

El (Paleo)Clima y ¿el frío que vendrá?

Si cerrásemos los ojos para visualizar la imagen de un geólogo, probablemente imaginaríamos a una persona descubriendo fósiles y recopilando y coleccionando minerales. No obstante, esta disciplina académica cuenta con muchísimas más aplicaciones desconocidas para gran parte de la sociedad.
Con el objetivo de dar visibilidad a esos otros aspectos que también forman parte de este campo científico nacieron las jornadas divulgativas “Abre los ojos y mira lo que pisas: Geología para miopes, poetas y despistados”, que se celebraron los días 22 y 23 de noviembre de 2018 en el Bizkaia Aretoa de la UPV/EHU en Bilbao.
La iniciativa estuvo organizada por miembros de la Sección de Geología de la Facultad de Ciencia y Tecnología de la UPV/EHU, en colaboración con el Vicerrectorado del Campus de Bizkaia, el Ente Vasco de la Energía (EVE-EEE), el Departamento de Medio Ambiente, Planificación Territorial y Vivienda del Gobierno Vasco, el Geoparque mundial UNESCO de la Costa Vasca y la Cátedra de Cultura Científica de la UPV/EHU.
Los invitados, expertos en campos como la arquitectura, el turismo o el cambio climático, se encargaron de mostrar el lado más práctico y aplicado de la geología, así como de visibilizar la importancia de esta ciencia en otros ámbitos de especialización.
Eneko Iriarte, geólogo del Laboratorio de Evolución Humana de la Universidad de Burgos, analiza cómo la geología ayuda a desentrañar la evolución del clima a lo largo de la historia, descubriendo las causas de las enormes variaciones que han existido a lo largo del tiempo y cómo éstas han influido en los organismos presentes y pasados, incluidos los humanos.
Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo El (Paleo)Clima y ¿el frío que vendrá? se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Geología: la clave para saber de dónde venimos y hacia dónde vamos
- La imperfección de los modelos del clima, por Manuel Toharia
- Los ojos que explorarán la superficie de Marte (Mars2020)
Variantes genéticas exóticas, claves para nuestra salud
Son los individuos que viven en condiciones más extremas -inuit, tibetanos y otros- aquellos que tienen variantes genéticas más infrecuentes que les permiten afrontar situaciones muy duras. En esos genes, puede estar la clave de la solución a algunos de nuestros problemas de salud.
Por ejemplo, se ha identificado una mutación del gen PCKS9 en norteamericanos de origen africano, gracias al cual tienen niveles muy bajos de colesterol. Esta mutación ha permitido desarrollar fármacos anticolesterol que tienen como diana ese gen.
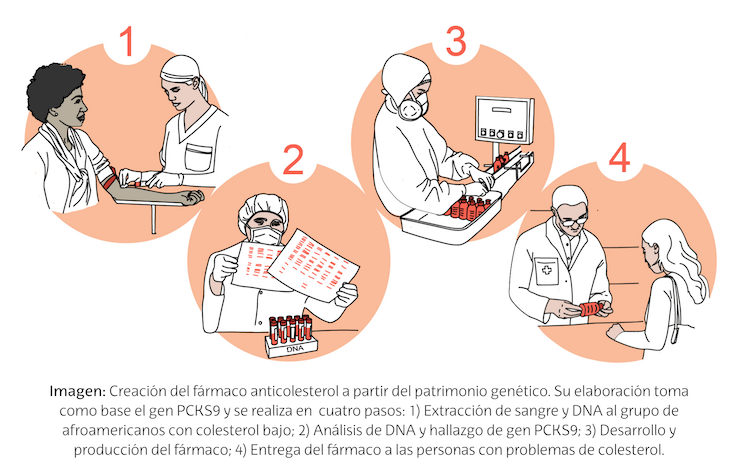 Ilustración: Ana Madinabeitia
Ilustración: Ana MadinabeitiaHay, por lo tanto, todo un patrimonio genético por explorar que puede ser fundamental para resolver problemas de salud.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Ana Madinabeitia Olabarria (@AnaMadinabeitia), alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Patrimonio genético. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 20 de marzo de 2016.
———————————-
El artículo Variantes genéticas exóticas, claves para nuestra salud se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Genética molecular para el rastreo de la caza furtiva
- Especies exóticas invasoras
- Frecuencia de variantes genéticas y alcoholismo
El citoesqueleto de las neuronas y el alzhéimer
José Martínez Hernández, investigador Ikerbasque del grupo Neuronal Ubiquitin Pathways del Departamento de Bioquímica y Biología Molecular de la Facultad de Ciencia y Tecnología de la UPV/EHU, ha participado en un estudio del Instituto de Neurociencias de Grenoble, en el que han descubierto la relación existente entre la presencia de péptidos beta-amiloide, conocidos por ser los componentes de las placas que se acumulan en el cerebro de las personas afectadas de alzhéimer, y la rápida pérdida de dinamismo del citoesqueleto de actina de las espinas dendríticas, las zonas de las neuronas encargada de recibir la información que viene de otras neuronas mediante sinapsis. Esta menor dinámica hace que la transmisión de la información no sea eficiente, lo que desemboca en la pérdida de las espinas y, por tanto, de la capacidad de formación de sinapsis de las neuronas.
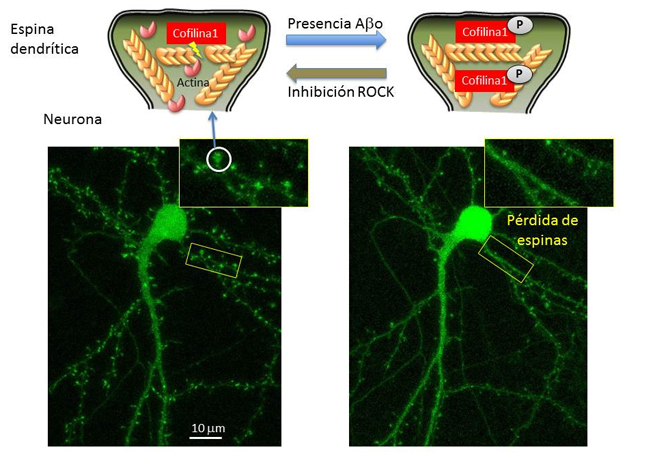 Pérdida de dinámica y posterior deterioro de las espinas dendríticas en las fases iniciales del alzhéimer. Detalles en el texto. Imagen: José Martínez Hernández / UPV/EHU.
Pérdida de dinámica y posterior deterioro de las espinas dendríticas en las fases iniciales del alzhéimer. Detalles en el texto. Imagen: José Martínez Hernández / UPV/EHU.El citoesqueleto es un entramado tridimensional de proteínas que provee de soporte interno a las células, organiza sus estructuras e interviene procesos como el transporte o el tráfico intracelular. Uno de los componentes del citoesqueleto son los filamentos de actina, que, tal como describe el doctor Martínez, “están ancladas pero en continuo movimiento, como si fueran una escalera mecánica; una proteína, llamada cofilina 1, se encarga de cortar los filamentos, y separar las unidades de actina, lo que mantiene activa esa dinámica”.
Sin embargo, en el caso de que la cofilina 1 sea fosforilada, es decir, se le añada un átomo de fósforo, esta proteína pasa a un estado inactivo, y deja de ejercer su función, lo que, a su vez impide que se lleve a cabo correctamente la actividad neuronal. “En nuestro estudio analizamos muestras de cerebros humanos con alzhéimer así como modelos animales de esta enfermedad, y en ellos vimos que la forma inactiva de la cofilina 1 aparecen en cantidades mayores que en neuronas sanas”.
En cultivos de neuronas vieron que la exposición a péptidos de beta-amiloide, el principal componente de las placas o depósitos que se acumulan en el cerebro de las personas con alzhéimer, provoca el aumento de la cofilina 1 fosforilada, y por tanto, provoca que se estabilicen demasiado los filamentos de actina, que pierdan dinamismo y altere el funcionamiento de las espinas dendríticas. “A largo plazo, además, los péptidos beta-amiloide hacen que haya menos espinas; al dejar de ser funcionales, se van perdiendo a lo largo del tiempo”, subraya el investigador
Una de las vías de fosforilación de la cofilina 1 es la ROCK, una quinasa, un tipo de enzima que modifica otras moléculas mediante fosforilación, a veces activándolas y otras desactivándolas. En el estudio quisieron ver si un medicamento que se utiliza en la práctica clínica, el Fasudil, cuya función es inhibir la acción de la enzima ROCK, revertía el efecto observado en los filamentos de actina, y “vimos que sí. No hemos propuesto un mecanismo de acción, pero hemos comprobado que la inhibición de esa vía de fosforilación de la cofilina 1 hace que la exposición a péptidos beta-amiloide no provoque la inactivación de la proteína, y el consecuente efecto en el citoesqueleto de las espinas dendríticas”, detalla Martínez.
“Nuestros resultados apoyan la idea que el daño provocado por los péptidos beta-amiloides a nivel de las espinas dendríticas en las primeras fases de la enfermedad puede prevenirse con la modulación de ROCK y la cofilina1, y que, por tanto, es necesaria la investigación en medicamentos que detengan esta fosforilación de manera específica de la cof1 en neuronas, para elaborar futuros tratamientos médicos contra el mal de Alzheimer”, concluye el doctor Martínez.
Referencia:
Travis Rush, Jose Martinez-Hernandez, Marc Dollmeyer, Marie Lise Frandemiche, Eve Borel, Sylvie Boisseau, Muriel Jacquier-Sarlin, Alain Buisson (2018) Synaptotoxicity in Alzheimer’s disease involved a dysregulation of actin cytoskeleton dynamics through cofilin 1 phosphorylation The Jounal of Neuroscience (2018) doi: 10.1523/JNEUROSCI.1409-18.2018
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo El citoesqueleto de las neuronas y el alzhéimer se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Implante de factores de crecimiento en nanoesferas para el tratamiento de alzhéimer y párkinson
- Háblame y te digo si tienes alzhéimer
- No dormir mata… neuronas
Bacterias contra bacterias
Un efecto secundario del tratamiento contra el cáncer es que debilita la microbiota (flora intestinal). Esta alteración puede aumentar el riesgo del paciente a padecer infecciones.
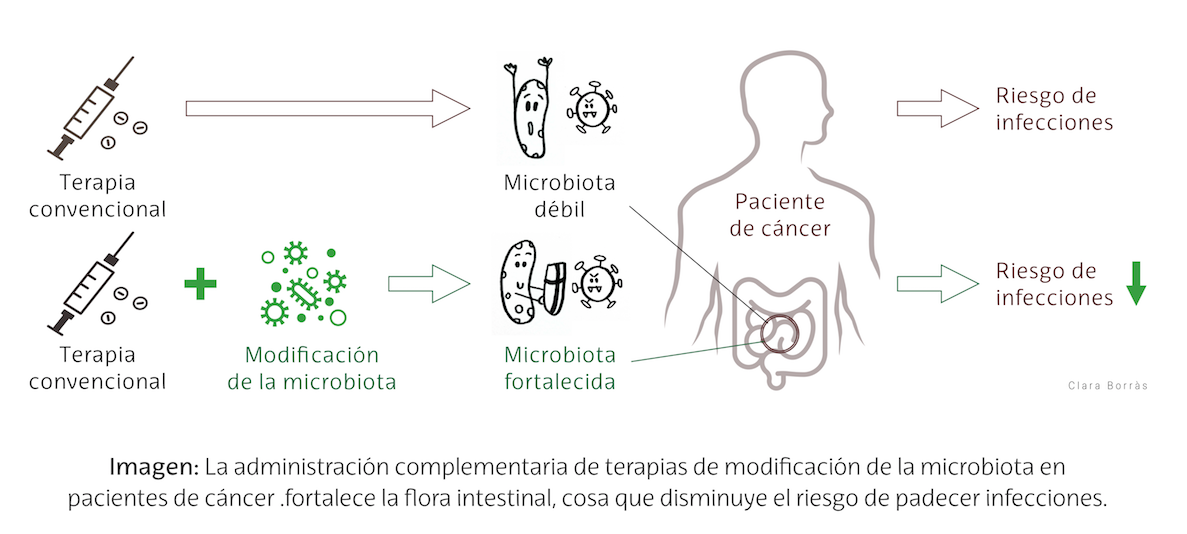 Ilustración: Clara Borrás
Ilustración: Clara BorrásLas estrategias terapéuticas que modifican y fortalecen la microbiota promueven una flora intestinal variada que protege de las bacterias infecciosas. Esto puede mejorar la calidad de vida del paciente con cáncer. En un futuro próximo, los datos de nuestro genoma, metabolismo, sistema inmune o microbioma se tendrán probablemente en cuenta a la hora de planear los tratamientos médicos personalizados o “a la carta”.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Clara Borrás Erodes, alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Microbiota y cáncer. Ignacio López-Goñi, Cuaderno de Cultura Científica, 10 de noviembre de 2017.
———————————-
El artículo Bacterias contra bacterias se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Metamorfosis criogénica de la rana del bosque
- En el mar, allí donde todo comienza
- Un ornitisquio emplumado
Las reglas de una buena melodía
Mah-nà mah-nà
Hay tonadillas tan conocidas que es imposible empezar escucharlas sin esperar ansiosamente su continuación.
Tu tu rururu.
Pero lo curioso de las expectativas musicales es que operan aunque sea la primera vez que escuchamos una determinada canción. En ese caso, las expectativas se basan en todo lo que sabemos (sin saberlo) de la música gracias a haber escuchado muchas otras canciones antes. De nuevo: con cada escucha hemos ido construyendo un modelo, un sentido de lo que es musical, que aplicamos a cada nueva escucha intentando siempre adivinar cuál es la nota que vendrá. Y, por supuesto, no manejamos un único modelo. Existen expectativas armónicas, rítmicas, tímbricas… que pueden ser generales o ajustarse a un determinado estilo musical.
Pero, por ahora, ciñámonos a las expectativas melódicas. En el post anterior comentamos algunas de los métodos que utiliza la psicología para medirlas. Ahora cabe preguntarse: ¿cuáles son esas expectativas?, ¿son verdaderamente descriptivas?, es decir: ¿se ajustan realmente a las melodías que solemos escuchar?
La buena noticia es que tenemos un montón de datos para averiguarlo. Basta tomar unas cuantas partituras (o unos cuantos miles) y empezar a buscar patrones. Estas son algunas de las cosas que la estadística nos cuenta sobre las melodías.
Grados conjuntos.
Piensa en tu canción preferida; en la primera estrofa, específicamente. No necesito ser adivina para saber que el cantante entona varias sílabas sobre la misma nota. Tiene truco, pensarás: la estrofa suele ser la parte menos lucida de la canción, la más monótona desde el punto de vista melódico. Pero incluso si jugamos con el estribillo, lo más probable es que todos los intervalos melódicos sean muy pequeños (de un tono normalmente) y que haya sólo un par de saltos, si acaso, un poco mayores.
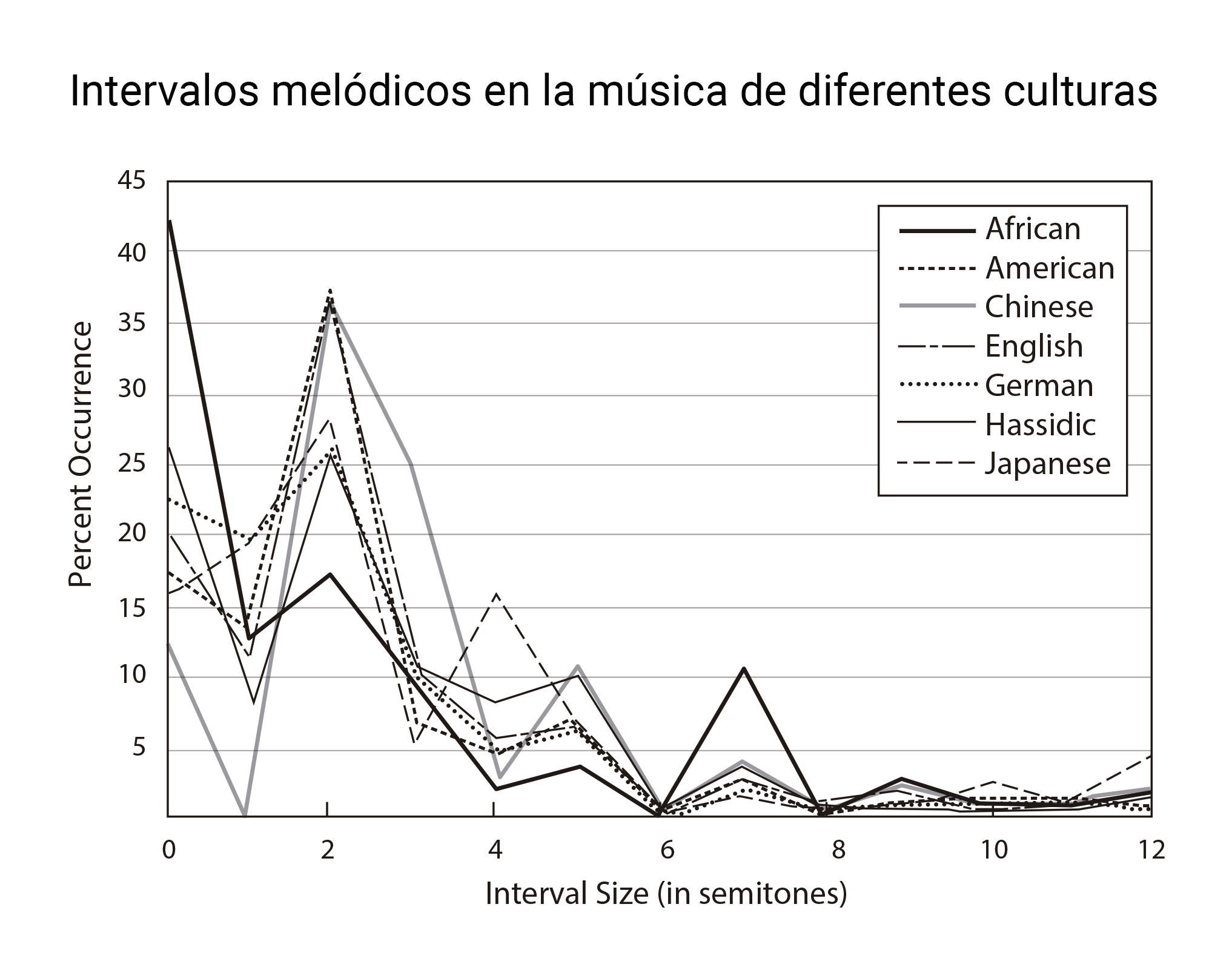
No es magia: es estadística. Las melodías más comunes se construyen, principalmente, por grados conjuntos. Y no se trata de un rasgo exclusivo de nuestra cultura. Podéis observarlo en la gráfica anterior1: a lo largo y ancho del planeta, los intervalos pequeños tienden a predominar, quizás debido a la dificultad que entraña cantar con precisión intervalos más amplios2. Asimismo, en 1978, Diana Deutsch mostró que las expectativas de los oyentes reflejan este patrón general3. Existen, eso sí, llamativas excepciones, como los yoiks escandinavos o el canto tirolés.
Pasos descendentes:
Las melodías más comunes tienden a utilizar intervalos pequeños pero todavía podemos decir más: en caso de producirse algún salto, lo más probable es que este sea ascendente (es decir: de sonidos graves hacia sonidos más agudos). David Huron comprobó que esta es, también, una característica a nivel universal de la música con muy contadas excepciones: las melodías saltan hacia el agudo y descienden por pequeños pasos hacia sonidos más graves.
Lo interesante es que este mismo dibujo es común al habla. Desde el punto de vista de la entonación, cada vez que hablamos tendemos a elevar la frecuencia de nuestra voz muy rápidamente al principio de cada frase y después vamos descenciendo poco a poco hacia sonidos más graves. De nuevo, existen excepciones: la entonación de las preguntas, ascendente al final, es una de ellas. Pero, en general, podemos decir que la voz hablada tiende a descender lentamente; probablemente debido a que la presión ejercida por el aire procedente de los pulmones disminuye a medida que este se agota. En realidad, cantar requiere un control mayor del flujo de aire, por lo que no parece probable que las líneas descendentes de las melodías se deban a esta misma causa fisiológica. Más bien: parece ser un préstamo directo procedente de la prosodia del lenguaje.
Inercia:
Los pasos descendentes tienden a ir seguidos por más pasos descendentes. No sucede así con los intervalos ascendentes que pueden cambiar de sentido con igual probabilidad. Sin embargo las expectativas de los oyentes, en este caso, no se corresponden perfectamente con la estadística: tendemos a esperar inercia en ambos sentidos. Quizás este modelo sea lo bastante descriptivo con un menor coste “computacional”, por así decirlo, pero el motivo no termina de estar claro.
Regresión melódica:
Imagina que vas por la calle y te cruzas con un tipo de dos metros. Lo más probable es que la siguiente persona que te cruces sea más baja. No es una relación causal, evidentemente; una persona alta no causa la aparición de personas más bajitas. Pero los valores extremos de una distribución normal son, simplemente, menos probables. Esto es lo que se conoce como regresión a la media.
Como las alturas humanas, los tonos de una melodía muestran una tendencia central: esto es, dentro de un espacio acotado de sonidos (la tesitura de la melodía), las notas más probables son aquellas que no son ni muy graves, ni muy agudas; sino que están situadas hacia el centro del rango sonoro. Por tanto, cada vez que alcanzamos una nota extrema, lo más probable es que la siguiente nota esté más cerca de la media.
Nuestras expectativas, nuevamente, reflejan este hecho musical. Aunque no de forma perfectamente fiel… en este caso, cada vez que se produce un salto melódico, los oyentes esperan que la siguiente nota se mueva en dirección contraria al salto. Y suelen acertar, puesto que los saltos melódicos tienden a acercar la melodía a los extremos de su tesitura. Como en el caso de la inercia, el modelo parece simplificar la realidad del fenómeno que quiere anticipar. Dado que, habitualmente, sus predicciones resultan ser correctas, es lo bastante bueno.
A fin de cuentas, ese es el único propósito de las expectativas; no se trata de alcanzar un conocimiento exacto de la música, basta con acertar. Y de hecho, lo consiguen: las melodías que escuchamos encajan con lo que esperamos de ellas, con aquello que nos resulta más musical. Y ahora cabe preguntarse: ¿qué fue antes, el huevo o la gallina?, ¿nuestras expectativas describen la música que nos rodea, o nos rodea música que se ajusta a nuestras expectativas?, ¿cuánto espacio queda para innovar?
Referencias:
David Huron (2008) Sweet anticipation: music and the psychology of expectation. The MIT Press.
Notas:
1 David Huron. “Tone and Voice: A Derivation of the Rules of Voice-Leading from Perceptual Principles”. Music Perception: An Interdisciplinary Journal, Vol. 19 No. 1. 2001.
2 La gráfica muestra dos picos especialmente prominentes: en 0 semitonos (una nota repetida) y en dos semitonos (un tono de distancia o grados conjuntos). En cambio, existe un mínimo peculiar sobre el número 6: este es el tamaño del tritono, un intervalo especialmente disonante y difícil de cantar (hasta el punto de ser conocido como “Diábolus in música”)
3 Deutsch, D. (1978). Delayed pitch comparisons and the principle of proximity. Perception & Psychophysics 23: 227–230.
Sobre la autora: Almudena M. Castro es pianista, licenciada en bellas artes, graduada en física y divulgadora científica
El artículo Las reglas de una buena melodía se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- «Una copita de vino es buena para el corazón». Claro que sí, guapi.
- Las partituras de Babel
- BertsoBot, el robot versolari
La adherencia, clave en el seguimiento de las dietas
La inquietud de la sociedad actual por lucir una buena imagen y sentirse sano, anima a los medios de comunicación y a la comunidad científica a la búsqueda de la dieta ideal. Este empeño parece solo quedarse en la utilización de la calculadora para cuantificar calorías, que según qué dietas (algunas de ellas verdaderos best sellers) estarán relacionadas con determinados grupos de alimentos y sus correspondientes nutrientes.
Lo que se está viendo en distintas investigaciones es que, además de la proporción de los diferentes alimentos a consumir en su justa medida, hay que tener en cuenta la continuidad de los hábitos dietéticos en el tiempo, la realización de actividad física y las creencias personales, a veces infundadas, respecto al consumo de ciertos alimentos.
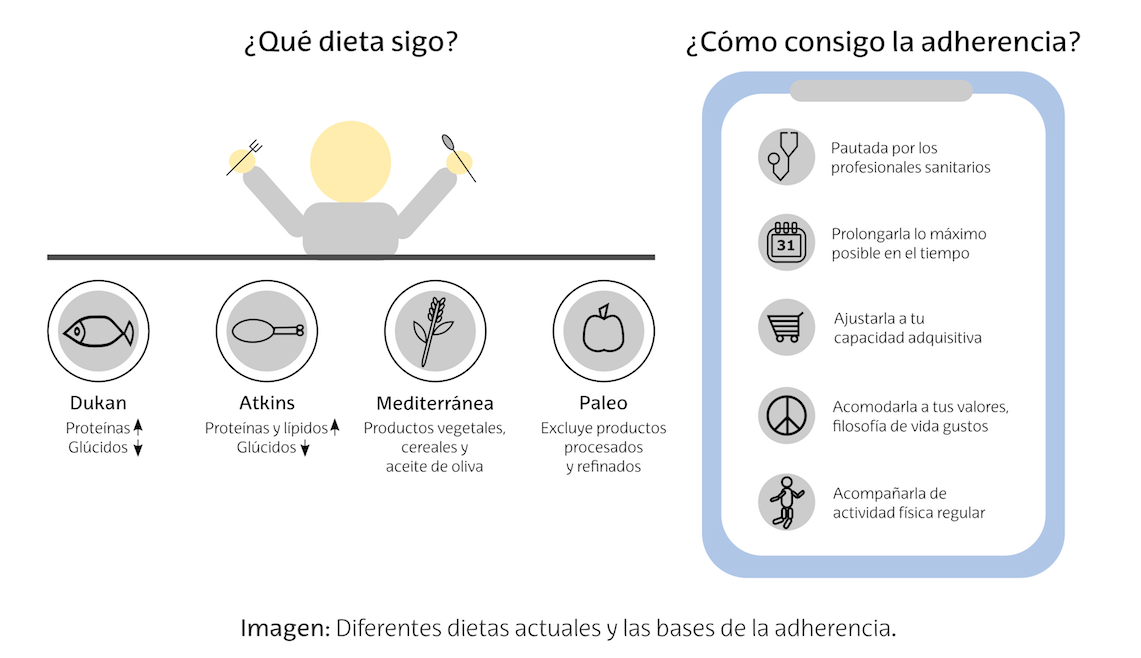 Ilustración: Héctor Márquez
Ilustración: Héctor MárquezLa adherencia personal por seguir estas pautas dietéticas, sin abandonar a las primeras de cambio, debe llegar a ser la base de la dieta equilibrada ideal de cada uno.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autor: Héctor Márquez Ortega, alumno del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Ni dieta equilibrada ni nutrientes. Es cosa de adherencia. Aitor Sánchez García, Cuaderno de Cultura Científica, 6 de noviembre de 2015.
———————————-
El artículo La adherencia, clave en el seguimiento de las dietas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El ciclo de una infección
- En el mar, allí donde todo comienza
- Metamorfosis criogénica de la rana del bosque
Cuando las palabras no son suficientes: conjunto vacío
El reflejo se hace infinito. Y el infinito es un conjunto eternamente vacío.
Verónica Gerber Bicecci, Conjunto Vacío (página 181)
El conjunto vacío –no es uno, es EL– es el único conjunto que no posee elementos. El matemático francés André Weil (1906-1998), uno de los miembros del grupo Bourbaki, propuso denotarlo con el símbolo Ø. Se inspiró en esta letra vocal usada por los alfabetos danés y noruego y que, parece, también se utilizaba en el antiguo euskera. En la teoría de conjuntos de Zermelo la existencia del conjunto vacío es un axioma.
El título de esta anotación hace referencia a la novela Conjunto vacío (Pepitas de calabaza, 2017) de Verónica Gerber Bicecci, que se define a sí misma como una «artista visual que escribe».

La editorial Pepitas de calabaza presenta la novela de esta manera:
Conjunto vacío, primera novela de Verónica Gerber Bicecci, es una historia construida con una dura e infinita belleza; un relato en el que la escritura va de la saturación al vacío, y en el que la prosa experimenta un viaje que parte de la normalidad y se mueve hacia la extrañeza. Estamos ante un libro tremendamente original en su manera de contar, en el que se utilizan tanto recursos narrativos (párrafos cada vez más cortos, capítulos cada vez más sintéticos) como lingüísticos (escrituras ilegibles, disgrafías, lenguajes infantiles, idiomas inventados) o gráficos (los diagramas de Venn que se utilizan en la teoría de conjuntos) con el fin de completar una historia que conquista al lector desde la primera línea. Conjunto vacío narra la desaparición de la madre del personaje principal, y su historia reconstruye la generación de hijos del exilio, la relación entre imagen y palabra, el desdoblamiento y el juego de espejos que produce el silencio y lo «no dicho».
Conjunto Vacío cuenta la historia de una artista gráfica, Verónica, hija de exiliados argentinos en México. Tras ser abandonada por su pareja, la protagonista regresa a la casa familiar. Allí rememora la época en la que su madre desapareció. Abandonó a Verónica y a su hermano Alejandro: el niño y la niña la buscaban, sin conseguir encontrarla. Ahora, ya mayor, de regreso a casa –el búnker–, el fantasma de la madre sigue rondando. Verónica la escucha, habla con ella, pero no la ve. Sigue fingiendo, como de pequeña, que la madre sigue habitando la casa familiar.
Verónica encuentra un trabajo archivando las pertenencias de la recién fallecida escritora –también exiliada argentina– Marisa Chubut: se trata de un encargo de su hijo Alonso. Tras una breve relación amorosa con la protagonista, Alonso también desaparece de su vida.
Los diferentes abandonos –el desamor, la orfandad, el desamparo, el exilio, el desarraigo– producen un formidable vacío en la vida de Verónica. Solo es capaz de contar su historia jugando a que las palabras desaparezcan poco a poco: el texto contiene mensajes en clave, misivas escritas del revés o diagramas de Venn que ayudan a la narradora a expresar aquellas situaciones que no consigue reflejar con vocablos.
Cada personaje se identifica con una letra (ella es Y –de yo–, M es su madre, A es su hermano, etc.). Cada encuentro, cada abandono, cada relación con uno u otro personaje se expresa a través de estos diagramas de Venn y otras imágenes geométricas. En el video de debajo pueden verse algunos ejemplos.
En la época de la dictadura argentina, la que provocó el exilio de la familia de la protagonista a México, la enseñanza de la teoría de conjuntos se prohibió en las escuelas por ‘subversiva’. Entiendo que como acto de rebelión, Verónica cuenta su historia con la teoría de conjuntos como herramienta destacada.
A través de ellos se puede ver el mundo «desde arriba», por eso me gustan los diagramas de Venn. […] Sabemos, por ejemplo, que un jitomate pertenece al conjunto de jitomates (JI) y no al de cebollas (C) ni al de chiles (CH) ni al de cilantro (CI). ¿Dónde está la amenaza en un razonamiento como este?
Verónica Gerber Bicecci, Conjunto Vacío, página 84onjunto vacío es una bella narración en la que los vacíos cotidianos pasan a expresarse mediante imágenes, por medio de metáforas matemáticas, a través de teoría de conjuntos. Porque cuando las palabras no permiten expresar los sentimientos o mostrar las complejas relaciones humanas, quizás las imágenes puedan sustituirlas. Como la propia autora indica, por medio de diagramas ‘se puede ver el mundo «desde arriba»’.
Referencias:
Marta Macho Stadler, Conjunto vacío de Verónica Gerber Bicecci, DivulgaMAT, enero 2018
Conjunto vacío, página web de Verónica Gerber Bicecci
Carlos Pardo, Estrategias del ermitaño. ‘Conjunto vacío’ es reconocida como una de las novelas más imaginativas de la literatura latinoamericana reciente, Babelia, 26 julio 2017
Vivian Murcia G., Verónica Gerber Bicecci, la mujer del ‘Conjunto Vacío’, Ibe.tv, 8 marzo 2018
Sobre la autora: Marta Macho Stadler es profesora de Topología en el Departamento de Matemáticas de la UPV/EHU, y colaboradora asidua en ZTFNews, el blog de la Facultad de Ciencia y Tecnología de esta universidad.
El artículo Cuando las palabras no son suficientes: conjunto vacío se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:La influencia de los genes en la felicidad
¿Qué nos hace realmente felices? ¿Las circunstancias de nuestra vida o cómo las percibimos? Investigadores de la Universidad de Essex (UK) han demostrado que nuestra actitud ante las circunstancias de la vida tiene un componente genético.
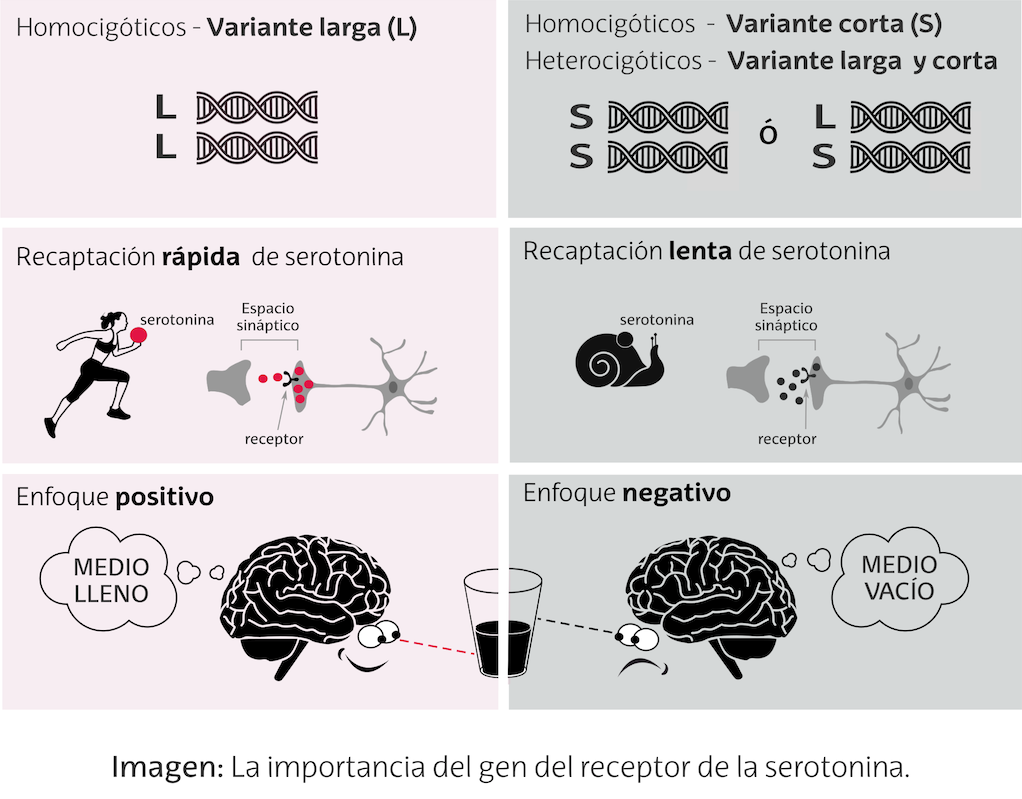 Ilustración: Inmaculada Martín
Ilustración: Inmaculada MartínSegún el trabajo de la investigadora Elaine Fox y sus compañeros, la tendencia a fijar nuestra atención en eventos desfavorables o a ignorarlos, en aras de lo positivo, está relacionada con diferencias en la longitud de la región promotora del gen del transportador de la serotonina (5-HTTLPR). Este gen determina la velocidad de recaptación de la serotonina hacia la neurona pre-sináptica. Así, en individuos homocigóticos para la variante larga (LL), la recaptación es más rápida dando lugar a un foco de atención centrado en los aspectos positivos. Mientras que la presencia de la región corta (SS o SL), da lugar a una recaptación lenta y a la ausencia del patrón de atención selectiva hacia los eventos favorables.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Inmaculada Martín Berenjeno, alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Un alelo para las gafas de color de rosa. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 7 de agosto de 2017.
———————————-
El artículo La influencia de los genes en la felicidad se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Genética molecular para el rastreo de la caza furtiva
- En el mar, allí donde todo comienza
- Metamorfosis criogénica de la rana del bosque
Reflexión de ondas: rayos
 Fuente: Nearshore wave modeling / The COMET Program
Fuente: Nearshore wave modeling / The COMET ProgramHemos visto que las ondas pueden pasar una a través de otra y sortear obstáculos en sus trayectorias. Las ondas también se reflejan, al menos en cierta medida, cada vez que llegan a cualquier límite del medio en el que viajan. Los ecos son ejemplos familiares de la reflexión de las ondas sonoras. Todas las ondas comparten la capacidad de reflejarse, algo que tiene muchos usos, como veremos en la próxima entrega. Nuevamente, el principio de superposición será el que nos ayude a comprender qué sucede cuando hay reflexión.
Supongamos que uno de los extremos de una cuerda está muy bien atado a un gancho firmemente sujeto a una pared [1]. Desde el otro extremo enviamos un pulso por la cuerda hacia el gancho. Como el gancho no puede moverse, la fuerza ejercida por la onda de la cuerda no puede hacer ningún trabajo en el gancho [2]. Por lo tanto, la energía transportada en la onda no puede abandonar la cuerda en este extremo fijo. ¿Qué hace la onda entonces? Rebota, se refleja, con la misma energía [3].
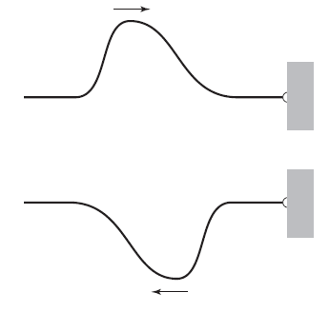 Figura 1. Imagen: Cassidy Physics Library
Figura 1. Imagen: Cassidy Physics Library¿Qué aspecto tiene la onda después de reflejarse? El sorprendente resultado es que la onda parece ponerse del revés en la reflexión. Imaginemos que la onda viene de izquierda a derecha, como en la Figura 1, y se encuentra con el gancho fijo. El efecto de la onda es intentar levantar (subir) el gancho. Según la tercera ley de Newton, el gancho debe ejercer una fuerza sobre la cuerda en la dirección opuesta mientras se lleva a cabo la reflexión. Los detalles de cómo varía esta fuerza en el tiempo son algo complicados y no los trataremos aquí, pero el efecto neto es que se envía de vuelta por la cuerda una onda invertida de la misma forma.
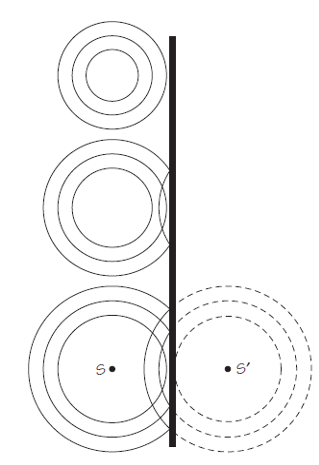 Figura 2. Imagen: Cassidy Physics Library
Figura 2. Imagen: Cassidy Physics LibraryFijémonos ahora en los tres diagramas de la Figura 2. Muestran los resultados de la reflexión de ondas en la superficie del agua en una pared recta. Puedes verificar si los diagramas son precisos al intentar reproducir el efecto en un lavabo o en una bañera. Espera hasta que el agua esté quieta, luego sumerge brevemente la punta del dedo o deja caer una gota en la masa de agua. En el diagrama de arriba, la cresta más exterior de la onda está cerca de la pared situada a la derecha. Los siguientes dos diagramas muestran las posiciones de las crestas después de que primero una y después dos se hayan reflejado.
Fijémonos en las curvas discontinuas en el último diagrama. Muestran que la onda reflejada parece originarse desde un punto S‘ que está tan lejos detrás de la pared como S está delante de ella. La fuente imaginaria en el punto S’ se llama imagen de la fuente S.
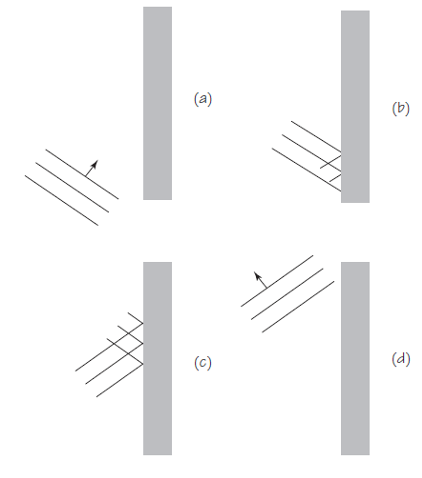 Figura 3. Imagen: Cassidy Physics Library
Figura 3. Imagen: Cassidy Physics LibraryHemos visto primero la reflexión de las ondas circulares, porque eso es lo que generalmente tenemos costumbre de ver cuando vemos ondas en la superficie del agua. Pero, en general, es más fácil usar un principio general para explicar la reflexión observando un frente de onda recto, reflejado desde una barrera también recta. Veamos los diagramas de la Figura 3 que indican lo que sucede cuando las crestas de las ondas se reflejan desde la barrera recta.
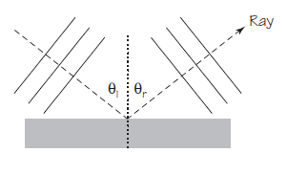 Figura 4. Imagen: Cassidy Physics Library
Figura 4. Imagen: Cassidy Physics LibraryParece que describir el comportamiento de los frentes de onda reflejados va a ser algo complicado. Sin embargo, es mucho más fácil si dibujamos perpendiculares a los frentes de onda. A esas líneas las vamos a llamar rayos, e indican la dirección de propagación de la onda. En la Figura 4 se han dibujado rayos para un conjunto de crestas onduladas justo antes de la reflexión y justo después de la reflexión desde una barrera. El rayo para las crestas incidentes forma un ángulo Θi con la pared. El rayo para las crestas reflejadas forma un ángulo Θr. El ángulo de reflexión Θr es igual al ángulo de incidencia Θi ; es decir, Θi = Θr.
Esto es un hecho experimental, que puedes verificar fácilmente.
Notas:
[1] Para ser rigurosos hemos de señalar que la pared tiene una masa enorme, está construida sólidamente y que no va a verse afectada en absoluto por lo que haga la cuerda.
[2] Que no puede hacer ningun trabajo significa que no puede desplazarlo (trabajo en física es fuerza por el desplazamiento que provoca), por estar anclado firmemente a una pared de las características de [1].
[3] Idealmente. Para que fuera exactamente así pared, gancho, sujeción al gancho y cuerda tendrían que ser ideales.
Sobre el autor: César Tomé López es divulgador científico y editor de Mapping Ignorance
El artículo Reflexión de ondas: rayos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Cuando las ondas se encuentran
- Ondas estacionarias
- Física de las ondas estacionarias: frecuencia fundamental y sobretonos
Mensajería electroquímica
El encéfalo es quien gobierna el organismo a través de una red de mensajería electroquímica encargada de recibir y gestionar toda la información.
 Imagen 1: El encéfalo humano. (Ilustración: Irene Manrique)
Imagen 1: El encéfalo humano. (Ilustración: Irene Manrique)En esta red se encuentran las neuronas, que junto con los sensores del encéfalo, coordinan las funciones vitales de nuestro cuerpo. Las neuronas realizan 5.000 conexiones entre ellas.
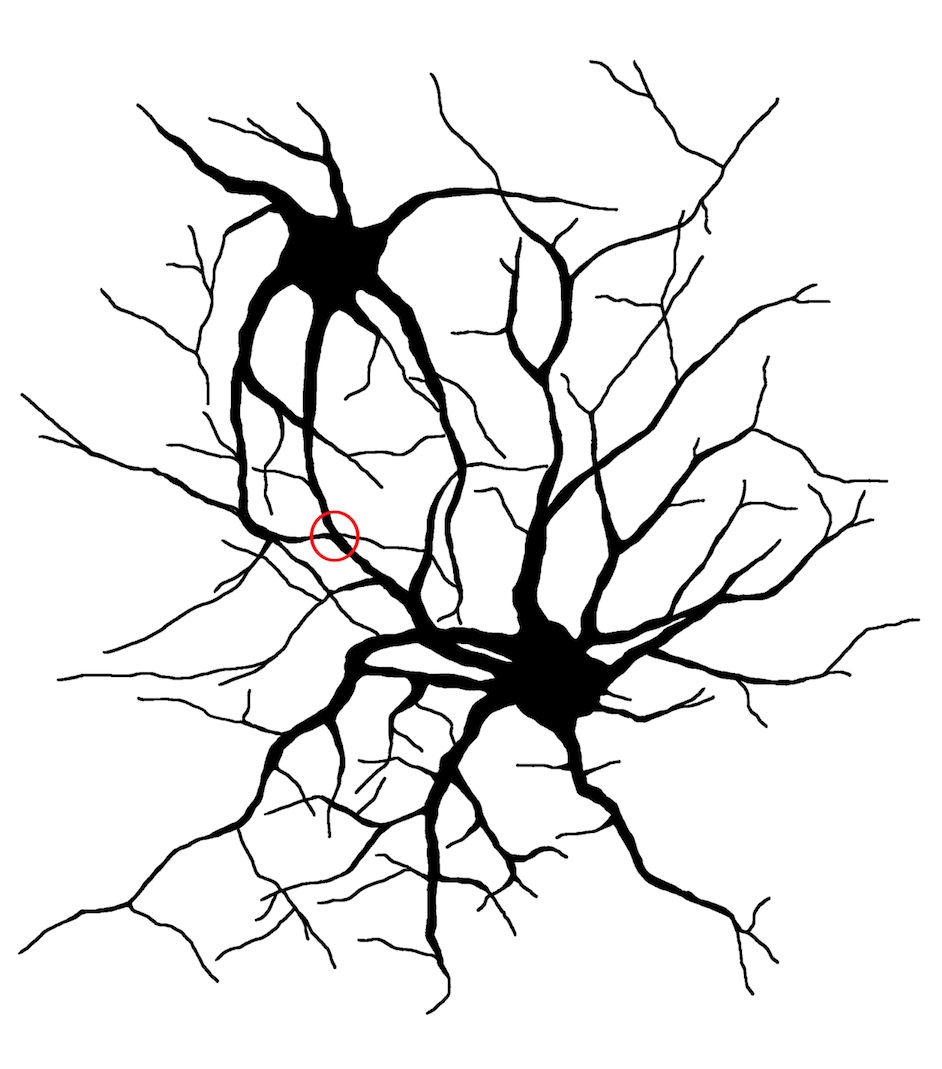 Imagen 2: Neuronas y conexiones sinápticas (círculo rojo). (Ilustración: Irene Manrique)
Imagen 2: Neuronas y conexiones sinápticas (círculo rojo). (Ilustración: Irene Manrique)Las neuronas trabajan en un millón de conexiones por segundo. En ellas se recibe la información en forma de presión, radiaciones electromagnéticas y sustancias químicas.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Inmaculada Manrique González, alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: El encéfalo humano. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 14 de agosto de 2017.
———————————-
El artículo Mensajería electroquímica se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Metamorfosis criogénica de la rana del bosque
- En el mar, allí donde todo comienza
- Especies exóticas invasoras
Digestión estomacal (I): el papel de las glándulas gástricas
La digestión estomacal cursa mediante la actuación de jugos gástricos sobre el quimo. Los produce el propio estómago, aunque la tasa a que se secretan depende de la alimentación. En los animales ectotermos que carecen de mecanismos de compensación térmica, una bajada de temperatura puede producir una disminución o, incluso, cese de la actividad alimenticia; en ese caso, también la secreción de jugos digestivos se reduce o se llega a detener. Y si se trata de animales cuya fuente de alimento es impredecible, pueden pasar largos periodos de tiempo sin alimentarse y sin actividad digestiva alguna: es lo que ocurre, por ejemplo, con ciertos reptiles como algunas serpientes, que capturan una presa cada mucho tiempo. En el extremo opuesto están los rumiantes, que digieren el alimento de forma permanente.
 Micrografía de la mucosa gástrica. Imagen: Wikimedia Commons
Micrografía de la mucosa gástrica. Imagen: Wikimedia CommonsLa secreción de jugos en el estómago de mamíferos corre a cargo de células especializadas de su pared, la llamada mucosa gástrica. Se diferencian en ella dos grandes áreas, la mucosa oxíntica, que recubre el cuerpo y el fundus, y el área de glándulas pilóricas, que recubre el antro. La mucosa presenta múltiples pliegues, en cuyo interior se hallan las criptas gástricas, que son invaginaciones profundas del epitelio estomacal; las criptas configuran conductos y aperturas por los que las glándulas gástricas, que se encuentran en su base, evacúan sus productos a la luz estomacal.
Las glándulas gástricas están formadas por células secretoras de diferente tipo, unas son exocrinas y otras, endocrinas o paracrinas, aunque hay una diferencia importante entre los tipos de células secretoras de las glándulas de la mucosa oxíntica y las del área de glándulas pilóricas. A estas células y sus productos de secreción nos referiremos más adelante.
En el proventrículo de las aves hay dos tipos de glándulas, unas secretan moco y otras, HCl y pepsinógeno; ambas sustancias se producen en la misma célula, la llamada célula principal o célula oxinocopéptica.
 Estructura de una glándula gástrica del fondo y el cuerpo del estómago humano. Imagen: Adaptada de Barrett KE, Gastrointestinal Physiology. New York: Lange Medical Books/McGraw-Hill, Medical Pub. Division, 2006. Fuente.
Estructura de una glándula gástrica del fondo y el cuerpo del estómago humano. Imagen: Adaptada de Barrett KE, Gastrointestinal Physiology. New York: Lange Medical Books/McGraw-Hill, Medical Pub. Division, 2006. Fuente.En el estómago de mamíferos hay tres tipos de células secretoras exocrinas en las paredes de las criptas de la mucosa oxíntica:
(1) Las células mucosas recubren las criptas gástricas y la entrada a las glándulas; secretan un moco ligero de consistencia acuosa.
(2) Las células principales y las parietales recubren las zonas más profundas de las glándulas gástricas; las más numerosas son células principales y secretan pepsinógeno y lipasa gástrica.
(3) Las células parietales (u oxínticas) secretan ácido clorhídrico y el denominado factor gástrico intrínseco, una glucoproteína esencial para la posterior absorción de la vitamina B12 más tarde en el intestino.
Además, hay algunas células troncales que se dividen rápidamente para dar lugar a los diferentes tipos celulares del epitelio. Hay que tener en cuenta que se trata de un tejido muy activo y que la mucosa gástrica se renueva en su totalidad en pocos días: tan solo tres en el estómago humano.
Todas las secreciones exocrinas citadas se evacúan a la luz estomacal y son denominadas de forma conjunta jugos gástricos.
Las células parietales secretan HCl a la luz de las criptas, de donde es evacuado al interior del estómago. Los protones se producen en el interior de las propias células parietales, a partir de la escisión de moléculas agua. El OH– se combina con CO2 para dar ión bicarbonato mediante una reacción catalizada por la anhidrasa carbónica. Una ATPasa de H+/K+ bombea los protones (H+) al exterior de la célula (a la luz de la cripta). Esa bomba también introduce K+ en la célula, pero este difunde al exterior a continuación a través de los correspondientes canales. El transporte de H+ se realiza contra un gradiente de concentración enorme: en la cripta los protones pueden estar hasta tres o cuatro millones de veces más concentrados que el citoplasma de la célula parietal. Eso quiere decir que se necesita una cantidad de energía muy grande para salvar ese gradiente, lo que explica la abundancia de mitocondrias en las células parietales.
El cloruro procede del plasma, y su transporte está relacionado con la formación del bicarbonato (HCO3–) antes referida. Un antiporter de Cl–/HCO3– (en la membrana basolateral de las células parietales) traslada el bicarbonato al plasma a favor de su gradiente electroquímico y el Cl– desde el plasma al interior celular (en contra de gradiente de concentración). El ión cloruro se acumula así en el citoplasma y como está más concentrado aquí que en la luz estomacal y, además, la cara interna de la membrana es negativa, sale de la célula a favor de su gradiente electroquímico.
El ácido clorhídrico así formado en la luz del estómago cumple varias funciones importantes: (1) activa el pepsinógeno, convirtiéndolo en la enzima pepsina, a la vez que produce el grado de acidez óptimo para su actuación; (2) ayuda a la rotura del tejido conjuntivo y fibras musculares; (3) desnaturaliza las proteínas del alimento eliminando así su estructura terciaria y haciendo los enlaces peptídicos más accesibles a la acción digestiva; y (4) elimina la mayor parte de los microorganismos que han sobrevivido a la acción de la lisozima salivar (aunque no todos).
No todos los animales tienen digestión ácida estomacal. Los insectos, por ejemplo, no la realizan y tampoco tienen pepsinógeno. Los peces globo no tienen estómago y tampoco expresan el gen en ningún otro enclave digestivo (¡aunque sí en la piel!). Pero todos los vertebrados con estómago, salvo los ciclóstomos, tienen actividad péptica. El pepsinógeno, que se encuentra en vesículas secretoras de las células principales, es liberado al ducto de las criptas gástricas cuando se necesita. Una vez en la luz estomacal, debido al pH ácido, se convierte en pepsina y esta, a su vez, prosigue la activación de más unidades de pepsinógeno. La pepsina actúa sobre ciertos enlaces entre aminoácidos en el interior de las cadenas proteicas para rendir péptidos de menores dimensiones.
La digestión estomacal comprende, en realidad, tres actividades digestivas diferentes. En su tránsito por el fundus, las contracciones de la musculatura lisa que provocan las ondas peristálticas son todavía débiles. Por ello, en esa zona, el quimo es una sustancia semisólida de cierta consistencia y solo la zona exterior se encuentra expuesta a la acción de los jugos gástricos. En el interior de la masa semisólida sigue actuando la amilasa salivar. Más adelante, sin embargo, las contracciones peristálticas son más fuertes, hay más mezcla, el quimo pierde consistencia y los jugos gástricos tienen acceso a la mayor parte de las partículas en que se ha convertido el alimento. En esa fase cesa la digestión estomacal del almidón y el glucógeno y es cuando sobre todo el quimo actúan el HCl, la pepsina y la lipasa gástrica1.
Llegados a este punto conviene tener presente que los productos vertidos al interior del estómago son, potencialmente, muy lesivos para la pared gástrica, sobre todo el ácido clorhídrico, pero también las enzimas proteolíticas. Por esa razón, la pared necesita protección. El epitelio estomacal, entre las criptas, está formado por unas células que secretan un moco viscoso, de pH alcalino, que recubre todo el epitelio y sirve para protegerlo de la acción del ácido. Además de moco, esas células también secretan bicarbonato, que queda embebido en el propio moco y que neutraliza el ácido de su entorno. Además, la membrana celular de las células epiteliales es impermeable a los protones, por lo que estos no pueden penetrar en su interior ni causar daño, y esas células se encuentran unidas entre sí por uniones estrechas (zonulae occludentes), lo que impide o dificulta mucho que el ácido penetre entre ellas hacia la submucosa. Por último, hay que recordar que las células de la mucosa estomacal se renuevan muy rápidamente.
Nota:
1 Se estima que el 30% de la digestión de lípidos en la especie humana se debe a esa actividad.
Sobre el autor: Juan Ignacio Pérez (@Uhandrea) es catedrático de Fisiología y coordinador de la Cátedra de Cultura Científica de la UPV/EHU
El artículo Digestión estomacal (I): el papel de las glándulas gástricas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- La motilidad estomacal
- Los tipos celulares humanos y su origen embrionario
- El estómago (u órgano equivalente)
Genética molecular para el rastreo de la caza furtiva
La genética molecular ha servido para desarrollar una herramienta que puede ser útil en los intentos de rastrear las diferentes partidas de colmillos de marfil que confisca la Interpol entre Asia y África.
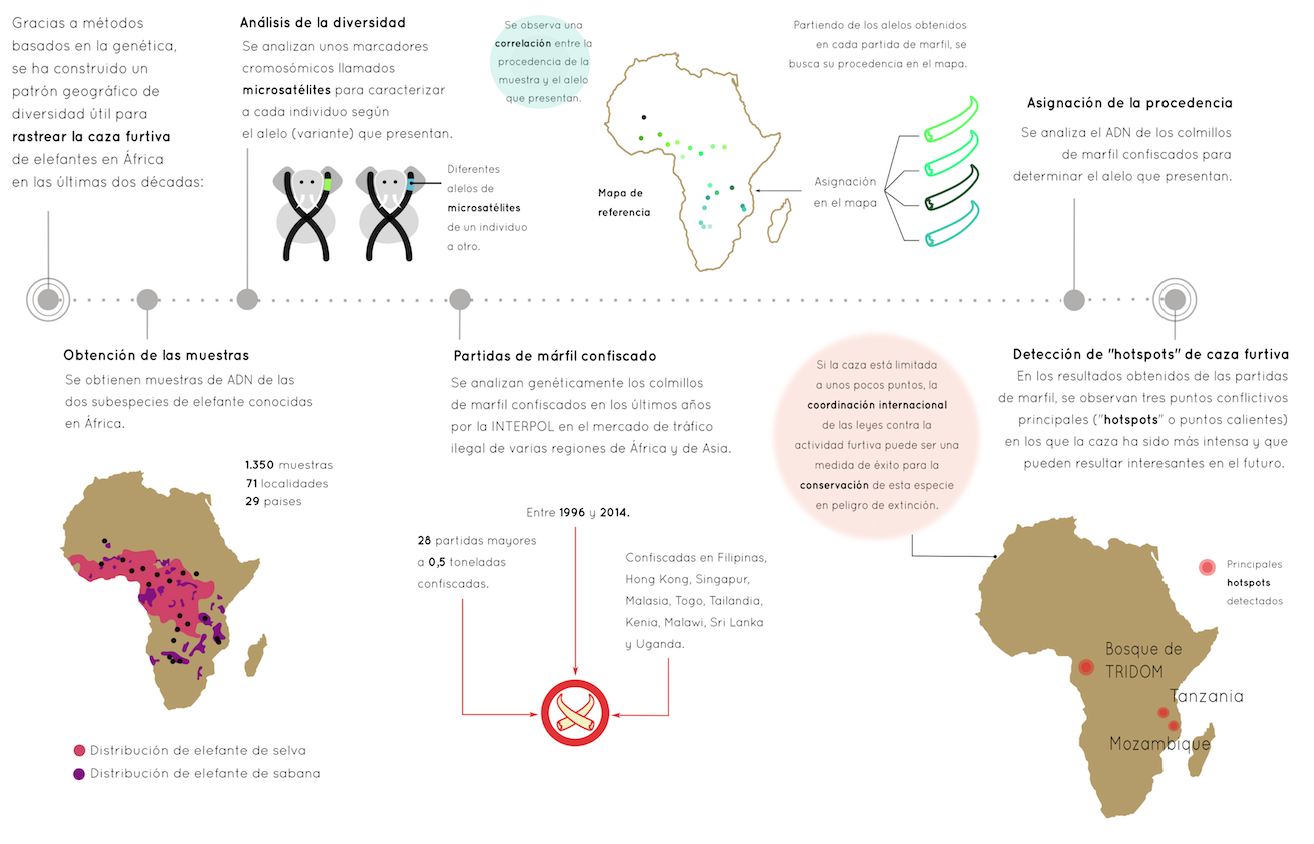 Imagen: Proceso detallado del estudio que ha determinado las zonas donde se desarrolla la caza furtiva de marfil. (Ilustración: Enara San Sebastian)
Imagen: Proceso detallado del estudio que ha determinado las zonas donde se desarrolla la caza furtiva de marfil. (Ilustración: Enara San Sebastian)En un estudio publicado en la revista Science Advances y llevado a cabo en la Universidad de Washington, con la colaboración de la entidad internacional, se ha concluido que la caza furtiva de marfil de las dos últimas décadas puede limitarse a tres zonas del continente africano: sudeste de Tanzania, el territorio contiguo al norte de Mozambique y la zona denomina TRIDOM (Trinational Dja-Odzala-Minkebe).
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Enara San Sebastian Casas (@enara_ssc), alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Contra el furtivismo, genética molecular. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 4 de octubre de 2015.
———————————-
El artículo Genética molecular para el rastreo de la caza furtiva se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Contra el furtivismo, genética molecular
- En el mar, allí donde todo comienza
- Metamorfosis criogénica de la rana del bosque
Ver para ver, pero no solo ‘tabula rasa’ en la corteza visual
Fernando Giraldez
Si un hombre nacido ciego recuperara la vista, ¿podría identificar al mirar los objetos que no pudo ver pero que conoce por el tacto? Esta fue la pregunta de William Molyneux a John Locke en 1688 y que éste último discutió en su “Ensayo sobre el entendimiento humano” (1). La cuestión puede considerarse una prueba para confrontar la idea de la existencia del conocimiento innato frente a la de que todo es aprendido, la tabula rasa, un caso particular del problema general del problema de “lo innato y lo adquirido”. En realidad, el “experimento” de Molyneux se ha realizado parcialmente mediante el tratamiento quirúrgico de cataratas congénitas en niños y la respuesta parece ser que la visión normal requiere una exposición temprana para desarrollar la capacidad plena de identificar objetos o para la percepción del espacio. Pero como toda buena pregunta, la respuesta genera aún más preguntas. ¿Excluye lo dicho que algún reconocimiento categórico fundamental para la supervivencia pueda ser heredado?, ¿Implica el resultado que no haya requisitos previos al aprendizaje, fuera de una capacidad asociativa general del cerebro? ¿Es el cerebro una verdadera tabula rasa?
 ¿Reconocería un ciego que recuperara la vista unas formas que solo ha conocido tocándolas simplemente con verlas? Imagen: Wikimedia Commons
¿Reconocería un ciego que recuperara la vista unas formas que solo ha conocido tocándolas simplemente con verlas? Imagen: Wikimedia CommonsLa capacidad humana para reconocer caras es bastante sorprendente. Se desarrolla muy temprano en la vida y tiene una serie de reglas específicas de tipo gestalt (2). Su prominencia en la infancia se manifiesta por cómo miran fijamente una cara que entra en su campo visual o el tamaño de los rostros dibujados por los niños cuando se les pide dibujar a su madre. Sin duda, el reconocimiento facial tiene un poderoso valor evolutivo, de supervivencia, tanto durante la infancia para la identificación de los próximos, como en la vida adulta para interactuar con los otros. De acuerdo con ello, el reconocimiento de caras requiere de mecanismos neuronales específicos y refinados. Esto se ejemplifica bien por un problema neurológico llamado prosopagnosia, un trastorno en el que los pacientes no pueden identificar las caras (ceguera facial). Los pacientes que sufren de prosopagnosia pueden ver e identificar numerosos objetos, pero no las caras. Pueden ver las líneas o formas que impactan en sus ojos, pero no identificar que aquello es una cara. Es decir, su sistema visual “está bien”, pero no pueden ver caras. Estos pacientes son capaces de compensar el defecto y a lo largo de sus vidas aprenden a identificar con quién están hablando mediante datos contextuales como la voz, la ropa o el aroma, y así no “confundir a su mujer con un sombrero”, como contaba el popular neurólogo Oliver Sacks.
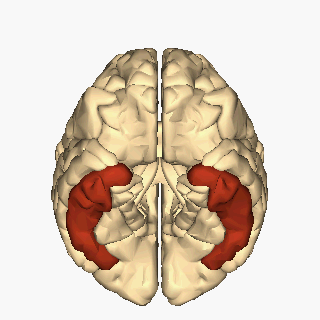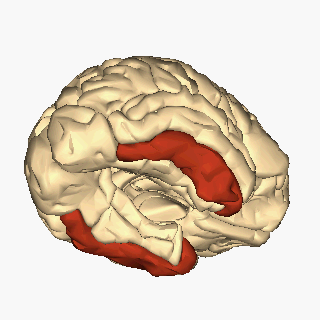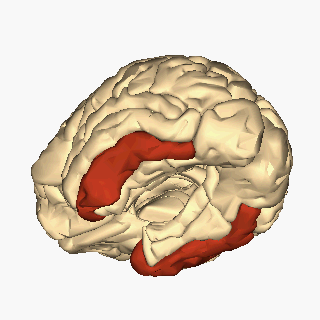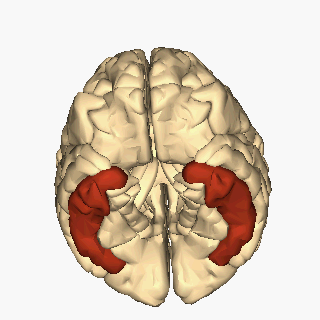 Ubicación del giro temporal inferior. Imagen: Wikimedia Commons
Ubicación del giro temporal inferior. Imagen: Wikimedia CommonsLa visión de las caras se ha rastreado hasta una región del cerebro, el lóbulo temporal inferior, más específicamente en la corteza infratemporal (IT). Esta región está dañada en muchos pacientes que sufren prosopagnosia y su estimulación distorsiona el reconocimiento facial, lo que sugiere que es un módulo esencial para la categorización facial. De hecho, el registro directo de la actividad de neuronas en la corteza temporal de monos muestra que hay neuronas que responden con alta selectividad a caras frente a otros objetos. Pero téngase en cuenta que esta capacidad de reconocer caras no sale de la nada en el cerebro y no es un mecanismo neuronal aislado o único. Cerca de estas “área de la cara” hay otras regiones que son selectivas a otras partes del cuerpo, a objetos, en fin, a “las cosas” que nos rodean. En otras palabras, la corteza temporal inferior alberga sistemas neuronales que categorizan el mundo que nos rodea. La organización de estos dominios de reconocimiento es invariante entre los individuos: las neuronas que responden a una categoría dada se agrupan y guardan relaciones topológicas constantes. Por lo tanto, parece que el aparato cerebral dedicado a la categorización del mundo que está muy bien estructurado, tanto anatómica como funcionalmente.
El problema es ahora saber cómo surge una estructura tan sofisticada en el cerebro. ¿Heredamos estos circuitos, o se organizan a lo largo de la vida? Parece obvio que es poco probable que la maquinaria neuronal para detectar teléfonos o sillas esté en nuestro cerebro al nacer, pero ¿ocurrirá lo mismo con las caras? ¿Podría ser que la circuitería cerebral dedicada a la detección facial ha sido seleccionada por la evolución y transmitida de padres a hijos? Este ha sido un tema de discusión recurrente en los últimos años y alguna evidencia apunta que este puede ser el caso. Sin embargo, una serie reciente de artículos del laboratorio de Margaret Livingstone (3) y sus colegas de Harvard apuntan más bien en otra dirección. A continuación describiré algunos de sus experimentos hechos en monos cuyo sistema de percepción es muy parecido al nuestro (4).
La primera pregunta que se hicieron los investigadores fue muy simple: ¿están presentes estas “áreas de categorización” al nacer? La respuesta parece ser negativa. Si bien en etapas tempranas de la vida la organización general del sistema visual es parecida a la de un adulto, esto no es así en los detalles. De hecho, los dominios dedicados a las caras o a los diferentes objetos no están presentes al nacer, aunque esto no significa que no haya ningún tipo de estructura. Por el contrario, estas regiones muestran lo que se llama una organización retinotópica, es decir, una correspondencia punto a punto entre la retina y una región dada del cerebro. También muestran una capacidad elemental de análisis, por ejemplo, pueden detectar patrones elementales como líneas, y su resolución varía del centro a la periferia (más a menos resolución respectivamente). Y más aún, las regiones centrales prefieren líneas con mayor curvatura que las periféricas. Por lo tanto, al nacer, esta región que más adelante alojará “las categorías” no está aún organizada en categorías, sino en una proto-arquitectura con reglas propias.
La siguiente pregunta ahora no es otra que ¿cómo se transita desde esta proto-arquitectura a la arquitectura adulta? Una posibilidad es que tengamos circuitos innatos que simplemente requieran madurar, algo así como “las categorías ya están ahí, pero requieren tiempo para desarrollarse”. La alternativa es que la interacción de esta proto-arquitectura con el entorno es lo que impulsa y especifica la estructura madura. La idea es que la arquitectura cerebral se continúa desarrollando después del nacimiento pero para ello requiere la interacción del propio sistema nervioso con su entorno (5). Con esto en mente, Margaret Livingstone y su grupo se preguntaron si el desarrollo de los “dominios cara” en el cerebro está ahí y requiere tiempo o por el contrario requiere exponerse a caras. Su experimento consistió en explorar lo que les sucede a los monos criados sin ninguna exposición a caras, aunque expuestos a un ambiente por otra parte “normal”, rico en otros estímulos (pudieron ver una variedad de juguetes y objetos, así como oír y oler a otros monos). El resultado fue que, a los seis meses, cuando los monos normales desarrollan los “dominios cara”, aquellos no expuestos a caras fueron incapaces de desarrollarlos. De acuerdo con ello, el comportamiento de los monos también fue menos atento y menos selectivo para las caras. Las regiones dedicadas a otras categorías, sin embargo, se mantuvieron esencialmente sin cambios. Al investigar ahora si el “dominio cara” simplemente desaparece o se reorganiza, descubrieron que el territorio es invadido por neuronas que responden selectivamente a otras cosas, a otras categorías como, por ejemplo, las manos. Por lo tanto, la región en estas etapas es plástica: capaz de categorizar caras, pero también otras cosas si no hay caras.
En resumen, esto sugiere que el origen de los “dominios cara” no difiere del de los otros dominios de categorización cerebral. De alguna manera aprendemos a ver, viendo. Sin embargo, el trabajo muestra también no es sólo (o simplemente) asociacionismo. Los “dominios cara”, como parte de una región más amplia de los “dominios de categorización”, se organiza a partir de una proto-arquitectura basada en la geometría, la correspondencia retinotópica punto a punto entre la retina y la corteza. Y esta organización retinotópica incluye también la excentricidad como una dimensión. Esto se refiere a que los diferentes elementos del análisis de la escena visual están orientados hacia diferentes regiones del campo visual. En palabras de Livingstone y colaboradores, “una organización retinotópica innata lleva consigo una organización para el tamaño del campo receptivo y, por lo tanto, un sesgo para características como la curvatura y la escala”. Por lo tanto, la excentricidad es un principio importante de la organización para estructurar los “dominios de categorías” y, de hecho, un vínculo entre la geometría y la organización inducida por la actividad. La hipótesis es que la frecuencia de aparición de diferentes objetos dentro del campo visual puede impulsar la organización de los parches dedicados a las diferentes categoría y dictar su ubicación. En otras palabras, la organización de esta región de la corteza refleja la organización del espacio visual (idea ya avanzada por Rafael Malach del Weizmann Institute de Israel). Las caras se representan en la región central del dominio de las categorías porque las caras son lo que los bebés ven constantemente en el centro de su campo visual que a su vez está sesgado para las figuras curvas, mientras que las manos o las tazas se desplazan hacia la periferia porque allí es donde normalmente están.
Y esto nos lleva de nuevo a nuestra pregunta inicial, el problema de Molyneux y la tabula rasa. Livingstone y sus colaboradores abordan el problema así: “Nuestros resultados limitan cuán fuerte puede ser un sesgo innato de las categorías y muestran que la primera organización no puede ser solamente categórica”. Es decir, siendo verdad que el sistema de detección de caras no es innato, esto no implica que su origen sea sólo la experiencia. Se necesitan unas reglas precisas, intrínsecas al sistema nervioso, que posibilitan la interacción con el entorno: la topología de los diferentes dominios visuales (curvatura, escala, resolución). Se trata así de otro ejemplo interesante para mostrar que heredamos reglas y no “cosas”. Una vez más, la discusión entre el carácter innato o adquirido de las funciones cerebrales como si fueran variables independientes aparece como un problema mal planteado cuando se ahonda en los mecanismos del desarrollo del cerebro.
NOTAS:
(1) William Molyneux (1656-1698) expuso el problema en Dioptrica nova (1692) y en una carta a John Locke, que éste reproduce en su Ensayo sobre el entendimiento humano (1694). La carta original de Molyneux se puede ver en https://plato.stanford.edu/entries/molyneux-problem/
(2) Gestalt es un término alemán y se suele traducir por forma, configuración o estructure. Define una corriente en la psicología que enfatiza el carácter global y organizado de la percepción. Se desarrolló a principios del siglo XX pero se puede trazar a Ernst Mach, un extraordinario científico y filósofo que realizó detallados estudios sobre la visión. Los psicólogos de la Gestalt descubrieron numerosas reglas con las que organizamos nuestras precepciones, mostrando que no son la mera agregación de elementos. Esta visión respira el concepto de las reglas a priori de Immanuel Kant.
(3) Margaret Livingstone es profesora de Neurobiología de la Harvard Medical School y se inició en la fisiología de la visión con el premio Nobel David H. Hubel en los años ochenta. Es autora de Vision and Art, un libro muy interesante sobre la biología de la percepción artística.
(4) Los monos tienen un sistema visual muy similar al nuestro, con lo que los resultados pueden ser extendidos a los humanos con bastante garantía. Estos experimentos se realizan utilizando la técnica de fMRI (Resonancia Magnética Nuclear funcional) que permite el mapeo de la actividad neuronal en dominios restringidos del cerebro. Es una técnica que no mide directamente la actividad de las neuronas sino el flujo sanguíneo, que a su vez es proporcional a la actividad neuronal. Su resolución espacial es de aproximadamente un milímetro de territorio cerebral, lo que supone la actividad agregada de varios miles de neuronas. La gran ventaja es que se trata de una técnica no invasiva que permite realizar experimentos en monos despiertos y entrenados realizar tareas específicas.
(5) Las interacciones del sistema nervioso con el entorno provocan cambios en la expresión de genes, refuerzo o debilitamiento de las conexiones neuronales (número de sinapsis, producción y liberación de neurotrasmisores, etc.). Estos mecanismos subyacen a los principales cambios observados en el cerebro del bebé y los llamados “períodos críticos”. Se trata de un proceso fascinante que implica que durante la infancia la estructura física del cerebro depende de su interacción con el entorn. Un ejemplo paradigmático de plasticidad y de la interacción entre los genes y el medio ambiente.
Referencias:
Arcaro, M.J., Schade, P.F., Vincent, J.L., Ponce, C.R. & Livingstone, M.S. (2017) Seeing faces is necessary for face-domain formation. Nature Neuroscience 20: 1404 https://www.nature.com/articles/nn.4635
Véase también: Livingstone, M.S., Arcaro, M.J. & P.F. Schade (2018) Cortex Is Cortex: Ubiquitous Principles Drive Face-Domain Development. Trends in Cognitive Sciences, 24: Letter DOI: 10.1016/j.tics.2018.10.009 Aquí se discuten algunas alternativas a la hipótesis de Livingstone y colaboradores.
Esta nota surgió de una charla con Jordi Chanovas (SUNY Downstate Medical Center) a quien agradezco sus sugerencias y comentarios.
Sobre el autor: Fernando Giráldez es catedrático de biología del desarrollo en el Departament de Ciències Experimentals i de la Salut de la Universitat Pompeu Fabra. Su carrera investigadora tanto en la Universidad de Cambridge como en distintas universidades españolas se ha centrado en el desarrollo y funcionamiento de los órganos de los sentidos. El profesor Giráldez tiene un especial interés en los aspectos filosóficos y humanísticos de la neurociencia. Mantine el blog Las neurociencias y las letras.
El artículo Ver para ver, pero no solo ‘tabula rasa’ en la corteza visual se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El entrenamiento mental solo sirve para entretenerse un rato
- El estrés no es solo cosa de humanos
- Cartogramas, una herramienta de información visual
Especies exóticas invasoras
Carrizo de la pampa, galápago de florida, mosquito tigre, avispa asiática… todas ellas son especies procedentes de otras latitudes, siendo diversas las razones de su introducción: propósitos ornamentales, pesca recreativa, industrias peleteras, etc. Estas especies se adaptan rápidamente al medio y compiten por el entorno con las demás especies autóctonas, convirtiéndose en una serie amenaza para la biodiversidad.
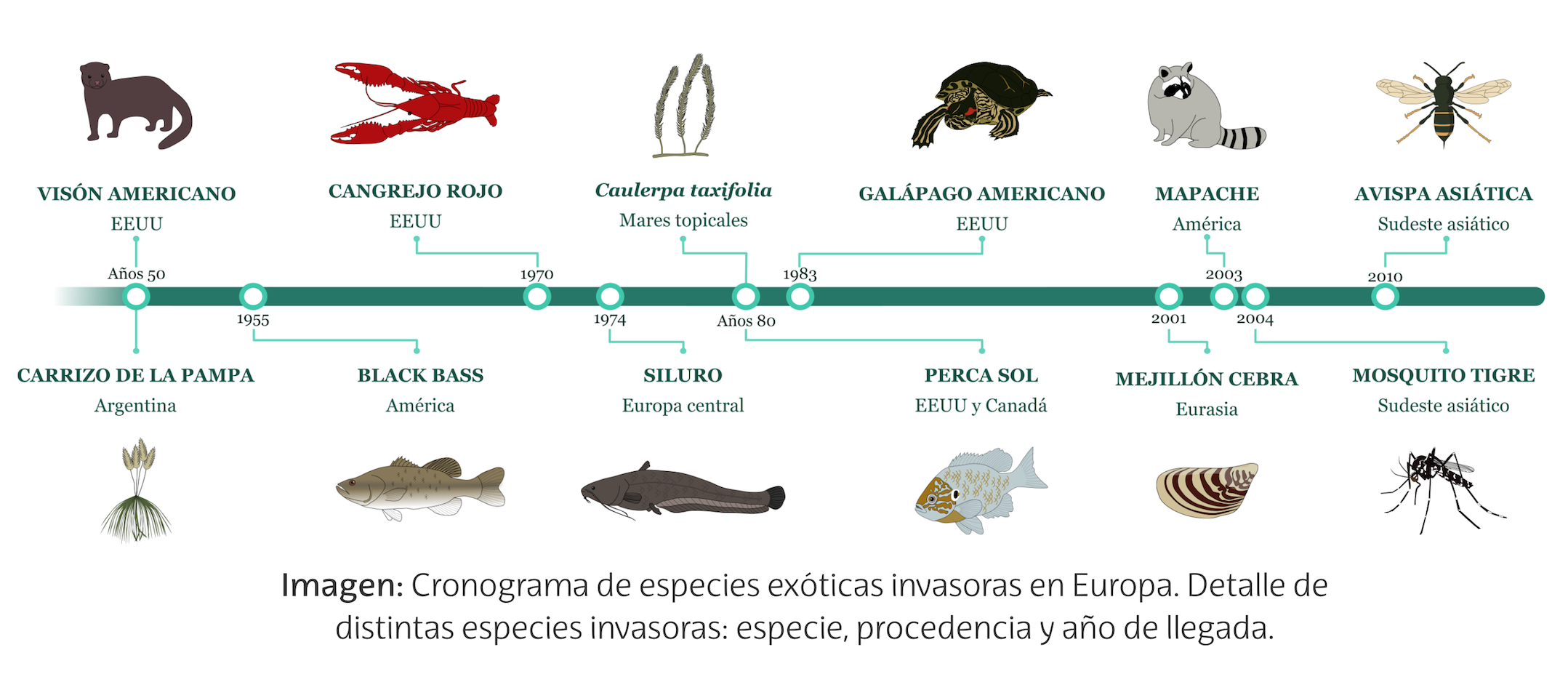 Ilustración: Izaskun Alberdi
Ilustración: Izaskun AlberdiSi observamos la imagen conoceremos una pequeña muestra de las numerosas especies que se han introducido en diferentes hábitats procedentes de otros entornos y que constituyen una gran amenaza para la biodiversidad. Sin duda, el comercio internacional y el tránsito de personas han multiplicado las ocasiones para su expansión lejos de sus lugares de origen, aumentado también el problema que supone erradicarlas.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Izaskun Alberdi Landaluze (@izas_ilustra), alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Los invasores. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 1 de mayo de 2016.
———————————-
El artículo Especies exóticas invasoras se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Metamorfosis criogénica de la rana del bosque
- En el mar, allí donde todo comienza
- Un ornitisquio emplumado
Geología: la clave para saber de dónde venimos y hacia dónde vamos
Si cerrásemos los ojos para visualizar la imagen de un geólogo, probablemente imaginaríamos a una persona descubriendo fósiles y recopilando y coleccionando minerales. No obstante, esta disciplina académica cuenta con muchísimas más aplicaciones desconocidas para gran parte de la sociedad.
Con el objetivo de dar visibilidad a esos otros aspectos que también forman parte de este campo científico nacieron las jornadas divulgativas “Abre los ojos y mira lo que pisas: Geología para miopes, poetas y despistados”, que se celebraron los días 22 y 23 de noviembre de 2018 en el Bizkaia Aretoa de la UPV/EHU en Bilbao.
La iniciativa estuvo organizada por miembros de la Sección de Geología de la Facultad de Ciencia y Tecnología de la UPV/EHU, en colaboración con el Vicerrectorado del Campus de Bizkaia, el Ente Vasco de la Energía (EVE-EEE), el Departamento de Medio Ambiente, Planificación Territorial y Vivienda del Gobierno Vasco, el Geoparque mundial UNESCO de la Costa Vasca y la Cátedra de Cultura Científica de la UPV/EHU.
Los invitados, expertos en campos como la arquitectura, el turismo o el cambio climático, se encargaron de mostrar el lado más práctico y aplicado de la geología, así como de visibilizar la importancia de esta ciencia en otros ámbitos de especialización.
Estíbaliz Apellaniz, doctora y profesora jubilada del departamento de Estratigrafía y Paleontología de la UPV/EHU, introduce en su intervención la geología como disciplina científica, y resume 4500 millones de años en 30 minutos.
Edición realizada por César Tomé López a partir de materiales suministrados por eitb.eus
El artículo Geología: la clave para saber de dónde venimos y hacia dónde vamos se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Zientziateka: Blanca Mª Martínez García – La geología fantástica de Verne, Poe y H.P. Lovecraft
- Las cartas de Darwin: ¡La geología por encima de todo!
- El metanol es clave para entender cómo se forman las estrellas
Metamorfosis criogénica de la rana del bosque
La rana del bosque, Lithobates sylvaticus, es un anfibio que sorprende porque pasa por una metamorfosis criogénica; es decir, se congela cuando hace mucho frío y cuando, semanas o meses después sube la temperatura, se descongela y recupera la actividad.
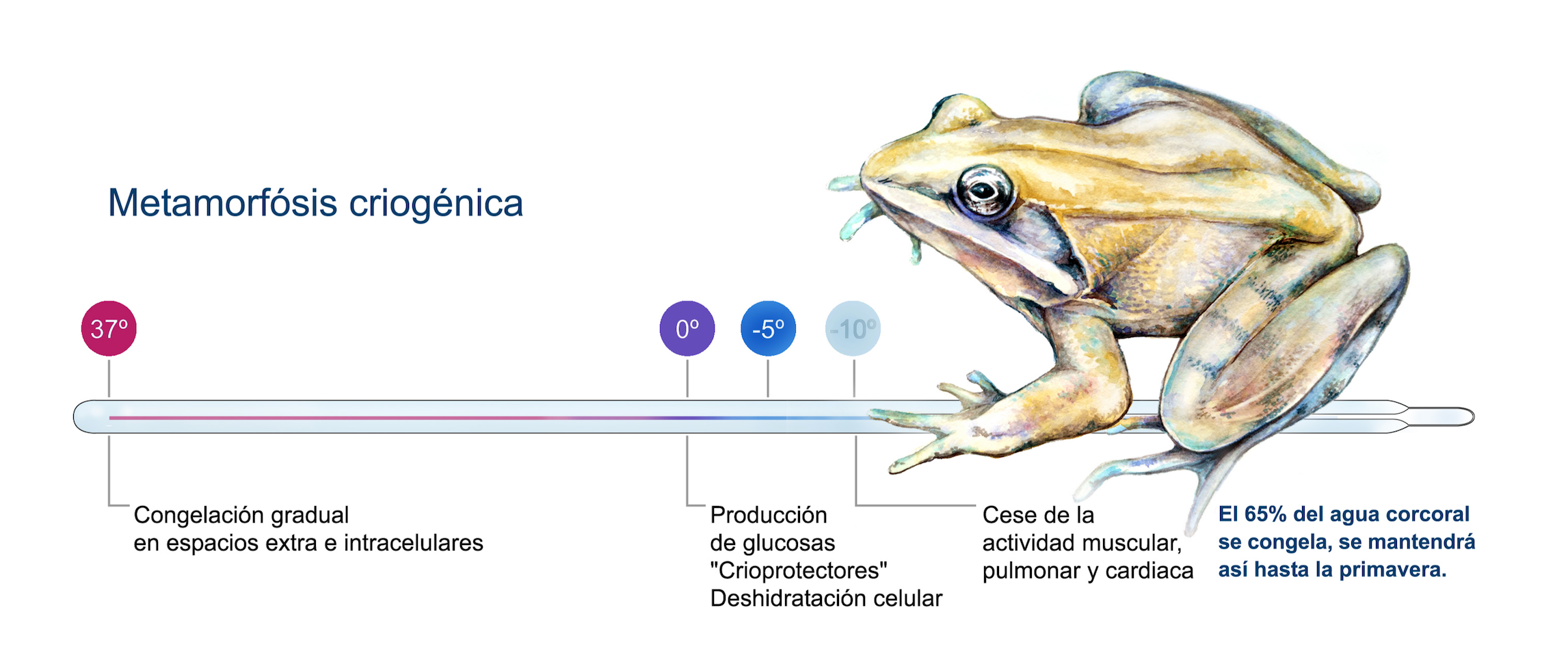 Imagen: Estadios por lo que pasa la rana del bosque en su proceso de criogenización. (Ilustración: Patricia Nagashiro)
Imagen: Estadios por lo que pasa la rana del bosque en su proceso de criogenización. (Ilustración: Patricia Nagashiro)Los científicos, a lo largo de los años, han investigado la vida de esta especie para determinar si ese proceso de congelamiento y descongelamiento puede ser aplicado a los humanos.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Patricia Nagashiro Vaca, alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: El sueño criogénico. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 5 de febrero de 2017.
———————————-
El artículo Metamorfosis criogénica de la rana del bosque se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:Control adaptativo de robots para rehabilitación
La investigadora del Departamento de Ingeniería de Sistemas y Automática de la UPV/EHU Aitziber Mancisidor Barinagarrementeria ha diseñado un algoritmo de control para dispositivos robóticos capaces de adaptarse a diferentes estados de recuperación de los pacientes en rehabilitación, sin repercusión en el coste del dispositivo.
 Fuente: Mancisidor et al (2018)
Fuente: Mancisidor et al (2018)En las últimas décadas, observando la necesidad de mejorar la calidad de vida de enfermos con movilidad reducida, y los progresos obtenidos gracias a la utilización de los robots en la industria, los dispositivos robóticos han sido propuestos para terapias de rehabilitación. “Los robots de rehabilitación permiten emular los ejercicios de un fisioterapeuta obteniendo tratamientos adaptados y precisos”, indica Aitziber Mancisidor, autora del estudio. Asimismo, “funcionan como una herramienta de medición que permite cuantificar fuerzas y/o movimientos. Y con ayuda de un interfaz gráfico, construyen un entorno de realidad virtual facilitando e incentivando el proceso de rehabilitación”, añade.
Sin embargo, debido a su reciente introducción al ámbito clínico, muchas de las áreas de la robótica de rehabilitación no han sido estudiadas en profundidad y existen varios aspectos a mejorar, entre ellos el control de los dispositivos. Ante esta situación, esta investigación se ha centrado en mejorar la parte del control de los dispositivos robóticos. “El dispositivo mecánico del robot es el encargado de realizar los movimientos, pero para que ese dispositivo se comporte de forma deseada es imprescindible diseñar un algoritmo de control que indique con qué fuerza y frecuencia se tienen que efectuar esos movimientos etc.”, explica Mancisidor.
Cualquier terapia de rehabilitación es un proceso largo. Al principio, los pacientes no tienen capacidad de generar movimiento, por lo que el robot es el que tiene que aportar ese movimiento de forma adecuada. Sin embargo, cuando el paciente va recuperando fuerza, el movimiento lo tiene que ejecutar el propio paciente y el robot le tiene que asistir o resistir. “Con el fin de dar respuesta a estas necesidades, se ha propuesto un algoritmo de control dividido en dos niveles: por un lado, calcula la asistencia que debe realizar el robot dependiendo del estado de recuperación del paciente y del ejercicio seleccionado; y por otro lado, controla la fuerza y el movimiento ejecutado por el robot generando movimientos suaves y seguros”, indica la investigadora de la UPV/EHU.
Asimismo, “el algoritmo de control diseñado se ha dotado con estimadores que permiten calcular la posición y la fuerza de contacto entre el dispositivo robótico y el usuario”, apunta Aitziber Mancisidor. “Una de las problemáticas de este tipo de robot es que existen muy pocos ejemplares en comparación con los robot industriales y por tanto su coste es muy elevado. Para reducir el coste de estos dispositivos de rehabilitación hemos utilizado varios estimadores de fuerza y movimiento en lugar de utilizar sensores costosos”, añade.
Por último, “hemos diseñado e implementado una plataforma de control y ejecución, que además de permitir la ejecución en tiempo real del algoritmo de control, sirve de puente de comunicación entre el robot de rehabilitación, el usuario y el controlador. Esta plataforma de control y ejecución ha permitido realizar diferentes pruebas experimentales del algoritmo de control propuesto, lo que ha posibilitado validar su funcionamiento en diferentes escenarios.
A la vista de los resultados obtenidos, la investigadora añade que “tanto por su capacidad de adaptarse a diferentes estados de recuperación de los pacientes como por su precisión los robot de rehabilitación pueden ser una buena alternativa en las terapias de rehabilitación del futuro”, concluye.
Referencia:
Mancisidor et al (2018) Kinematical and dynamical modeling of a multipurpose upper limbs rehabilitation robot Robotics and Computer-Integrated Manufacturing doi: 10.1016/j.rcim.2017.08.013
Edición realizada por César Tomé López a partir de materiales suministrados por UPV/EHU Komunikazioa
El artículo Control adaptativo de robots para rehabilitación se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El aprendizaje continuo mejora la interacción de robots con humanos en lenguaje natural
- Cuando las proteínas son robots
- Naukas Bilbao 2017 – Diana González: Identidad digital y robots
En el mar, allí donde todo comienza
Se cree que el origen de la vida en la Tierra se dio hace 4.500 millones de años aproximadamente. En un intento constate por descubrir, el ser humano ha llegado a investigar en los más recónditos y profundos lugares.
A más de 4.000 metros de profundidad, en el fondo de los océanos, un grupo de investigación ha encontrado microorganismos fósiles que, según los indicios, pudieron albergar el posible origen de la vida.
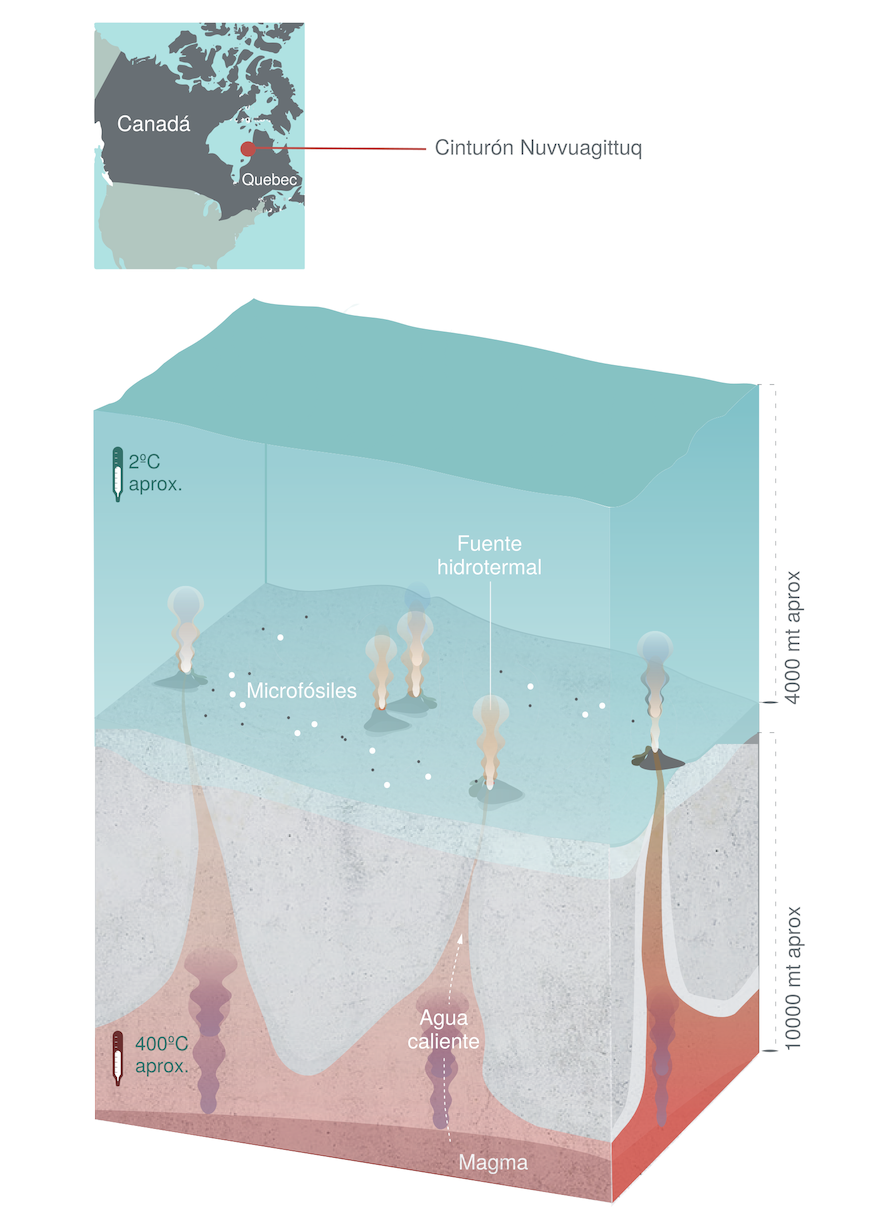 Imagen: Zona del cinturón Nurvvuagittuq donde se han encontrado los microfósiles. (Ilustración: Paula Gómez)
Imagen: Zona del cinturón Nurvvuagittuq donde se han encontrado los microfósiles. (Ilustración: Paula Gómez)———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Paula Gómez Bernal, alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: En lo más recóndito de nuestro planeta. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 11 de diciembre de 2016.
———————————-
El artículo En el mar, allí donde todo comienza se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- Un ornitisquio emplumado
- La evolución de los perros
- Asociación evolutiva entre la higuera común y las avispas
Las dietas detox ni desintoxican ni adelgazan

Después de las fiestas de Navidad y de los periodos vacacionales, muchos cambian el turrón y las bebidas alcohólicas por zumos detox y dietas milagro. Nace una especie de obsesión por purificar el organismo y ya de paso perder los kilos que hemos ganado. Hay que compensar los excesos. Tenemos la dieta de la alcachofa, del pomelo, de los zumos depurativos, del agua con limón, de la piña, etc. Este tipo de dietas ni sirven para perder peso, ya que tienen un efecto rebote que puede hacernos ganar más peso del que teníamos cuando la empezamos, ni sirven para desintoxicar nuestro organismo. Ningún alimento desintoxica. El concepto detox es muy marquetiniano, sirve para vender, pero desgraciadamente no sirve para nada más.
-
El origen de las dietas detox
La primera dieta milagro que causó furor fue la de la sopa de repollo en los años 60. Consistía en consumir exclusivamente sopa de repollo tres o cuatro veces al día. Sufrirías agotamiento y mareos, pero a cambio esa dieta te prometía bajar de peso.
Probablemente la primera dieta que se puso de moda como dieta detox fue la del pomelo allá por los años 70. ¿Por qué les dio por el pomelo y no por cualquier otra fruta o verdura? Nada tiene que ver con la salud. La razón fue que en esa década hubo un excedente en la producción de pomelo. Fue una estrategia brillante para revertir la relación oferta/demanda y que el pomelo subiera de precio.

El verdadero auge de los zumos detox ocurrió a partir de 2010. En esta década nacieron los juicers –algo así como zumeros-, personas que creen limpiar su organismo y controlar su peso a base de zumos detox. Esta suerte de movimiento surgió de la mano de Joe Cross, un empresario australiano que saltó a la fama por protagonizar la película Gordo, enfermo y casi muerto. Pesaba 140 kg y padecía una enfermedad autoinmune. La película es un documental en el que Joe Cross se pasa 60 días alimentándose de zumos. Hoy en día dirige una marca de salud y estilo de vida y es autor de varios libros. El movimiento de juicers que lidera le ha venido muy bien a la industria de las licuadoras: las ventas de licuadoras se dispararon tras el documental.
-
Nuestro organismo no necesita desintoxicarse
En nuestro cuerpo contamos con dos órganos detox por excelencia: el hígado y los riñones. También hacen lo propio la piel, los pulmones, el intestino y el sistema linfático. Es fisiología básica. No necesitamos un zumo de pomelo ni un agua con limón para animar a nuestros órganos a ponerse a trabajar. Ellos solitos ya saben bien lo que hay que hacer, y si no, estaríamos ante un cuadro de insuficiencia que desgraciadamente no se resuelve con zumos.
La intoxicación es un concepto médico. Nos podemos intoxicar con drogas o con venenos. De ahí el término desintoxicación que se aplica a las personas que padecen drogadicción. También podemos intoxicarnos con venenos, como quien ingiere lejía de forma accidental o quien consume un pescado contaminado con metales pesados. Ninguna de estas intoxicaciones se subsana con zumos o dietas milagro, sino con atención médica.
No obstante, se han hecho estudios científicos sobre las dietas detox. La conclusión es que no sirven para desintoxicar nuestro organismo ni tienen un efecto positivo sobre nuestra salud.
-
Las dietas detox ni desintoxican ni sirven para perder peso
La evidencia científica de la que disponemos nos dice que, tal y como cabía esperar, las dietas detox no sirven para desintoxicar. El término detox resulta atractivo, pero no es una alegación saludable reconocida por ninguna autoridad sanitaria. Es decir, no significa nada. Cualquier alimento puede llamarse detox porque sí, sin demostrar nada en absoluto. Turrón detox. Cerveza detox. Zumo detox. Es lo mismo.
La evidencia científica también nos dice que las dietas detox tampoco sirven para perder peso, sino todo lo contrario. Tras varios días alimentándonos solo a base de zumos sí experimentaremos una notable pérdida de peso. Ocurriría lo mismo si nos alimentamos solo de rodajas de piña, de vasos de agua o de nada. La restricción calórica severa tiene como consecuencia directa la pérdida de peso. No obstante, esta pérdida de peso es ficticia, se debe en mayor medida a pérdida de líquidos y no a pérdida de grasa, y además se recupera rápidamente. Esto tiene una razón biológica de ser. Ante la escasez de alimento, nuestro metabolismo entra en “modo ahorro de energía” como mecanismo de supervivencia. Esto quiere decir que las dietas hipocalóricas “ralentizan” nuestro metabolismo, de modo que en cuanto dejamos de hacer dieta (o casi ayuno) se producirá el conocido “efecto rebote”: un aumento de peso repentino en cuanto abandonamos la dieta, superior al peso de inicio.
Estos cambios metabólicos inducidos por esta clase de dietas también tienen implicaciones sobre el apetito: se ha demostrado que por cada kilo perdido tras este tipo de dieta la ingesta media aumenta en 100 kcal diarias.
-
Las dietas detox tienen riesgos
Pasarte varios días alimentándote de un solo tipo de alimento o consumiendo solo zumos es contraproducente. El contra más evidente es que pasaremos hambre y eso tiene implicaciones en el estado de ánimo: irritabilidad, falta de concentración, apatía… En cierto modo estas dietas depurativas son una especie de penitencia a la que nos sometemos voluntariamente para resarcirnos del pecado del exceso. Por eso las implicaciones psicológicas de este tipo de conductas no son menores.
Otros de los riesgos son la malnutrición y la desnutrición. Falta de nutrientes, sobre todo proteínas y vitaminas, y desequilibrios electrolíticos. Además, algunas de estas dietas implican el consumo de laxantes y diuréticos -aunque sean de origen natural- que enfatizan el problema. Estas dietas no nos sanan, sino que nos enferman.
Tampoco es una buena elección consumir frutas y verduras en forma de zumo. En cuanto exprimimos la fruta, los azúcares que antes eran saludables se convierten en azúcares libres. Las principales autoridades sanitarias, entre ellas la Organización Mundial de la Salud, alertan sobre el consumo de zumos y su relación con la obesidad y la diabetes tipo II. Al hacer zumo estamos dejando la fibra en la licuadora o el exprimidor, por lo que metabolizamos los azúcares de diferente manera, tanto es así que se convierten en azúcares insalubres. Además, hay que tener en cuenta que no es lo mismo masticar que beber, no solo con respecto al hábito, sino con respecto a la saciedad. Nos sacia más comernos una manzana que bebernos un zumo hecho con una manzana, un plátano y una naranja.
Otro riesgo tiene que ver con la errónea idea de la compensación. Del mismo modo que practicar deporte no compensa el consumo de azúcares libres, pasarnos varios días a zumos no compensa las comidas copiosas o el consumo de alcohol. Lo que provocan estas conductas compensatorias es la perpetuación de malos hábitos alimenticios y favorecen la aparición de trastornos en la conducta alimentaria, como el trastorno de purga, la bulimia nerviosa o la preocupación patológica por la comida sana (comúnmente llamada ortorexia).
-
Zumos detox y estatus
Cuando vimos a las protagonistas de Sexo en Nueva York beber café en vasos de cartón, los demás no íbamos a ser menos. Podemos hacer pasar por glamurosa cualquier absurdez. Incluso en los países en los que hay una especie de culto alrededor del buen café, las cadenas que ofrecen litronas aguadas a precio de oro han triunfado.

Eva Longoria, Jessica Alba, Elsa Pataky, Jennifer Garner, Miley Cyrus, Blake Lively o Anne Hathaway han dejado de pasearse con cafés y ahora lo hacen con un brebaje verde llamado green juice a base de verduras de moda como el kale (o col rizada). Dile al mundo que tu intención es cuidarte, aunque lo hagas sin ningún tipo de conocimiento. Y luego publica un selfie con tu zumo detox en las redes sociales, porque de eso se trata, de definir quién eres. Hasta un zumo verde puede definirte incluso mejor que tus zapatos.
También hay influencers que solo se alimentan de zumos. Se les llama juice cleanses (algo así como limpiezas con zumo). Es decir, las dietas detox de siempre pero con un nombre más cool. Estrellas como Salma Hayek o Gwyneth Paltrow han amadrinado diferentes marcas de cleanses. En programa de cinco días de zumos favorito de Paltrow puede costar hasta 400 dólares, y el menú de Hayek ronda los 58 dólares diarios.
No se trata de cuidar la salud sino de cuidar tu estatus. Y bueno, en general los zumos son más baratos que las joyas.
-
Conclusiones
Si eres consciente de que durante las últimas vacaciones te has alimentado mal, ya tienes algo ganado. Aprovecha para dejar de hacerlo mal y comenzar a hacerlo bien. Si no sabes cómo, o si crees que podrías padecer obesidad o algún trastorno en la conducta alimentaria, como comer por ansiedad, es el momento de que visites a un especialista en nutrición. Pasarte una o dos semanas siguiendo una dieta detox no solucionará el problema, sino que lo empeorará. De hecho, cualquier dieta que sea imposible mantener a lo largo del tiempo, no es una buena dieta.
Los zumos detox y las dietas milagro ni sirven para desintoxicarnos ni sirven para perder peso, sino lo contrario. En el mejor de los casos solo perderemos tiempo y dinero, en el peor además perderemos salud.
Referencias:
Detox diets for toxin elimination and weight management: a critical review of the evidence. Klein AV, Kiat H. J Hum Nutr Diet. 2015 Dec;28(6):675-86. doi: 10.1111/jhn.12286
Maintenance of Lost Weight and Long-Term Management of Obesity. Hall KD, Kahan S. Med Clin North Am. 2018 Jan;102(1):183-197. doi: 10.1016/j.mcna.2017.08.012
How strongly does appetite counter weight loss? Quantification of the feedback control of human energy intake. David Polidori, Arjun Sanghvi, Randy Seeley, and Kevin D. Hall. Obesity (Silver Spring). 2016 Nov; 24(11): 2289–2295. doi: 10.1002/oby.21653
Potential relationship between juice cleanse diets and eating disorders. A qualitative pilot study. Bóna E, Forgács A, Túry F. Orv Hetil. 2018 Jul;159(28):1153-1157. doi: 10.1556/650.2018.31090
Sobre la autora: Déborah García Bello es química y divulgadora científica
El artículo Las dietas detox ni desintoxican ni adelgazan se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas:- El azúcar oculto en los alimentos
- De la sal «sin gluten» al champú «sin gluten»: no solo marketing
- Con los edulcorantes artificiales (casi) todo son ventajas
Asociación evolutiva entre la higuera común y las avispas
La relación simbiótica entre la higuera común, Ficus carica, y la avispa Blastophaga psenes se remonta a unos ochenta millos de años atrás.
La avispa hembra sale del higo en el que ha nacido, cargada de polen y huevos fecundados, en busca de otra higuera de la misma especie. Tras encontrarla entra en el interior del higo, deja en él el polen y los huevos que lleva adheridos. Los huevos crecen y nacen las avispas. Los machos fecundan a las hembras y tras hacerlo mueren. Las hembras, sin embargo, vuelan en busca de una nueva higuera donde se repite de nuevo el proceso.
 Imagen: Ciclo de vida de la avispa Blastophaga psenes, asociada a la polinización de la higuera común Ficus carica y diseminación de sus semillas. (Ilustración: Paulina Peña)
Imagen: Ciclo de vida de la avispa Blastophaga psenes, asociada a la polinización de la higuera común Ficus carica y diseminación de sus semillas. (Ilustración: Paulina Peña)Una vez que las avispas dejan el higo, éste crece y cambia de tonalidad, se vuelve rojizo y se llena de azúcar. Así se transforma en el dulce alimento que conocemos.
———————————-
“Ilustrando ciencia” es uno de los proyectos integrados dentro de la asignatura Comunicación Científica del Postgrado de Ilustración Científica de la Universidad del País Vasco. Tomando como referencia un artículo de divulgación, los ilustradores confeccionan una nueva versión con un eje central, la ilustración.
Autora: Paulina Peña Matamala, alumna del Postgrado de Ilustración Científica de la UPV/EHU – curso 2017/18
Artículo original: Árbol sagrado, árbol maldito. Juan Ignacio Pérez Iglesias, Cuaderno de Cultura Científica, 22 de octubre de 2017.
———————————-
El artículo Asociación evolutiva entre la higuera común y las avispas se ha escrito en Cuaderno de Cultura Científica.
Entradas relacionadas: