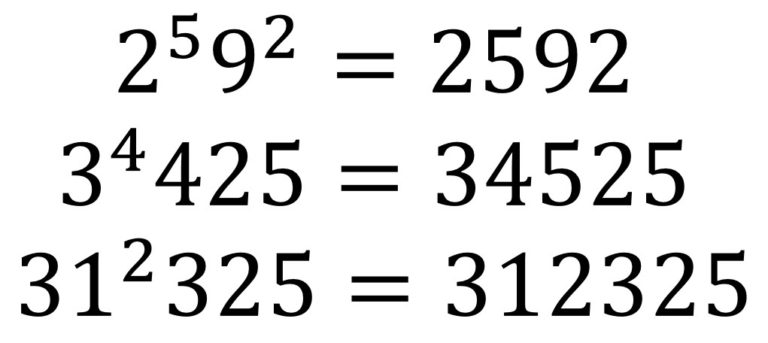
En esta entrada vamos a centrar nuestra atención en una serie de fracciones tales que, a pesar de producirse un error que podríamos calificar de matemático, en concreto, una cancelación anómala, el valor de la fracción se mantiene correcto. Veamos en qué consisten exactamente.
Empecemos con una sencilla fracción como es 12/15 (cuyo valor es 0,8). Como nos han enseñado cuando estudiábamos fracciones en la escuela, las fracciones como esta se pueden simplificar si tenemos en cuenta que 12 = 3 x 4 y 15 = 3 x 5, dividiendo el numerador y el denominador por un divisor común, en este caso, el 3. Es decir, “cancelamos” arriba y abajo el divisor común, luego 12/15 se transforma en 4 / 5 (cuyo valor sigue siendo 0,8).
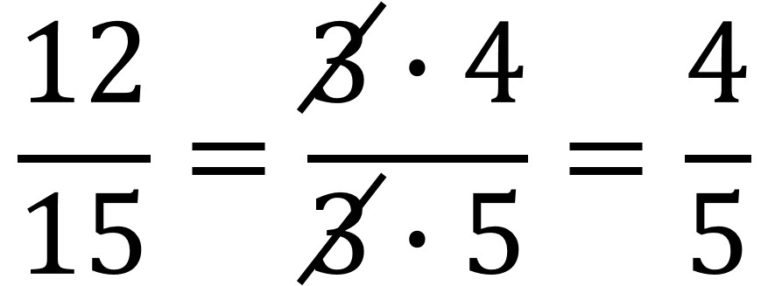
En las llamadas cancelaciones anómalas lo que ocurre es que se cancelan dígitos del numerador y del denominador como si fuesen divisores de los mismos. Esa cancelación que a priori daría lugar a un resultado completamente diferente, sin embargo, en el caso de las llamadas cancelaciones anómalas, lo que ocurre es que el resultado sorprendentemente no varía. Vamos a mostrar dos casos en los que se cancela un dígito del numerador y del denominador, viendo que en el primero el resultado es distinto, mientras que en el segundo el resultado es el mismo, obteniendo así un ejemplo de cancelación anómala.
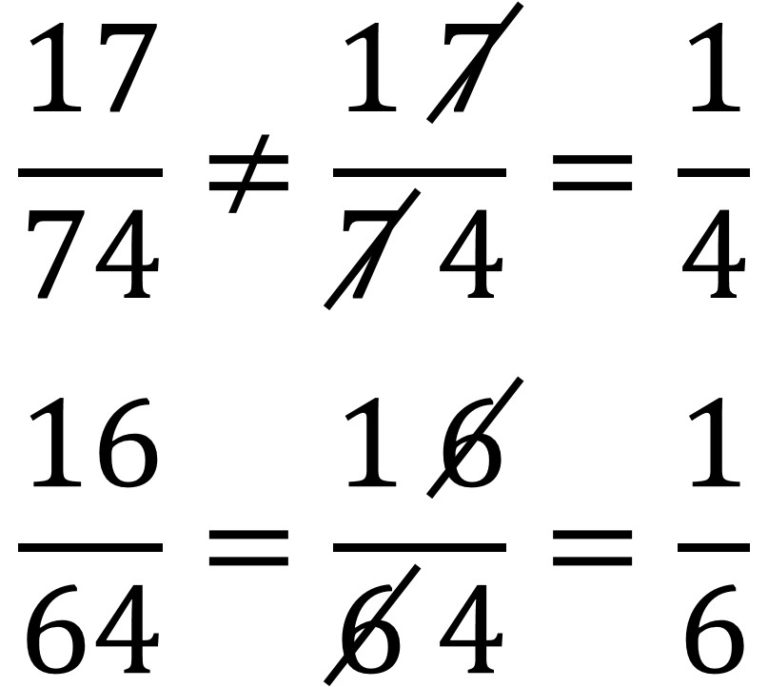
Una vez que hemos entendido cuando una fracción (consideraremos las fracciones propias, es decir, aquellas cuyo valor es menor que 1, lo cual se produce si el numerador es menor que el denominador) es una cancelación anómala, podemos buscar más ejemplos de las mismas. Así, nos planteamos el siguiente problema: encontrar las cancelaciones anómalas en las que numerador y denominador tengan solo dos dígitos.
Veamos cómo se puede resolver este problema. Buscamos una fracción cuyo numerador tenga dos dígitos, luego sea de la forma ac, por lo que su valor es (a.10 + c), y cuyo denominador, con dos dígitos, tiene que ser de la forma cb, luego su calor es (c.10 + d), para que se produzca la cancelación, por tanto, ac / cb = a / b (como es una fracción propia a es menor que b). Es decir,
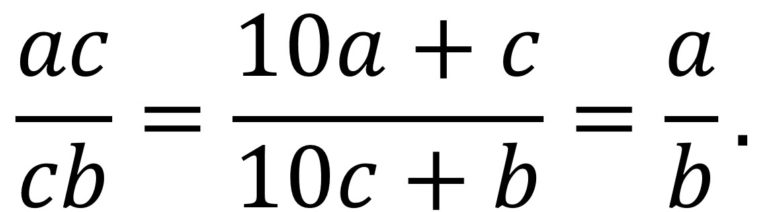
La solución del problema consiste, por lo tanto, en averiguar para qué valores de a, b y c, entre 0 y 9, se satisface la anterior igualdad.
Para empezar, de la igualdad (la segunda) de la expresión matemática anterior, se puede expresar el número que se cancela c en función de los otros dos, a y b.
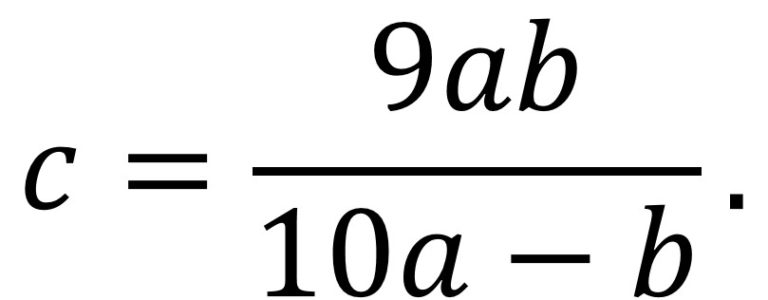
En consecuencia, dados a y b, esa expresión 9 a b / 10 a – b, es un número natural. Más aún, a partir de esa expresión, teniendo en cuenta que c es menor o igual que 9, se puede derivar la siguiente desigualdad.
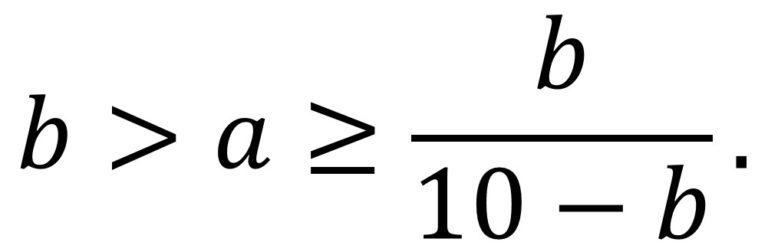
Por lo tanto, se trata de ver para qué números a y b (el primero más pequeño, a b), tales que verifican la desigualdad anterior, se satisface que el valor calculado anteriormente para c, es decir, 9 a b / 10 a – b, es un número natural. Puede verse fácilmente que las únicas soluciones posibles para el par de número (a, b) son (1, 4), (1, 5), (2,5) y (4,8), que se corresponden con las únicas cancelaciones anómalas con números de dos dígitos.
Más aún, a partir de esos cuatro ejemplos sencillos se derivan fácilmente cuatro cadenas de cancelaciones anómalas.

Las primeras menciones, según la literatura matemática, a las cancelaciones anómalas son dos artículos del matemático Alfred Moessner publicados en la revista de la Universidad Yeshiva (Nueva York) Scripta Mathematica, alrededor del año 1950. La siguiente referencia es el artículo Anomalous Cancellation del matemático estadounidense R. P. Boas, publicado en el libro Mathematical Plums (Ross Honsberger (editor). MAA, 1979), en el que se abordaba el problema para números con dos dígitos, pero en una base de numeración arbitraria b. Expliquemos un segundo esto. Teniendo en cuenta que en las cancelaciones anómalas, se “cancelan” dígitos de los números, entonces esta propiedad no depende de los números en sí mismo, sino de su representación en la base de numeración (normalmente la decimal, como hemos estudiado, pero podrían considerarse otras bases).
Pero existen más ejemplos de fracciones propias que son cancelaciones anómalas, con números con más dígitos. Por ejemplo, en el artículo sobre cancelaciones anómalas de la página Wolfram MathWorld se muestran algunas, con números de tres y cuatro dígitos.
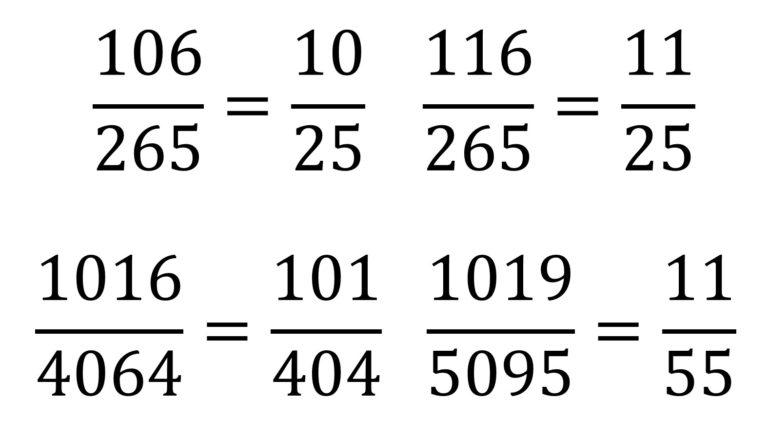
En este último ejemplo se “cancelaban” dos dígitos del numerador y del denominador. Veamos algunos ejemplos más con diferentes características.
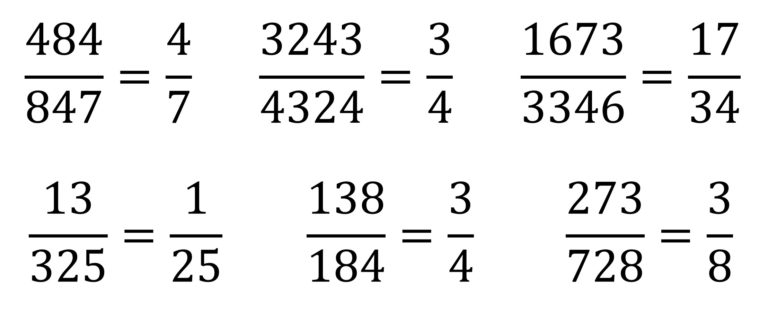
En el libro The Penguin Dictionary of Curious and Interesting Numbers, del matemático y divulgador británico David Wells, se muestra un ejemplo de una cadena con números inicialmente más grandes.

Más aún, en este libro se muestran dos variantes curiosas de cancelaciones, cuando los dígitos que se cancelan son los de las potencias.
Para terminar, como en otras ocasiones acabaremos con una obra de arte relacionada con los números.
 Counter painting on Kimono (2013), del artista japonés Tatsuo Miyajima. Imagen de la página del artista.
Counter painting on Kimono (2013), del artista japonés Tatsuo Miyajima. Imagen de la página del artista.Bibliografía
1.- David Wells, The Penguin Dictionary of Curious and Interesting Numbers, Penguin Press, 1998.
2.- Wolfram MathWorld: Anomalous Cancellation
3.- N. J. A. Sloane, The On-line Encyclopedia of Integer Sequences
4.- Proof Wiki: Anomalous Cancellation on 2-Digit Numbers
5.- Fun with Numbers: Fractions, Anomalous Cancellation
Sobre el autor: Raúl Ibáñez es profesor del Departamento de Matemáticas de la UPV/EHU y colaborador de la Cátedra de Cultura Científica
El artículo Cancelaciones anómalas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Números primos gemelos, parientes y sexis (2)
- El secreto de los números que no querían ser simétricos
- Números errores de impresión
Semiconductores
 foto: Luis Quintero / Unsplash
foto: Luis Quintero / UnsplashEl uso más frecuente hoy en día de los semiconductores es en forma de transistores, los componentes básicos electrónicos de todos los «componentes electrónicos de estado sólido» y los microchips de ordenador. Los semiconductores son los materiales más importantes en la revolución digital y en el desarrollo de otros dispositivos electrónicos. Estas aplicaciones que disfrutamos hoy surgieron hace casi un siglo, a partir de la década de 1930, a partir de la mecánica cuántica de la estructura en bandas de los sólidos.
Los semiconductores más comunes están hechos de silicio o germanio, los elementos 14 y 32 en la tabla periódica. A pesar de que forman estructuras cristalinas muy estables que deberían ser aislantes, en realidad son conductores débiles de la electricidad. ¿Cómo es esto posible?
En ambos elementos el número de electrones es suficiente para llenar completamente una banda de energía. Esta es la razón por la que deberían ser aislantes y, de hecho, cerca del cero absoluto, 0 K, son aislantes (no superconductores). A muy baja temperatura, las vibraciones de la red en el silicio y el germanio son mínimas, y los electrones en la parte superior de la banda de valencia no pueden obtener suficiente energía de las vibraciones de la red como para saltar la brecha de energía a la siguiente banda y convertirse en conductor. Sin embargo, la brecha con la siguiente banda es muy pequeña, de solo 0,7 eV en el germanio y 1,1 eV en el silicio. Debido a que estas brechas son tan pequeñas, a temperaturas algo superiores al cero absoluto los electrones pueden captar suficiente energía de las vibraciones de la red cristalina como para saltar a la banda de conducción vacía. A temperatura ambiente, estos elementos, que por su estructura deberían ser aislantes, en realidad son conductores débiles.
Como aislantes fallidos y conductores pobres, el silicio y el germanio no encontraron mucha utilidad en la electrónica hasta la década de 1950, cuando se hicieron avances en la introducción controlada de ciertas impurezas en la estructura reticular [1]. El uso masivo de estos dos elementos no comenzaría, sin embargo, hasta la década de 1980 con la introducción de métodos de producción a escala industrial de capas de silicio súper delgadas estructuradas microscópicamente, y (en menor medida) cristales de germanio, que, cuando se disponen adecuadamente pueden actuar como transistores. Hoy en día, las obleas de silicio, cuando se convierten en microtransistores mediante la introducción de impurezas y se descomponen en «chips», son la base de las industrias de la informática y la electrónica. [2]
El germanio puro se usó al principio en células fotoeléctricas. Un fotón externo puede golpear un electrón en la banda de valencia del germanio [3], proporcionando al electrón suficiente energía para alcanzar la banda de conducción. Si nos fijamos esto no es más que un “efecto fotoeléctrico interno”. Para que esto ocurra, la energía del fotón debe ser de, al menos, 0,7 eV para el germanio y 1,1 eV para el silicio. Como la energía de un fotón es E = hf, resulta que estas energías se corresponden con fotones que poseen frecuencias en el rango infrarrojo de las ondas electromagnéticas. Cualquier fotón con frecuencia en el rango infrarrojo o superior, lo que incluye luz visible, hará que los electrones salten a la banda de conducción y produzcan una corriente.
Notas:
[1] Curiosamente, dado que el germanio y el silicio son tan sensibles a las impurezas, su uso a gran escala como semiconductores no se produjo hasta que se desarrollaron métodos para producir grafito ultra puro para los reactores nucleares y germanio ultra puro para los circuitos electrónicos durante la Segunda Guerra Mundial. De las impurezas hablamos en la siguiente entrega de esta serie.
[2] Toda esta revolución social digital y las empresas mayores del mundo hoy día dependen de unos pequeños saltos de energía. Como los huracanes y el batir de alas de una mariposa, solo que facturable. Esta es una reflexión que te podrá ser útil en tu próxima charla con amigos.
[3] Esto también aplica al silicio, pero su uso fue más tardío.
[4] Este tipo de conductividad inducida por la luz tiene aplicaciones evidentes. Se puede usar, por ejemplo, para detectores de movimiento. Un haz de luz que incide sobre una fotocélula integrada en un circuito generará una corriente constante. Si alguien atraviesa el haz interrumpirá la corriente, lo que puede o activar una alarma o abrir una puerta automática para que la persona salga o entre sin usar sus manos. Los controles automáticos de las luces de los coches o de las farolas de las calles pueden utilizar el mismo principio. Dado que las fotocélulas son sensibles incluso a los rayos infrarrojos, siempre que haya suficiente luz natural la célula producirá una corriente. Cuando se pone el sol, la corriente se detiene, lo que proporciona la señal para encender las luces.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Semiconductores se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La teoría de bandas explica la conducción eléctrica
- Se intuye la conservación de la energía (1)
- Potencia y eficiencia de una máquina
Virus en el sistema de publicaciones científicas
Joaquín Sevilla, Alberto Nájera López y Juan Ignacio Pérez Iglesias
 Unsplash/Vlad Kutepov, CC BY-SA
Unsplash/Vlad Kutepov, CC BY-SAEl sistema de publicaciones científicas afronta una situación tan comprometida a causa de la COVID-19 que podría acabar desembocando en su transformación. No sería prudente hacer predicciones acerca de la forma en que se comunicarán los resultados científicos cuando la pandemia haya pasado, pero no cabe descartar ninguna posible evolución. La situación que atraviesa el sistema es de verdadera crisis.
El camino habitual para comunicar resultados científicos consiste en publicarlos en revistas especializadas. Para ello, una propuesta de artículo ha de pasar un proceso, generalmente lento, de revisión por pares. Durante este, otros especialistas en el campo, ajenos a los autores y anónimos para ellos, juzgan su calidad y lo aceptan, rechazan o proponen cambios.
Este proceso ganó peso a lo largo del siglo XX (aunque a Einstein no le gustaba nada) y hoy es un elemento inexcusable de una revista científica de calidad.
Publica o perece
En los últimos años el sistema de publicaciones científicas está sufriendo unas tensiones enormes. Por un lado, el progreso en la carrera científica se basa cada vez más en las publicaciones. Esto ha generado una práctica, condensada en la máxima “publica o perece”, que revela una preocupante confusión entre fines y medios.
Por otro, la irrupción de internet ha transformado el sistema de acceso y manejo de la información científica. La presión generada por las redes ha modificado drásticamente el mercado de todos los productos susceptibles de digitalizarse (música, cine, series y periódicos). A pesar de los cambios, el sistema de publicaciones científicas mantiene una estructura análoga a la que vivió Einstein.
Este contraste entre la transformación del sistema de acceso a los contenidos y el mantenimiento de la estructura editorial genera fuertes tensiones, hasta el punto de que se habla incluso de que “la máquina de hacer ciencia está rota”.
Las tensiones afloran por muchos sitios, lo que da lugar a problemas preocupantes y a diversos “males de la ciencia”. Hay una crisis de revisores, pues cada vez menos científicos están dispuestos a dedicar su tiempo a una labor ingrata, que no reporta ningún beneficio directo (ni económico ni de reconocimiento). Ante esto, muchos editores han optado por pedir a los propios autores que sugieran revisores, cosa que ha dado lugar a comportamientos fraudulentos.
Los conflictos de intereses entre autores y revisores son un problema intrínseco del sistema, pero que se ve agravado por las presiones. La importancia que para el sistema de ciencia tienen las editoriales de las revistas consideradas de prestigio hace que se comporten como un cartel, manteniendo unos precios y sistemas de tarificación que están provocando la cancelación de la suscripción a revistas por países enteros.
Éramos pocos y llegó el SARS-CoV-2
La pandemia de COVID-19 bien pudiera ser el elemento que abra la grieta definitiva en un sistema de publicaciones científicas ya tensionado y aquejado, como hemos visto, de diversos problemas serios.
Una de las características más obvias de la revisión por pares es que es lenta. Por rápido que se quiera hacer, desde que se envía un trabajo, es aceptado para su revisión, tres especialistas lo leen y consensuan su juicio para, finalmente ser aceptado (o rechazado), es difícil que pase menos de un mes. Ese tiempo, que puede ser razonable en condiciones normales, es una eternidad en tiempos de pandemia. La investigación, en estado de frenética actividad, no puede esperar semanas para conocer lo que otros equipos están haciendo, máxime cuando el valor que en realidad aporta la revisión al producto final tampoco es esencial.
No solo se retrasan los artículos científicos que podríamos denominar “estándar” con resultados experimentales, sino también otro tipo de contribuciones que permiten enriquecer el desarrollo científico, como son las cartas, comentarios, editoriales y perspectivas. Muchas revistas, ante la imposibilidad de atender todas las propuestas, han limitado su número o no los aceptan. Alguna, incluso, indica que este tipo de contribuciones se harán por iniciativa propia de la revista o consejo editorial, limitando mucho el acceso a ese tipo de formatos a la comunidad científica.
Esta situación conduce a que la comunidad científica que investiga el SARS-CoV-2, en todos sus ámbitos, genere conocimiento mucho más rápido de lo que el sistema editorial puede asimilar. Por eso se ha visto obligado a buscar alternativas.
El papel ¿mojado? de la prepublicación
En una sociedad donde la comunicación no tiene límites, la científica no puede verse encorsetada por un mundo editorial incapaz de dar respuesta en tiempo y forma. Así que muchos autores se han visto obligados a acudir a plataformas de prepublicaciones (preprints) como ArXiv, medRxiv, bioRxiv, Queios y OSFpreprints para dar a conocer los resultados de sus investigaciones.
Son sitios web donde los autores publican sus artículos para que se puedan leer mientras son revisados en las revistas. Esos sitios existen desde hace décadas y se crearon originalmente para mitigar el problema de posibles robos de ideas por parte de revisores poco éticos. Algunos ponen algunas limitaciones y un consejo “editorial” hace de filtro, otros son mucho más flexibles. Casi todos ofrecen la asignación de un DOI (Digital Object Identifier) que permite identificar el contenido, de forma similar al ISBN.
Algunos de estos espacios permiten que otros científicos, previa acreditación con su ORCID (Open Researcher and Contributor ID“ o «Identificador Abierto de Investigador y Colaborador” en español) discutan y revisen públicamente el contenido de la contribución. El número de científicos que pueden “revisar” un artículo será muchísimo mayor que el ofrecido por un sistema de revisión por pares. ¿Estamos ante un cambio de paradigma hacia una verdadera y plena Open Science?
Quizás lo estemos, pero hay que ser cautelosos. En estos días de ciencia frenética, la gran demanda social de conocimiento hace que estudios de bajísima credibilidad adquieran una importante relevancia pública. Por esa razón, en cualquier caso, cualquier alternativa a la revisión por pares a priori deberá garantizar una mínima calidad de lo que se publique.
Situaciones desesperadas requieren medidas desesperadas
El poner una prepublicación en un repositorio público antes de su aceptación formal no implica que la publicación tenga la misma validez de un artículo en una revista de prestigio. Pero ¿acaso la comunidad científica necesita el dictamen de consejos editoriales y revisores para decidir qué es científicamente aceptable o no? Son unas normas y manera de funcionar tradicionales que, por diversas razones, parecen hacer aguas en una situación de emergencia como la que vivimos.
Una prepublicación solo reconoce, de alguna manera, la autoría de una idea. Algo así como colocar el trabajo en la “pole” en una carrera, pero que, al final, podrá ganar otro si se publica antes. Algunos científicos están prefiriendo compartir sus resultados o ideas para que contribuyan al conocimiento lo antes posible, antes que recibir ese reconocimiento de un “aceptado” editorial porque saben que, por encima del curriculum vitae, estamos hablando de vidas.
La pregunta de si nos encontramos ante un nuevo paradigma no tiene una respuesta fácil. Pero no debemos descartar que la situación actual alumbre un nuevo modelo de comunicación de los resultados de la investigación. Más de una vez ha ocurrido a lo largo de la historia que un sistema débil ha perdurado en el tiempo, por inercia, en tanto no ha habido amenazas exteriores que forzasen su transformación o sustitución. Podemos estar en una coyuntura similar. Es posible que la gran cantidad de información generada con motivo de la pandemia sea la amenaza que acabe propiciando la transformación del sistema de publicaciones científicas. Su crisis sería por tanto, la antesala de un nuevo sistema.![]()
Sobre los autores:Joaquín Sevilla responsable de divulgación del conocimiento y profesor de tecnología electrónica en la Universidad Pública de Navarra; Alberto Nájera López es profesor contratado doctor de radiología y medicina física en la Universidad de Castilla-La Mancha; Juan Ignacio Pérez Iglesias es catedrático de fisiología en la Universidad del País Vasco / Euskal Herriko Unibertsitatea
Este artículo fue publicado originalmente en The Conversation. Artículo original.
El artículo Virus en el sistema de publicaciones científicas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Hacia un nuevo sistema de publicaciones científicas
- Las publicaciones científicas
- #Naukas14 Acceso abierto a las publicaciones científicas
Homeostasis y crisis del coronavirus
Juan Luis Arsuaga y María Martinón-Torres
 maradon 333 / shutterstock
maradon 333 / shutterstockHomeostasis es una palabra poco común, que se utiliza en biología, pero que podría ser útil en el contexto de la epidemia que estamos padeciendo. La homeostasis tiene que ver con el equilibrio y a la vez con el desequilibrio. Nos habla, en definitiva, de un desequilibrio equilibrado, o de un desequilibrio estable. La vida es una pura paradoja.
El ser humano ha tenido siempre la sensación de vivir en un mundo estable. Nunca sucede nada y las montañas no cambian de sitio. Y es cierto, pero solo a la escala de la generación humana. Hubo un tiempo en que esas montañas que sostienen el horizonte fueron el fondo de un mar, o una gigantesca cámara de magma subterráneo.
Tampoco los continentes han estado jamás quietos. En realidad siguen moviéndose. La tierra se separa, se junta, se quiebra. Se trata de fenómenos geológicos, movidos por fuerzas gigantescas que operan en el interior de la Tierra, donde se encuentra la caldera de su motor. También el clima ha cambiado, y de eso sí alcanzamos a ser testigos. Hace solo un siglo, los glaciares se extendían mucho más que ahora. Lo podemos comprobar en postales antiguas. Sin saberlo, nuestros abuelos y bisabuelos vivían al final de una pequeña glaciación.
Pero la realidad es que tampoco hay estabilidad en biología, a ninguna escala. Las especies están permanentemente enfrentadas a crisis, no conocen otro tipo de existencia. Podríamos afirmar que los seres vivos están siempre sufriendo una crisis o recuperándose de ella. Podríamos ir más allá y asegurar que una especie está continuamente a punto de extinguirse. La extinción consiste, simplemente, en no haber sido capaz de superar la última crisis.
La vida consiste en resolver problemas
En esa lucha continua, los organismos, como individuos, tampoco dejan de estar sometidos a tensiones. El filósofo Karl Popper acertó con su definición de la vida: consiste en resolver problemas. Los minerales y los muertos no tienen problemas que puedan resolver y por eso nunca cambian. Nuestros átomos cambian, nuestras moléculas cambian, nuestras células cambian, pero nosotros permanecemos.
Y es aquí donde entra la palabra homeostasis. Homeostasis es la capacidad de un organismo de reajustarse después de una grave alteración. Los organismos viven en equilibrios dinámicos, no estáticos. El acueducto de Segovia está en equilibrio estático, arquitectónico. Si se cae un solo pilar se hunde una parte de la canalización y el agua deja de circular, con lo que el acueducto se vuelve inútil por completo. No hay forma de que el propio acueducto segregue un nuevo pilar. El equilibrio (o el desequilibrio) constante es inherente a estar vivo.
Así, una bacteria es un sistema muy complejo, con numerosas estructuras internas bien diferenciadas que se reparten el trabajo. Cualquier célula de nuestro cuerpo es todavía más compleja, y la complejidad será mayor en los tejidos, en los órganos y en lo que en biología se denominan propiamente los sistemas, tales como el sistema respiratorio, el nervioso, el circulatorio, el locomotor, el inmune, el digestivo, el reproductor o el excretor. Finalmente, el individuo (una planta, un animal, una persona) es un sistema de sistemas de sistemas de sistemas. Pero no acaba ahí.
Por encima del individuo está el sistema social que los filósofos, a partir de Platón, han comparado con un organismo biológico. También el cuerpo social tiene homeostasis y eso es lo que, precisamente, le permite superar las crisis. En contra de lo que suele pensarse, la caída de un imperio, como el romano de Occidente (no el de Oriente) o el maya, no se produjo por una crisis única, sino por una serie de perturbaciones encadenadas y muy seguidas a las que el imperio no pudo hacer frente. La resiliencia consiste, simplemente, en recuperarse lo bastante rápido como para que la siguiente perturbación nos pille en equilibrio.
Otras crisis vendrán
El coronavirus ha provocado una crisis sanitaria, económica y social que superaremos sin ninguna duda. Otras crisis vendrán en el futuro y probablemente serán muy distintas, porque habremos aprendido a prevenir esta y otras parecidas. Como no podemos adivinar la naturaleza del siguiente embate, lo único que nos queda es reforzar la homeostasis de nuestra sociedad, que es cada vez más global.
Eso no quiere decir que debamos permanecer estáticos, sino todo lo contrario. Se trata de mejorar nuestra capacidad de alcanzar equilibrios dinámicos que permitan afrontar cualquier perturbación sin perder la estabilidad. No es cuestión de imitar a los acueductos romanos, sino a los organismos biológicos.
En su monumental “La montaña mágica”, Thomas Mann recoge en boca del joven Hans Castorp la definición de la vida como una “fiebre de la materia” que se balancea en precario equilibrio “dentro de este complejísimo y febril proceso de descomposición y renovación”. Nuestra sociedad aun herida, está viva. Tras los golpes, de los objetos inanimados solo quedan añicos; a los seres vivos les salen cicatrices.
Y esa es la lección política, en el mejor sentido de la palabra, que podemos extraer de la crisis del COVID-19. La homeostasis solo se logra si el organismo está bien organizado, si no incuba en su seno distorsiones que lo hagan inestable. Superaremos esta crisis, y la siguiente, y la siguiente, y la siguiente, si nos preocupamos ahora de reducir los desajustes internos en educación, salud, medio ambiente, democracia, riqueza, cultura, ciencia, justicia, solidaridad y sensibilidad.
Homeostasis es, por lo tanto, la palabra oportuna. Si nuestra sociedad mantiene sus equilibrios internos, es seguro que sobrevivirá a todas las crisis. Preocupémonos de que la cuerda sobre la que hacemos equilibrios no sea demasiado floja.![]()
Sobre los autores: Juan Luis Arsuaga, es catedrático de paleontología de la Universidad Complutense de Madrid, y trabaja en el Centro Mixto ISCIII-UCM de Evolución y Comportamiento Humanos y en el Museo de Evolución Humana de Burgos; María Martinón-Torres es directora del CENIEH, Centro Nacional de Investigación sobre la Evolución Humana (CENIEH).
Este artículo fue publicado originalmente en The Conversation. Artículo original
El artículo Homeostasis y crisis del coronavirus se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- De la homeostasis
- El coronavirus de Wuhan, ¿qué sabemos hasta ahora?
- La oreja de oso, una joya del Pirineo que guarda el secreto de la resurrección